



Les données brutes n'ont aucun sens. Les rendre prêtes pour le business implique beaucoup de temps, de ressources et bien sûr, de café.
Les data scientists gèrent les données de trois manières : gestion, analyse et visualisation. Les modèles d'apprentissage automatique (ML) sont une combinaison de toutes ces méthodes. Ils vérifient vos données, testent leur utilisabilité et les convertissent selon vos attentes.
Le besoin de modèles d'apprentissage automatique explose dans les industries commerciales et non commerciales. L'optimisation des données avec les logiciels d'opérationnalisation de l'intelligence artificielle et de l'apprentissage automatique est devenue le cœur de toutes les opérations de production. Là où la plupart des entreprises cherchent à licencier des clients, les modèles d'apprentissage automatique provoquent une énorme révolution axée sur les données.
Qu'est-ce qu'un modèle d'apprentissage automatique ?
Un modèle d'apprentissage automatique est une représentation graphique de données du monde réel. Il est programmé dans un environnement de données intégré et fonctionne sur des cas d'affaires réels. Il s'entraîne sur des données anciennes et fonctionne sur des données fraîches. Il faut du temps pour programmer, tester et valider les modèles d'apprentissage automatique avant de les utiliser pour prendre des décisions commerciales.
L'apprentissage automatique et les expériences d'intelligence artificielle (IA) remontent au 20ème siècle. L'idée de la "génération de superordinateurs" ou "cinquième génération d'ordinateurs" a créé une poussée de croissance technologique dans un monde informatique sous vide.
Histoire des modèles d'apprentissage automatique
La conception initiale de l'apprentissage automatique a commencé en 1943 lorsque le logicien Walter Pitts et le neuroscientifique Warren McCulloch ont construit un modèle mathématique d'un réseau neuronal. Ils visaient à reproduire le fonctionnement du cerveau humain. Une décennie plus tard, le scientifique en informatique Arthur Samuel a inventé le terme "apprentissage automatique" et l'a décrit comme "la capacité d'un ordinateur à apprendre sans être explicitement programmé."
Le concept est né pour la première fois en 1945, lorsque Joseph Weizenbaum a découvert le traitement du langage naturel (NLP) comme une branche de l'intelligence artificielle. Lentement, de nouveaux concepts d'apprentissage automatique ont remplacé les anciens. Lentement, avec l'évolution du big data, l'apprentissage automatique a incubé une forme plus élevée d'intelligence informatique. Cette intelligence était plus précise, ciblée et légère que les inventions antérieures.
Bien que les modèles d'apprentissage automatique n'étaient pas précis à 100 % en termes de résultats, ils fournissent une prédiction stable. La précision de la prédiction dépendait également du type de données d'entraînement sur lesquelles ils travaillaient. Ces modèles apprenaient les similitudes entre les données externes et internes pour établir des projections.
L'apprentissage automatique au fil des ans
- 1945 : Le premier concept de traitement du langage naturel (NLP) a été créé par Joseph Weizenbaum
- 1949 : The Organization of Behaviour, qui parlait des réseaux neuronaux pour la première fois, publié par Donald Hebb
- 1950 : Invention du test de Turing, qui a été mené pour vérifier l'intelligence et la fluidité des ordinateurs.
- 1951 : La machine calculatrice de renforcement analogique stochastique neuronale (SNARC), le premier dispositif conceptuel basé sur un réseau neuronal artificiel, a été créé.
- 1966 : Conception de Shakey, le premier robot basé sur l'IA
- 1967 : Algorithme des k-plus proches voisins conçu
- 1979 : Invention du Stanford Cart, un chariot télécommandé et auto-assisté
- 1986 : Invention de la machine de Boltzmann restreinte (RBM)
- 1995 : Lancement de l'algorithme "forêt aléatoire"
- 2006 : Première discussion sur les "algorithmes d'apprentissage profond" par Geoffrey Hinton
- 2009 : Fei Fei Li a développé ImageNet, une base de données basée sur des images
- 2012 : Introduction de Google Brain, par Google Inc.
