



Im heutigen schnell wachsenden technologischen Arbeitsumfeld haben Unternehmen mehr Daten als je zuvor.
Eine große Menge an Daten bedeutet nichts; was Sie mit diesen Daten tun, ist entscheidend. Hier kommt das Data Mining ins Spiel. Es gibt den Daten einen Sinn, während Unternehmen daran arbeiten, verschiedene Ziele und potenzielle Verbesserungsstrategien durch den Prozess der Umwandlung von Rohdaten in umsetzbare Erkenntnisse umzusetzen. Es gibt viele Möglichkeiten, dies zu tun, und es hängt alles von den Data-Mining-Techniken ab, die Ihr Unternehmen wählt.
Data Mining ist der Prozess des Findens und Erkennens von Mustern in Daten für relevante Erkenntnisse; die verschiedenen Techniken sind der Weg, wie Sie Rohdaten in genaue Beobachtungen umwandeln.
Gängige Data-Mining-Techniken
Eine Vielzahl von Data-Mining-Techniken ist oft erforderlich, um Erkenntnisse zu gewinnen, die in großen Datensätzen verborgen sind, daher wäre es sinnvoll, mehr als eine zu wählen. Während Data Mining Kunden segmentieren kann, kann es auch helfen, Kundenloyalität zu bestimmen, Risiken zu identifizieren, prädiktive Modelle zu erstellen und vieles mehr.
Die meisten, aber nicht alle, Data-Mining-Techniken fallen entweder in die Kategorie der statistischen Analyse oder des maschinellen Lernens, je nachdem, wie sie verwendet werden. Im Folgenden gehen wir näher auf jede Technik ein.
Datenbereinigung
Eine notwendige Technik im Data Mining ist die Datenbereinigung. Rohdaten müssen bereinigt, formatiert und analysiert werden, damit sie nützlich sind und auf verschiedene Arten von Analysemethoden angewendet werden können. Diese Technik ist Teil verschiedener Elemente der Datenmodellierung, -transformation, -aggregation und -migration.
Wie wird Datenbereinigung heute verwendet?
Unternehmen verwenden die Datenbereinigung als ersten Schritt im Data-Mining-Prozess, da die gefundenen Daten sonst nutzlos und unzuverlässig sind. Es muss Vertrauen in die Daten und die Ergebnisse der Datenanalyse bestehen, damit ein lohnenswerter und umsetzbarer nächster Schritt möglich ist. Die Datenbereinigung ist oft der erste Schritt, der im Data-Mining-Prozess durchgeführt wird.
Clustering
Eine Data-Mining-Technik wird als Clusteranalyse bezeichnet, auch als numerische Taxonomie bekannt. Diese Technik gruppiert im Wesentlichen große Datenmengen basierend auf ihren Ähnlichkeiten. Diese Darstellung zeigt, wie eine Clusteranalyse aussehen könnte.
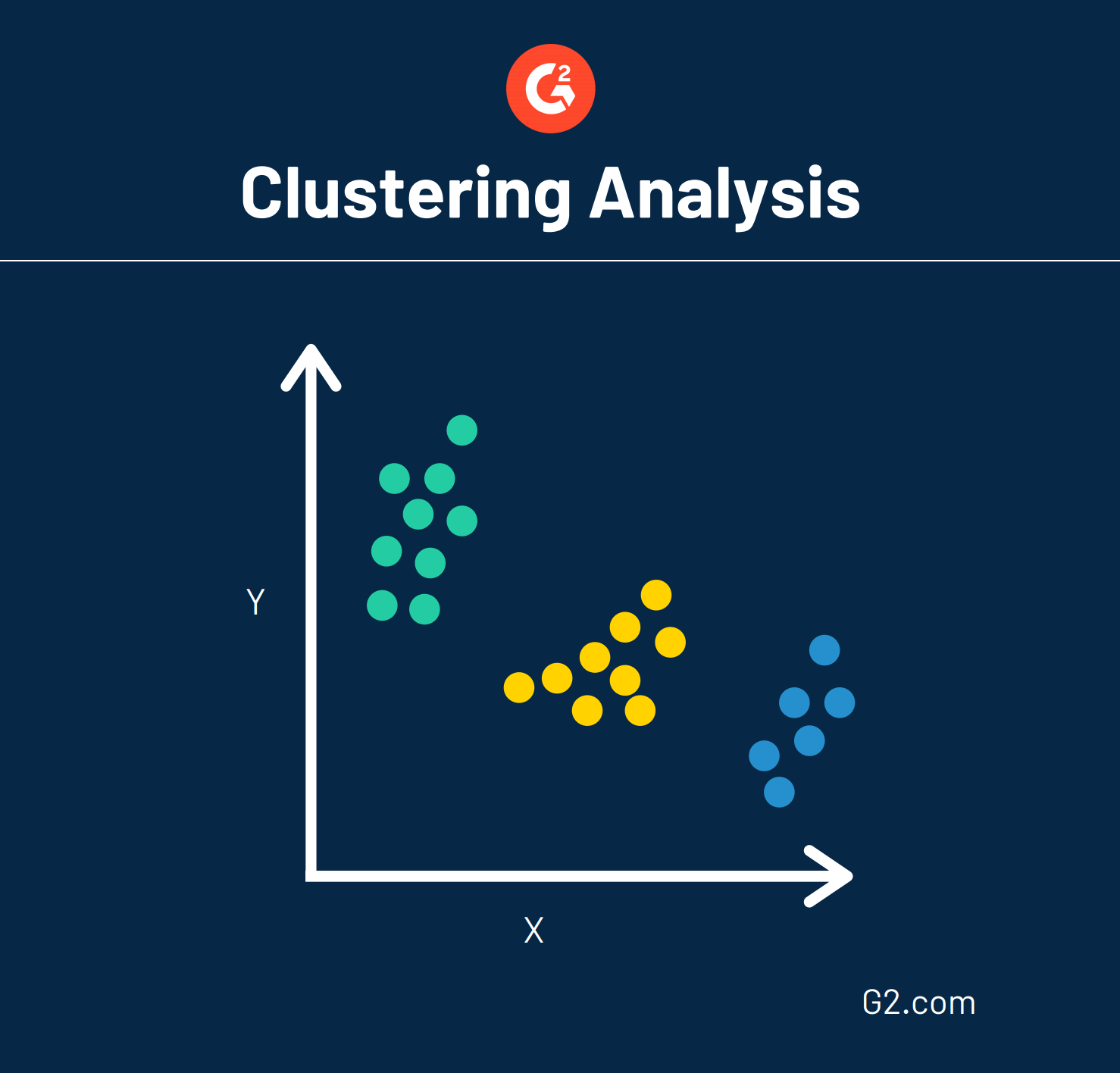
Daten, die sporadisch auf einem Diagramm verteilt sind, können durch Clusteranalyse auf strategische Weise gruppiert werden. Diese Analyse kann auch als Vorverarbeitungsschritt fungieren, was bedeutet, dass Daten so formatiert werden, dass andere Techniken leicht angewendet werden können.
