


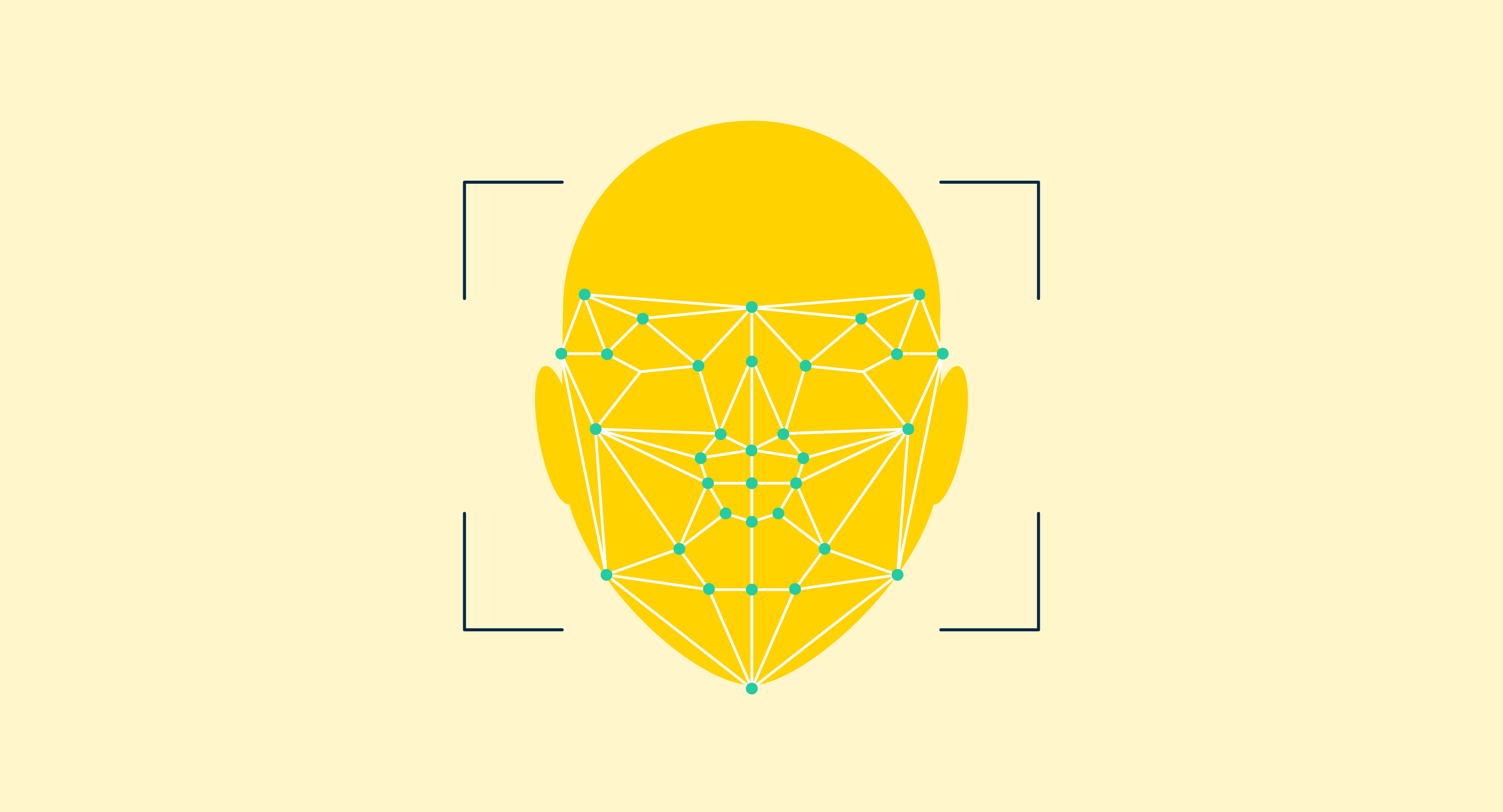
Nosso mundo está repleto de imagens, e na maioria das vezes, nós, humanos, conseguimos decifrar exatamente o que são essas imagens e o que significam com bastante facilidade. Para os computadores, isso não é tão simples.
