



L'apprentissage profond est la manière dont une machine intelligente apprend les choses.
C'est une méthode d'apprentissage pour les machines, inspirée par la structure du cerveau humain et notre façon d'apprendre.
C'est une technologie critique qui rend les véhicules autonomes une réalité et c'est aussi la raison pour laquelle l'assistant vocal de votre smartphone s'améliore avec le temps pour vous assister. En d'autres termes, l'apprentissage profond est notre meilleure chance de créer des machines avec une intelligence semblable à celle des humains.
Qu'est-ce que l'apprentissage profond ?
L'apprentissage profond (DL) est un sous-domaine de l'apprentissage automatique qui imite le fonctionnement du cerveau humain dans le traitement des données. Le DL permet aux machines d'apprendre sans supervision humaine et leur donne la capacité de reconnaître la parole, de traduire des langues, de détecter des objets et même de prendre des décisions basées sur les données.
En d'autres termes, l'apprentissage profond est un type d'apprentissage automatique (ML) inspiré par la structure du cerveau humain. En effet, le DL est une imitation des neurones du cerveau humain et tente de mimer leurs fonctions.
Bien que l'apprentissage profond soit une branche de l'apprentissage automatique, les systèmes DL ne sont pas limités par une capacité finie d'apprendre comme les algorithmes ML traditionnels. Au lieu de cela, les systèmes DL peuvent apprendre et améliorer leurs performances avec l'accès à de plus grands volumes de données.
L'apprentissage profond permet aux systèmes d'intelligence artificielle d'imiter la manière dont les humains acquièrent certains types de connaissances. Les algorithmes DL essaient de tirer des conclusions – de la même manière que les humains le font – en analysant continuellement les données. Pour y parvenir, le DL utilise des réseaux de neurones artificiels (ANN).
Le DL imite le fonctionnement du cerveau humain, principalement les fonctions telles que le traitement des données et la création de modèles pour la prise de décision. Il est intéressant de noter que les scientifiques et les chercheurs en IA ont commencé à construire des ANN afin que les machines puissent éventuellement exhiber les caractéristiques de l'intelligence humaine, telles que les capacités de résolution de problèmes, la conscience de soi, la perception, la créativité et l'empathie, pour n'en nommer que quelques-unes.
L'apprentissage profond n'aurait pas été possible sans que les ordinateurs deviennent moins chers, plus rapides et plus petits. Il en va de même pour les dispositifs de stockage car de grandes quantités de données doivent être stockées et traitées pour que l'apprentissage profond devienne une réalité. C'est pourquoi, bien que l'apprentissage profond ait été théorisé dans les années 1980, il n'est devenu réalisable que récemment.
Traiter de tels volumes énormes de données non structurées est pratiquement impossible pour les humains. Même si nous parvenons à acquérir la main-d'œuvre nécessaire, il pourrait falloir des années pour analyser et extraire des informations pertinentes de ces grands ensembles de données. Cependant, avec l'apprentissage profond, ce processus est étonnamment simplifié.
Avec l'aide de l'apprentissage profond, un système d'IA peut apprendre et s'améliorer sans aucune supervision humaine. Le DL permet également aux machines d'apprendre à partir de données non étiquetées ou non structurées, ou les deux. Cependant, notez que le processus d'apprentissage peut être non supervisé, semi-supervisé ou supervisé.
L'apprentissage profond est également une partie critique de la science des données. Il est bénéfique pour les scientifiques des données de collecter, analyser et interpréter de grands volumes de données et rend les processus comme la modélisation prédictive plus rapides et plus efficaces.
Des branches de l'intelligence artificielle telles que la vision par ordinateur et le traitement du langage naturel sont réalisables grâce à l'apprentissage profond. Avant d'aller plus loin, voyons comment l'apprentissage profond fonctionne pour nous aider.
Comment fonctionne l'apprentissage profond ?
En termes plus simples, le processus d'apprentissage du DL se déroule en modifiant les actions du système sur la base d'une boucle de rétroaction continue. Le système d'apprentissage est récompensé pour chaque action correcte et puni pour les mauvaises. Le système essaie d'ajuster ses actions pour maximiser la récompense.
L'apprentissage profond utilise des modèles d'apprentissage supervisé, semi-supervisé, ainsi que non supervisé pour s'entraîner.
Les neurones qui forment les réseaux de neurones peuvent être classés en trois catégories en fonction de leur hiérarchie : les couches d'entrée, cachées et de sortie.
- La couche d'entrée, qui est la première couche de neurones, reçoit les données d'entrée et les transmet à la première couche cachée.