Bei den Clustering-Ansätzen gibt es fünf Hauptmethoden, die von Datenwissenschaftlern verwendet werden:
- Partitionierungsalgorithmen: Erstellen verschiedener Partitionen und anschließende Bewertung anhand spezifischer Kriterien
- Hierarchiealgorithmen: Erstellen einer hierarchischen Anordnung des Datensatzes anhand spezifischer Kriterien
- Dichtebasiert: Basierend auf Konnektivitäts- und Dichtefunktionen
- Rasterbasiert: Basierend auf mehrstufigen Granularitätsstrukturen
- Modellbasiert: Ein Modell wird zuerst für jeden der Cluster angenommen, dann wird die beste Anpassung des Modells gefunden
Hand in Hand mit diesen Clustering-Ansätzen gehen fünf Clustering-Algorithmen, die verwendet werden, um jeden Datenpunkt in eine bestimmte Gruppe zu klassifizieren. Datenpunkte innerhalb derselben Gruppe haben ähnliche Eigenschaften oder Merkmale.
Diese Algorithmen sind:
- K-Means Clustering: Gruppiert Beobachtungen in Cluster, wobei jeder Datenpunkt Teil des Clusters mit dem nächstgelegenen Mittelwert ist
- Mean-Shift Clustering: Weist die Datenpunkte iterativ den Clustern zu, indem Punkte in Richtung des Modus verschoben werden. Am häufigsten in der Bildverarbeitung und Computer Vision verwendet
- Dichtebasierte räumliche Clusteranalyse von Anwendungen mit Rauschen (DBSCAN): Gruppiert Datenpunkte in einem bestimmten Raum, die nahe beieinander liegen, während spezifische Ausreißerpunkte in Regionen mit geringer Dichte innerhalb des Clusters markiert werden. Häufig in wissenschaftlicher Literatur zitiert
- Erwartungs-Maximierungs-Clustering (EM) mit Gaußschen Mischmodellen (GMM): Wird verwendet, um nicht gekennzeichnete Daten zu clustern, da es die Varianz (Breite einer Glockenkurve) berücksichtigt, um die Form der Verteilung oder des Clusters zu bestimmen
- Agglomerative hierarchische Clusteranalyse: Arbeitet daran, eine hierarchische Analyse der Cluster mit einem „Bottom-up“-Ansatz zu erstellen. Jede Beobachtung beginnt in ihrem eigenen Cluster, und Paare von Clustern werden zusammengeführt, während man die Hierarchie hinaufsteigt
Wofür wird Clustering verwendet?
Es gibt einige Möglichkeiten, Wissen aus der Clusteranalyse zu ziehen. Versicherungsunternehmen können Gruppen von Versicherungsnehmern mit hohen durchschnittlichen Schadensfällen identifizieren. Clustering kann im Marketing verwendet werden, um Kunden basierend auf den Vorteilen zu segmentieren, die sie beim Kauf eines bestimmten Produkts erleben werden.
Ein weiteres Beispiel für Clustering ist, wie Seismologen den Ursprung von Erdbebenaktivitäten und die Stärke jedes Erdbebens sehen können, um diese Erkenntnisse dann für die Gestaltung von Evakuierungsrouten anzuwenden.
Klassifikation
Klassifikation wird oft als Untergruppe des Clustering bezeichnet. Die Klassifikation besteht darin, verschiedene Attribute zu analysieren, die mit unterschiedlichen Datentypen verbunden sind. Wenn ein Unternehmen die Hauptmerkmale dieser Datentypen identifizieren kann, kann es alle damit verbundenen Daten besser organisieren und klassifizieren.
Dies ist ein wesentlicher Bestandteil der Identifizierung spezifischer Datentypen, wie z. B. wenn ein Unternehmen Dokumente mit sensiblen Informationen wie Sozialversicherungs- oder Kreditkartennummern weiter schützen möchte.
Ausreißererkennung
Auch als Anomalieerkennung bekannt, tut diese Data-Mining-Technik vielleicht das Gegenteil von Clustering. Anstatt nach großen Datenmengen zu suchen, die zusammengefasst werden könnten, sucht die Ausreißererkennung nach Datenpunkten, die selten und außerhalb einer etablierten Gruppe oder eines Durchschnitts liegen.
