



Los datos en bruto no tienen sentido. Prepararlos para el negocio implica mucho tiempo, recursos y, por supuesto, café.
Los científicos de datos gestionan los datos de tres maneras: gestión, análisis y visualización. Los modelos de aprendizaje automático (ML) son una combinación de todos ellos. Verifican tus datos, prueban su usabilidad y los convierten en tus expectativas.
La necesidad de modelos de aprendizaje automático está explotando en industrias comerciales y no comerciales. La optimización de datos con software de inteligencia artificial y operacionalización del aprendizaje automático se ha convertido en el núcleo de todas las operaciones de producción. Donde la mayoría de las empresas buscan despedir clientes, los modelos de aprendizaje automático están provocando una gran revolución impulsada por los datos.
¿Qué son los modelos de aprendizaje automático?
Un modelo de aprendizaje automático es una representación gráfica de datos del mundo real. Está programado en un entorno de datos integrado y trabaja en casos de negocio de la vida real. Se entrena con datos antiguos y trabaja con datos nuevos. Toma tiempo programar, probar y validar modelos de aprendizaje automático antes de utilizarlos para tomar decisiones empresariales.
Las incursiones en el aprendizaje automático y la inteligencia artificial (IA) se remontan al siglo XX. La idea de la "generación de supercomputadoras" o "quinta generación de computadoras" creó un auge tecnológico en un mundo de computadoras al vacío.
Historia de los modelos de aprendizaje automático
La concepción temprana del aprendizaje automático comenzó en 1943 cuando el lógico Walter Pitts y el neurocientífico Warren McCulloch construyeron un modelo matemático de una red neuronal. Su objetivo era replicar el funcionamiento del cerebro humano. Una década después, el científico informático Arthur Samuel acuñó el término "aprendizaje automático" y lo describió como "la capacidad de una computadora para aprender sin ser programada explícitamente."
El concepto nació por primera vez en 1945, cuando Joseph Weizenbaum descubrió el procesamiento del lenguaje natural (NLP) como una derivación de la inteligencia artificial. Lentamente, los conceptos más nuevos de aprendizaje automático reemplazaron a los más antiguos. Lentamente, con la evolución de big data, el aprendizaje automático incubó una forma más avanzada de inteligencia computacional. Esta inteligencia era más precisa, enfocada y ligera que las invenciones anteriores.
Aunque los modelos de aprendizaje automático no eran 100% precisos en términos de resultados, proporcionan una predicción constante. La precisión de la predicción también dependía del tipo de datos de entrenamiento con los que trabajaba. Estos modelos aprendieron las similitudes entre datos externos e internos para hacer proyecciones.
El aprendizaje automático a lo largo de los años
- 1945: El primer concepto de procesamiento del lenguaje natural (NLP) fue creado por Joseph Weizenbaum
- 1949: The Organization of Behaviour, que habló sobre redes neuronales por primera vez, publicado por Donald Hebb
- 1950: Invención de la prueba de Turing, que se realizó para verificar la inteligencia y fluidez de las computadoras.
- 1951: La calculadora de refuerzo analógico neuronal estocástico (SNARC) máquina, el primer dispositivo conceptual basado en una red neuronal artificial, fue creado.
- 1966: Diseño de Shakey, el primer robot basado en IA
- 1967: Algoritmo de k-vecinos más cercanos ideado
- 1979: Invención del Stanford Cart, un carrito de autoasistencia controlado a distancia
- 1986: Invención de la máquina de Boltzmann restringida (RBM)
- 1995: Lanzamiento del "algoritmo de bosque aleatorio"
- 2006: Primera charla sobre "algoritmos de aprendizaje profundo" por Geoffrey Hinton
- 2009: Fei Fei Li desarrolló ImageNet, una base de datos basada en imágenes
- 2012: Introducción de Google Brain, por Google Inc.
