



Dans l'espace de travail technologique en pleine croissance d'aujourd'hui, les entreprises disposent de plus de données que jamais auparavant.
Disposer de grandes quantités de données ne signifie rien ; ce que vous faites de ces données est ce qui compte. C'est là que l'exploration de données entre en jeu. Elle donne un sens aux données alors que les entreprises s'efforcent de mettre en œuvre divers objectifs et stratégies d'amélioration potentielle grâce au processus de transformation des données brutes en informations exploitables. Il existe de nombreuses façons de procéder, et tout dépend des techniques d'exploration de données que votre entreprise choisit d'utiliser.
L'exploration de données est le processus de recherche et de détection de motifs dans les données pour obtenir des informations pertinentes ; les différentes techniques sont la manière dont vous transformez les données brutes en observations précises.
Techniques courantes d'exploration de données
Une variété de techniques d'exploration de données est souvent nécessaire pour découvrir les informations qui se cachent dans de grands ensembles de données, il serait donc logique d'en choisir plus d'une. Bien que l'exploration de données puisse segmenter les clients, elle peut également aider à déterminer la fidélité des clients, identifier les risques, construire des modèles prédictifs, et bien plus encore.
La plupart, mais pas toutes, des techniques d'exploration de données relèvent soit de l'analyse statistique, soit de l'apprentissage automatique, selon la manière dont elles sont utilisées. Ci-dessous, nous approfondissons chaque technique.
Nettoyage des données
Une technique nécessaire en matière d'exploration de données est le nettoyage des données. Les données brutes doivent être nettoyées, formatées et analysées pour être utiles et appliquées à différents types de méthodes analytiques. Cette technique fait partie de différents éléments de modélisation, transformation, agrégation et migration des données.
Comment le nettoyage des données est-il utilisé aujourd'hui ?
Les entreprises utilisent le nettoyage des données comme première étape du processus d'exploration de données car sinon, les données trouvées sont inutiles et peu fiables. Il doit y avoir une confiance dans les données, et les résultats qui découlent de l'analyse des données, pour qu'il y ait une étape suivante valable et exploitable. Le nettoyage des données est souvent la première étape réalisée dans le processus d'exploration de données.
Regroupement
Une technique d'exploration de données est appelée analyse de regroupement, également appelée taxonomie numérique. Cette technique regroupe essentiellement de grandes quantités de données en fonction de leurs similitudes. Cette maquette montre à quoi pourrait ressembler une analyse de regroupement.
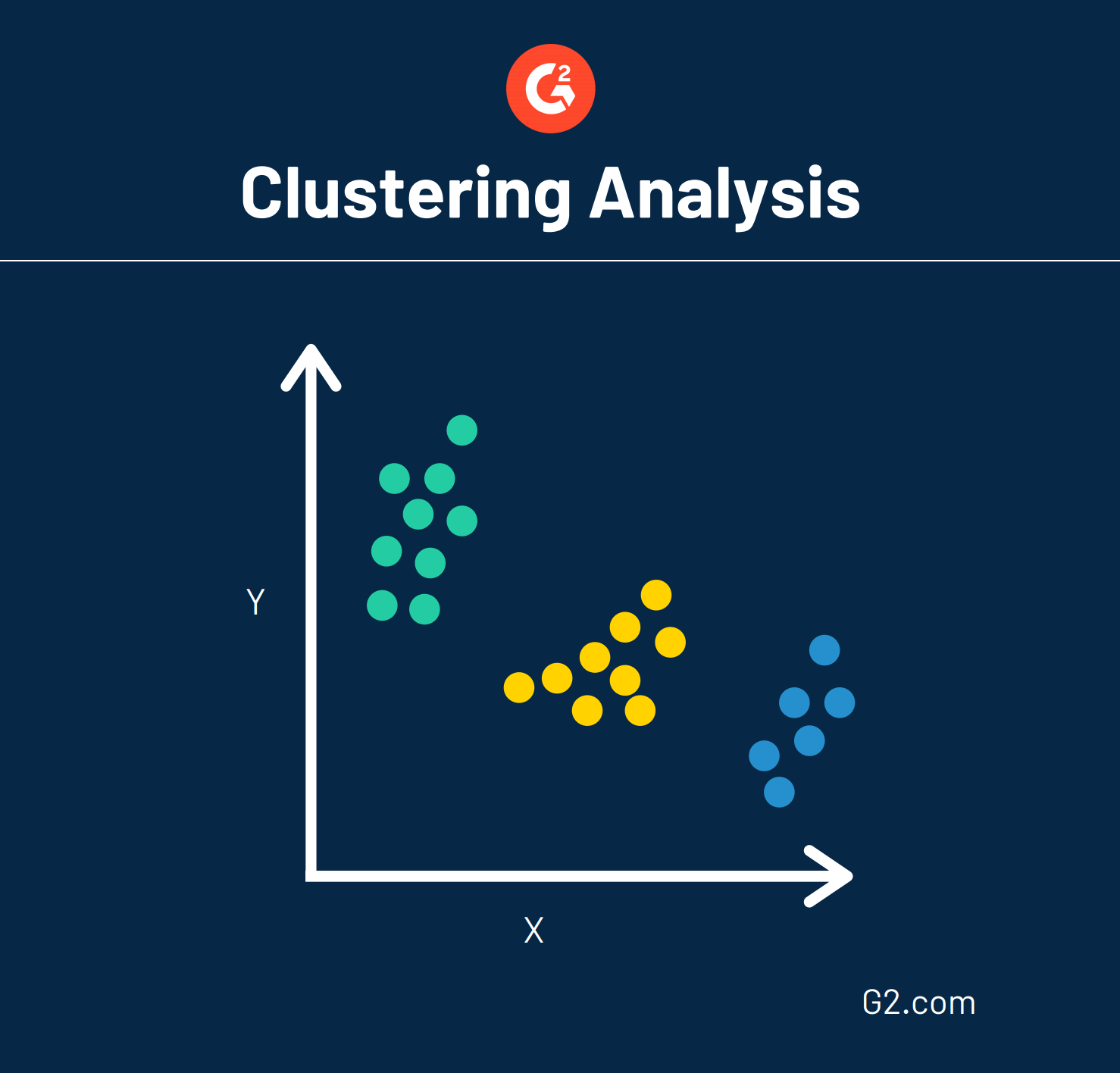
Les données qui sont disposées de manière sporadique sur un graphique peuvent être regroupées de manière stratégique grâce à l'analyse de regroupement. Cette analyse peut également servir d'étape de prétraitement, ce qui signifie que les données sont formatées de manière à ce que d'autres techniques puissent être facilement appliquées.