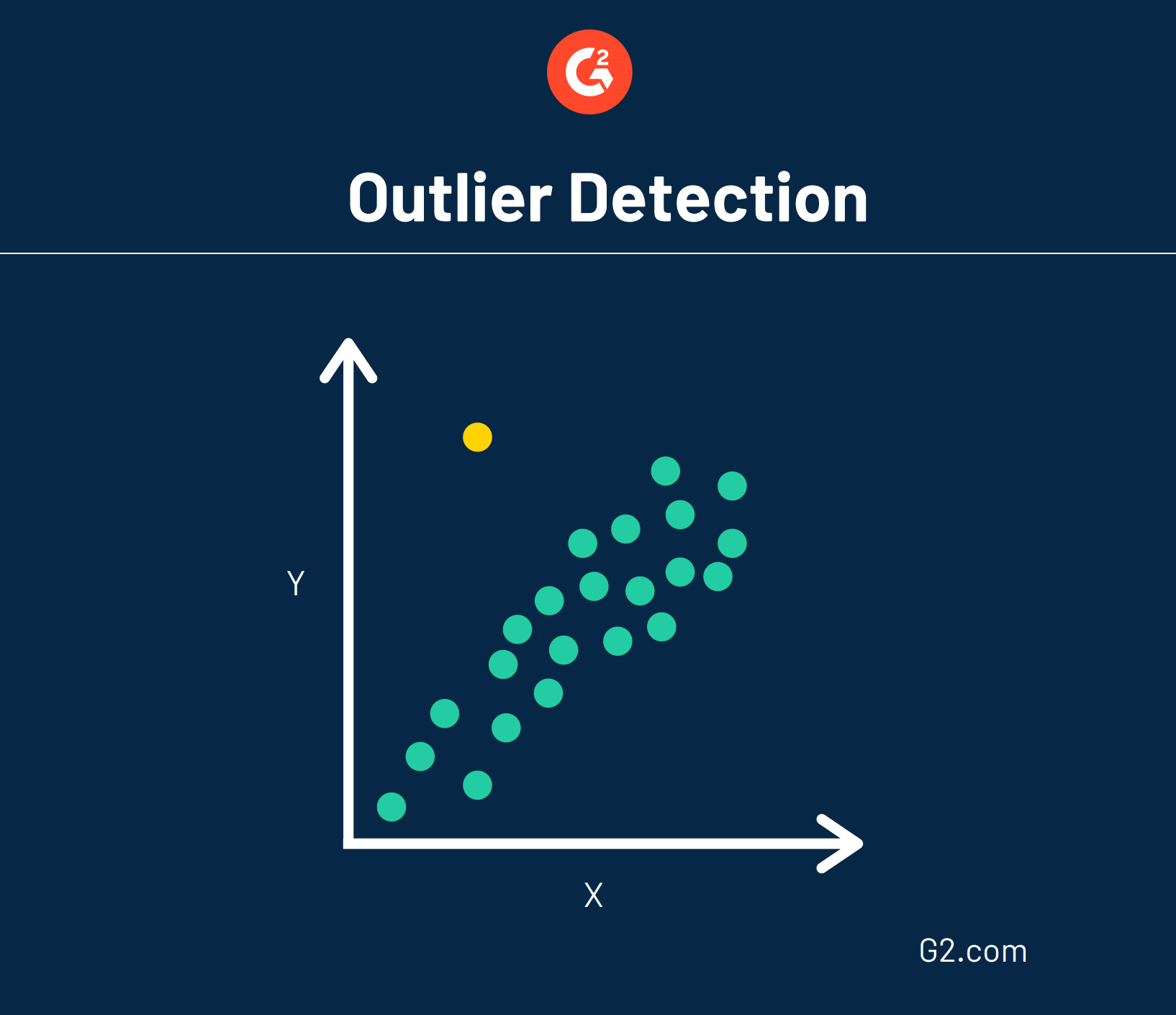
Da Daten ziemlich zufällig sind, weisen Anomalien nicht unbedingt auf einen Trend hin. Stattdessen könnten Daten, die gegen den Strich gehen, darauf hindeuten, dass etwas Ungewöhnliches vor sich geht und eine weitere Analyse erfordert.
Sobald ein Unternehmen oder eine Organisation diese Unregelmäßigkeiten in den Daten gefunden hat, wird es einfacher zu verstehen, warum diese Anomalien auftreten und sich auf zukünftige vorzubereiten.
Es gibt zwei Arten von Ausreißern:
- Univariat: ein Datenpunkt, der einen Extremwert auf einer Variablen aufweist
- Multivariat: eine Kombination ungewöhnlicher Werte auf mindestens zwei Variablen
Von diesen beiden Typen gibt es vier Ausreißertechniken:
- Numerischer Ausreißer: Ausreißererkennung in einem eindimensionalen Raum
- Z-Score: Parametrische Ausreißererkennung in einem ein- oder niedrigdimensionalen Raum
- DBSCAN: Die dichtebasierte Ausreißererkennung in einem ein- oder mehrdimensionalen Raum
- Isolation Forest: Nicht-parametrische Methode für große Datensätze in einem ein- oder mehrdimensionalen Raum
Wofür wird die Ausreißererkennung verwendet?
Die Ausreißererkennung wird am häufigsten zur Erkennung von betrügerischem Verhalten verwendet. Zum Beispiel kann die Ausreißererkennung verdächtige Kreditkartenaktivitäten identifizieren und eine Reaktion auslösen (wie z. B. das Einfrieren eines Kontos).
In einem Zeitalter, in dem Cyberangriffe robuster und häufiger sind als je zuvor, hilft die Ausreißererkennung, Datenverletzungen auf Websites zu identifizieren, damit sie schnell behoben werden können. Dies wird als Eindringungserkennung bezeichnet.
