


Os humanos são dotados de visão periférica; mas os computadores estão se tornando competentes em detecção de objetos agora.
Seja o Autopilot da Tesla ou os aspiradores Deebot, os dispositivos de computação são alimentados com novos algoritmos de IA generativa para acelerar o poder de processamento e nomear objetos físicos. Conhecida como detecção de objetos em resumo, essa simulação de visão projetada com software de reconhecimento de imagem passou o bastão da visão e da percepção para os computadores.
O principal objetivo da detecção de objetos é segmentar, localizar e anotar objetos físicos ou digitais com precisão infalível para completar uma tarefa designada.
A detecção de objetos abriu novos caminhos de assistência robótica que visam fabricar dispositivos de autoajuda para facilitar tarefas tediosas. Vamos aprender sobre isso em detalhes.
O que é detecção de objetos?
A detecção de objetos é uma abordagem de IA restrita que identifica, classifica e localiza objetos em fotografias ou vídeos digitais. O principal objetivo da detecção de objetos é detectar as instâncias de cada objeto, segmentá-los e analisar suas características necessárias para categorização em tempo real e modularidade aprofundada.
A detecção de objetos é parte da arquitetura de banco de dados de uma empresa. Algumas empresas adotaram com sucesso essa tecnologia, enquanto outras estão esperando para anunciá-la como uma técnica de gerenciamento de banco de dados bem-sucedida.
Exemplos principais de detecção de objetos incluem segurança e vigilância, controle de acesso, presença biométrica, monitoramento de condições de estradas, máquinas de autoajuda e proteção de fronteiras marítimas.
Como funciona a detecção de objetos?
A detecção de objetos funciona de forma semelhante ao reconhecimento de objetos. A única diferença é que o reconhecimento de objetos é o processo de identificar a categoria correta do objeto, enquanto a detecção de objetos simplesmente detecta a presença e a localização do objeto em uma imagem.
As tarefas de detecção de objetos podem ser realizadas usando duas técnicas diferentes de análise de dados.
- Processamento de imagem é parte do aprendizado não supervisionado que não requer dados de treinamento históricos para ensinar modelos analíticos. Os modelos se auto-treinam nas imagens de entrada e criam mapas de características para fazer previsões. O processamento de imagem não requer alto poder de processamento gráfico ou grandes conjuntos de dados para execução.
- Rede neural profunda: Uma rede neural profunda é geralmente um algoritmo de aprendizado supervisionado que requer grandes conjuntos de dados e alto poder de computação de GPU para prever classes de objetos. É uma maneira mais precisa de classificar objetos parcialmente ocultos, complexos ou colocados em fundos desconhecidos em uma imagem.
Treinar uma rede neural profunda é uma tarefa trabalhosa e cara. No entanto, alguns conjuntos de dados em grande escala fornecem a disponibilidade de dados rotulados.
Você sabia? COCO, um conjunto de dados de detecção, segmentação e legendagem de objetos em grande escala, pode ser usado para treinar uma rede neural profunda.
Algumas características que você pode esperar do MS COCO:
- Segmentação de objetos
- Reconhecimento em contexto
- Segmentação de superpixel
- Pré-treinado em 33 mil imagens
- 1,5 milhão de instâncias de objetos
- 80 classes de objetos
- 91 categorias de "coisas"
- 5 legendas por imagem
- 250.000 pessoas com pontos-chave
Quer aprender mais sobre Software de Reconhecimento de Imagem? Explore os produtos de Reconhecimento de Imagem.
Importância da detecção de objetos
Tendo entendido a metodologia de trabalho, é hora de discutir o que torna a detecção de objetos importante.
A detecção de objetos forma a base para outras técnicas importantes de visão de IA, como classificação de imagens, recuperação de imagens, processamento de imagens ou co-segmentação de objetos, que extraem informações significativas de objetos da vida real. Desenvolvedores e engenheiros estão usando essas técnicas para construir máquinas futuristas que entregam mantimentos e medicamentos em nossas portas!
Um algoritmo de detecção de objetos pode detectar automaticamente movimentos de gado, sinais de trânsito e faixas de estrada para que veículos autônomos possam chegar aos seus destinos. Isso, por sua vez, elimina a necessidade de motoristas para realizar tarefas logísticas.

A detecção de objetos também pode ser executada em redes móveis, podando as camadas de uma rede neural profunda. Já está sendo usada em scanners de segurança ou detectores de metais em aeroportos para detectar objetos indesejados e ilegais.