- 2014 : Reconnaissance faciale de Facebook, DeepFace, lancée
- 2016 : Victoire d'Alphago, alimenté par l'IA de Google, contre des joueurs de jeux de stratégie
- 2018 : Invention des perceptrons multicouches, des réseaux adverses génératifs et des réseaux d'apprentissage profond par renforcement.
- 2020 : Standardisation de la réalité augmentée et de la réalité virtuelle
- 2022 : Internet des objets, 5G Edge et ML automatisé
Vous voulez en savoir plus sur Logiciel de réseau de neurones artificiels ? Découvrez les produits Réseau de neurones artificiels.
Quand utiliser des modèles d'apprentissage automatique
Les modèles d'apprentissage automatique sont utilisés pour tirer des informations de données déjà existantes. Ils sont utilisés pour automatiser les opérations commerciales afin de stimuler la croissance. Cependant, certains problèmes peuvent ne pas nécessiter une approche axée sur les données. Ces problèmes ne nécessitent pas d'apprentissage automatique et peuvent être résolus avec des calculs mathématiques standard. Certains scénarios éligibles où l'apprentissage automatique est indispensable sont :
- Incapacité à établir des règles : Dans les cas où vous devez détecter le spam par e-mail, des applications d'apprentissage automatique comme HoxHunt peuvent être utilisées. Les algorithmes de Hoxhunt prédisent les opportunités de spam potentielles et vous empêchent d'accéder à l'URL malveillante via un e-mail de spam. L'e-mail de spam semble à 99 % authentique et ne peut pas être détecté par des règles simples. Un algorithme d'apprentissage automatique robuste détermine tous les facteurs de phishing et arrête l'utilisateur.
- Incapacité à l'échelle : Vous pourriez reconnaître quelques e-mails de phishing mais pas tous. Le phishing est une technique de piratage invisible à l'œil non averti. Il fait apparaître un e-mail comme authentique tout en stockant vos détails privés dans une base de données cachée. Un algorithme ML gère et résout ce problème à grande échelle.
- Cybersécurité : Avec les modèles d'apprentissage automatique, les solutions logicielles de cybersécurité peuvent analyser les modèles, repérer les anomalies dans de vastes quantités de données de journal et trouver des corrélations. Cela empêche les entreprises de subir des attaques de sécurité.
Le saviez-vous ? Vous pouvez évaluer un modèle d'apprentissage automatique avec la validation croisée. Cela implique d'entraîner le modèle sur des données d'entrée et de le tester sur des données de test complémentaires. Cela empêche le surajustement du modèle et aide à établir des modèles similaires pour les prédictions futures.
Différents types de modèles d'apprentissage automatique
Il existe trois principaux types de modèles d'apprentissage automatique. Bien que toutes les techniques de modélisation de l'apprentissage automatique aient un objectif commun, leur approche d'un problème de données diffère.

À mesure que ces modèles sont exposés à plus d'échantillons de données et d'entrées, ils s'améliorent dans l'apprentissage et le calcul des valeurs prédites. Les modèles développent leur intelligence avec le temps, l'apprentissage constant et l'expérimentation.
1. Apprentissage supervisé
Dans l'apprentissage supervisé, le modèle d'apprentissage automatique est enseigné avec des entrées prédéfinies.
Le modèle est équipé de signaux d'entrée et de sortie. Il doit simplement déterminer comment arriver à une valeur de sortie. Le modèle d'apprentissage automatique passe par le processus d'entraînement, cartographie les caractéristiques et les classe pour les données entrantes.
Ensuite, il essaie de capter le signal de sortie le plus proche à mesure que la valeur d'entrée est stockée. Il utilise des expressions booléennes pour calculer les valeurs de données. Les data scientists ou les ingénieurs ML entraînent ce modèle avec un ensemble de données connu qui comprend des entrées et des sorties. L'algorithme doit élaborer une stratégie d'interprétation par lui-même. Si une divergence se produit, l'utilisateur humain la corrige.
Le processus se répète jusqu'à ce que le modèle atteigne un haut degré de précision. Des exemples d'apprentissage supervisé incluent la reconnaissance optique de caractères, la reconnaissance de motifs et la reconnaissance vocale.