Assoziationsregel-Mining
Nach Gruppen und Ausreißern zu suchen, sind einige Möglichkeiten, Wissen zu gewinnen, aber eine andere Technik namens Assoziationsregel-Mining untersucht, wie eine Variable mit einer anderen zusammenhängt, während sie ein verborgenes Muster im Datensatz entdeckt.
Datenwissenschaftler suchen nach bestimmten Ereignissen oder Attributen, die stark mit einem anderen Ereignis oder Attribut korreliert sind. Die Erkenntnisse aus dem Assoziationsregel-Mining können Unternehmen auch dabei helfen, potenzielle Korrelationen zu identifizieren. Zum Beispiel, wenn Ereignis A eintritt, dann wird wahrscheinlich Ereignis B folgen. Wenn Ereignis A ein Schneesturm ist, können wir davon ausgehen, dass Ereignis B, die Stornierung von Flügen, wahrscheinlich als nächstes kommt. Wenn Ihnen jemals auf einer E-Commerce-Website Produkte basierend auf dem Inhalt Ihres Warenkorbs vorgeschlagen wurden, dann haben Sie Assoziationsregel-Mining in Aktion gesehen.
Zum Beispiel, das ist, was Amazon mir basierend auf Artikeln, die ich in der Vergangenheit gekauft habe, empfiehlt.

Wofür wird Assoziationsregel-Mining verwendet?
Walmart hat diese Data-Mining-Technik 2004 während des Hurrikans Frances perfekt angewendet. Durch das Mining von Transaktions- und Bestandsdaten entdeckten Analysten, dass der Verkauf von Erdbeer-Pop-Tarts siebenmal höher war, kurz bevor der Hurrikan zuschlug. Bier wurde auch als das meistverkaufte Produkt vor dem Hurrikan enthüllt. Mit diesen Informationen zur Hand war Walmart sicher, sich einzudecken. Wie Walmart können kleine und mittelständische Unternehmen diese Daten auf die gleiche Weise nutzen.
Regression
Wenn ein Unternehmen eine Vorhersage basierend auf der Wirkung einer Variablen auf andere machen möchte, kann es auf eine Data-Mining-Technik namens Regressionsanalyse zurückgreifen. Diese Datenmethode identifiziert und analysiert die Beziehung zwischen Variablen.
Denken Sie daran: Regression und Assoziation werden oft miteinander verwechselt. Die statistische Analyse-Regression ist die Gleichung, die verwendet wird, um Daten für zwei oder mehr Variablen zu spezifizieren und zu assoziieren. Assoziation ist die Beziehung zwischen zwei gemessenen Größen, die sie abhängig oder korreliert machen wird.
Wofür wird Regression verwendet?