Além disso, as empresas usam a detecção de objetos para contagem de pessoas, reconhecimento de placas de veículos, reconhecimento de fala e detecção de evidências. No entanto, uma ligeira falta de precisão às vezes prejudica sua eficiência em detectar objetos minuciosos. A falta de precisão de cem por cento torna-a menos preferível para domínios críticos como mineração e militar.
Classificação de imagem vs. detecção de objetos
A detecção de objetos é frequentemente confundida com a classificação de imagens. Embora sejam lados do mesmo cubo de Rubik, aqui estão algumas diferenças notáveis.
-png.png)
Classificação de imagem é um conceito simples de categorizar uma imagem multiespectral com base em seus componentes. Se você receber uma imagem de um cachorro, o modelo de classificação de imagem pode interpretar suas características principais e rotular a imagem como "cachorro" facilmente. Se uma imagem contiver dois objetos, como um gato e um cachorro, o modelo usa um classificador de múltiplos rótulos para classificar ambos os objetos.
O modelo de classificação de imagem não aceita nenhuma variável para localização de objetos além de definir a classe do objeto. É aqui que a detecção de objetos entra em cena.
Um algoritmo de detecção de objetos pode identificar a classe do objeto e prever a localização exata dos objetos em uma imagem, desenhando caixas delimitadoras ao redor deles. É uma combinação de classificação de imagem e localização de objetos que permite ao sistema saber onde os objetos estão colocados em uma imagem e por quê. Ele capacita um sistema a analisar visualmente cada objeto e determinar sua aplicação na vida real, assim como os humanos fazem.
Modelos de detecção de objetos
As abordagens mais preferidas para detecção de objetos são aprendizado de máquina ou aprendizado profundo. Ambos os métodos funcionam em conjunto com uma máquina de vetores de suporte (SVM) para extrair as características, treinar o algoritmo, e categorizar objetos.
A detecção de objetos não é possível sem um conjunto de dados adequado. Os conjuntos de dados cobrem as principais características conhecidas de um objeto, como localização, dimensões, categoria ou cores. Na prática, se um modelo de detecção de objetos for pré-treinado em um conjunto de dados de algo com rodas, um para-brisa, piscas, um motor e um porta-malas, ele pode classificar com precisão o objeto na imagem dada como um carro.
Diferentes tipos de métodos de detecção de objetos têm diferentes níveis de eficácia e aplicabilidade em diferentes indústrias. Vamos entender isso em detalhes:
Aprendizado de máquina
O ponto positivo de usar um algoritmo de aprendizado de máquina para realizar a detecção de objetos é que ele se baseia em dados inseridos manualmente para classificação, não em dados de treinamento automáticos. Isso torna o algoritmo geral menos propenso a erros e mais estável.
A detecção de objetos é um problema de aprendizado de máquina supervisionado, o que significa que você deve usar modelos pré-treinados para acionar detectores de objetos. A lista de classes no conjunto de dados de treinamento de um algoritmo de ML deve pertencer a uma imagem específica ou lista de imagens.
Abordagens de aprendizado de máquina como processamento de linguagem natural (NLP) identificam e classificam objetos com base em sua intensidade de iluminação contra um fundo. Algoritmos de ML para objetos 2D também podem ser reutilizados para detectar objetos 3D em imagens.
Características de canal agregado (ACF)
ACF é um método de aprendizado de máquina que reconhece objetos específicos em uma imagem com base em um conjunto de dados de imagens de treinamento e nas localizações dos objetos. É usado principalmente para detecção de objetos em múltiplas vistas, como identificar objetos 3D capturados de três câmeras. Veículos de autoajuda, detecção de pedestres e detecção facial funcionam nesse princípio.
ACF combina diferentes canais que extraem características de uma imagem como gradientes ou pixels, em vez de recortar uma imagem em várias localizações. Canais comuns incluem escala de cinza ou RBG, dependendo da dificuldade do problema de detecção de objetos. ACF oferece uma compreensão mais rica dos objetos e acelera a velocidade de detecção para maior precisão.
Dica: Para criar um detector de objetos ACF, declare e defina uma função de programação MATLAB, "trainACFObjectDetector()" e carregue as imagens de treinamento. Teste a precisão da detecção em uma imagem de teste separada.
Detecção de objetos DPM
O modelo de partes deformáveis (DPM) é uma abordagem de aprendizado de máquina que reconhece objetos com uma mistura de modelos gráficos e partes deformáveis da imagem. Ele contém quatro componentes principais:
- Um filtro de raiz grosseiro define várias caixas delimitadoras em uma imagem para capturar os objetos.