2. Apprentissage non supervisé
Les modèles d'apprentissage automatique non supervisés identifient les motifs cachés dans les données pour former des relations et tirer des conclusions. Ils traitent les ensembles de données d'entrée en les comparant aux informations stockées. Le taux de précision d'un algorithme non supervisé ne croît que lorsqu'il travaille avec autant de données fraîches que nécessaire.
Exemple : Si l'apprentissage automatique non supervisé fonctionne sur une image de chiens et de chats, il ne peut pas dire si l'image est un chien ou un chat car leurs attributs physiques sont trop similaires. Il ne pourra pas distinguer leurs caractéristiques distinctes et renverra un résultat confus. La précision de classification du modèle augmente lorsqu'il fonctionne sur plusieurs images.
3. Apprentissage par renforcement
Dans l'apprentissage par renforcement, l'algorithme se comporte comme un agent intelligent qui apprend de chaque opération infructueuse. Le modèle s'adapte aux sorties incorrectes et s'efforce d'atteindre l'objectif final. Un cycle de rétroaction récompense le modèle avec l'intelligence acquise lorsque la sortie est correcte. Mais lorsqu'elle est incorrecte, le modèle apprend de ses erreurs.
Chacun de ces trois types de modèles d'apprentissage automatique englobe différentes techniques de création de modèles. Regardons les plus populaires pour l'instant.
Types d'apprentissage supervisé
La classification, la régression et la prévision sont des techniques d'analyse de données sous l'apprentissage supervisé.
Classification
Dans les tâches de classification, la modélisation ML aide à attribuer une catégorie aux données. Ils doivent tirer des conclusions à partir des valeurs observées pour classer le résultat. Par exemple, lors de la classification des données des patients comme "nouveau" ou "ancien", un modèle ML doit examiner les dates d'enregistrement existantes pour classer les données.
Les deux types d'algorithmes de classification sont la classification binaire et la classification multi-classes. Les classificateurs binaires renvoient le résultat sous forme de oui/non ou vrai/ faux. Ils sont uniquement responsables de vérifier si une classe de données particulière est présente ou non. En revanche, si le problème a plus de deux résultats possibles, on parle de problème de classification multi-classes.
Régression
La régression est une méthode d'apprentissage automatique axée sur une variable dépendante pour une série de variables de sortie. L'analyse d'un algorithme de régression rend les prédictions précises et utiles. Elle passe par une série d'étapes comme la directionnalité des données, l'analyse de la variance (ANOVA), les tests d'hypothèses et la création finale du modèle.
Les modèles d'apprentissage automatique résolvent sept types de problèmes de régression :
-
La régression linéaire est une technique d'analyse de données qui analyse la relation entre les variables d'entrée et de sortie. Il peut y avoir plusieurs modèles de régression linéaire pour un problème. Cela vous aide à mieux corréler les données et à créer une relation variable à variable, comme l'impact de la pression atmosphérique sur le changement topographique.
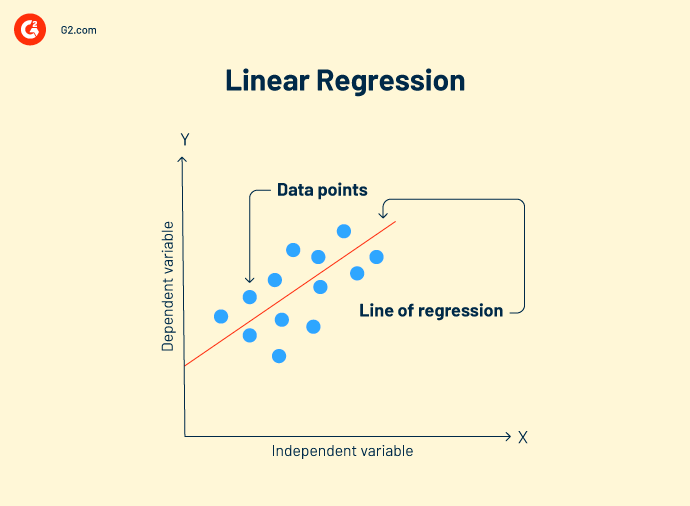
Formule de régression linéaire :
Y = mx+c+e
Y = valeur prédite
m = variable dépendante
c = constante
e = résidu d'erreur
L'objectif de la régression linéaire est de trouver un modèle de bon ajustement qui montre des prédictions précises sur les données de test.