No entanto, na última década, os avanços em inteligência artificial (IA) e aprendizado de máquina melhoraram significativamente a capacidade dos computadores de entender conteúdo visual.
Usando ferramentas complexas de reconhecimento de imagem, os computadores agora podem identificar diferentes elementos dentro de uma imagem e transmitir essa informação para nós. Como resultado, eles estão muito mais bem equipados para interpretar e explicar do que se trata uma imagem.
O reconhecimento de imagem é uma subcategoria da visão computacional, um campo mais amplo onde visuais são identificados e processados na tentativa de torná-los o mais semelhante possível à visão e compreensão humanas. À medida que a IA se torna mais sofisticada, o mesmo acontece com o software de reconhecimento de imagem e sua capacidade de entender conteúdo visual.
O que é reconhecimento de imagem?
O reconhecimento de imagem é um processo em que máquinas identificam objetos ou características, como pessoas ou animais, dentro de uma imagem visual. Através de um processo complexo de análise de pixels e suas regularidades, padrões, cores e formas, os computadores podem determinar o que a imagem retrata e classificá-la de forma semelhante à interpretação humana.
Como um processo de múltiplas etapas, o reconhecimento de imagem envolve a coleta de dados iniciais sobre uma imagem, seguida pelo processamento através da máquina. Os dados são então analisados em comparação com exemplos do mundo real que a máquina foi treinada a usar. Esses conjuntos de dados de treinamento são críticos na construção de uma base a partir da qual o software de reconhecimento de imagem pode aprender e tornar o reconhecimento de imagens futuras mais preciso.
Exemplo de reconhecimento de imagem
Alguns exemplos de reconhecimento de imagem são o recurso de marcação automática do Facebook, o aplicativo Google Lens que traduz imagens ou elementos de busca, a busca por imagem do eBay e a organização automatizada de imagens e vídeos no Google Fotos. Ao analisar parâmetros de imagem, o reconhecimento de imagem pode ajudar a navegar por obstáculos e automatizar tarefas que precisam de supervisão humana.
Outro exemplo simples de reconhecimento de imagem é o software de reconhecimento óptico de caracteres (OCR), que identifica texto impresso e converte arquivos não editáveis em documentos formatáveis. Uma vez que o scanner OCR determinou os caracteres na imagem, ele os converte e os armazena em um arquivo de texto.
É desnecessário dizer que todas as técnicas de reconhecimento de imagem podem ser aplicadas a fluxos de vídeo. Porque, fundamentalmente, um vídeo consiste em um grupo de imagens que são mostradas rapidamente. Assim, a técnica de reconhecimento de imagem pode ser aplicada a vídeos.
Quer aprender mais sobre Software de Reconhecimento de Imagem? Explore os produtos de Reconhecimento de Imagem.
Reconhecimento de imagem vs. detecção de objetos
Reconhecimento de imagem envolve identificar e categorizar os objetos encontrados dentro de uma imagem ou vídeo, usando padrões e características aprendidos para determinar com precisão o conteúdo. O objetivo é que a máquina identifique o que está acontecendo na imagem como a percepção humana.
Detecção de objetos, por outro lado, tem um objetivo mais focado de identificar objetos específicos dentro de uma imagem.
Em outras palavras, o reconhecimento de imagem interpreta amplamente o conteúdo geral de uma imagem, enquanto a detecção de objetos é encarregada de identificar e classificar partes específicas da imagem conforme definido pelo usuário.
Ambos os processos usam algoritmos de aprendizado de máquina para aprender, processar e classificar os vários elementos dentro de uma imagem. No entanto, seu objetivo e resultado diferem ligeiramente — a detecção de objetos é mais específica com um escopo de trabalho mais restrito.
Reconhecimento de imagem vs. visão computacional
O reconhecimento de imagem é uma subcategoria da visão computacional. Muitos usam esses dois termos de forma intercambiável.