- Filtros de partes cobrem os fragmentos dos objetos e os transformam em setas de pixels mais escuros.
- Um modelo espacial armazena a localização de todos os fragmentos de objetos em relação às caixas delimitadoras no filtro de raiz.
- Um regressor diminui a distância entre as caixas delimitadoras e a verdade do solo para prever objetos com precisão.

Fonte: lilianweng.github.io/
Dica: Extrair características importantes de objetos salientes pode ser útil ao coletar dados de canteiros de obras para acompanhar o progresso do trabalho ou aplicar saúde e segurança ambiental durante o trabalho.
Aprendizado profundo
Enquanto os modelos de aprendizado de máquina são construídos com seleção manual das características, os fluxos de trabalho de aprendizado profundo vêm com seleção automática de características para se adequar ao seu conjunto tecnológico. Abordagens de aprendizado profundo como modelos de redes neurais convolucionais produzem previsões de objetos mais rápidas e precisas. Claro, você precisa de uma unidade de processamento gráfico (GPU) mais alta e conjuntos de dados maiores para que isso aconteça!
O aprendizado profundo é usado para uma variedade de tarefas de detecção de objetos. Câmeras de vigilância modernas ou sistemas de monitoramento são alimentados por redes neurais para detectar com sucesso rostos ou objetos desconhecidos.
Aqui estão algumas abordagens de aprendizado profundo para lidar com a detecção de objetos.
Você Só Olha Uma Vez (YOLO)
YOLO é uma estrutura de detecção de objetos de estágio único dedicada a aplicações industriais. Seu design eficiente e alto desempenho o tornam amigável ao hardware e eficiente. É uma CNN treinada em grandes bancos de dados visuais como image nets e pode ser codificada em editores de código aberto no TensorFlow, Darknet ou Python.
YOLO produz detecções de objetos de última geração a uma velocidade impressionante de 45 quadros por segundo. Até o momento, diferentes versões do YOLO, como YOLOv1, YOLOv2 ou YOLOv3, foram lançadas.
A versão mais recente, YOLOv6, pode ser treinada em conjuntos de dados personalizados no PyTorch via interfaces de programação de aplicativos (APIs). Pytorch é um pacote Python e uma das formas mais preferidas de pesquisa em aprendizado profundo. YOLOv6 é treinado exclusivamente para detectar veículos em movimento na estrada.
Você sabia? YOLO ou redes neurais convolucionais baseadas em região (R-CNN) usam a função de precisão média ou mAP(). Ela compara uma caixa delimitadora de solo com uma caixa detectada real e retorna uma probabilidade ou pontuação de confiança. Quanto maior a pontuação, mais precisa é a previsão.
SSD (Detetor de Tiro Único)
SSD é um detector de objetos personalizado sem uma rede de proposta de região específica (diferentes partes de uma imagem agrupadas em uma rede) para previsão de objetos. Ele prevê a localização e o tipo de objeto de uma imagem diretamente em uma única passagem por uma gama de camadas de um modelo de aprendizado profundo.
O SSD é bifurcado em duas partes:
1. Backbone
O backbone da rede de classificação de imagem pré-treinada extrai as características da imagem para identificar a imagem. Essas redes, como ResNet, são treinadas em ImageNets (grandes bancos de dados de imagens) e separadas da camada interna de classificação de imagem. Isso deixa o modelo backbone como uma rede neural profunda, treinada exclusivamente em milhões de imagens para extrair informações semânticas da imagem de entrada enquanto preserva a estrutura espacial da imagem.
Para ResNet34, o backbone cria mapas de características 256x7x7 para qualquer imagem de entrada.
2. Cabeça
A cabeça do modelo de detecção de objetos é apenas uma camada de cérebro de rede neural adicionada ao backbone que ajuda no processo de regressão final da imagem. Ela fornece a localização espacial do objeto e a combina com a classe do objeto nas etapas finais do SSD.
Fonte:developers.arcgis.com
Outros componentes importantes
Aqui estão os componentes importantes que compõem um modelo SSD para realizar a detecção de objetos em tempo real.
- Célula de grade: Assim como o algoritmo YOLO, o algoritmo SSD divide a caixa delimitadora em uma grade 5x5. Cada célula de grade é responsável por fornecer a forma, localização, cor e rótulo do objeto que contém.
- Caixa âncora: À medida que a CNN divide a imagem em uma grade, cada célula na grade é atribuída a mais de uma caixa âncora. O modelo SSD usa uma técnica de correspondência de modelos durante o período de treinamento para corresponder a caixa delimitadora com cada objeto de verdade do solo da imagem.