-
La régression logistique fonctionne sur des données catégorielles. Son concept de fonctionnement est similaire à celui de la régression linéaire. Elle établit une relation entre les variables dépendantes et indépendantes pour calculer les variables prédites. Cependant, la variable de sortie ne peut avoir que deux valeurs, oui ou non.
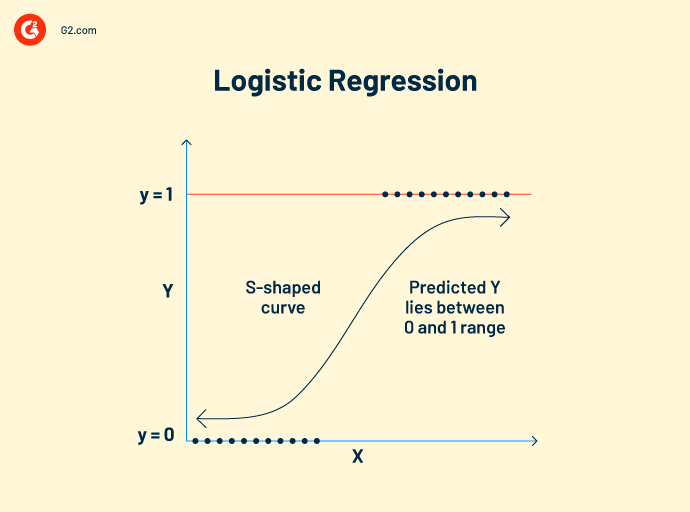
Le modèle de régression logistique prédit des valeurs booléennes comme 0 et 1 ou vrai et faux. Cela le rend populaire en tant qu'algorithme de vision par ordinateur pour détecter la présence d'obstacles externes.
Formule de régression logistique :
Cette formule est notée par la fonction logit, qui mesure la relation entre la variable cible et les variables indépendantes.
Logit (p) = In(p/(1-p)) = b0+b1X2+b2X2……+bkXk
p = probabilité d'une caractéristique
-
Les arbres de décision ou les flux de travail de décision regroupent tous les résultats possibles d'un événement dans une structure arborescente. L'arbre a des nœuds définis, des branches et des déclencheurs d'événements. Chaque nœud interne est une représentation des données de test. Les données de test s'exécutent sur les nœuds internes pour prédire les résultats.
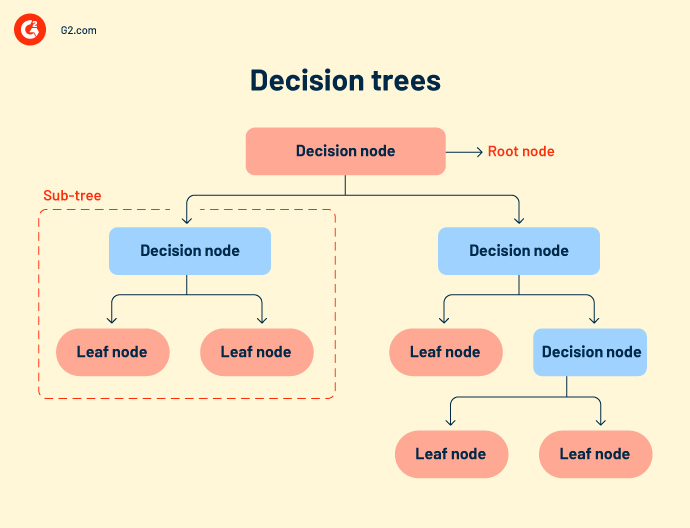
Bien que les arbres de décision soient simples et intuitifs, ils manquent de précision. Comme ils comprennent de nombreux nœuds, parfois le système se confond lors du calcul du résultat.