- Les couches cachées effectuent des calculs spécifiques, comme la reconnaissance d'images, sur les données reçues.
- Une fois les calculs terminés, la couche de sortie génère la sortie requise.
Comme mentionné précédemment, l'apprentissage profond est rendu possible par les réseaux de neurones artificiels. Ils sont construits en s'inspirant des réseaux de neurones du cerveau humain. Un grand nombre de perceptrons – l'équivalent artificiel des neurones – sont empilés ensemble pour former des ANN.
Le terme "profond" est utilisé pour spécifier le nombre de couches cachées que les réseaux de neurones ont. Alors que les réseaux de neurones traditionnels contiennent deux à trois couches cachées, les réseaux profonds peuvent en avoir même 150.
Une façon simple de comprendre comment fonctionne l'apprentissage profond est de regarder les réseaux de neurones convolutifs (CNN). C'est l'un des types les plus populaires de réseaux de neurones profonds, en dehors des réseaux de neurones récurrents (RNN), des réseaux antagonistes génératifs (GAN) et des réseaux de neurones à propagation avant.
Le CNN extrait des caractéristiques directement des images, éliminant le besoin d'extraction manuelle de caractéristiques. Aucune des caractéristiques n'est pré-entraînée ; au lieu de cela, elles sont apprises par le réseau lorsqu'il s'entraîne sur l'ensemble d'images donné. Cette caractéristique d'extraction automatique de caractéristiques rend les modèles d'apprentissage profond très efficaces pour la classification d'objets et d'autres applications de vision par ordinateur.
La raison pour laquelle les réseaux de neurones profonds sont très précis dans l'identification des caractéristiques et la classification des images est due aux centaines de couches qu'ils contiennent. Chaque couche apprendrait à identifier des caractéristiques spécifiques, et à mesure que le nombre de couches augmente, la complexité des caractéristiques d'image apprises augmente.
Vous voulez en savoir plus sur Logiciel de réseau de neurones artificiels ? Découvrez les produits Réseau de neurones artificiels.
Apprentissage profond vs apprentissage automatique
L'apprentissage automatique est une application de l'IA qui permet aux machines d'apprendre et de progresser automatiquement à partir de l'expérience, sans être explicitement programmées pour le faire.
L'algorithme de filtrage de spam présent dans votre compte de messagerie est un excellent exemple d'algorithme d'apprentissage automatique. Les algorithmes ML sont également utilisés dans les plateformes OTT comme Netflix pour recommander des films et des séries que vous êtes plus susceptible de regarder et d'apprécier.
Les algorithmes ML sont capables d'analyser des données, d'identifier des modèles et de faire des prédictions. Ils apprennent et s'adaptent à mesure que de nouveaux ensembles de données leur sont introduits. D'une certaine manière, l'apprentissage automatique rend les ordinateurs plus humains car il leur accorde la capacité d'apprendre et de progresser.