- 2014: Reconocimiento facial de Facebook, DeepFace, lanzado
- 2016: Victoria de Alphago, impulsado por IA de Google, contra jugadores de juegos de estrategia
- 2018: Invención de perceptrones multicapa, redes generativas adversarias y redes de aprendizaje profundo q.
- 2020: Estandarización de realidad aumentada y realidad virtual
- 2022: Internet de las cosas, 5G Edge y ML automatizado
¿Quieres aprender más sobre Software de Redes Neuronales Artificiales? Explora los productos de Red neuronal artificial.
Cuándo usar modelos de aprendizaje automático
Los modelos de aprendizaje automático se utilizan para extraer información de datos ya existentes. Se utilizan para automatizar operaciones comerciales y fomentar el crecimiento. Sin embargo, ciertos problemas pueden no necesitar un enfoque basado en datos. Tales problemas no requieren aprendizaje automático y pueden abordarse con cálculos matemáticos estándar. Algunos escenarios elegibles donde el aprendizaje automático es imprescindible son:
- Incapacidad de reglas: En lugares donde necesitas detectar spam de correo electrónico, se pueden usar aplicaciones de aprendizaje automático como HoxHunt. Los algoritmos de Hoxhunt predicen oportunidades de spam potenciales y te impiden ir a la URL maliciosa a través de un correo electrónico de spam. El correo electrónico de spam parece 99% genuino y no puede ser detectado a través de reglas simples. Un algoritmo robusto de aprendizaje automático determina todos los factores de phishing y detiene al usuario.
- Incapacidad de escala: Puedes reconocer algunos correos electrónicos de phishing, pero no todos. El phishing es una técnica de hacking que es invisible para el ojo no entrenado. Hace que un correo electrónico parezca genuino mientras almacena tus detalles privados en una base de datos oculta. Un algoritmo de ML maneja y resuelve este problema a gran escala.
- Ciberseguridad: Con modelos de aprendizaje automático, las soluciones de software de ciberseguridad pueden analizar patrones, detectar anomalías en grandes cantidades de datos de registro y encontrar correlaciones. Esto previene ataques de seguridad a las empresas.
¿Sabías? Puedes evaluar un modelo de aprendizaje automático con validación cruzada. Involucra entrenar el modelo con datos de entrada y probarlo con datos de prueba complementarios. Previene el sobreajuste del modelo y ayuda a dibujar patrones similares para futuras predicciones.
Diferentes tipos de modelos de aprendizaje automático
Existen tres tipos principales de modelos de aprendizaje automático. Aunque todas las técnicas de modelado de aprendizaje automático trabajan con un propósito común, su forma de abordar un problema de datos difiere.

A medida que estos modelos se exponen a más muestras de datos y entradas, mejoran en el aprendizaje y el cálculo de valores predichos. Los modelos desarrollan inteligencia con el tiempo, el aprendizaje constante y la experimentación.
1. Aprendizaje supervisado
En aprendizaje supervisado, el modelo de aprendizaje automático se enseña con entradas predefinidas.
El modelo está equipado con señales de entrada y salida. Solo necesita averiguar cómo llegar a un valor de salida. El modelo de aprendizaje automático pasa por el proceso de entrenamiento, mapea características y las clasifica para los datos entrantes.
Luego, intenta captar la señal de salida más cercana a medida que el valor de entrada se almacena. Utiliza expresiones booleanas para calcular valores de datos. Los científicos de datos o ingenieros de ML entrenan este modelo con un conjunto de datos conocido que comprende entrada y salida. El algoritmo necesita idear una estrategia de interpretación por sí mismo. Si ocurre una discrepancia, el usuario humano la corrige.
El proceso se repite hasta que el modelo recibe un alto grado de precisión. Ejemplos de aprendizaje supervisado incluyen reconocimiento óptico de caracteres, reconocimiento de patrones y reconocimiento de voz.