Auf den ersten Blick sind Daten chaotisch. Es gibt viel Versuch und Irrtum, wenn man die Beziehung zwischen einem Datensatz und einem anderen untersucht – insbesondere, wenn ein Unternehmen versucht, Ereigniswahrscheinlichkeiten zu ermitteln und Vorhersagen zu treffen. Die Regressionsanalyse kann diese Vorhersagen in die richtige Richtung lenken.
Ein Beispiel für Regressionsanalyse in der Gesundheitsbranche ist die Untersuchung der Auswirkungen, die der Body-Mass-Index oder BMI auf andere Variablen hat. Sie würden auch Regression verwenden, um zu bestimmen, wie der Preis eines Produkts die Anzahl der Verkäufe Ihres Unternehmens beeinflussen wird oder wie die Menge an Niederschlag das Wachstum von Pflanzen beeinflussen wird.
Lineare Regression
Eine häufige Art der Regression wird als lineare Regression bezeichnet.
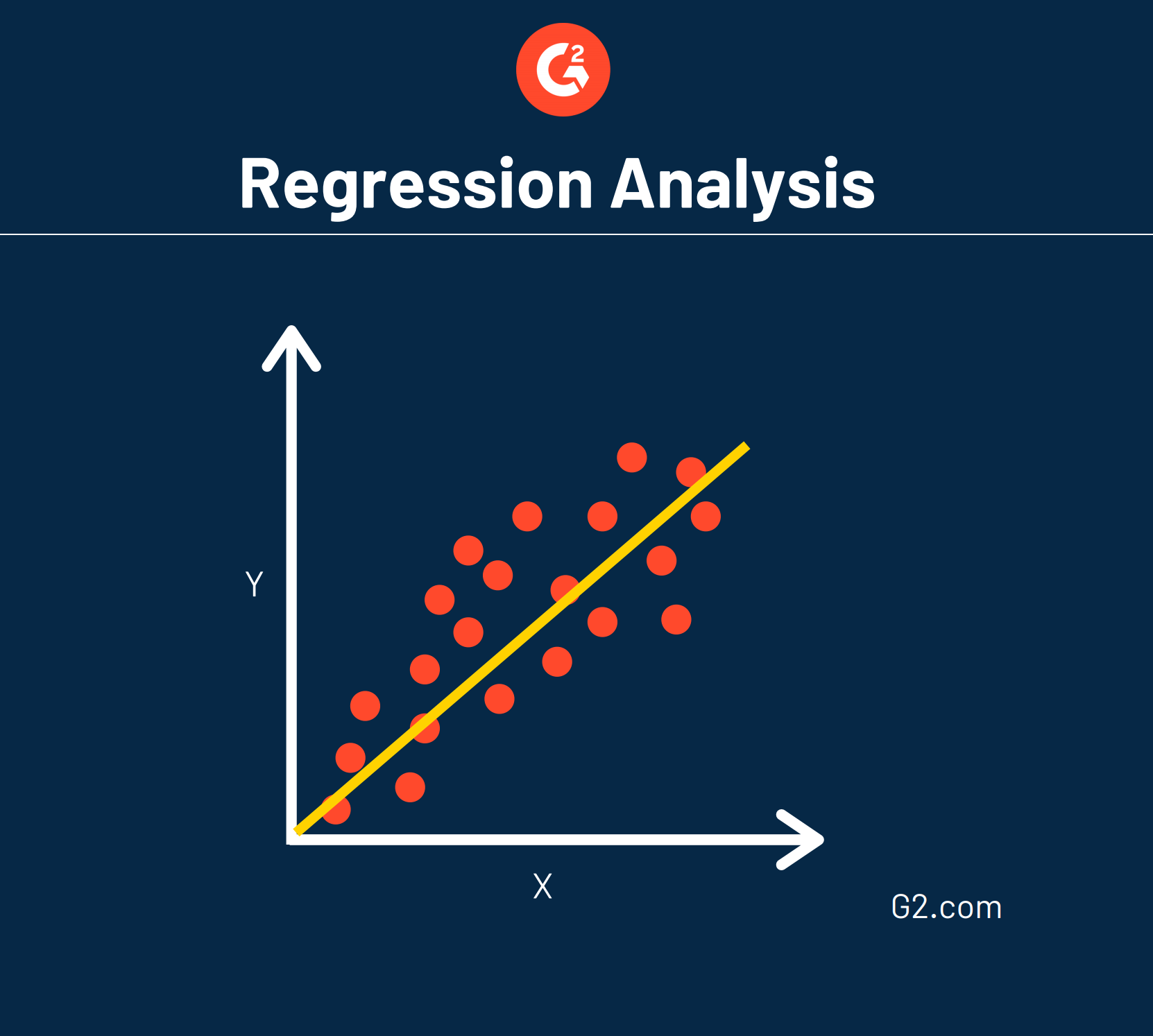
Das bedeutet, dass eine gerade Linie gezeichnet werden kann, um zu zeigen, wie jede Variable miteinander in Beziehung steht.
Verwandt: Erfahren Sie mehr über Regression, den Unterschied zwischen Korrelation und Regression und wann Sie diese beiden statistischen Messungen verwenden sollten.
Entscheidungsbaum
Einer der visuelleren Data-Mining-Techniken wird als Entscheidungsbaumanalyse bezeichnet und ist eine beliebte Methode für wichtige Entscheidungsfindungen.
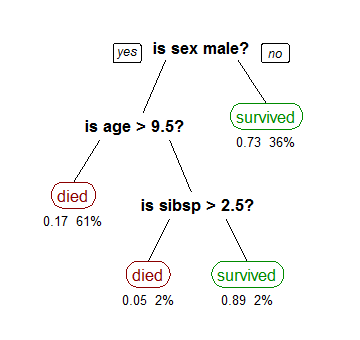
Quelle: Research Gate
Es gibt zwei Arten von Entscheidungsbaumanalysen. Eine davon wird als Klassifikation bezeichnet, was Sie im obigen Beispiel sehen, um zu bestimmen, ob ein Passagier auf der Titanic überlebt hätte oder nicht. Die Klassifikation basiert auf Logik und verwendet eine Vielzahl von Wenn/Dann- oder Ja/Nein-Bedingungen, bis alle relevanten Daten abgebildet sind.
Diese Bäume bestehen aus drei verschiedenen Elementen:
- Wurzelknoten: der oberste Knoten, der das ultimative Ziel oder die Entscheidung darstellt, die Sie treffen möchten.
- Äste: die von der Wurzel ausgehen, repräsentieren verschiedene Optionen oder Handlungswege, die üblicherweise durch einen Pfeil dargestellt werden.
- Blattknoten: die an den Enden der Äste befestigt sind, repräsentieren die möglichen Ergebnisse für jede Aktion. Ein quadratischer Knoten zeigt an, dass eine weitere Entscheidung getroffen werden muss, während ein kreisförmiger Blattknoten ein Zufallsereignis oder unbekanntes Ergebnis anzeigt.