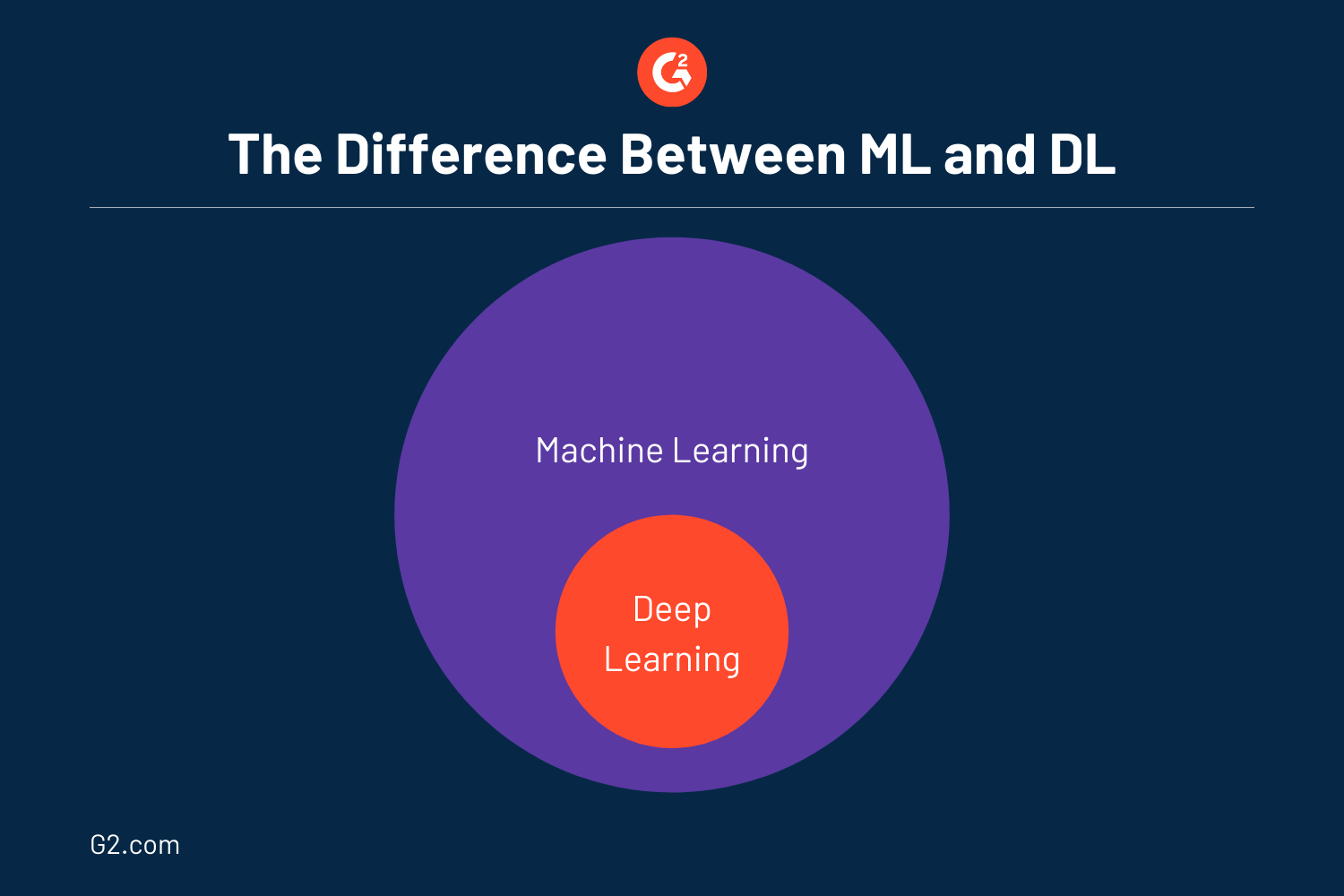
Comme mentionné précédemment, l'apprentissage profond est un sous-ensemble de l'apprentissage automatique, qui à son tour est un sous-ensemble de l'intelligence artificielle. Plus précisément, l'apprentissage profond est en fait de l'apprentissage automatique et peut être considéré comme une version évoluée de ce dernier. Très souvent, beaucoup utilisent DL et ML de manière interchangeable car ils fonctionnent presque de la même manière.
Cependant, leurs capacités sont différentes. Bien que les algorithmes ML puissent apprendre et s'améliorer progressivement, ils ont encore besoin d'une certaine forme de guidance. Par exemple, si l'algorithme fait une prédiction incorrecte, alors une intervention humaine est essentielle pour faire des ajustements. Au contraire, les algorithmes d'apprentissage profond peuvent déterminer si leurs prédictions sont exactes ou non avec l'aide de réseaux de neurones artificiels.
Le programme AlphaGo développé par DeepMind utilise largement l'apprentissage profond. C'est le tout premier programme informatique à battre un joueur professionnel de Go humain. AlphaGo a été suivi par de nombreuses versions avancées, y compris MuZero, qui peut maîtriser un jeu sans qu'on lui enseigne les règles.
Il est intéressant de noter que les chercheurs ont essayé d'utiliser des techniques d'apprentissage automatique traditionnelles pour entraîner des robots à maîtriser le jeu pendant de nombreuses années. Mais ils n'ont réussi que lorsqu'ils ont combiné l'apprentissage profond avec l'apprentissage par renforcement et d'autres paradigmes.
Une autre façon de différencier l'apprentissage automatique et l'apprentissage profond est de regarder comment ils apprennent. Supposons que vous deviez enseigner à une machine à catégoriser les images de chiens et de chats. Si vous utilisez le modèle d'apprentissage automatique, vous devrez fournir des données structurées – dans ce cas, les images étiquetées de chiens et de chats – pour que l'algorithme apprenne les caractéristiques spécifiques qui différencient les images des deux animaux. L'algorithme s'améliore avec chaque image étiquetée à laquelle il est exposé.
| Apprentissage automatique | Apprentissage profond | |
| Supervision humaine | Requise | Non requise |
| Données étiquetées | Requises | Non requises |
| Temps d'entraînement | Secondes ou quelques heures | Heures ou quelques semaines |
| Nombre de points de données requis | Milliers | Millions |
| Ressources informatiques | Moins de ressources nécessaires | Ressources massives nécessaires |
| GPU | Non requis | Requis |
Une fois que les images sont traitées à travers différentes couches des réseaux de neurones profonds, le système aura accès à des identifiants spécifiques, ce qui aidera à classer les animaux et leurs images. Les différentes sorties traitées par chaque couche du réseau de neurones sont combinées pour catégoriser efficacement les images.