2. Aprendizaje no supervisado
Los modelos de aprendizaje automático no supervisado identifican patrones ocultos en los datos para formar relaciones y sacar conclusiones. Procesan conjuntos de datos de entrada comparándolos con información almacenada. La tasa de precisión de un algoritmo no supervisado solo crece cuando trabaja con tantos datos nuevos como sea necesario.
Ejemplo: Si el aprendizaje automático no supervisado se ejecuta en una imagen de perros y gatos, no puede decir si la imagen es de un perro o un gato porque sus atributos físicos son demasiado similares. No podrá distinguir sus características separadas y devolverá un resultado confuso. La precisión de clasificación del modelo aumenta cuando se ejecuta en múltiples imágenes.
3. Aprendizaje por refuerzo
En aprendizaje por refuerzo, el algoritmo se comporta como un agente inteligente que aprende de cada operación fallida. El modelo se adapta a partir de salidas incorrectas y se esfuerza por lograr el objetivo final. Un ciclo de retroalimentación recompensa al modelo con inteligencia adquirida cuando la salida es correcta. Pero cuando es incorrecta, el modelo aprende de sus errores.
Cada uno de estos tres tipos de modelos de aprendizaje automático abarca diferentes técnicas de creación de modelos. Veamos los más populares por ahora.
Tipos de aprendizaje supervisado
La clasificación, la regresión y la previsión son técnicas de análisis de datos bajo el aprendizaje supervisado.
Clasificación
En tareas de clasificación, el modelado de ml ayuda a asignar una categoría a los datos. Deben sacar conclusiones de los valores observados para clasificar la salida. Por ejemplo, al clasificar datos de pacientes como "nuevos" o "antiguos", un modelo de ML debe observar las fechas de registro existentes para clasificar los datos.
Los dos tipos de algoritmos de clasificación son clasificación binaria y clasificación multiclase. Los clasificadores binarios devuelven la salida como sí/no o verdadero/ falso. Solo son responsables de verificar si una clase de datos particular está presente o no. Por otro lado, si el problema tiene más de dos resultados posibles, se llama problema de clasificación multiclase.
Regresión
La regresión es un método de aprendizaje automático centrado en una variable dependiente para una serie de variables de salida. El análisis de un algoritmo de regresión hace que las predicciones sean precisas y útiles. Pasa por una serie de pasos como la direccionalidad de los datos, el análisis de varianza (ANOVA), la prueba de hipótesis y la creación final del modelo.
Los modelos de aprendizaje automático resuelven siete tipos de problemas de regresión:
-
Regresión lineal es una técnica de análisis de datos que analiza la relación entre variables de entrada y salida. Puede haber múltiples modelos de regresión lineal para un problema. Ayuda a correlacionar mejor los datos y crear una relación de variable a variable, como el impacto de la presión atmosférica en el cambio topográfico.
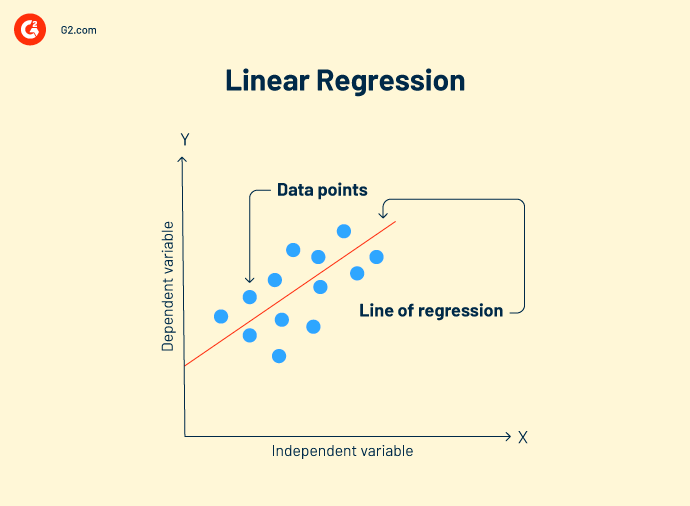
Fórmula de regresión lineal:
Y = mx+c+e
Y = valor predicho
m = variable dependiente
c = constante
e = residuo de error
El objetivo de la regresión lineal es encontrar un modelo de buen ajuste que muestre predicciones precisas en datos de prueba.