Fonte: pyimagesearch.com
Aqui, a caixa delimitadora prevista é desenhada em vermelho, enquanto a caixa delimitadora de verdade do solo (rotulada manualmente) está em verde. Como há um alto grau de sobreposição, esta caixa âncora é responsável por identificar a presença de objetos. A Interseção sobre União (IoU) aqui pode ser medida como
- Proporção: Cada objeto tem uma forma e configuração diferentes. Alguns são mais arredondados e maiores, enquanto outros são encolhidos e mais curtos. A arquitetura SSD ajuda a declarar proporções de antemão através de um parâmetro de proporção.
- Nível de zoom: O parâmetro de zoom pode ampliar objetos menores em cada célula de grade para identificar sua presença, categoria e localização. Por exemplo, se precisarmos identificar um prédio e um parque de um helicóptero, precisamos escalar o algoritmo SSD de forma que ele detecte tanto os objetos maiores quanto os menores.
- Campo receptivo: O campo receptivo é definido como o conjunto móvel de pixels da imagem em que o algoritmo está atualmente trabalhando. Diferentes camadas de um modelo CNN computam diferentes regiões de uma imagem de entrada. À medida que vai mais fundo, o tamanho do objeto aumenta. Assim como um microscópio, um modelo CNN amplia cada pixel do objeto para computar a qual categoria ele pertence.
Interseção sobre União (IoU): Área de sobreposição / Área de união
EfficientNet
EfficientNet é uma arquitetura de rede neural convolucional que escala uniformemente todas as dimensões de um objeto antes de detectá-las. Essas redes neurais são desenvolvidas a um custo fixo de software de aplicação. Sobre a disponibilidade de recursos, os algoritmos EfficientNet podem ser escalados em um domínio de aplicação para alcançar melhores resultados de detecção de objetos.
EfficientNet é considerado um dos melhores modelos CNN existentes para detecção de objetos, pois alcançou precisão de última geração em conjuntos de dados de aprendizado como Flores (98,8%) enquanto é 6,1x mais rápido do que outros modelos de detecção de objetos.
Mask R-CNN
Isso estende o Faster R-CNN ao agrupar a rede de proposta de região e a CNN pré-treinada como AlexNet. Uma rede de proposta de região é uma rede de regiões separadas por caixas delimitadoras. Mask R-CNN extrai características da imagem e cria mapas de características para detectar a presença de objetos. Ele também gera uma máscara de alta qualidade (caixa delimitadora) para cada objeto para separá-lo do restante.
Como funciona o Mask R-CNN?
Mask R-CNN foi construído usando Faster R-CNN e Fast R-CNN. Enquanto o Faster R-CNN tem uma camada softmax que bifurca as saídas em duas partes, uma previsão de classe e um deslocamento de caixa delimitadora, o Mask R-CNN é a adição de um terceiro ramo que descreve a máscara do objeto, que é a forma do objeto. É distinto de outras categorias e requer a extração das coordenadas gráficas do objeto para prever com precisão a localização.
Mask R-CNN é uma combinação de duas CNNs que funciona agrupando em uma camada de máscara de objeto, também conhecida como Região de Interesse (ROI), paralela ao localizador de caixa delimitadora existente.
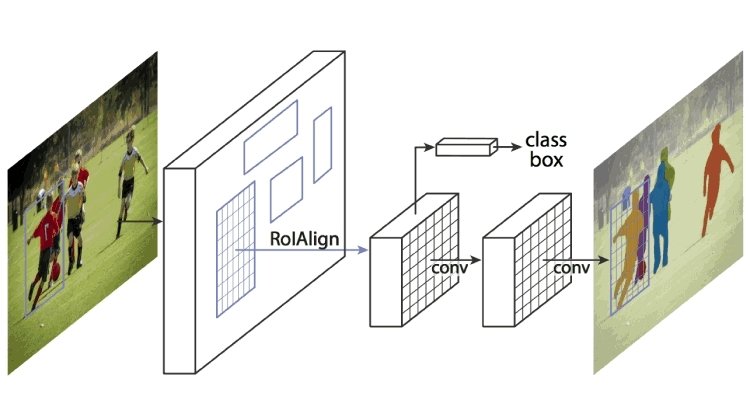
Fonte: viso.ai
Características do Mask R-CNN
Vamos discutir brevemente algumas características.
- É um modelo extremamente simples de treinar e roda a uma velocidade de 5 quadros por segundo (FPS)
- Funciona milagrosamente bem para detectar rostos humanos em diferentes configurações.
- Supera todas as entradas de modelo único em todas as tarefas de detecção de objetos.