La présence de réseaux de neurones signifie également que les algorithmes d'apprentissage profond nécessitent de grands ensembles de données. C'est parce que les algorithmes DL ne peuvent apprendre que lorsqu'ils sont exposés à un million ou plus de points de données. D'autre part, les algorithmes ML peuvent apprendre et s'améliorer avec des directives pré-définies.
Une autre différence notable entre l'apprentissage automatique et l'apprentissage profond est le type de matériel requis pour les deux. Étant donné que la complexité des calculs et la quantité de données traitées sont significativement plus faibles pour l'apprentissage automatique, les programmes ML peuvent fonctionner sur des ordinateurs bas de gamme sans nécessiter beaucoup de puissance de calcul.
En revanche, les systèmes d'apprentissage profond nécessitent des ressources informatiques massives et des composants matériels puissants comme les unités de traitement graphique (GPU). Le scientifique informatique Andrew Ng a déterminé que les GPU pouvaient augmenter la vitesse des systèmes d'apprentissage profond de plus de 100 fois.
Avec l'aide des GPU, le temps nécessaire pour entraîner les modèles d'apprentissage profond peut être réduit de plusieurs jours à quelques heures. La majorité des frameworks d'apprentissage profond tels que PyTorch et TensorFlow sont déjà accélérés par GPU.
Des entreprises comme Nvidia prennent plus au sérieux l'apprentissage profond accéléré par GPU et ajustent leurs produits en conséquence. De plus, les GPU sont utiles pour les calculs matriciels ou vectoriels.
Le temps nécessaire pour entraîner les algorithmes d'apprentissage profond et d'apprentissage automatique est également significativement différent. Comme vous l'avez peut-être deviné, les algorithmes d'apprentissage profond prennent beaucoup de temps à s'entraîner en raison de la quantité massive de données et des calculs complexes impliqués. Il peut falloir quelques heures ou même des semaines pour entraîner un système DL, tandis qu'un système ML peut être entraîné en quelques secondes ou heures.
Encore une fois, choisir entre l'apprentissage profond et l'apprentissage automatique doit être une décision hautement informée. La décision doit être prise en tenant compte du volume et de la nature des données, de la complexité du problème que vous essayez de résoudre et des ressources informatiques disponibles.
Applications de l'apprentissage profond
Bien que l'apprentissage profond soit considéré comme un domaine en plein essor, les chercheurs et les organisations bénéficient déjà de ses applications. Voici quelques exemples d'apprentissage profond qui façonnent le monde qui nous entoure, et très probablement, vous en avez rencontré certains dans votre vie quotidienne.
Voitures autonomes
Les véhicules autonomes sont les bénéficiaires les plus célèbres de l'apprentissage profond. Des millions d'ensembles de données qui reproduisent de nombreux scénarios de la vie réelle sont introduits dans le système, qui est utilisé pour enseigner au véhicule comment naviguer sur la route en toute sécurité.
Avec l'aide de modèles d'apprentissage profond, les fabricants peuvent s'assurer que les voitures sans conducteur peuvent gérer des scénarios imprévus sans causer de tort aux passagers ou aux piétons.
En plus d'aider les machines à résoudre des scénarios hypothétiques, l'apprentissage profond les aide également à analyser et traiter les données brutes collectées à partir de caméras, de GPS et de nombreux capteurs. Ce faisant, les véhicules autonomes peuvent identifier et distinguer les voies et les séparateurs de routes, les barricades, les panneaux, les piétons, les voitures ralentissant ou arrêtées, et plus encore.
Traitement du langage naturel
Le traitement du langage naturel (NLP) est un domaine de l'intelligence artificielle qui accorde aux machines la capacité de comprendre, d'interpréter et de tirer du sens des langues humaines. En termes simples, le NLP permet aux machines de converser avec les humains et même de comprendre les nuances contextuelles d'une langue.
Les assistants intelligents comme Siri et Google Assistant et les applications de traduction de langues comme Google Translate sont des exemples concrets de NLP. Le NLP peut être encore divisé en génération de langage naturel (NLG) et compréhension du langage naturel (NLU).
Astuce : Découvrez certains des meilleurs logiciels de traitement du langage naturel de l'industrie.