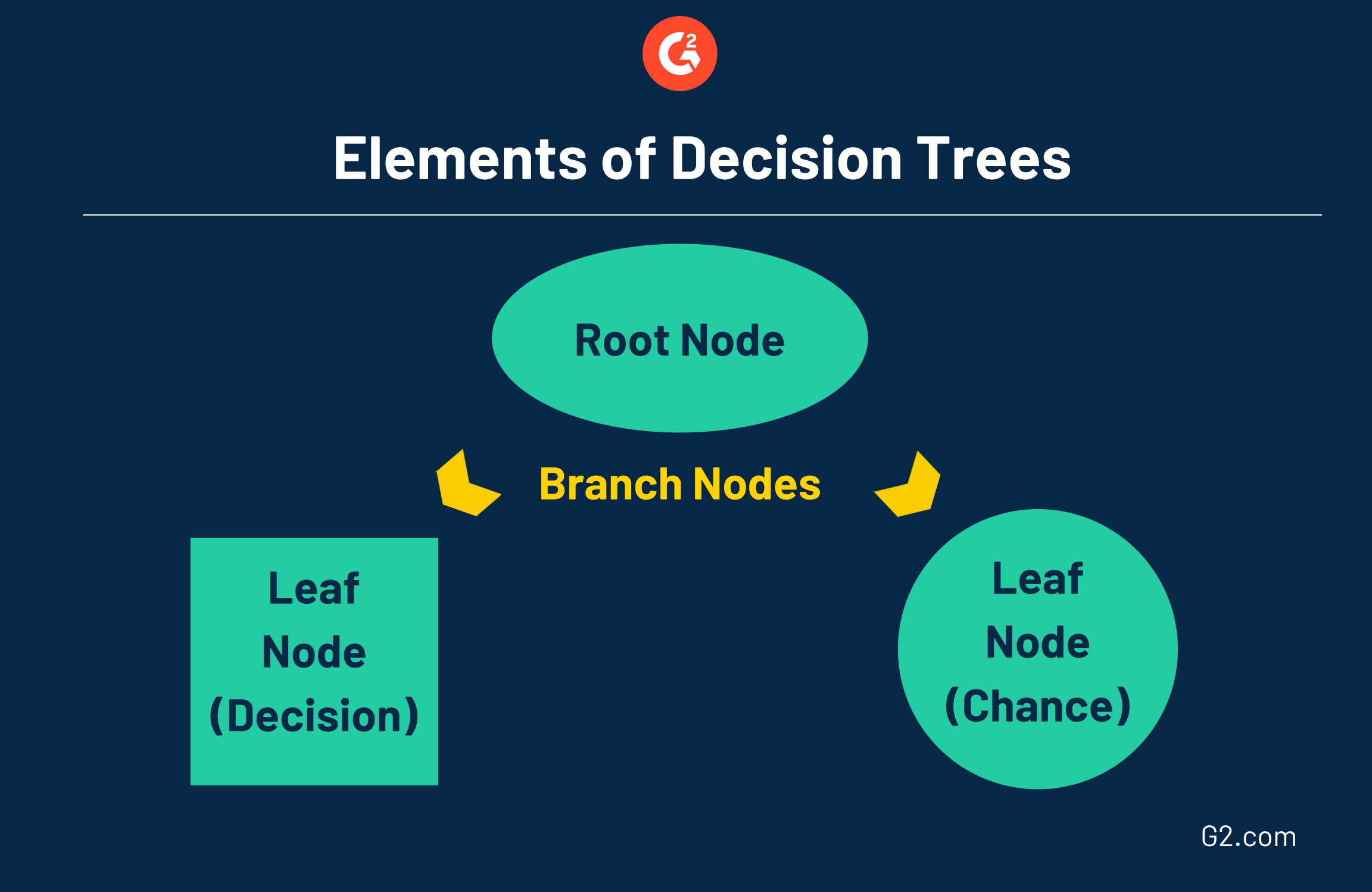
Der andere Entscheidungsbaum wird als Regression bezeichnet, der verwendet wird, wenn die Zielentscheidung ein numerischer Wert ist. Zum Beispiel könnte Regression verwendet werden, um den Wert eines Hauses zu bestimmen. Beide Entscheidungsbäume können durch maschinelle Lernprogramme ausgeführt werden.
Unsicher, welche Maschinelles Lernen Software Sie für Ihren Entscheidungsbaum verwenden sollen? Schauen Sie sich Hunderte von unvoreingenommenen Bewertungen an, die Ihnen kostenlos von G2 zur Verfügung gestellt werden!
Ein Entscheidungsbaum ermöglicht es einem Benutzer, klar zu verstehen, wie die Dateneingaben die Ausgaben beeinflussen. Wenn mehr als ein Entscheidungsbaum für eine Vorhersageanalyse kombiniert wird, wird dies als Random Forest bezeichnet. Wenn ein Random-Forest-Modell zu komplex wird, wird es als Black-Box-Maschinenlerntechnik bezeichnet, da es schwierig ist, ihre Ausgaben basierend auf den Eingaben zu verstehen.
Vorhersage
Wie der Name schon sagt, verwendet die Vorhersage oder prädiktive Analyse eine Kombination anderer Data-Mining-Techniken, wie Clustering und Klassifikation, um vergangene Ereignisse oder Instanzen in der richtigen Reihenfolge zu analysieren, um ein zukünftiges Ereignis vorherzusagen.
In den meisten Fällen reicht es aus, historische Trends zu erkennen und zu verstehen, um eine genaue Vorhersage darüber zu treffen, was in der Zukunft passieren könnte. Es gibt viele Ansätze zur Vorhersageanalyse, von maschinellem Lernen bis hin zu künstlicher Intelligenz. Eine genaue Vorhersage hängt jedoch nicht von diesen beiden Techniken ab; sie kann auch durch verschiedene Algorithmen bestimmt werden.
Wofür wird Vorhersage verwendet?
Viele Organisationen verwenden Vorhersagen, um Einblicke in die nächsten Trends in ihren Daten zu erhalten. Wie die Ausreißererkennung kann auch die prädiktive Analyse Betrug, Zero-Day-Schwachstellen und persistente Bedrohungen erkennen. Ein spezifisches Beispiel ist, wie Staples Vorhersagen verwendet hat, um das Verhalten zu analysieren und ein vollständiges Bild ihrer Kunden zu erhalten, was zu einem 137%igen Anstieg des ROI führte.
Datenvisualisierung
Datenvisualisierung arbeitet daran, Benutzern zusätzliche Einblicke in ihre Informationen zu geben, indem sie Diagramme und Grafiken in Echtzeit verwendet, um Leistungsziele besser zu verstehen. Diese Technik ist beliebt, weil die Datenvisualisierung in der Lage ist, Daten aus jeder Quelle durch Datei-Uploads, Datenbankabfragen und Anwendungskonnektoren zu konsumieren.
Wie wird Datenvisualisierung heute verwendet?
Dank der Dashboards, die mit Datenvisualisierungssoftware erstellt wurden, ist es einfacher denn je, verschiedene Einblicke, Trends und KPIs in Daten zu finden. Viele dieser Tools bieten Drag-and-Drop-Funktionalität und andere nicht-technische Fähigkeiten, sodass der durchschnittliche Geschäftsanwender notwendige Dashboards erstellen kann.