En ce qui concerne les approches de regroupement, il existe cinq méthodes principales utilisées par les scientifiques des données :
- Algorithmes de partitionnement : création de diverses partitions puis évaluation en fonction de critères spécifiques
- Algorithmes hiérarchiques : création d'une disposition hiérarchique de l'ensemble de données en utilisant des critères spécifiques
- Basé sur la densité : basé sur la connectivité et les fonctions de densité
- Basé sur la grille : basé sur des structures de granularité à plusieurs niveaux
- Basé sur le modèle : un modèle est d'abord supposé pour chacun des groupes, puis le meilleur ajustement du modèle est trouvé
Allant de pair avec ces approches de regroupement, cinq algorithmes de regroupement sont utilisés pour classer chaque point de données dans un groupe spécifique. Les points de données au sein du même groupe ont des propriétés ou des caractéristiques similaires.
Ces algorithmes sont :
- Regroupement K-Means : regroupe les observations en groupes où chaque point de données fait partie du groupe avec la moyenne la plus proche
- Regroupement par décalage de la moyenne : attribue les points de données aux groupes de manière itérative en déplaçant les points vers le mode. Le plus souvent utilisé dans le traitement d'images et la vision par ordinateur
- Regroupement spatial basé sur la densité d'applications avec bruit (DBSCAN) : regroupe les points de données dans un espace spécifique qui sont proches les uns des autres tout en marquant des points aberrants spécifiques dans des régions de faible densité au sein du groupe. Fréquemment cité dans la littérature scientifique
- Regroupement par maximisation de l'espérance (EM) avec modèles de mélange gaussien (GMM) : utilisé pour regrouper des données non étiquetées car il prend en compte la variance (largeur d'une courbe en cloche) pour déterminer la forme de la distribution ou du groupe
- Regroupement hiérarchique agglomératif : travaille à construire une analyse hiérarchique des groupes avec une approche « ascendante ». Chaque observation commencera dans son propre groupe, et des paires de groupes sont fusionnées à mesure que l'on monte dans la hiérarchie
À quoi sert le regroupement ?
Il existe plusieurs façons de tirer des connaissances de l'analyse de regroupement. Les compagnies d'assurance peuvent identifier des groupes de souscripteurs avec des réclamations moyennes élevées. Le regroupement peut être utilisé en marketing pour segmenter les clients en fonction des avantages qu'ils tireront de l'achat d'un produit spécifique.
Un autre exemple de regroupement est la façon dont les sismologues peuvent voir l'origine de l'activité sismique et la force de chaque tremblement de terre, puis appliquer cette information pour concevoir des itinéraires d'évacuation.
Classification
La classification est souvent considérée comme un sous-ensemble du regroupement. La classification consiste à analyser divers attributs associés à différents types de données. Lorsqu'une entreprise peut identifier les principales caractéristiques de ces types de données, elle peut mieux organiser et classer toutes les données qui y sont liées.
C'est une partie essentielle de l'identification de types de données spécifiques, comme si une entreprise souhaite protéger davantage des documents contenant des informations sensibles, telles que des numéros de sécurité sociale ou de carte de crédit.
Détection des valeurs aberrantes
Également connue sous le nom de détection d'anomalies, cette technique d'exploration de données fait peut-être l'opposé du regroupement. Au lieu de rechercher de grands groupes de données pouvant être regroupés, la détection des valeurs aberrantes recherche des points de données rares et en dehors d'un groupe ou d'une moyenne établie.