À première vue, la reconnaissance vocale peut sembler être simplement une question de conversion du son en mots respectifs. C'est assez simple pour les humains car le cortex auditif de notre cerveau a été formé pendant des années à reconnaître et comprendre une langue parlée ou plus.
Un exemple simple pour représenter la complexité de la compréhension des sons est "recognize speech" et "wreck a nice beach". Les deux sons sont très similaires, bien que leurs significations soient entièrement différentes. Bien que les machines puissent détecter les mots dans une phrase, comprendre leur signification contextuelle est encore une tâche herculéenne. C'est là que le DL intervient pour le NLP.
Presque tous les assistants intelligents reposent sur l'apprentissage profond, et leurs niveaux de compréhension et de précision augmentent avec chaque tâche. Google Assistant, qui dépend presque entièrement du DL, a la plus grande précision.
L'apprentissage profond permet également aux machines de comprendre les complexités d'une langue, telles que les nuances tonales, les expressions et même le sarcasme. Comprendre les complexités d'une langue est également crucial pour l'analyse des sentiments sur les données textuelles. Ce n'est qu'alors que les entreprises peuvent surveiller la réputation de la marque et du produit, comprendre l'opinion publique et analyser les expériences des clients.
Une autre application de l'apprentissage profond est la résumé de documents. Le résumé de documents ou simplement la synthèse de texte est la tâche d'extraire des informations cruciales d'un grand passage de texte et de créer un synopsis concis de celui-ci. En plus de faire gagner du temps aux humains, le résumé de documents peut également aider les programmes informatiques qui doivent traiter de grandes quantités de données en peu de temps.
La reconnaissance vocale est une autre application utile de l'apprentissage profond et devient de plus en plus précise. Les gouvernements peuvent utiliser cette technologie pour identifier les terroristes passant des appels téléphoniques anonymes en comparant leurs échantillons de voix à une base de données contenant des voix reconnues.
Reconnaissance d'images
Avant l'apprentissage profond, le domaine de la reconnaissance d'images reposait fortement sur le réglage manuel. Cela signifie que de nombreux processus devaient être effectués par des humains et prenaient beaucoup de temps. L'apprentissage profond élimine le besoin de traitement d'image manuel ou traditionnel et accélère considérablement l'ensemble du processus.
Dans cette décennie, la majorité des systèmes de détection d'objets précis que vous rencontrez reposent uniquement sur l'apprentissage profond. Google Photos est un excellent exemple. Il utilise l'apprentissage profond pour classer et regrouper les images.
Même si vous n'avez effectué aucun étiquetage manuel, vous pouvez rechercher dans votre album Google Photos quelque chose comme "insectes sur des fleurs" et obtenir des résultats, à condition que vous ayez des images connexes stockées. Vous pouvez même rechercher des animaux en fonction de leur espèce ou de leur race et obtenir toutes les photos contenant l'animal en question.
Alors que les systèmes traditionnels non basés sur l'apprentissage profond ont du mal à identifier les objets d'une image, l'apprentissage profond va plusieurs étapes plus loin. Il fait un travail impressionnant de reconnaissance des visages humains, des animaux, des lieux et des choses avec une grande précision et presque aucune erreur.
Fabrication
Avec l'introduction de l'Internet des objets (IoT), les usines deviennent plus intelligentes que jamais. L'automatisation n'est pas nouvelle dans l'industrie manufacturière, et l'apprentissage profond rend les choses plus rationalisées.
Avec l'aide d'architectures d'apprentissage profond comme le CNN, les entreprises peuvent remplacer la majorité des opérateurs humains qui étaient autrement essentiels pour repérer les produits défectueux sur la chaîne de montage.
De cette façon, repérer les problèmes de qualité devient plus précis et rentable, et les risques d'erreur humaine sont éliminés. Ces systèmes sont également hautement évolutifs et peuvent être formés pour détecter les problèmes de qualité à n'importe quel point de la ligne de production.
Une autre application de l'apprentissage profond dans la fabrication est la maintenance prédictive. En collectant et en analysant les données de santé des machines sur une période de temps, les algorithmes d'apprentissage profond peuvent prédire les chances qu'un actif de fabrication tombe en panne.
Déterminer quand réparer un équipement est crucial du point de vue financier d'une entreprise car une machine défectueuse pourrait arrêter toute la production. Étant donné que la maintenance irrégulière peut également causer des dommages coûteux et irréparables aux machines et des accidents d'usine catastrophiques dans le pire des cas, les entreprises peuvent économiser beaucoup avec la maintenance prédictive. Savoir quand réparer aidera également les entreprises à planifier à l'avance et à chercher des alternatives pour réduire les temps d'arrêt de l'usine.