Diese Art von Software wird von Führungskräften auf C-Ebene und Teams in den Bereichen Vertrieb, Marketing, Kundenservice und Personalwesen verwendet. Zum Beispiel würde Ihr Vertriebsteam diese Software verwenden, um Umsatzzahlen für abgeschlossene Geschäfte zu verfolgen, während Marketingteams diese Tools verwenden, um Webverkehr, E-Mail-Kampagnen und Social-Media-Impressionen zu analysieren.
Verwandt: Erfahren Sie mehr über die 67 Arten von Datenvisualisierungen, die Ihr Unternehmen verwenden kann, um das größere Bild zu sehen.
Neuronale Netze
Neuronales Lernen ist ein spezifisches Modell des maschinellen Lernens und eine statistische Technik, die oft in Verbindung mit künstlicher Intelligenz und Deep Learning verwendet wird und einige der genauesten Modelle des maschinellen Lernens sind, die wir heute verwenden.
Diese Data-Mining-Technik wurde in den 1940er Jahren benannt, als sie entdeckt wurde, weil sie verschiedene Schichten hat, die alle den Arbeitsweisen von Neuronen im menschlichen Gehirn ähneln. Trotz ihrer Genauigkeit sollten Organisationen, die neuronale Netze verwenden, sich der Tatsache bewusst sein, dass einige dieser Modelle extrem komplex sind, was es schwierig macht, zu verstehen, wie das Ergebnis bestimmt wird.
Tatsächlich sind einige neuronale Netze so unglaublich komplex, dass sie bis zu 150 versteckte Schichten haben. Jede Schicht spielt eine Schlüsselrolle beim Aufschlüsseln von Merkmalen roher Daten. Dies wird formell als Merkmalsextraktion bezeichnet.
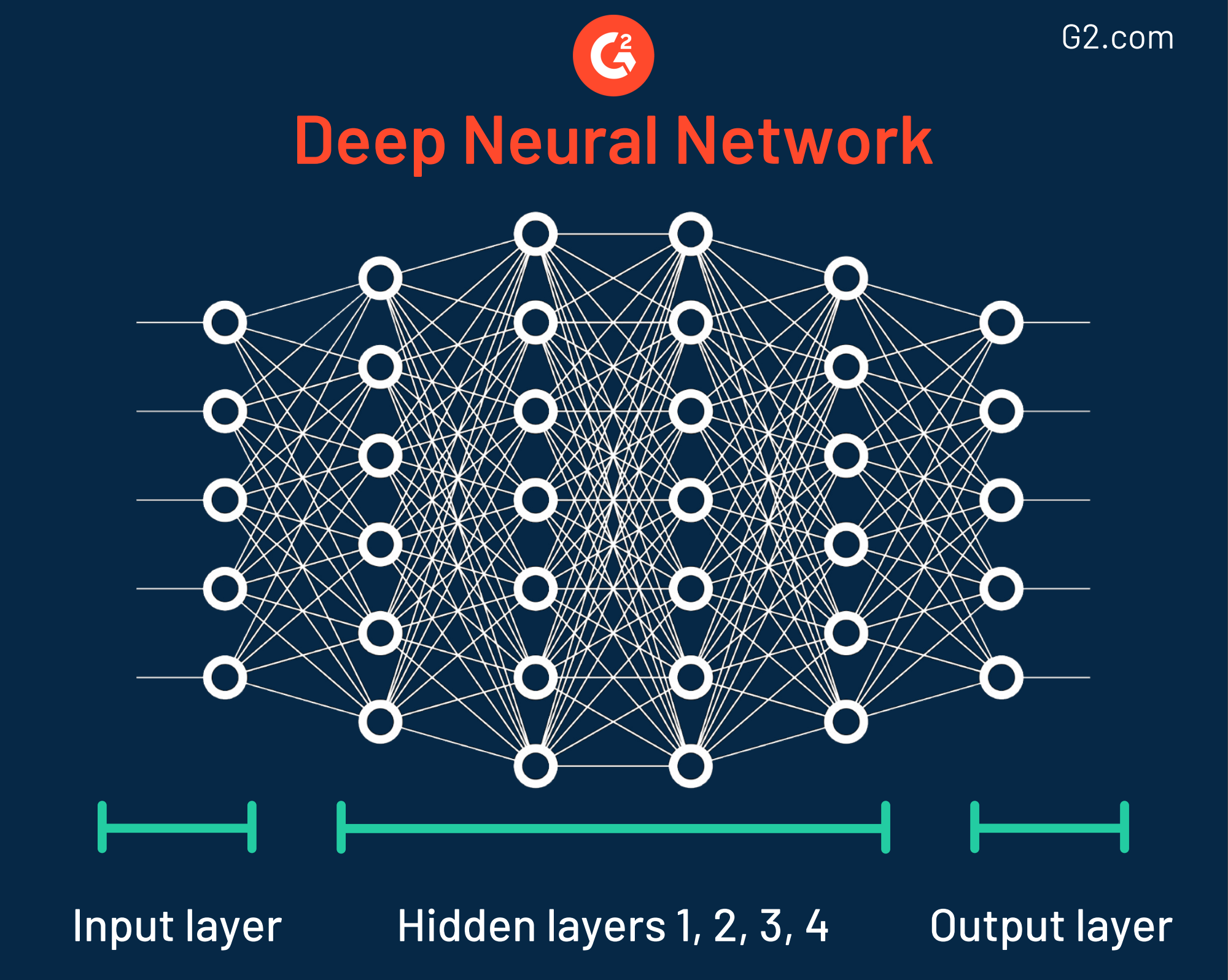
Wie werden neuronale Netze heute verwendet?