- Mask R-CNN pode facilmente se generalizar para outras tarefas. Também pode ser usado para estimar poses humanas em um determinado quadro.
- Serve como uma base sólida para criar robôs de autoajuda que preverão nosso ambiente futuro.
Todos os algoritmos de detecção de objetos supervisionados dependem de conjuntos de dados rotulados, o que significa que os humanos devem aplicar seu conhecimento para treinar a rede neural em diferentes entradas. Label_maps pode buscar os objetos rotulados em um conjunto de dados () funções para inferir a categoria correta do objeto.
O que são mapas de rótulos?
O label-map() na programação Tensorflow mapeia números de saída para a classe de objeto. Se a saída de um algoritmo de detecção de objetos for 4, essa função escaneia os dados de treinamento e retorna a classe correspondente ao número "4". Se "4" for mencionado como "avião", o texto de saída será "avião".
Aplicações de detecção de objetos em diferentes indústrias
Até agora, a detecção de objetos alcançou feitos em domínios críticos como segurança, transporte, medicina e militar. Empresas de software a utilizam para recuperar e categorizar automaticamente grandes conjuntos de dados relacionais para aumentar a eficiência da produção. Esse processo também é conhecido como rotulagem de dados ou anotação de dados.
Aqui estão algumas aplicações da vida real que citam a importância dos sistemas de detecção de objetos alimentados por IA:
- Polícia e forense: A detecção de objetos pode rastrear e localizar objetos específicos, como uma pessoa, veículo ou mochila, de quadro a quadro. Permite que policiais e profissionais forenses inspecionem cada canto de um local de crime para coletar provas. No entanto, devido ao grande volume de dados, o processo de detecção de objetos é um pouco complicado e requer horas de filmagem para identificar o que pode ajudar no sucesso de um caso.
- Checkout sem contato: Muitos restaurantes usam rastreamento de objetos RFID para calcular o valor da conta escaneando pratos vazios. Esse processo adiciona automaticamente o preço de todos os itens ao total e elimina as transações usuais em dinheiro e crédito em um restaurante.
- Inventário e armazenamento: Profissionais de logística podem facilmente detectar, classificar e pegar produtos acabados para transporte por meio de detecção de objetos em tempo real. Algumas empresas até desenvolveram auto-armazenamento para navegar mais facilmente nas prateleiras dos armazéns. Também pode automatizar e regular o gerenciamento da cadeia de suprimentos rastreando níveis de inventário para determinar o fluxo de produção ideal.
- Sistema de estacionamento: Detectores visuais pré-integrados em carros podem detectar vagas de estacionamento abertas em lotes de superfície ou garagens de estacionamento. Também pode fornecer ao motorista uma visão frontal e traseira do espaço de estacionamento e de outros veículos para estacionar o carro com segurança.
- Resposta a desastres: Flutuações recentes em nossos ecossistemas, como a deterioração da camada de ozônio, aumento dos gases de efeito estufa e aquecimento global, levaram desenvolvedores e engenheiros a criar aplicações de detecção de objetos. Ao ajustar redes neurais e usar kits de ferramentas essenciais, modelos rápidos e precisos podem ser construídos para resposta e gerenciamento de desastres.
- Reconhecimento biométrico e facial: Verificações de segurança em aeroportos empregam reconhecimento facial perto dos portões de embarque para atestar a identidade dos viajantes. Dispositivos de reconhecimento facial comparam documentos de identidade com outras tecnologias biométricas, como impressões digitais, para prevenir fraudes e roubo de identidade. Durante transferências internacionais, departamentos de imigração e alfândega usam correspondências faciais para comparar o retrato do viajante com a foto no passaporte.
Top 5 plataformas de reconhecimento de imagem
*Esses são os 5 principais softwares de reconhecimento de imagem com base no G2 Fall 2024 Grid Report em dezembro de 2024

Um escudo para a visão humana
A detecção de objetos não é apenas o resultado da geração de supercomputadores; é também uma promessa de um futuro seguro para a humanidade. Além de alimentar máquinas com visão habilitada por IA, ela descobriu, analisou e desvendou nossos problemas mundanos melhor do que nós.
A detecção de objetos pode não ser extensa – ainda. Mas ela abriu o caminho inicial de sucesso em cadeias de negócios. Não há como voltar atrás a partir daqui.
Explore como a IA está se espalhando além dos limites com software de texto para fala para apoiar deficientes visuais e melhorar a acessibilidade de dados.Este artigo foi publicado originalmente em 2022. Foi atualizado com novas informações.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