L'optimisation des intrants de l'usine est une autre application bénéfique de l'apprentissage profond. Avec les consommateurs devenant plus préoccupés par l'empreinte carbone des produits et les réformes écologiques mises en œuvre par leurs créateurs, les entreprises n'ont d'autre choix que d'optimiser l'utilisation des ressources physiques.
De plus, l'optimisation des ressources aidera les entreprises à tirer plus de profit de chaque produit, d'où l'optimisation des intrants de l'usine. En suivant l'utilisation des ressources (consommation d'électricité et d'eau, principalement) de différentes machines et processus de production, les systèmes d'apprentissage profond peuvent suggérer dynamiquement les meilleures pratiques d'optimisation.
Découverte de médicaments
La découverte de médicaments est incroyablement chronophage et coûteuse. L'apprentissage profond peut rendre ce processus moins cher et plus rapide. L'apprentissage profond peut aider à prédire l'affinité de liaison des médicaments avec des protéines particulières et même les effets toxiques de certains composés.
AtomNet est un réseau de neurones convolutif profond utilisé pour la conception rationnelle de médicaments. C'est une technologie de pointe capable de trouver des composés médicamenteux nouveaux et non évidents et peut être un outil remarquable pour les projets de repositionnement accéléré de médicaments. AtomNet a également été utilisé pour prédire de nouvelles biomolécules candidates pour Ebola et la sclérose en plaques (MS).
Hôtellerie
L'hôtellerie est une industrie de plusieurs milliards de dollars toujours désireuse d'adopter de nouvelles technologies, et la technologie de l'apprentissage profond ne fait pas exception. Avec le DL, les organisations peuvent trouver de nouveaux moyens d'améliorer l'expérience et la satisfaction des clients et même identifier des processus coûteux et remplaçables.
L'apprentissage profond peut aider les organisations à planifier à l'avance en prédisant les demandes saisonnières. Un système d'apprentissage profond peut facilement trouver la corrélation entre les facteurs qui causent les demandes saisonnières et prédire les tendances futures en analysant les données passées.
En analysant les données des clients, les modèles DL peuvent également aider les entreprises à élaborer des stratégies client pour de meilleurs taux de rétention et de satisfaction. Les entreprises peuvent également utiliser diverses techniques d'apprentissage automatique pour des prix compétitifs en tenant compte de plusieurs facteurs tels que la saisonnalité, les événements en temps réel, les promotions de tiers, les événements locaux et les données de réservation passées.
Finance
Étant donné que le traitement de données volumineuses complexes est une spécialité de l'apprentissage profond, il a un potentiel immense dans l'industrie financière. En analysant les données historiques, divers paramètres de marché et les facteurs externes qui peuvent affecter la performance d'une entreprise, les algorithmes d'apprentissage profond peuvent prédire les valeurs boursières avec une précision impressionnante.
Étant donné que les algorithmes DL peuvent analyser de vastes volumes de données provenant de plusieurs sources simultanément, ils sont incroyablement plus rapides que les humains et sont donc utilisés pour créer des stratégies de trading rentables.
Les réseaux de neurones profonds sont également utilisés dans le processus d'approbation de prêt. En analysant les données historiques concernant les approbations et les rejets, les banques peuvent évaluer correctement les risques d'approuver un prêt à une entité.
Restauration d'images
La restauration d'images est un autre exploit impressionnant que l'apprentissage profond peut réaliser. La restauration d'images fait généralement référence à la récupération d'une image claire non dégradée à partir d'une image dégradée. La dégradation peut se produire en raison de plusieurs facteurs, le bruit d'image étant l'un d'eux.
Si le bruit d'image est le coupable, alors le processus de restauration est appelé débruitage d'image. De même, les images peuvent être de résolution inférieure, et par le processus de super-résolution, des images de résolution supérieure peuvent être créées.
Avec l'apprentissage profond, de tels processus de restauration deviennent plus précis et moins chronophages. Les méthodes d'apprentissage telles que Deep Image Prior sont utilisées pour le processus de restauration. En termes simples, Deep Image Prior est un réseau de neurones convolutif utilisé pour améliorer une image sans aucune donnée d'entraînement préalable autre que l'image elle-même.
En 2017, les chercheurs de l'équipe Google Brain ont formé un réseau de neurones profond pour analyser des images de visages de très basse résolution et prédire les visages. Cette méthode est appelée Pixel Recursive Super Resolution et peut améliorer considérablement la résolution des images. Le réseau de neurones peut identifier les caractéristiques distinctives d'une personne avec facilité.