-png.png)
Visão computacional é um campo amplo que inclui diferentes ferramentas e estratégias que visam infundir capacidades visuais em máquinas e sistemas de computação. Essas técnicas incluem rastreamento de objetos, síntese de imagem, segmentação de imagem, reconstrução de cena, detecção de objetos e processamento de imagem. A técnica de visão computacional alimenta várias inovações, como imagem médica, estudo de órgãos anatômicos, carros autônomos, automação de processos robóticos e automação industrial. O objetivo principal é replicar as capacidades de visão humana em sistemas de computação para que possam completar mais de uma tarefa ao mesmo tempo, reconhecendo seu estado visual e aparência.
Reconhecimento de imagem é uma subcategoria dentro da tecnologia de visão computacional que se concentra em detectar, categorizar e reestruturar elementos de imagem dentro de fotografias digitais estáticas, vídeos e cenários do mundo real. Este software é pré-treinado em conjuntos de imagens com características semelhantes às do conjunto de teste. O algoritmo de reconhecimento de imagem analisa a localização dos objetos, extrai características, submete-as a uma camada de agrupamento e, finalmente, alimenta as características a uma máquina de vetores de suporte (SVM) para fazer a classificação final. Aplicações comuns incluem reconhecimento facial, autenticação biométrica, identificação de produtos e moderação de conteúdo.
Tipos de reconhecimento de imagem
O reconhecimento de imagem é tipicamente dividido em três categorias com base em como a máquina foi treinada:
- Aprendizado supervisionado. Quando os dados são rotulados e as categorias para elementos de imagem são conhecidas de antemão, o aprendizado supervisionado é a melhor abordagem a ser usada. Ele pode distinguir diferentes categorias, por exemplo, "não é um gato" e "é um gato", e reconhecer essas partes da imagem.
- Aprendizado não supervisionado. Quando as categorias são desconhecidas e as imagens são alimentadas na máquina, o aprendizado não supervisionado reconhece padrões nos dados. A análise da imagem é baseada em atributos e características, em vez de categorias ou objetos pré-programados.
- Aprendizado auto-supervisionado. Quando há alguns dados rotulados, mas a máquina ainda está aprendendo a funcionar com informações menos específicas, o aprendizado auto-supervisionado pode ser uma boa abordagem a ser utilizada. É um subconjunto do aprendizado não supervisionado, onde os rótulos são criados durante o processo de análise. Mais supervisão é necessária nesta etapa crítica de treinamento, pois determina o quão bem a máquina pode reconhecer imagens futuras.
Dentro de cada uma dessas categorias, vários tipos de aplicações podem ser usados para um reconhecimento de imagem mais extenso e específico. Estes incluem:
- Reconhecimento facial. Este tipo especializado de reconhecimento de objetos treina máquinas para identificar e processar características faciais individuais. As aplicações variam de segurança e vigilância a aplicação da lei. Por exemplo, a segurança aeroportuária e o controle de fronteiras agora frequentemente usam reconhecimento facial para comparar as características de um humano em frente à câmera com o documento de identidade para verificar sua identidade.
- Reconhecimento de cena. Paisagens e edifícios também podem ser identificados por software de reconhecimento de imagem. Isso pode ser usado de várias maneiras, como veículos autônomos, sistemas de mapeamento ou software de jogos, como headsets de realidade aumentada e virtual.
- Reconhecimento de gestos. Embora identificar imagens estáticas seja desafiador para computadores, reconhecer e avaliar gestos em movimento, particularmente os de humanos, pode ser ainda mais complexo. As ferramentas de reconhecimento de imagem podem ser programadas para ler e entender movimentos das mãos, expressões faciais e mais.
- Reconhecimento óptico de caracteres (OCR). Caracteres fixos como letras e números são mais fáceis para os computadores decifrarem, particularmente quando a máquina foi treinada para captar esses visuais e tem categorias pré-atribuídas para organizá-los. Documentos manuscritos podem precisar ser digitalizados e convertidos em texto digital. Esta técnica é uma das maneiras mais fáceis e rápidas de digitalizar informações escritas.
Como funciona o reconhecimento de imagem?