-
Regresión logística trabaja con datos categóricos. Su concepto de trabajo es similar al de la regresión lineal. Establece una relación entre variables dependientes e independientes para calcular variables predichas. Sin embargo, la variable de salida solo puede tener dos valores, sí o no.
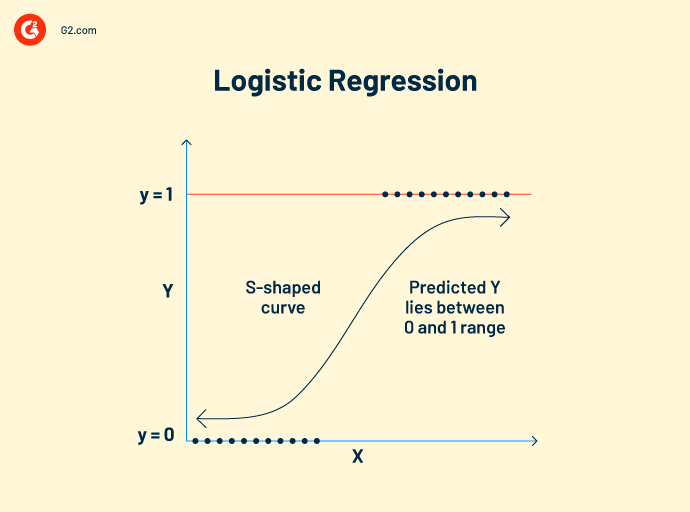
El modelo de regresión logística predice valores booleanos como 0 y 1 o verdadero y falso. Eso lo hace popular como un algoritmo de visión por computadora para detectar la presencia de obstáculos externos.
Fórmula de regresión logística:
Esta fórmula está representada por la función logit, que mide la relación entre la variable objetivo y las variables independientes.
Logit (p) = In(p/(1-p)) = b0+b1X2+b2X2……+bkXk
p = probabilidad de una característica
-
Árboles de decisión o flujos de trabajo de decisión agrupan todos los posibles resultados de un evento en una estructura similar a un árbol. El árbol tiene nodos definidos, ramas y desencadenantes de eventos. Cada nodo interno es una representación de datos de prueba. Los datos de prueba se ejecutan en nodos internos para predecir resultados.
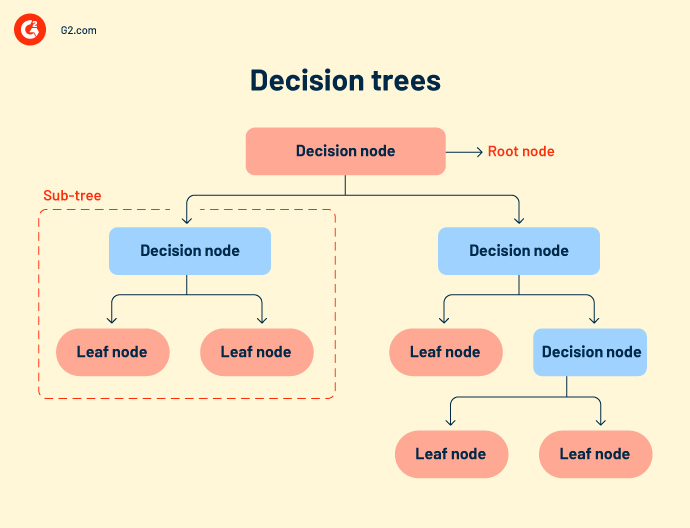
Aunque los árboles de decisión son simples e intuitivos, carecen de precisión. Como comprende muchos nodos, a veces el sistema se confunde durante el cálculo de la salida.