L'apprentissage profond est également largement utilisé pour coloriser des photos en noir et blanc. Vous pouvez consulter des outils en ligne comme Algorithmia pour voir comment certaines images en noir et blanc auraient ressemblé si elles avaient été prises avec un appareil photo couleur.
Publicité mobile
L'apprentissage profond permet aux annonceurs mobiles de publier des annonces qui peuvent capturer l'attention de leur public cible et offrir un retour sur investissement (ROI) plus élevé. Les techniques d'apprentissage profond telles que la publicité prédictive basée sur les données sont utilisées pour augmenter la pertinence des annonces également.
De nombreux réseaux publicitaires mobiles en temps réel utilisent des API d'apprentissage profond, qui aident les annonceurs à maximiser le taux de clics (CTR). Les temps de réponse plus rapides des systèmes d'apprentissage profond permettent également aux annonceurs de diffuser les bonnes annonces au bon moment et à l'endroit approprié.
Détection des retards de développement
Un diagnostic précoce et un traitement des troubles du développement, de l'autisme ou des troubles de la parole peuvent avoir un impact positif sur l'avenir d'un enfant. Un humain ne remarquerait pas de nombreux signes précoces, mais un système d'apprentissage profond le peut certainement.
En utilisant l'apprentissage profond, les chercheurs du MIT's Computer Science and Artificial Intelligence Laboratory et de l'Institute of Health Professions de l'hôpital général du Massachusetts ont créé un système informatique capable d'identifier les troubles de la parole avant même qu'un enfant n'entre à la maternelle.
De plus, les enfants qui sont sur le spectre de l'autisme ont du mal à reconnaître les états émotionnels des personnes qui les entourent. Par exemple, les enfants autistes auront du mal à différencier un visage heureux d'un visage effrayé.
En guise de remède à ce problème, certains médecins utilisent des robots adaptés aux enfants, alimentés par l'apprentissage profond, pour engager les enfants à imiter les émotions et y répondre de manière appropriée. Au fur et à mesure que le robot interagit, il analyse l'intérêt et l'engagement de l'enfant en observant leurs réponses.
L'apprentissage profond permet au robot d'extraire les informations les plus cruciales des données collectées sans nécessiter d'assistance humaine. Avec l'aide du DL, les chercheurs ont découvert de nombreux faits fascinants tels que les différences culturelles entre les enfants de différents pays.
Ils ont observé que pendant les épisodes d'engagement élevé, les enfants du Japon montraient plus de mouvements corporels. En revanche, les grands mouvements corporels étaient liés à des épisodes de désengagement pour les enfants de Serbie.
L'une des plus grandes raisons pour lesquelles ce type de traitement est efficace est que le robot est conçu pour attirer l'attention des enfants. De plus, les humains ont tendance à changer fréquemment leurs expressions et à exprimer la même émotion de différentes manières. Mais le robot le fait toujours de la même manière afin que le processus d'apprentissage soit beaucoup moins frustrant pour l'enfant.
Prédiction sonore
La production sonore est une partie intégrante de la réalisation de films. Bien que certains sons comme les pas, les coups à la porte ou les pneus crissants puissent être empruntés à des audios de stock, ils doivent souvent être recréés pour améliorer l'expérience cinématographique.
Des chercheurs du MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) ont créé un algorithme d'apprentissage profond qui prédit le son. Lorsqu'on lui donne un clip vidéo silencieux d'un objet frappé, l'algorithme peut produire des sons réalistes. Le son prédit est suffisamment réaliste pour tromper les humains.
Pour entraîner l'algorithme, les chercheurs ont filmé environ 1 000 vidéos de près de 46 000 sons constituant différents objets frappés, piqués et raclés avec une baguette. Ils ont utilisé une baguette spécifiquement parce qu'elle offrait une méthode cohérente pour produire un son.
Les systèmes de prédiction sonore ne rendront pas seulement les choses meilleures pour l'industrie cinématographique, mais pourraient aider les machines intelligentes à naviguer dans le monde et à comprendre les propriétés des objets.
Traduction visuelle
Avez-vous déjà essayé de traduire des langues étrangères avec l'application Google Translate ? Non seulement l'application "traduit" les mots, mais elle superpose l'image avec la traduction. L'application fait cela avec l'aide de réseaux de neurones profonds et c'est l'une des nombreuses façons dont Google intègre l'apprentissage profond dans un smartphone.