Les arbres de décision sont principalement utilisés dans la recherche et le développement de produits, l'analyse opérationnelle et la planification financière stratégique. - La forêt aléatoire fait référence à un grand nombre d'arbres de décision regroupés. Chaque nœud d'arbre prédit la présence d'une catégorie à travers un agrégateur de vote. Si la plupart des nœuds votent pour le même résultat, ce résultat est choisi. La forêt aléatoire est plus complexe que d'autres algorithmes de régression. Elle peut être utilisée à la fois pour la classification et les corrélations.
- Les k-plus proches voisins (KNN) est l'un des algorithmes d'apprentissage les plus simples. Il classe vos données en fonction des points de données les plus proches d'une catégorie. L'algorithme KNN suppose que les nouvelles données proviennent du même contexte que les anciennes données et traite rapidement le résultat.
- Les classificateurs Naïve Bayes sont basés sur le théorème de Bayes. C'est un classificateur probabiliste qui détermine la probabilité d'une classe par rapport aux données. C'est l'un des modèles ML les plus récents, les plus rapides et les plus précis. Les équipes de données l'utilisent pour mener des analyses de consommateurs, des analyses sentimentales et des classifications d'articles.
- La machine à vecteurs de support (SVM) est un modèle de classification et de régression principalement utilisé pour la reconnaissance d'images ou la reconnaissance d'objets. Les cartes de caractéristiques extraites du modèle principal et l'emplacement des données sont fournies à un classificateur SVM, qui combine ces données pour prédire la catégorie requise.
3. Prévision
La prévision est une méthodologie basée sur les tendances qui prédit l'avenir avec des données actuelles ou passées. Elle est principalement utilisée pour extrapoler les tendances commerciales actuelles et le potentiel du marché pour les entreprises prenant des décisions d'investissement. La méthode de prévision la plus importante est la prévision de séries temporelles.
La prévision de séries temporelles est une méthode d'analyse de données pour faire des prédictions scientifiques. Elle implique la construction de modèles à travers l'analyse de données historiques sur une période de temps spécifique. Les exemples incluent la prévision météorologique, la prévision des catastrophes naturelles et la prévision des épidémies. La précision de la prévision de séries temporelles est certaine car elle fonctionne sur des données probantes.
Les exemples incluent XGboost, le lissage exponentiel, l'autorégression et DeepAR.
Types d'apprentissage non supervisé
Les data scientists ou les ingénieurs ML utilisent l'apprentissage non supervisé pour construire des modèles d'apprentissage automatique auto-assistés. Ces modèles apprennent et s'améliorent par eux-mêmes, sans attache de données externes.
Clustering
Le clustering est le processus de division des données d'entrée en paniers de catégories similaires pour une classification ultérieure. Deux méthodes efficaces de clustering conviennent le mieux à vos données.
-
Clustering exclusif : Cette méthode place des points de données similaires dans des groupes définis. Les clusters de données sont mutuellement exclusifs. Par exemple, tous les États d'Amérique du Nord seront placés dans un cluster et ceux d'Amérique du Sud dans un autre. Les clusters ne se chevaucheront à aucun stade du processus d'analyse.
- Clustering hiérarchique : Également connu sous le nom de clustering ascendant, c'est une manière plus raffinée et organisée de regrouper vos données. L'algorithme traite chaque ensemble de données comme un cluster unique et les fusionne en un seul ensemble. Lors du clustering des données, vous pouvez choisir soit le clustering agglomératif, soit le clustering divisif.
Échantillonnage aléatoire
L'échantillonnage aléatoire est une méthode d'interprétation statistique qui crée des échantillons aléatoires de données. Elle regroupe les données en différents clusters en fonction de leur nature, de leur type et de leur comportement. Elle est utilisée pour calculer le recensement, l'offre et la demande de produits, et la collecte de revenus dans des zones particulières. L'échantillonnage aléatoire est similaire au clustering mais n'est pas fiable en termes de précision.