Los árboles de decisión se utilizan principalmente en investigación y desarrollo de productos, análisis operativo y planificación financiera estratégica. - Bosque aleatorio se refiere a un gran número de árboles de decisión que se agrupan. Cada nodo del árbol predice la presencia de una categoría a través de un agregador de votación. Si la mayoría de los nodos votan por la misma salida, se elige esa salida. El bosque aleatorio es más complejo que otros algoritmos de regresión. Puede usarse tanto para clasificación como para correlaciones.
- K-vecinos más cercanos (KNN) es uno de los algoritmos de aprendizaje más simples. Clasifica tus datos en función de los puntos de datos más cercanos de una categoría. El algoritmo KNN asume que los nuevos datos provienen del mismo contexto que los datos antiguos y procesa rápidamente la salida.
- Clasificadores de Bayes ingenuos se basan en el teorema de Bayes. Es un clasificador probabilístico que determina la probabilidad de una clase para los datos. Es uno de los modelos de ML más nuevos, rápidos y precisos. Los equipos de datos lo utilizan para realizar análisis de consumidores, análisis de sentimientos y clasificación de artículos.
- Máquina de vectores de soporte (SVM) es un modelo de clasificación y regresión utilizado principalmente para reconocimiento de imágenes o reconocimiento de objetos. Los mapas de características extraídos del modelo principal y la ubicación de los datos se alimentan a un clasificador SVM, que combina estos datos para predecir la categoría requerida.
3. Previsión
La previsión es una metodología basada en tendencias que predice el futuro con datos del presente o del pasado. Se utiliza principalmente para extrapolar las tendencias comerciales actuales y el potencial de mercado para empresas que toman decisiones de inversión. El método más destacado de previsión es la previsión de series temporales.
La previsión de series temporales es un método de análisis de datos para hacer predicciones científicas. Involucra la construcción de modelos a través del análisis de datos históricos durante un período de tiempo específico. Ejemplos incluyen la previsión del clima, la previsión de desastres naturales y la previsión de epidemias. La precisión de la previsión de series temporales es cierta ya que trabaja con datos probatorios.
Los ejemplos son XGboost, suavización exponencial, autorregresivo y DeepAR.
Tipos de aprendizaje no supervisado
Los científicos de datos o ingenieros de ML utilizan el aprendizaje no supervisado para construir modelos de aprendizaje automático de autoasistencia. Estos modelos aprenden y mejoran por sí mismos, sin datos externos.
Agrupamiento
El agrupamiento es el proceso de dividir los datos de entrada en grupos de categorías similares para una clasificación posterior. Dos métodos efectivos de agrupamiento son los más adecuados para tus datos.
-
Agrupamiento exclusivo: Este método coloca puntos de datos similares en grupos definidos. Los grupos de datos son mutuamente excluyentes. Por ejemplo, todos los estados de América del Norte se colocarán en un grupo y América del Sur en otro. Los grupos no se superpondrán en ninguna etapa del proceso de análisis.
- Agrupamiento jerárquico: También conocido como agrupamiento de abajo hacia arriba, este es una forma más refinada y organizada de agrupar tus datos. El algoritmo trata cada conjunto de datos como un solo grupo y los fusiona en un superconjunto. Al agrupar datos, puedes elegir entre agrupamiento aglomerativo o agrupamiento divisivo.
Muestreo aleatorio
El muestreo aleatorio es un método de interpretación estadística que crea muestras aleatorias de datos. Agrupa los datos en diferentes grupos según su naturaleza, tipo y comportamiento. Se utiliza para calcular censos, oferta y demanda de productos, y recolección de ingresos en áreas particulares. El muestreo aleatorio es similar al agrupamiento pero no es confiable en términos de precisión.