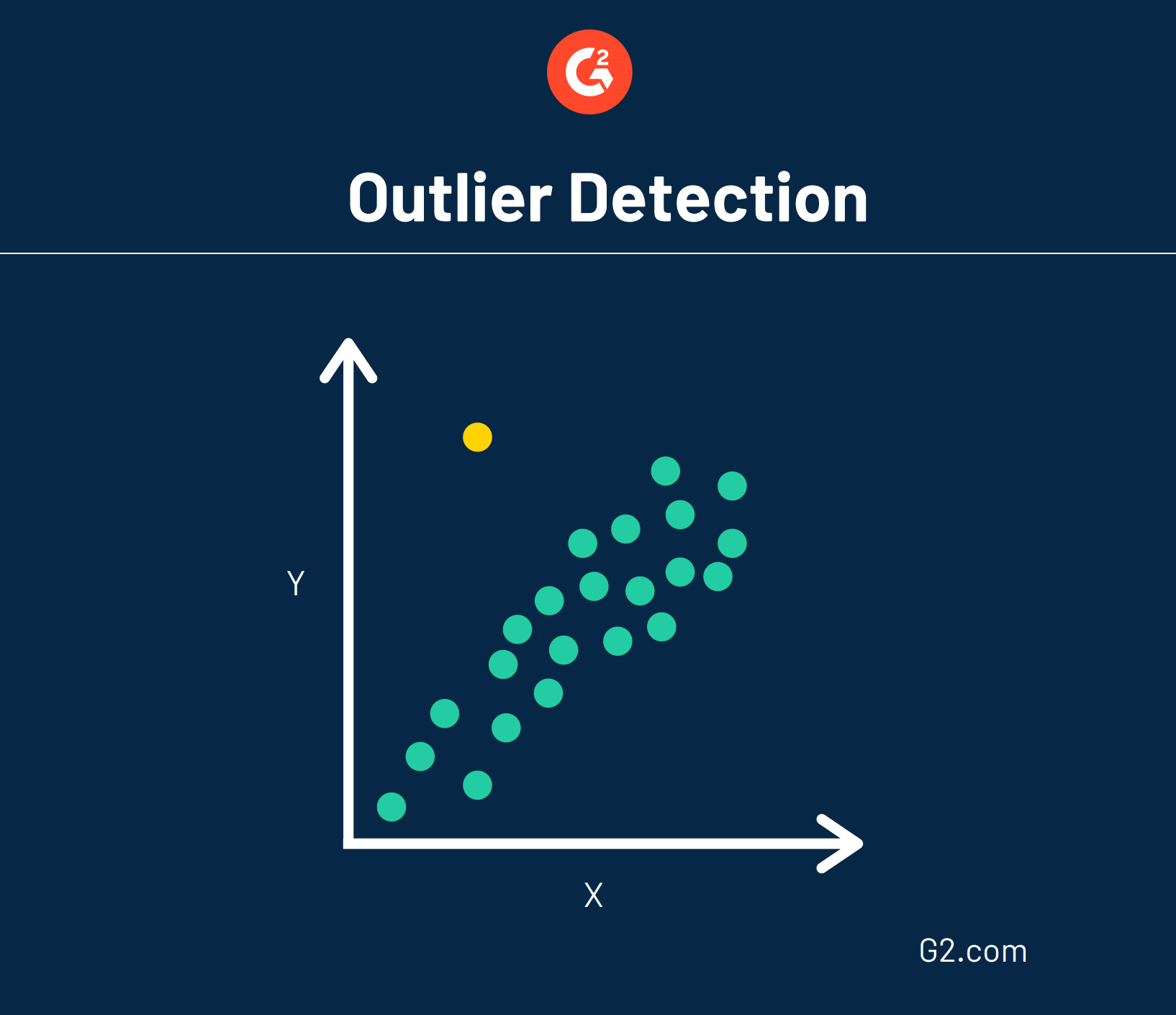
Parce que les données sont assez aléatoires, les anomalies ne pointent pas nécessairement vers une tendance. Au lieu de cela, les données qui vont à contre-courant pourraient indiquer que quelque chose d'anormal se passe et nécessite une analyse plus approfondie.
Une fois qu'une entreprise ou une organisation trouve ces anomalies dans les données, il devient plus facile de comprendre pourquoi ces anomalies se produisent et de se préparer à celles qui pourraient survenir à l'avenir.
Il existe deux types de valeurs aberrantes :
- Univariée : un point de données qui consiste en une valeur extrême sur une variable
- Multivariée : une combinaison de scores inhabituels sur au moins deux variables
Parmi ces deux types, il existe quatre techniques de détection des valeurs aberrantes :
- Valeur aberrante numérique : détection des valeurs aberrantes dans un espace unidimensionnel
- Z-Score : détection paramétrique des valeurs aberrantes dans un espace unidimensionnel ou de faible dimension
- DBSCAN : détection des valeurs aberrantes basée sur la densité dans un espace unidimensionnel ou multidimensionnel
- Isolation Forest : méthode non paramétrique pour les grands ensembles de données dans un espace unidimensionnel ou multidimensionnel
À quoi sert la détection des valeurs aberrantes ?
La détection des valeurs aberrantes est le plus souvent utilisée pour détecter les comportements frauduleux. Par exemple, la détection des valeurs aberrantes peut identifier une activité suspecte de carte de crédit et déclencher une réponse (comme un gel de compte).