Neuronale Netze mit nur wenigen Schichten werden in Banken und Postämtern verwendet, um Handschriftenstile zu erkennen. Dies ist nützlich, wenn Sie Schecks mit Ihrem Mobiltelefon einlösen.
Komplexere neuronale Netze mit vielen Schichten werden derzeit entwickelt, um fahrerlose Autos zu entwickeln. Das Extrahieren von Elementen von der Straße, das Erkennen von Zebrastreifen und Verkehrsschildern und das Verstehen von Bewegungsmustern anderer Fahrzeuge sind nur einige der vielen Arten von Rohdaten, die in komplexen neuronalen Netzen Stück für Stück aufgeschlüsselt werden.
Hauptkomponentenanalyse
Die Data-Mining-Technik Hauptkomponentenanalyse (PCA) wird verwendet, um versteckte Verbindungen zwischen Eingabevariablen zu veranschaulichen, da sie neue Variablen erstellt, die dieselben Informationen visualisieren, die mit den ursprünglichen Daten erfasst wurden, jedoch mit weniger Variablen. Im Wesentlichen kombiniert diese Methode korrelierte Informationen, um eine kleinere Anzahl von Variablen zu bilden, die als „Hauptkomponenten“ bezeichnet werden und den größten Teil der Varianz in den Daten ausmachen.
Der Zweck der Reduzierung der Anzahl der Variablen, während dieselbe Menge an Informationen vermittelt wird, besteht darin, dass Datenanalysten die Genauigkeit von überwachten Data-Mining-Modellen verbessern können. Im Wesentlichen macht es Ihre Daten einfach zu erkunden und zu visualisieren.
Wie wird die Hauptkomponentenanalyse heute verwendet?
PCA wird am häufigsten von Personen im Finanzsektor verwendet, die verschiedene Zinssätze durchführen und analysieren. Personen, die mit Aktien und dem Aktienmarkt arbeiten, verwenden PCA auch, um zu bestimmen, welche Aktien gehandelt werden sollen und wann.
Musterverfolgung
Wenn es um Data-Mining-Techniken geht, ist die Musterverfolgung eine grundlegende. Die Musterverfolgung beinhaltet das Identifizieren und Überwachen von Trends und Mustern in Daten, um eine kluge und kalkulierte Annahme über Geschäftsergebnisse zu treffen.
Wann wird die Musterverfolgung heute verwendet?
Angenommen, eine Organisation identifiziert einen Trend in ihren Verkaufsdaten und verwendet ihn als Ausgangspunkt, um auf einer bestimmten Erkenntnis Kapital zu schlagen. Wenn die Daten zeigen, dass ein bestimmtes Produkt für eine bestimmte demografische Gruppe besser verkauft wird als andere, könnten sie beschließen, diese Daten zu nutzen, um ähnliche Produkte oder Dienstleistungen zu erstellen. Ebenso könnten sie sich entscheiden, das ursprüngliche Produkt für diese demografische Gruppe besser zu lagern.
Datenlagerung
Auch als Enterprise Data Warehousing bekannt, beinhaltet die Datenlagerung das Speichern strukturierter Daten in relationalen Datenbankmanagementsystemen, damit sie für die Berichterstattung und Business Intelligence analysiert werden können. Die heutigen Data-Mining- und Datenlagerungstechniken nutzen sowohl Cloud-Datenlager für eine sicherere Speicherung dieser Erkenntnisse.
Die in diesen Lagern gespeicherten Informationen können verwendet werden für:
- Optimierung von Produktionsstrategien: Vergleich von Produktverkäufen entweder vierteljährlich oder jährlich, um Portfolios zu verwalten und Produkte neu zu positionieren
- Kundenanalyse: Ein tieferer Einblick in die Kaufpräferenzen der Kunden, Budgetzyklen, Kaufzeiten und mehr
- Betriebsanalyse: Hilft bei der Analyse von Geschäftsabläufen, Kundenbeziehungen und wie man richtige Umweltverbindungen herstellt
Wie wird die Datenlagerung heute verwendet?
Die Investment- und Versicherungsbranche nutzt die Datenlagerung, um Datenmuster, Kundentrends und Marktbewegungen zu analysieren. Der Einzelhandel verwendet Datenlager, um Artikel, Kundenkaufmuster, Werbeaktionen und zur Bestimmung der Preispolitik zu verfolgen.
Entdecken Sie das Unbekannte
Die Verwendung der richtigen Data-Mining-Technik wird sicher beispiellose Einblicke in Ihren Datenreichtum bieten. Da die Technologie immer fortschrittlicher wird, wird das Data Mining nur weiter wachsen und tiefere Einblicke finden.
Krempeln Sie die Ärmel hoch und tauchen Sie tief in das ein, was Ihre Daten Ihnen zeigen; Sie könnten überrascht sein, was Sie finden.
Gehen Sie all dieses Wissen einen Schritt weiter und erfahren Sie mehr über Business Analytics und wie es verwendet werden kann, um Erfolg zu erzielen.
Möchten Sie mehr über Maschinelles Lernsoftware erfahren? Erkunden Sie Maschinelles Lernen Produkte.

Mara Calvello
Mara Calvello is a Content and Communications Manager at G2. She received her Bachelor of Arts degree from Elmhurst College (now Elmhurst University). Mara writes content highlighting G2 newsroom events and customer marketing case studies, while also focusing on social media and communications for G2. She previously wrote content to support our G2 Tea newsletter, as well as categories on artificial intelligence, natural language understanding (NLU), AI code generation, synthetic data, and more. In her spare time, she's out exploring with her rescue dog Zeke or enjoying a good book.