Para que um computador reconheça imagens e padrões, ele emprega um processo conhecido como aprendizado profundo. Esta é uma forma de aprendizado de máquina onde redes neurais profundas replicam os complexos poderes de tomada de decisão do cérebro humano em um ambiente artificial.
Essas redes neurais profundas são compostas por três ou mais camadas, muitas vezes centenas ou milhares, que treinam o modelo de software de reconhecimento de imagem para aplicações do mundo real. Assim como nossos cérebros contêm inúmeros nós interconectados para passar informações por todo o nosso corpo, essas redes de computadores operam de maneira comparável.
Esses nós na rede identificam o que o computador está vendo, pesam diferentes opções e, em seguida, fornecem um resultado conclusivo sobre o que a imagem mostra. Treinar esses nós é crucial para que a máquina aprenda e melhore sua precisão ao longo do tempo.
A máquina deve ser treinada usando um grande conjunto de dados, o que a ajuda a aprender e identificar as características necessárias de diferentes objetos. Uma vez treinada, o processo de reconhecimento de imagem geralmente segue estas seis etapas:
- Coleta de dados. Os dados são alimentados na máquina, geralmente em um ambiente de aprendizado supervisionado com imagens rotuladas.
- Pré-processamento. Antes de o treinamento começar, as imagens são ajustadas para remover quaisquer distorções ou interferências. Isso pode envolver cortar, clarear ou ajustar de outra forma as imagens para torná-las o mais úteis possível para a máquina.
- Extração de características. Isolar as partes da imagem que precisam ser categorizadas é uma etapa essencial no treinamento. Isso ajuda a máquina a distinguir entre diferentes partes do visual.
- Treinamento do modelo. Usando os conjuntos de dados rotulados, a rede neural da máquina é treinada repetidamente até que padrões e características sejam reconhecidos com um alto nível de precisão. A marcação e a segmentação ocorrem durante esta fase, dando ao modelo mais informações para entender a imagem.
- Teste do modelo. Diferentes conjuntos de dados serão usados para continuar treinando e testando o algoritmo até que esteja pronto para implantação. Esses conjuntos de dados provavelmente se tornarão mais complexos ao longo do tempo, passando de conjuntos de dados rotulados para não rotulados para ajudar a máquina a aprender e se tornar mais precisa.
- Implantação e re-teste. Quando o modelo foi suficientemente testado e validado, ele pode ser implantado para uso mais amplo.
Por exemplo, a máquina poderia ser alimentada com uma imagem de dois cães brincando em um quintal. O software de reconhecimento de imagem começaria a identificar os elementos da imagem com classificação, separando os cães do fundo. A partir daí, eles poderiam voltar para marcar os cães individuais como "cachorro" e outros elementos na imagem, como "árvore", "bola" ou "cerca".
Indústrias que se beneficiam do reconhecimento de imagem
As aplicações comerciais do reconhecimento de imagem estão se tornando mais extensas à medida que a IA e o aprendizado de máquina atingem níveis sem precedentes de sofisticação e precisão. Para tarefas que poderiam ser automatizadas ou exigem um nível significativo de esforço humano, o reconhecimento de imagem pode reduzir significativamente tanto o tempo quanto os custos.
Algumas das indústrias que estão se beneficiando dessa tecnologia incluem:
- Varejo. O reconhecimento de imagem na indústria de varejo é uma das melhores maneiras de melhorar a experiência do cliente ao fazer compras na loja. Por exemplo, ele pode combinar roupas com um cliente específico com base em seu estilo atual. Sistemas de segurança também podem usar reconhecimento de imagem para identificar potenciais ladrões ou outras ameaças à segurança.
- Saúde. Radiologistas podem usar reconhecimento de imagem para identificar rápida e facilmente problemas em ressonâncias magnéticas e outras imagens médicas, levando a um tratamento mais rápido e eficaz para os pacientes.
- Agricultura. Pragas e doenças podem ser desastrosas para a comunidade agrícola. Com software de reconhecimento de imagem, os agricultores podem analisar a composição visual das culturas, permitindo que tomem medidas corretivas antes que os problemas sejam irreversíveis.