À une époque où les cyberattaques sont plus robustes et courantes que jamais, la détection des valeurs aberrantes aide à identifier les violations de données sur les sites Web afin qu'elles puissent être rapidement résolues. Cela s'appelle la détection d'intrusion.
Extraction de règles d'association
Rechercher des groupes et des valeurs aberrantes sont quelques façons d'extraire des connaissances, mais une autre technique appelée extraction de règles d'association examine comment une variable se rapporte à une autre en découvrant un motif caché dans l'ensemble de données.
Les scientifiques des données recherchent des événements ou des attributs spécifiques qui sont fortement corrélés avec un autre événement ou attribut. Les informations issues de l'extraction de règles d'association peuvent également aider les entreprises à identifier des corrélations potentielles. Par exemple, si l'événement A se produit, alors l'événement B est susceptible de suivre. Si l'événement A est une tempête de neige, nous pouvons supposer que l'événement B, les annulations de vols, est susceptible de venir ensuite. Si vous avez déjà reçu des suggestions de produits sur un site de commerce électronique en fonction de ce qui se trouve dans votre panier, alors vous avez vu l'extraction de règles d'association en action.
Par exemple, voici ce qu'Amazon me recommande d'acheter en fonction des articles que j'ai achetés dans le passé.

À quoi sert l'extraction de règles d'association ?
Walmart a appliqué cette technique d'exploration de données de manière impeccable en 2004 lors de l'ouragan Frances. En explorant les données de transaction et d'inventaire, les analystes ont découvert que les ventes de Pop-Tarts à la fraise étaient sept fois plus élevées juste avant que l'ouragan ne frappe. La bière a également été révélée comme l'article le plus vendu avant l'ouragan. Avec cette information en main, Walmart s'est assuré de faire le plein. Comme Walmart, les petites et moyennes entreprises peuvent utiliser ces données de la même manière.
Régression
Si une entreprise cherche à faire une prédiction basée sur l'effet qu'une variable a sur d'autres, elle peut se référer à une technique d'exploration de données appelée analyse de régression. Cette méthode de données identifie et analyse la relation entre les variables.
Rappelez-vous : La régression et l'association sont souvent confondues l'une avec l'autre. La régression en analyse statistique est l'équation utilisée pour spécifier et associer des données pour deux ou plusieurs variables. L'association est la relation entre deux quantités mesurées qui les rendra dépendantes ou corrélées.
À quoi sert la régression ?