Apprentissage des règles d'association
L'apprentissage des règles d'association impose certaines règles pour la classification des données. Il crée des relations et des motifs intéressants entre les données et cartographie les co-dépendances de manière à générer un profit maximal. Les exemples incluent l'exploration de données ou l'analyse de panier de marché.
Réduction de la dimensionnalité
Cette technique élimine les données erronées, les valeurs aberrantes et les valeurs inégales, rendant l'ensemble de données d'entrée plus propre et plus net. Les exemples incluent l'analyse en composantes principales ou le clustering K-means.
Apprentissage profond
L'apprentissage profond nécessite de grands ensembles de données et une puissance de calcul graphique élevée (GPU) pour prédire la classe des variables d'entrée. Il implique des réseaux neuronaux composés de fonctions d'activation et de nœuds de déclenchement. Le réseau accepte l'entrée via la couche d'entrée, déclenche les nœuds de décision via la fonction d'activation et traite la sortie. Les modèles les plus significatifs sont :
- Autoencodeurs
- Machine de Boltzmann
- o Réseaux de neurones convolutifs
- o Perceptron multicouche
- o Réseaux de neurones récurrents
Types d'apprentissage par renforcement
Faire des erreurs est humain. Faire des erreurs est aussi le propre des machines.
L'apprentissage par renforcement désigne un agent intelligent pour travailler sur les données. Ces actions intelligentes prennent des mesures dans un environnement d'apprentissage automatique pour prédire des résultats corrects. Si l'apprentissage par renforcement prédit un résultat correct, il reçoit une récompense cumulative. C'est l'un des trois paradigmes de base de l'apprentissage par renforcement.
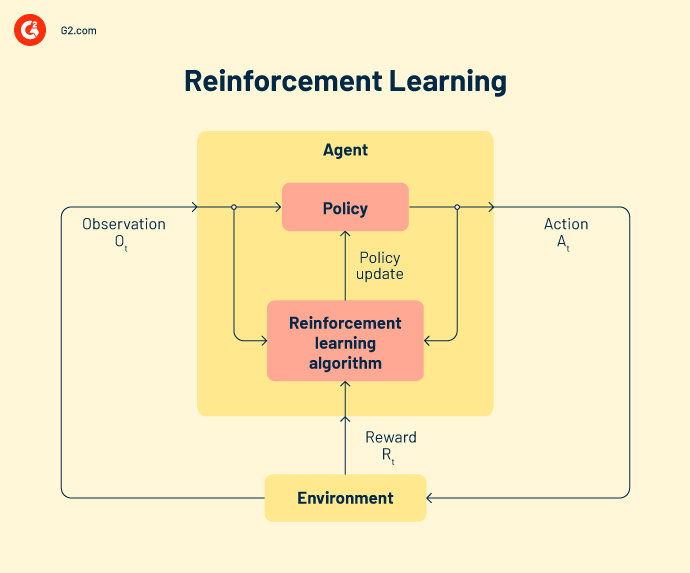
Certains modèles de renforcement populaires incluent.
Q-learning est un algorithme de renforcement populaire qui aide les agents IA à prendre des décisions judicieuses. Avec cet algorithme, vous pouvez calculer la valeur q, prendre l'action requise et maximiser les points de récompense.
State-action-reward-state-action (SARSA) est un algorithme sur politique qui calcule la valeur q pour chaque paire état-action. Pour chaque état spécifique de l'entrée, il y a une sortie désignée et une récompense désignée en cas de précision de la sortie. Chaque lettre de SARSA représente une ligne.
Un réseau Q. profond, ou réseau neuronal Q. profond, est un réseau neuronal artificiel qui a de nombreuses couches de calcul. Il traite la sortie en fonction de l'entrée, des poids et du biais ajouté.
Différents modèles d'apprentissage automatique ont différentes utilités et accomplissent différents ensembles d'objectifs. Vous devez choisir quel modèle fonctionnera le mieux pour vous à long terme.
Algorithme vs modèle d'apprentissage automatique vs modèle d'apprentissage profond
Peu importe l'approche, le résultat final est toujours un modèle qui agit sur les données. L'apprentissage profond. L'apprentissage automatique ou l'algorithme est le deuxième nom de la gestion des données, comme votre data scientist pourrait le confirmer.