- Finanças. O erro humano na contabilidade pode ser extremamente caro, mas inúmeras tarefas na indústria financeira podem ser automatizadas para economizar tempo e dinheiro. Processamento de faturas, gestão de despesas e validação de transações financeiras são todos exemplos de como o reconhecimento de imagem pode ajudar. Por exemplo, pequenas empresas podem rapidamente digitalizar um recibo de papel em seu telefone e carregá-lo em seu software de contabilidade. O reconhecimento de imagem extrairá as informações na imagem para adicionar automaticamente esses dados de despesas aos seus registros.
- Manufatura. Defeitos em produtos podem ser erros caros para a indústria de manufatura. O reconhecimento de imagem pode encontrar esses erros ou qualquer desvio do padrão de qualidade típico. Por exemplo, no campo da produção farmacêutica, o reconhecimento de imagem pode facilmente detectar uma pílula faltando em um pacote antes que o processo de fabricação seja concluído e o medicamento seja embalado para venda em quantidade incorreta.
Tarefas do software de reconhecimento de imagem
O software de reconhecimento de imagem é alimentado por aprendizado profundo, mais precisamente, redes neurais artificiais.
Antes de discutirmos o funcionamento detalhado do software de reconhecimento de imagem, vamos examinar as cinco tarefas comuns de reconhecimento de imagem: detecção, classificação, marcação, heurística e segmentação.
Detecção
O processo de localizar um objeto em uma imagem é chamado de detecção. Uma vez que o objeto é encontrado, uma caixa delimitadora é colocada ao redor dele.
Por exemplo, considere uma imagem de um parque com cães, gatos e árvores ao fundo. A detecção pode envolver localizar árvores na imagem, um cachorro sentado na grama ou um gato deitado.
Uma vez que o objeto é detectado, uma caixa delimitadora é colocada ao redor dele. Claro, os objetos podem ter todas as formas e tamanhos. Dependendo da complexidade do objeto, técnicas como anotação de polígono, semântica e ponto-chave são usadas para detecção.
Classificação
É o processo de determinar a classe ou categoria de uma imagem. Uma imagem pode ter apenas uma única classe. No exemplo anterior, se houver um filhote ao fundo, ele pode ser classificado como 'cães' ou simplesmente como imagens de cães. Se houver cães de diferentes raças ou cores, eles também podem ser classificados como "cães".
Marcação
A marcação é semelhante à classificação, mas visa uma melhor precisão. Ela tenta identificar múltiplos objetos em uma imagem. Portanto, uma imagem pode ter uma ou mais tags. Por exemplo, uma imagem de um parque pode ter tags como "cães", "gatos", "humanos" e "árvores".
Heurística
O algoritmo prevê uma "heurística" para cada elemento dentro de uma imagem, que é uma pontuação projetiva de um elemento pertencente a uma categoria de imagem específica. A heurística é uma medida estimada, geralmente medida por uma métrica de distância como a métrica Euclidiana ou Minkowski. A heurística é então comparada com um valor "tensor", que é calculado pela multiplicação cruzada das propriedades dos dados em um número de grades em que a imagem é dividida. O valor heurístico define um objetivo predeterminado para o algoritmo de reconhecimento de imagem alcançar.
Segmentação
A segmentação de imagem é uma tarefa de detecção que tenta localizar objetos em uma imagem até o pixel mais próximo. É útil em situações onde a precisão é crítica. A segmentação de imagem é amplamente utilizada em imagens médicas para detectar e rotular pixels de imagem.
Processar uma imagem inteira nem sempre é uma boa ideia, pois pode conter informações desnecessárias. A imagem é segmentada em subpartes, e as propriedades dos pixels de cada parte são calculadas para entender sua relação com a imagem geral. Outros fatores também são considerados, como iluminação da imagem, cor, gradiente e representações vetoriais faciais.
Por exemplo, se você está tentando detectar carros em um estacionamento e segmentá-los, outdoors ou placas podem não ser muito úteis. É aqui que a partição da imagem em vários segmentos se torna crítica. Pixels semelhantes em uma imagem são segmentados juntos e fornecem uma compreensão granular dos objetos na imagem.