En surface, les données sont chaotiques. Il y a beaucoup d'essais et d'erreurs impliqués lors de l'examen de la relation entre un ensemble de données et un autre - surtout lorsqu'une entreprise essaie de déterminer les probabilités d'événements et de faire des prédictions. L'analyse de régression peut orienter ces prédictions dans la bonne direction.
Un exemple d'analyse de régression dans le secteur de la santé est l'examen des effets que l'indice de masse corporelle, ou IMC, a sur d'autres variables. Vous utiliseriez également la régression pour déterminer comment le prix d'un produit affectera le nombre de ventes de votre entreprise ou comment la quantité de précipitations affectera la croissance des cultures.
Régression linéaire
Un type courant de régression est appelé régression linéaire.
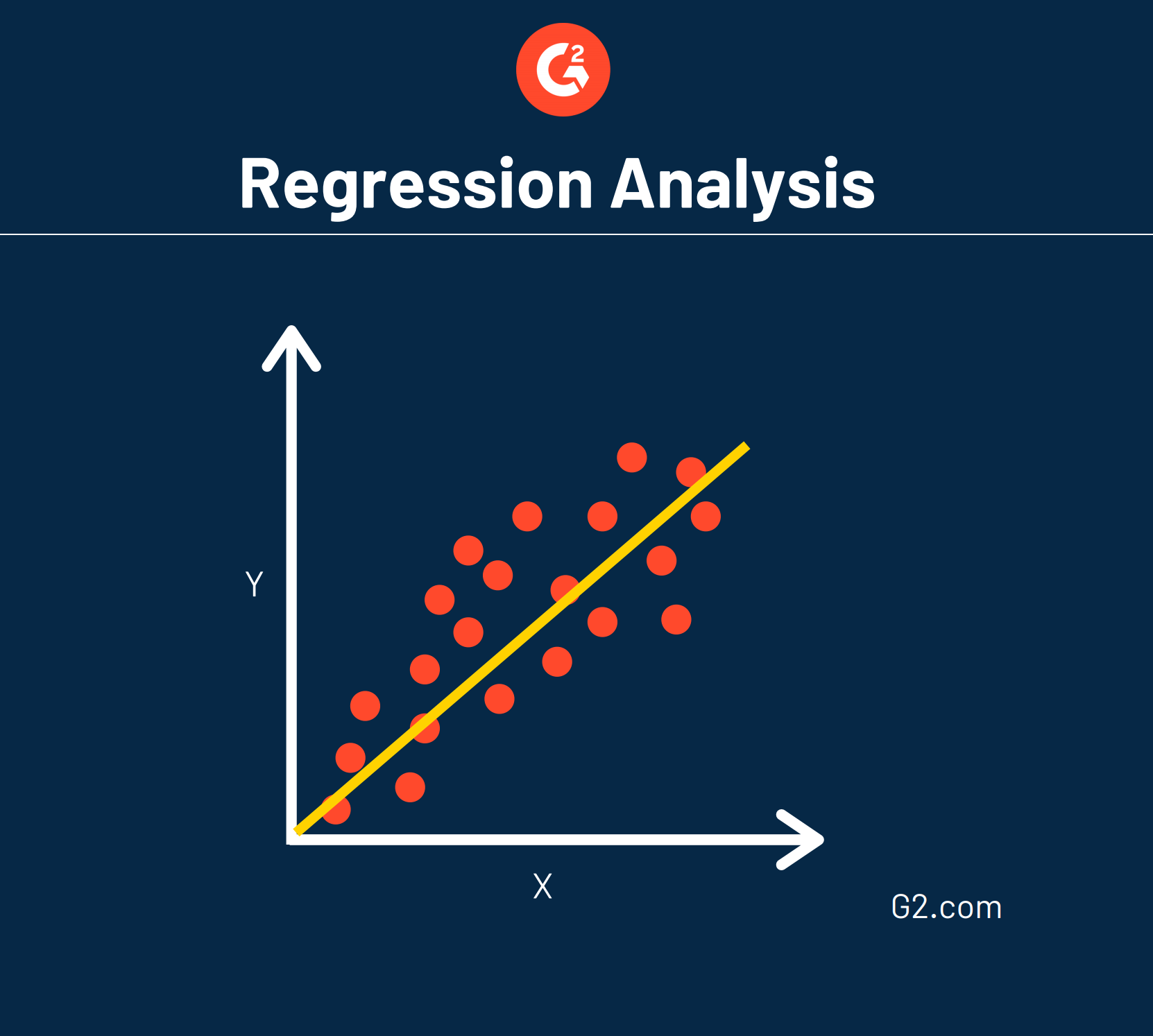
Cela signifie qu'une ligne droite peut être tracée pour montrer comment chaque variable se rapporte à une autre.
En relation : En savoir plus sur la régression, la différence entre corrélation et régression, et quand vous devriez utiliser ces deux mesures statistiques.
Arbre de décision
Une des techniques d'exploration de données les plus visuelles est appelée analyse d'arbre de décision, et c'est une méthode populaire pour la prise de décision importante.
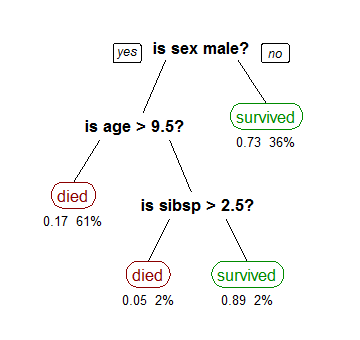
Source: Research Gate
Il existe deux types d'analyses d'arbre de décision. L'un d'eux est appelé classification, ce que vous voyez dans l'exemple ci-dessus déterminant si un passager aurait survécu sur le Titanic. La classification est basée sur la logique, utilisant une variété de conditions si/alors ou oui/non jusqu'à ce que toutes les données pertinentes soient cartographiées.
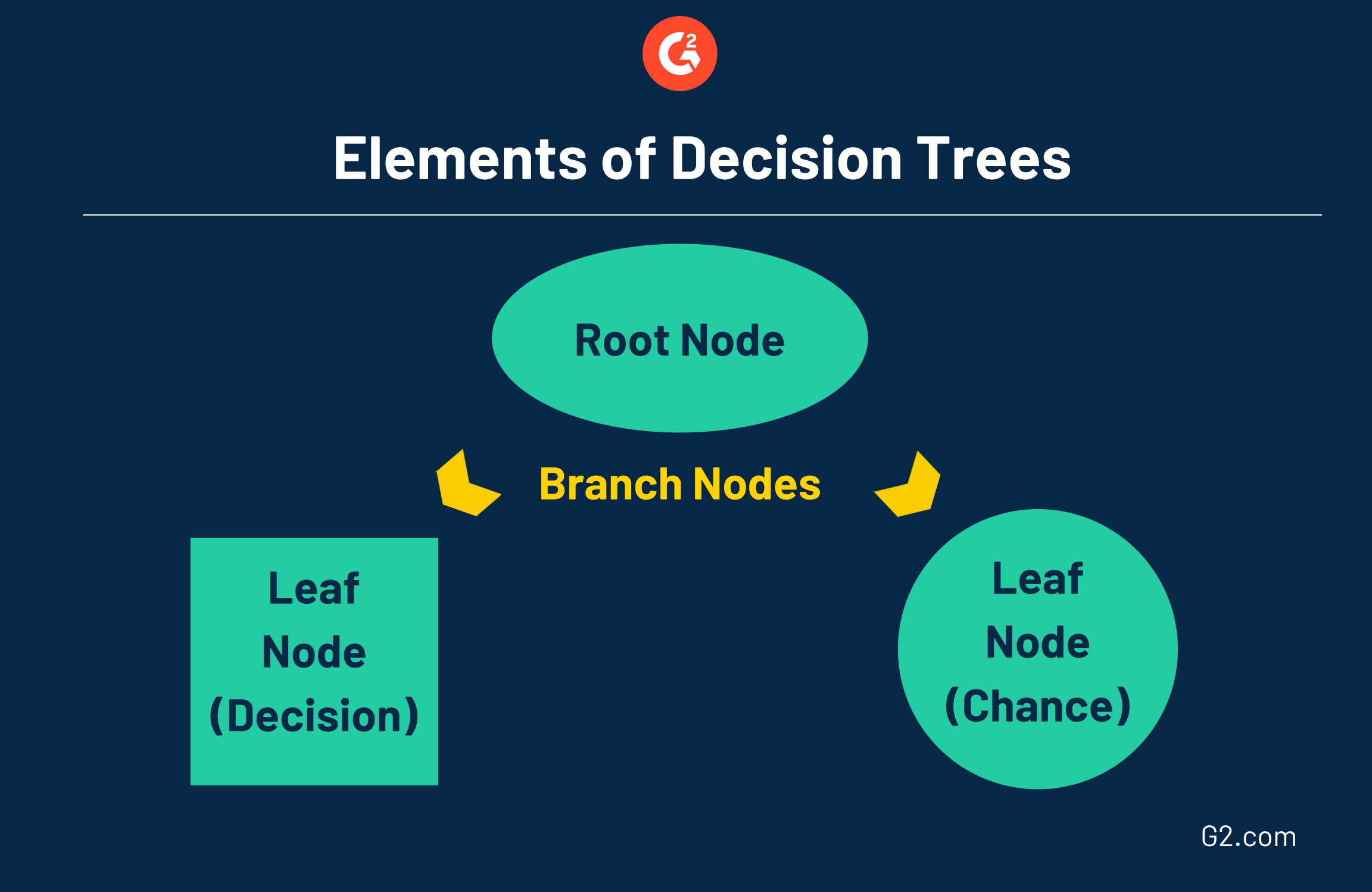
Ces arbres se composent de trois éléments différents :
- Nœud racine : le nœud de niveau supérieur qui représente l'objectif ultime ou la décision que vous essayez de prendre.
- Branches : partant de la racine, les branches représentent différentes options ou cours d'action, qui sont généralement représentées par une flèche.
- Nœud feuille : attaché à la fin des branches, les nœuds feuille représentent les résultats possibles pour chaque action. Un nœud carré indique qu'une autre décision doit être prise, tandis qu'un nœud feuille circulaire indique un événement aléatoire ou un résultat inconnu.
L'autre arbre de décision est appelé régression, qui est utilisé lorsque la décision cible est une valeur numérique. Par exemple, la régression pourrait être utilisée pour déterminer la valeur d'une maison. Les deux arbres de décision peuvent être exécutés via des programmes d'apprentissage automatique.
Vous ne savez pas quel logiciel d'apprentissage automatique utiliser pour votre arbre de décision ? Consultez des centaines d'avis impartiaux offerts gratuitement par G2 !