-png.png)
Les algorithmes sont un ensemble d'expressions de programmation qui sont auto-explicatives. Ils exécutent un fil de commandes sur les données d'entrée. Un algorithme d'apprentissage automatique est codé dans des outils open-source comme Python, Java ou TensorFlow. Vous devez appeler un package spécifique de la bibliothèque de packages et installer ses répertoires. Après cela, vous pouvez charger vos ensembles de données, définir l'axe et créer des modèles. Certains packages sont Scikit learn, NumPy ou Matplotlib.
Le modèle d'apprentissage automatique est la création finale d'un algorithme de données. Les modèles sont classés comme biaisés, normaux ou de bon ajustement. Les propriétés des données et la précision de l'algorithme sont les principaux contributeurs à un modèle d'apprentissage automatique. Le modèle est déployé sur des données de test et étendu dans les applications de flux de travail d'une organisation.
Le modèle d'apprentissage profond est un pas en avant par rapport aux modèles d'apprentissage automatique. Ces modèles sont formés pour extraire et stocker des caractéristiques individuelles à partir des données, puis les utiliser pour faire des prédictions précises. Cependant, ces systèmes de calcul nécessitent de grands ensembles de données, des ensembles d'images et une puissance de calcul graphique élevée (GPU). Les exemples incluent le réseau neuronal convolutif (CNN), le réseau neuronal convolutif récurrent (R-CNN) et "vous ne regardez qu'une fois" (YOLO).
Comprendre les subtilités des données peut être très délicat. Et beaucoup de subtilités résident dans la façon dont vous choisissez vos modèles ML.
Conseil : Vous pouvez utiliser l'apprentissage automatique en tant que service (MLaaS) pour externaliser les processus d'apprentissage automatique pour vos flux de travail commerciaux. Ce service est une collection de différents logiciels basés sur le cloud qui déploient des outils d'apprentissage automatique pour fournir des solutions d'analyse prédictive à vos équipes ML pour divers cas d'utilisation commerciale.
Comment choisir le meilleur modèle d'apprentissage automatique pour votre entreprise
Pour trouver le meilleur modèle, examinez attentivement votre infrastructure informatique existante. Votre réseau local actuel ouvrira la voie à la compatibilité future du matériel et des logiciels. Prenez en compte votre budget, votre bande passante, votre réseau local (LAN), la bande passante des data scientists et d'autres politiques de maintenance des installations pour faire fonctionner vos modèles d'apprentissage automatique en tandem.
Une façon sûre est de commencer petit. Construisez un cadre de preuve de concept et évaluez votre maturité en IA. Utilisez les attributs de données existants, le volume, les caractéristiques et la complexité pour construire un modèle d'apprentissage automatique intermédiaire. Validez-le et testez-le pour de petits projets et cas d'utilisation commerciale. Lorsque votre modèle s'intègre aux données, déployez-le à plus grande échelle.
Au fur et à mesure que vous progressez, comptez sur plus de bande passante d'équipe, de budget et d'efforts des data scientists. Beaucoup d'efforts sont consacrés à la gestion, à l'entraînement et au diagnostic des modèles ML, ce qui peut empiéter sur vos ressources commerciales.
Le saviez-vous ? Le marché mondial de l'intelligence artificielle était évalué à 93,5 milliards de dollars en 2021 et devrait croître à un taux de croissance annuel composé de 38,1 % de 2022 à 2030.
Source : Grand View Research
Bien que le modèle d'apprentissage automatique représente vos données mathématiquement, il n'entre pas en action de lui-même.
Vos données sont votre piste de décollage
L'apprentissage automatique est le présent, mais il éclaire également la voie vers un avenir numérique. Rassemblez une quantité copieuse de recherches, étudiez les processus existants et décidez quelle option vous mettra à l'avant-garde du marché des logiciels.
apprenez comment vous pouvez choisir le modèle de science des données et d'apprentissage automatique correct pour votre entreprise.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