Benefícios do reconhecimento de imagem
Para empresas e consumidores, o software de reconhecimento de imagem tem vários benefícios significativos.
Protege as pessoas contra crimes online
Hoje em dia, nossos rostos estão por toda a internet, junto com informações pessoais aparentemente infinitas. Com ferramentas de reconhecimento de imagem, buscas de imagem podem ser realizadas para verificar o uso não autorizado de suas informações para fraude.
Para artistas visuais, esta também é uma boa maneira de identificar se alguém está roubando ou usando indevidamente sua obra de arte.
Processa dados rapidamente
O reconhecimento de imagem por IA pode processar grandes conjuntos de dados exponencialmente mais rápido do que um humano poderia. Isso não apenas libera sua equipe para realizar outras tarefas que são mais críticas para os negócios, mas também completa o trabalho em um tempo muito mais rápido.
Soluções escaláveis para qualquer projeto visual
Os sistemas de IA têm uma ampla gama de aplicações, o que significa que podem ser usados para quase tudo. Isso torna o software de reconhecimento de imagem uma das opções mais adaptáveis e flexíveis para qualquer tipo de projeto, independentemente do tamanho.
Melhor software de reconhecimento de imagem
Com sua gama de capacidades, o software de reconhecimento de imagem certo depende de sua necessidade específica e dos resultados desejados. A maioria das ferramentas pode lidar com uma variedade de entradas de dados, incluindo o melhor software de reconhecimento de imagem gratuito. Mas para projetos mais complexos, o software pago é muitas vezes a melhor escolha.
Para ser incluído na categoria de software de reconhecimento de imagem, as plataformas devem:
- Fornecer um algoritmo de aprendizado profundo especificamente para reconhecimento de imagem
- Conectar-se a pools de dados de imagem para aprender uma solução ou função específica
- Consumir os dados de imagem como uma entrada e fornecer uma solução de saída
- Integrar capacidades de reconhecimento de imagem em outras aplicações, processos ou serviços
* Abaixo estão as cinco principais soluções de software de reconhecimento de imagem do Relatório de Primavera de 2024 da G2. Algumas avaliações podem ser editadas para clareza.
1. Google Cloud Vision API
Google Cloud Vision API permite que os desenvolvedores aproveitem facilmente o poder da IA e do aprendizado de máquina para reconhecer e avaliar imagens com precisão de previsão líder do setor. As ferramentas permitem que você carregue imagens diretamente, com a API Vision atuando como um localizador de objetos para detectar objetos e rótulos dentro da própria imagem.
O que os usuários mais gostam:
“Estamos usando a API em um projeto onde precisamos saber o valor nutricional dos alimentos, então obtemos o nome do alimento por reconhecimento de imagem e depois calculamos seus nutrientes conforme o conteúdo do alimento. É muito fácil integrá-lo ao nosso aplicativo e o tempo de resposta da API também é muito rápido.”
- Avaliação do Google Cloud Vision API, Badal O.
O que os usuários não gostam:
“Dependendo do uso, os custos associados ao uso do Google Cloud Vision API podem se acumular. Os usuários devem revisar cuidadosamente o modelo de preços e estimar as despesas potenciais para seus casos de uso específicos.”
- Avaliação do Google Cloud Vision API, Piyush D.
2. Syte
Impulsionado por IA, Syte é a primeira plataforma de descoberta de produtos do mundo. Com busca por câmera, personalização e ferramentas inteligentes de eCommerce, as empresas podem ajudar os clientes a descobrir e comprar produtos com uma experiência hiper-personalizada em sua loja online.
O que os usuários mais gostam:
“A ferramenta de loja semelhante tem sido uma ótima ferramenta desde que a implementamos em nossos sites. A ferramenta Syte tem sido instrumental na descoberta de produtos e ajudando os clientes a encontrar produtos visualmente semelhantes quando não conseguem encontrar seu tamanho.”
- Avaliação do Syte, Emely C.