Un arbre de décision permet à un utilisateur de comprendre clairement comment les entrées de données affectent les sorties. Lorsqu'un arbre de décision est combiné à d'autres pour une analyse prédictive, cela devient ce que l'on appelle une forêt aléatoire. Lorsqu'un modèle de forêt aléatoire devient trop complexe, il est qualifié de technique d'apprentissage automatique en boîte noire car il est difficile de comprendre leurs sorties en fonction des entrées.
Prédiction
Comme son nom l'indique, la prédiction ou l'analyse prédictive utilise une combinaison d'autres techniques d'exploration de données, comme le regroupement et la classification, pour analyser des événements ou des instances passés dans la bonne séquence afin de prédire un événement futur.
Dans la plupart des cas, reconnaître et comprendre les tendances historiques suffit à charger une prédiction précise de ce qui pourrait se passer à l'avenir. Il existe de nombreuses approches de l'analyse prédictive, de l'apprentissage automatique à l'intelligence artificielle. Cependant, une prédiction précise ne dépend pas de ces deux techniques ; elle peut également être déterminée à l'aide de divers algorithmes.
À quoi sert la prédiction ?
De nombreuses organisations utilisent la prédiction pour obtenir un aperçu des tendances qui se produiront ensuite dans leurs données. Comme la détection des valeurs aberrantes, l'analyse prédictive peut également détecter la fraude, les vulnérabilités zero-day et les menaces persistantes. Un exemple spécifique est la façon dont Staples a utilisé la prédiction pour analyser le comportement et fournir une image complète de leurs clients, ce qui a entraîné une augmentation de 137 % du retour sur investissement.
Visualisation des données
La visualisation des données vise à donner aux utilisateurs des informations supplémentaires sur leurs informations en utilisant des graphiques et des diagrammes en temps réel pour mieux comprendre les objectifs de performance. Cette technique est populaire en raison du fait que la visualisation des données est capable de consommer des données de n'importe quelle source via des téléchargements de fichiers, des requêtes de base de données et des connecteurs d'application.
Comment la visualisation des données est-elle utilisée aujourd'hui ?
Grâce aux tableaux de bord créés à l'aide de logiciels de visualisation de données, trouver diverses informations, tendances et indicateurs clés de performance dans les données est plus facile que jamais. Beaucoup de ces outils offrent des fonctionnalités de glisser-déposer et d'autres capacités non techniques, de sorte que l'utilisateur moyen de l'entreprise peut créer les tableaux de bord nécessaires.