Aprendizaje de reglas de asociación
El aprendizaje de reglas de asociación impone ciertas reglas para la clasificación de datos. Crea relaciones y patrones interesantes entre los datos y mapea co-dependencias de una manera que genera el máximo beneficio. Ejemplos son minería de datos o análisis de cesta de mercado.
Reducción de dimensionalidad
Esta técnica elimina datos sucios, valores atípicos y valores desiguales, haciendo que el conjunto de datos de entrada sea más limpio y nítido. Ejemplos incluyen el análisis de componentes principales o el agrupamiento K-means.
Aprendizaje profundo
El aprendizaje profundo requiere grandes conjuntos de datos y alta potencia computacional gráfica (GPU) para predecir la clase de variables de entrada. Involucra redes neuronales que están compuestas por funciones de activación y nodos de activación. La red acepta entrada a través de la capa de entrada, activa nodos de decisión a través de la función de activación y procesa la salida. Los modelos más significativos son:
- Autoencoders
- Máquina de Boltzmann
- o Redes Neuronales Convolucionales
- o Perceptrón multicapa
- o Redes Neuronales Recurrentes
Tipos de aprendizaje por refuerzo
Errar es humano. Errar también es de máquinas.
El aprendizaje por refuerzo asigna un agente inteligente para trabajar con datos. Estas acciones inteligentes toman acción en un entorno de aprendizaje automático para predecir resultados correctos. Si el aprendizaje por refuerzo predice una salida correcta, obtiene una recompensa acumulativa. Es uno de los tres paradigmas básicos de ML del aprendizaje por refuerzo.
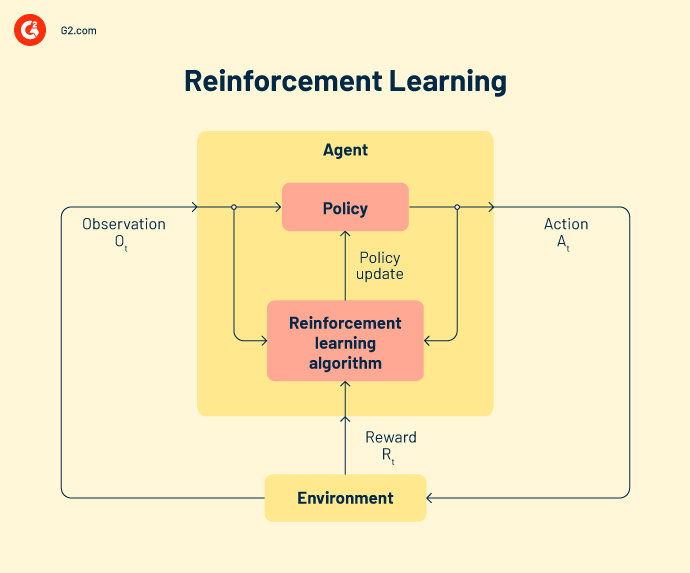
Algunos modelos de refuerzo populares incluyen.
Q-learning es un algoritmo de refuerzo popular que ayuda a los agentes de IA a tomar decisiones sabias. Con este algoritmo, puedes calcular el valor q, tomar la acción requerida y maximizar los puntos de recompensa.
State-action-reward-state-action (SARSA) es un algoritmo en política que calcula el valor q para cada par de estado-acción. Para cada estado específico de la entrada, hay una salida designada y una recompensa designada en caso de que la salida sea precisa. Cada letra en SARSA representa una fila.
Una red Q. profunda, o red Q. neural profunda, es una red neuronal artificial que tiene muchas capas computacionales. Procesa la salida basada en la entrada, los pesos y el sesgo añadido.
Diferentes modelos de aprendizaje automático tienen diferentes utilidades y logran diferentes conjuntos de objetivos. Debes elegir qué modelo funcionará mejor para ti a largo plazo.
Algoritmo vs. modelo de aprendizaje automático vs. modelo de aprendizaje profundo
No importa el enfoque, el resultado final siempre es un modelo que actúa sobre los datos. Aprendizaje profundo. El aprendizaje automático o el algoritmo es el segundo nombre de la gestión de datos, como podría atestiguar tu científico de datos.