Une fois que l'application trouve où les lettres sont situées dans l'image en analysant ses pixels, un réseau de neurones convolutif formé sur des lettres et des non-lettres essaie de reconnaître ce que chaque lettre est. Une fois les lettres identifiées, l'application consulte un dictionnaire pour obtenir des traductions.
La traduction est ensuite rendue par-dessus les lettres originales dans le même style que l'image originale. De telles traductions visuelles sont super rapides si elles sont effectuées sur les centres de données de Google. Mais comme la majorité des utilisateurs possèdent un smartphone bas de gamme et ont des connexions Internet instables, Google a développé un petit réseau de neurones avec de nombreuses limitations.
Systèmes de recommandation
Les algorithmes d'apprentissage profond sont utilisés dans les systèmes de recommandation pour suggérer du contenu que les utilisateurs sont plus susceptibles de regarder. L'efficacité de ces algorithmes est cruciale pour des plateformes comme Netflix car ce n'est que si les utilisateurs trouvent fréquemment du contenu intéressant qu'ils continueront l'abonnement. Amazon et de nombreuses autres plateformes de commerce électronique dépendent également fortement des algorithmes d'apprentissage profond pour recommander les bons produits et augmenter les ventes.
Détection de fraude
Les pertes et dommages liés à la fraude sont une triste réalité de l'industrie financière. Les escrocs financiers se multiplient.
1,9 milliard de dollars
a été perdu en raison du vol d'identité et de la fraude en 2019.
Source : Insurance Information Institute
Cependant, il peut y avoir de nombreux comportements d'utilisateur que les systèmes basés sur des règles peuvent ne pas identifier comme suspects, mais les systèmes de détection de fraude basés sur le DL le feraient sûrement. La puissance de traitement des systèmes basés sur le DL est également remarquable, et ils réduisent également le besoin de travail manuel – contrairement aux systèmes basés sur des règles qui nécessitent une supervision humaine fréquente et des corrections manuelles.
Comment créer et entraîner des modèles d'apprentissage profond
Il existe trois façons courantes d'entraîner un modèle d'apprentissage profond à effectuer une classification d'objets. Vous pouvez soit l'entraîner à partir de zéro, soit utiliser l'apprentissage par transfert, soit utiliser un réseau comme extracteur de caractéristiques. Jetons un coup d'œil rapide à chacun.
1. Entraînement à partir de zéro
Pour entraîner des réseaux de neurones profonds à partir de zéro, vous devez acquérir de grands volumes d'ensembles de données étiquetées – par exemple, les images étiquetées de chats et de chiens. Après cela, vous devez concevoir une architecture de réseau qui peut apprendre les caractéristiques distinctes des animaux. En fonction du volume de données, du taux d'apprentissage et de la puissance de traitement, les réseaux peuvent prendre des jours ou des semaines pour s'entraîner.
2. Approche d'apprentissage par transfert
La façon la plus courante d'entraîner des réseaux de neurones profonds est par l'approche d'apprentissage par transfert. Dans ce processus, un modèle pré-entraîné est affiné pour effectuer une nouvelle tâche. Vous pouvez commencer avec un réseau existant et lui fournir de nouveaux ensembles de données contenant des classes précédemment inconnues.
Vous pouvez ajuster le réseau selon vos besoins, dans ce cas, identifier et distinguer les images de chats et de chiens. Étant donné que ce processus nécessite moins de données, le temps de calcul diminue considérablement.
3. Utilisation d'un extracteur de caractéristiques
Une autre approche pour entraîner un modèle d'apprentissage profond est d'utiliser un réseau comme extracteur de caractéristiques. Étant donné que chaque couche du réseau est désignée pour apprendre des caractéristiques spécifiques à partir d'images, vous pouvez en fait extraire ces caractéristiques du réseau pendant le processus d'entraînement. Ces caractéristiques peuvent ensuite être entrées dans un modèle d'apprentissage automatique. Ce faisant, vous pouvez réduire le besoin de ressources informatiques énormes.
Apprentissage profond : plus c'est mieux
Une propriété intéressante de l'apprentissage profond est qu'il s'améliore si vous fournissez plus de données et plus de ressources informatiques. Bien que les algorithmes d'apprentissage profond puissent sembler trop exigeants, ils sont très précis et nécessitent peu ou pas d'assistance humaine dans la plupart des cas.
L'apprentissage profond sera également notre clé pour débloquer l'intelligence artificielle générale, un système d'IA capable de penser, d'apprendre et d'agir comme les humains.
En savoir plus sur l'intelligence artificielle générale et voyez par vous-même si une telle machine intelligente serait un ami ou un ennemi.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