Ce type de logiciel est utilisé par les cadres de niveau C, et les équipes des secteurs des ventes, du marketing, du service client et des ressources humaines. Par exemple, les membres de votre équipe de vente utiliseraient ce logiciel pour suivre les chiffres de revenus sur les affaires qu'ils ont conclues, tandis que les équipes de marketing utilisent ces outils pour analyser le trafic Web, les campagnes par e-mail et les impressions sur les réseaux sociaux.
En relation : En savoir plus sur les 67 types de visualisations de données que votre entreprise peut utiliser pour voir la situation dans son ensemble.
Réseaux neuronaux
L'apprentissage neuronal est un type spécifique de modèle d'apprentissage automatique et de technique statistique souvent utilisé en conjonction avec l'intelligence artificielle et l'apprentissage profond, et ce sont certains des modèles d'apprentissage automatique les plus précis que nous utilisons aujourd'hui.
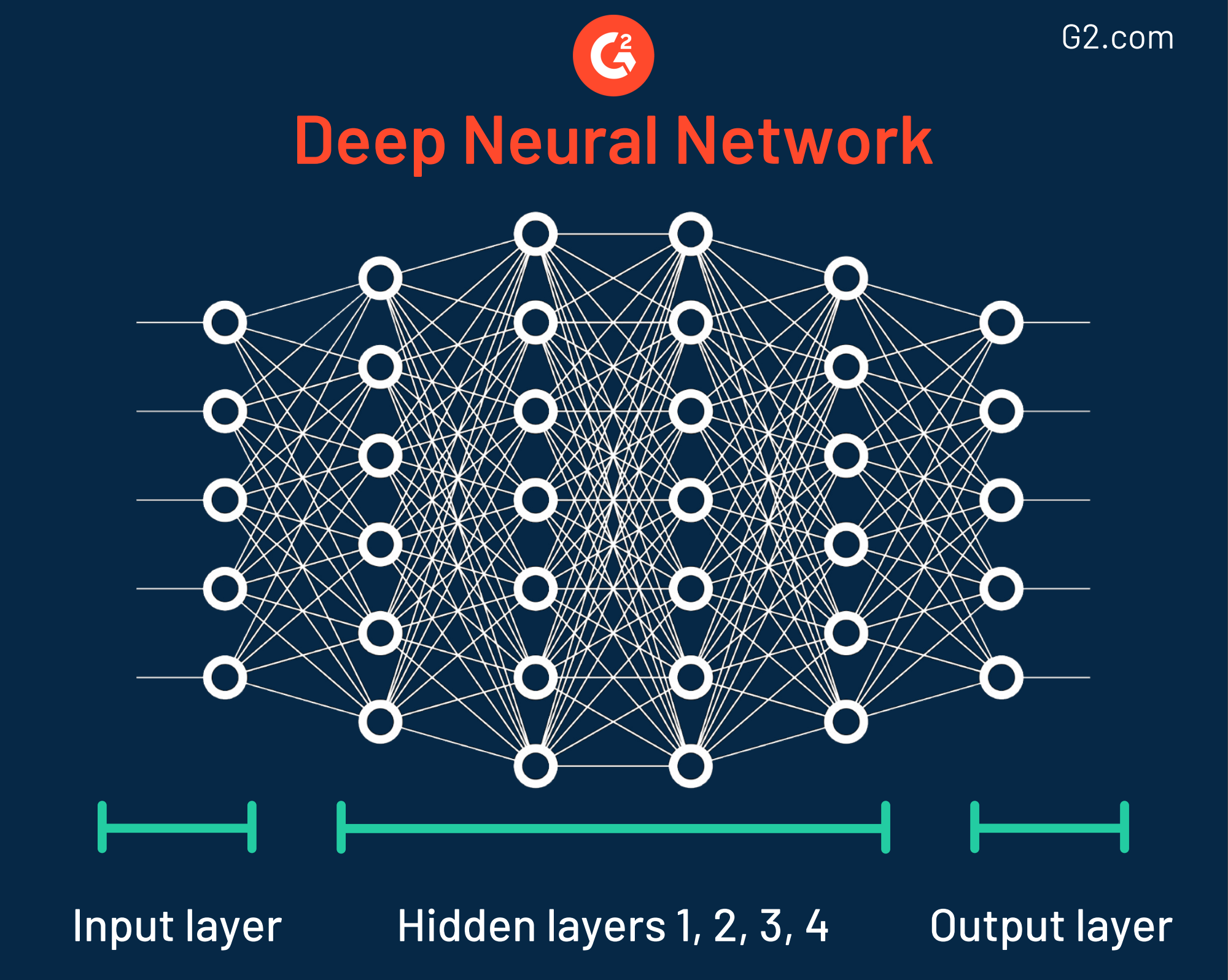
Cette technique d'exploration de données a été nommée lorsqu'elle a été découverte dans les années 1940 car elle comporte différentes couches, toutes ressemblant aux façons dont les neurones fonctionnent dans le cerveau humain. Malgré sa précision, les organisations utilisant des réseaux neuronaux doivent être conscientes du fait que certains de ces modèles sont extrêmement complexes, ce qui rend difficile la compréhension de la façon dont la sortie est déterminée.