-png.png)
Los algoritmos son un conjunto de expresiones de programación que son autoexplicativas. Ejecutan un hilo de comandos en los datos de entrada. Un algoritmo de aprendizaje automático se codifica en herramientas de código abierto como Python, Java o TensorFlow. Necesitas llamar a un paquete específico de la biblioteca de paquetes e instalar sus directorios. Después de eso, puedes cargar tus conjuntos de datos, establecer el eje y crear modelos. Algunos paquetes son Scikit learn, NumPy o Matplotlib.
El modelo de aprendizaje automático es la creación final de un algoritmo de datos. Los modelos se categorizan como sesgados, normales o de buen ajuste. Las propiedades de los datos y la precisión del algoritmo son los principales contribuyentes a un modelo de aprendizaje automático. El modelo se despliega en datos de prueba y se extiende a las aplicaciones de flujo de trabajo de una organización.
El modelo de aprendizaje profundo está un paso adelante de los modelos de aprendizaje automático. Estos modelos están entrenados para extraer y almacenar características individuales de los datos y luego usarlas para hacer predicciones precisas. Sin embargo, estos sistemas de computación necesitan grandes conjuntos de datos, conjuntos de imágenes y alta potencia computacional gráfica (GPU). Ejemplos son la red neuronal convolucional (CNN), la red neuronal convolucional recurrente (R-CNN) y "solo miras una vez" (YOLO).
Comprender las tecnicidades de los datos puede ser muy complicado. Y mucha de la complicación radica en cómo eliges tus modelos de ML.
Consejo: Puedes usar aprendizaje automático como servicio (MLaaS) para externalizar procesos de aprendizaje automático para los flujos de trabajo de tu negocio. Este servicio es una colección de diferentes software basados en la nube que despliegan herramientas de aprendizaje automático para proporcionar soluciones de análisis predictivo a tus equipos de ML para varios casos de uso empresarial.
Cómo elegir el mejor modelo de aprendizaje automático para tu negocio
Para encontrar el mejor modelo, observa detenidamente tu infraestructura de TI existente. Tu red local actual allanará el camino para la compatibilidad futura de hardware y software. Ten en cuenta tu presupuesto, ancho de banda, red de área local (LAN), ancho de banda de los científicos de datos y otras políticas de mantenimiento de instalaciones para hacer que tus modelos de aprendizaje automático funcionen en conjunto.
Una forma segura es comenzar pequeño. Construye un marco de prueba de concepto y evalúa tu madurez en IA. Usa atributos de datos existentes, volumen, características y complejidad para construir un modelo de aprendizaje automático intermedio. Valídalo y pruébalo para proyectos pequeños y casos de uso empresarial. Cuando tu modelo se ajuste a los datos, desplégalo a mayor escala.
A medida que avanzas, cuenta con más ancho de banda del equipo, presupuesto y esfuerzos de los científicos de datos. Se requiere mucho esfuerzo para gestionar, entrenar y diagnosticar modelos de ML, lo que puede consumir tus recursos empresariales.
¿Sabías? El mercado global de inteligencia artificial fue valorado en $93.5 mil millones en 2021 y se proyecta que se expanda a una tasa de crecimiento anual compuesta del 38.1% de 2022 a 2030.
Fuente: Grand View Research
Mientras que el modelo de aprendizaje automático representa tus datos matemáticamente, no entra en acción por sí solo.
Tus datos son tu pista de despegue
El aprendizaje automático es el presente, pero también ilumina el camino hacia un futuro digital. Reúne una gran cantidad de investigación, estudia los procesos existentes y decide qué opción te pondrá al frente del mercado de software.
aprende cómo puedes elegir el modelo correcto de ciencia de datos y aprendizaje automático para tu negocio.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