O que os usuários não gostam:
“A plataforma de merchandising de back-end não é tão intuitiva quanto outras plataformas. O “complete o visual” não mostra os produtos exatos como parte do visual, apenas semelhantes.”
- Avaliação do Syte, Cristina F.
3. Carifai
Carifai é uma plataforma de IA completa para desenvolvedores e equipes colaborarem em produções de IA de áudio e visual. Os modelos de aprendizado de linguagem personalizados são de código aberto, com atualizações frequentes, e podem servir a usos multimodais em uma variedade de projetos e indústrias.
O que os usuários mais gostam:
“Fácil de navegar e uma ampla seleção de modelos construídos por usuários para começar a brincar e aprender. Parece o github, mas com IA. Fácil para um iniciante como eu encontrar o que estou procurando. Inscrição rápida e fácil e você pode começar imediatamente sem nenhuma chamada de demonstração ou discurso de vendas irritante primeiro.”
- Avaliação do Clarifai, Tate T.
O que os usuários não gostam:
“Seria bom ter a biblioteca de treinamento ainda mais reforçada, pois os casos de uso e modelos são relativamente novos. Seria bom ter tutoriais de como implementar modelos de ponta a ponta para diferentes tipos de modelos.”
- Avaliação do Clarifai, Sam G.
4. Gesture Recognition Toolkit
Gesture Recognition Toolkit é um conjunto de ferramentas de código aberto e multiplataforma que permite aos desenvolvedores a liberdade e flexibilidade de projetar e construir software de reconhecimento de gestos em tempo real. Amplamente utilizado no desenvolvimento de jogos e realidade virtual, os usuários do kit de ferramentas podem criar do zero ou trabalhar com outros membros da comunidade para aproveitar aplicativos de código aberto para construir seus modelos de aprendizado de linguagem.
O que os usuários mais gostam:
“Gosto de como é projetado para trabalhar com dados de sensores em tempo real e, ao mesmo tempo, a tarefa tradicional de aprendizado de máquina offline. Gosto que ele tenha um float de precisão dupla e pode ser facilmente alterado para precisão única, tornando-o uma ferramenta muito flexível.”
- Avaliação do Gesture, Diana Grace Q.
O que os usuários não gostam:
"Tem um atraso ocasional e um processo de implementação menos suave. O tempo de resposta do suporte ao cliente poderia ser mais rápido.
- Avaliação do Gesture, Civic V.
5. SuperAnnotate
SuperAnnotate é uma plataforma líder para construir, treinar, testar e implantar modelos de IA com dados de treinamento de alta qualidade. Ferramentas avançadas de anotação e reconhecimento de imagem permitem que os usuários construam pipelines de aprendizado de máquina bem-sucedidos e gerenciem cargas de trabalho de automação.
O que os usuários mais gostam:
“SuperAnnotate tem uma interface intuitiva. Foi fácil se familiarizar com as diferentes funções e ferramentas que a plataforma oferece. É fácil navegar entre as milhares de imagens em nosso conjunto de dados - tanto no modo de anotação quanto fora dele. Isso tem sido muito útil em situações onde precisei encontrar imagens específicas para fazer algumas alterações no conjunto de dados. Além disso, o recurso de visão geral de rótulos é útil para detectar e corrigir quaisquer inconsistências em nossas anotações.”
- Avaliação do SuperAnnotate, Camilla M.
O que os usuários não gostam:
“A plataforma pode fornecer mais opções de filtro para contas de gerentes e funções adicionais para anotadores corrigirem tarefas enviadas inadvertidamente.”
- Avaliação do SuperAnnotate, Hoang D.

É quase irreconhecível... mas não completamente!
Imagens visuais e vídeos desempenham um papel crítico em nossas vidas, tanto pessoalmente quanto no local de trabalho. Ter tecnologia ao nosso alcance que pode detectar e avaliar esses visuais de maneira quase igual ao cérebro humano é um passo significativo na inteligência artificial, com possibilidades infinitas de como essas ferramentas podem beneficiar nossas vidas cotidianas.
Saiba mais sobre aplicações de IA para que você possa automatizar mais tarefas e funções diárias em seu negócio.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