En fait, certains réseaux neuronaux sont si incroyablement complexes qu'ils ont jusqu'à 150 couches cachées. Chaque couche joue un rôle clé dans la décomposition des caractéristiques des données brutes. Cela s'appelle formellement l'extraction de caractéristiques.
Comment les réseaux neuronaux sont-ils utilisés aujourd'hui ?
Les réseaux neuronaux avec seulement quelques couches sont utilisés dans les banques et les bureaux de poste pour reconnaître les styles d'écriture manuscrite. Cela est utile lors de l'encaissement de chèques avec votre téléphone mobile.
Des réseaux neuronaux plus complexes avec de nombreuses couches sont actuellement utilisés pour développer des voitures sans conducteur. Extraire des éléments de la route, reconnaître les passages pour piétons et les panneaux de signalisation, et comprendre les mouvements des autres véhicules ne sont que quelques-uns des nombreux types de données brutes décomposées pièce par pièce dans des réseaux neuronaux complexes.
Analyse en composantes principales
La technique d'exploration de données appelée analyse en composantes principales (ACP) est utilisée pour illustrer les connexions cachées entre les variables d'entrée en créant de nouvelles variables qui visualisent les mêmes informations capturées à l'aide des données d'origine mais avec moins de variables. Essentiellement, cette méthode combine des informations corrélées pour former un plus petit nombre de variables appelées « composantes principales » qui représentent la plupart de la variance dans les données.
Le but de réduire le nombre de variables, tout en transmettant la même quantité d'informations, est que les analystes de données puissent améliorer la précision des modèles d'exploration de données supervisés. Essentiellement, cela rend vos données faciles à explorer et à visualiser.
Comment l'analyse en composantes principales est-elle utilisée aujourd'hui ?
L'ACP est le plus souvent utilisée par ceux du secteur financier par ceux qui effectuent et analysent divers taux d'intérêt. Ceux qui travaillent avec des actions et le marché boursier utilisent également l'ACP pour déterminer quelles actions échanger, et quand.
Suivi des motifs
En ce qui concerne les techniques d'exploration de données, le suivi des motifs est une technique fondamentale. Le suivi des motifs implique l'identification et la surveillance des tendances et des motifs dans les données pour faire une présomption intelligente et calculée sur les résultats commerciaux.
Quand le suivi des motifs est-il utilisé aujourd'hui ?
Disons qu'une organisation identifie une tendance dans ses données de vente et l'utilise comme point de départ pour capitaliser sur un aperçu spécifique. Si les données montrent qu'un certain produit se vend mieux que d'autres pour un public particulier, ils peuvent décider d'utiliser ces données pour créer des produits ou services similaires. De même, ils pourraient choisir de mieux stocker le produit d'origine pour ce public.
Entrepôt de données
Aussi connu sous le nom d'entrepôt de données d'entreprise, l'entrepôt de données implique le stockage de données structurées dans des systèmes de gestion de bases de données relationnelles afin qu'elles puissent être analysées pour l'utilisation de rapports et de l'intelligence d'affaires. Les techniques d'exploration de données et d'entrepôt de données d'aujourd'hui utilisent à la fois des entrepôts de données cloud pour un stockage plus sécurisé de ces informations.
Les informations stockées dans ces entrepôts peuvent être utilisées pour :
- Optimisation des stratégies de production : comparer les ventes de produits soit trimestriellement soit annuellement pour gérer les portefeuilles et repositionner les produits
- Analyse client : examiner de plus près les préférences d'achat des clients, les cycles budgétaires, le moment des achats, et plus encore
- Analyse des opérations : aider à analyser les opérations commerciales, les relations avec les clients, et comment établir des connexions environnementales appropriées
Comment l'entrepôt de données est-il utilisé aujourd'hui ?
Les industries de l'investissement et de l'assurance utilisent l'entrepôt de données pour analyser les motifs de données, les tendances des clients, et pour suivre les mouvements du marché. Ceux dans le commerce de détail utilisent les entrepôts de données pour suivre les articles, les motifs d'achat des clients, les promotions, et pour déterminer la politique de tarification.
Découvrez l'inconnu
Utiliser la bonne technique d'exploration de données est sûr de fournir un aperçu sans précédent de votre richesse de données. À mesure que la technologie devient plus avancée, l'exploration de données ne fera que continuer à croître et à trouver des informations plus approfondies.
Retroussez vos manches et plongez profondément dans ce que vos données vous montrent ; vous pourriez être surpris par ce que vous trouvez.
Faites un pas de plus avec toutes ces connaissances et apprenez-en plus sur l'analyse commerciale et comment elle peut être utilisée pour réussir.
Vous voulez en savoir plus sur Logiciel d'apprentissage automatique ? Découvrez les produits Apprentissage automatique.

Mara Calvello
Mara Calvello is a Content and Communications Manager at G2. She received her Bachelor of Arts degree from Elmhurst College (now Elmhurst University). Mara writes content highlighting G2 newsroom events and customer marketing case studies, while also focusing on social media and communications for G2. She previously wrote content to support our G2 Tea newsletter, as well as categories on artificial intelligence, natural language understanding (NLU), AI code generation, synthetic data, and more. In her spare time, she's out exploring with her rescue dog Zeke or enjoying a good book.

