



El aprendizaje profundo es la forma en que una máquina inteligente aprende cosas.
Es un método de aprendizaje para máquinas, inspirado en la estructura del cerebro humano y en cómo aprendemos.
Es una tecnología crítica que hace que los vehículos autónomos sean una realidad y también es la razón por la que el asistente de voz de tu smartphone mejora con el tiempo al asistirte. En otras palabras, el aprendizaje profundo es nuestra mejor oportunidad para crear máquinas con inteligencia similar a la humana.
¿Qué es el aprendizaje profundo?
El aprendizaje profundo (DL) es un subcampo del aprendizaje automático que imita el funcionamiento del cerebro humano en el procesamiento de datos. DL permite a las máquinas aprender sin supervisión humana y les otorga la capacidad de reconocer el habla, traducir idiomas, detectar objetos e incluso tomar decisiones basadas en datos.
En otras palabras, el aprendizaje profundo es un tipo de aprendizaje automático (ML) inspirado en la estructura del cerebro humano. En efecto, DL es una imitación de las neuronas del cerebro humano y trata de imitar sus funciones.
Aunque el aprendizaje profundo es una rama del aprendizaje automático, los sistemas DL no están restringidos por una capacidad finita para aprender como los algoritmos tradicionales de ML. En cambio, los sistemas DL pueden aprender y mejorar su rendimiento con acceso a volúmenes más grandes de datos.
El aprendizaje profundo permite a los sistemas de inteligencia artificial imitar la manera en que los humanos adquieren ciertos tipos de conocimiento. Los algoritmos DL intentan sacar conclusiones, similar a cómo lo hacen los humanos, analizando continuamente los datos. Para lograr esto, DL utiliza redes neuronales artificiales (ANNs).
DL imita el funcionamiento del cerebro humano, principalmente las funciones como el procesamiento de datos y la creación de patrones para la toma de decisiones. Es interesante notar que los científicos e investigadores de IA comenzaron a construir ANNs para que las máquinas pudieran eventualmente exhibir las características de la inteligencia humana, como habilidades para resolver problemas, autoconciencia, percepción, creatividad y empatía, por nombrar algunas.
El aprendizaje profundo no habría sido posible sin que las computadoras se volvieran más baratas, rápidas y pequeñas. Lo mismo es cierto para los dispositivos de almacenamiento, ya que se necesita almacenar y procesar grandes cantidades de datos para que el aprendizaje profundo se convierta en una realidad. Es por eso que, aunque el aprendizaje profundo fue teorizado en la década de 1980, se volvió factible solo recientemente.
Procesar volúmenes tan enormes de datos no estructurados es prácticamente imposible para los humanos. Incluso si logramos adquirir la mano de obra necesaria, podría llevar años analizar y extraer información relevante de esos grandes conjuntos de datos. Sin embargo, con el aprendizaje profundo, este proceso se simplifica asombrosamente.
Con la ayuda del aprendizaje profundo, un sistema de IA puede aprender y mejorar sin ninguna supervisión humana. DL también permite a las máquinas aprender de datos que no están etiquetados o estructurados, o ambos. Sin embargo, ten en cuenta que el proceso de aprendizaje puede ser no supervisado, semi-supervisado o supervisado.
El aprendizaje profundo también es una parte crítica de la ciencia de datos. Es beneficioso para los científicos de datos recopilar, analizar e interpretar grandes volúmenes de datos y hace que procesos como el modelado predictivo sean más rápidos y eficientes.
Ramas de la inteligencia artificial como la visión por computadora y el procesamiento del lenguaje natural son practicables gracias al aprendizaje profundo. Antes de profundizar en eso, veamos cómo funciona el aprendizaje profundo para ayudarnos.
¿Cómo funciona el aprendizaje profundo?
En términos más simples, el proceso de aprendizaje de DL ocurre modificando las acciones del sistema basado en un ciclo de retroalimentación continua. El sistema de aprendizaje es recompensado por cada acción correcta y castigado por las incorrectas. El sistema intenta ajustar sus acciones para maximizar la recompensa.
El aprendizaje profundo utiliza modelos de aprendizaje supervisado, semi-supervisado, así como no supervisado para entrenar.
Las neuronas que forman las redes neuronales pueden clasificarse en tres categorías según su jerarquía: capas de entrada, ocultas y de salida.
- La capa de entrada, que es la primera capa de neuronas, recibe los datos de entrada y los pasa a la primera capa oculta.
- Las capas ocultas realizan cálculos específicos, como el reconocimiento de imágenes, sobre los datos recibidos.
- Una vez que se completan los cálculos, la capa de salida genera la salida requerida.
Como se mencionó anteriormente, el aprendizaje profundo es posible gracias a las redes neuronales artificiales. Están construidas inspirándose en las redes neuronales del cerebro humano. Un gran número de perceptrones, la contraparte artificial de las neuronas, se apilan juntos para formar ANNs.
El término "profundo" se utiliza para especificar el número de capas ocultas que tienen las redes neuronales. Mientras que las redes neuronales tradicionales contienen de dos a tres capas ocultas, las redes profundas pueden tener incluso 150 capas.
Una forma fácil de entender cómo funciona el aprendizaje profundo es observando las redes neuronales convolucionales (CNNs). Es uno de los tipos más populares de redes neuronales profundas, además de las redes neuronales recurrentes (RNNs), las redes generativas adversarias (GANs) y las redes neuronales de avance.
La CNN extrae características directamente de las imágenes, eliminando la necesidad de extracción manual de características. Ninguna de las características está preentrenada; en cambio, son aprendidas por la red cuando se entrena con el conjunto de imágenes dado. Esta característica de extracción automática de características hace que los modelos de aprendizaje profundo sean altamente efectivos para la clasificación de objetos y otras aplicaciones de visión por computadora.
La razón por la que las redes neuronales profundas son altamente precisas en la identificación de características y clasificación de imágenes se debe a las cientos de capas que poseen. Cada capa aprendería a identificar características específicas, y a medida que aumenta el número de capas, aumenta la complejidad de las características de imagen aprendidas.
¿Quieres aprender más sobre Software de Redes Neuronales Artificiales? Explora los productos de Red neuronal artificial.
Aprendizaje profundo vs. aprendizaje automático
El aprendizaje automático es una aplicación de la IA que permite a las máquinas aprender y avanzar automáticamente a partir de la experiencia, sin ser programadas explícitamente para hacerlo.
El algoritmo de filtrado de spam presente en tu cuenta de correo electrónico es un excelente ejemplo de un algoritmo de aprendizaje automático. Los algoritmos de ML también se utilizan en plataformas OTT como Netflix para recomendar películas y series que es más probable que veas y disfrutes.
Los algoritmos de ML son capaces de analizar datos, identificar patrones y hacer predicciones. Aprenden y se adaptan a medida que se les introducen nuevos conjuntos de datos. De alguna manera, el aprendizaje automático hace que las computadoras sean más humanas ya que les otorga la capacidad de aprender y progresar.
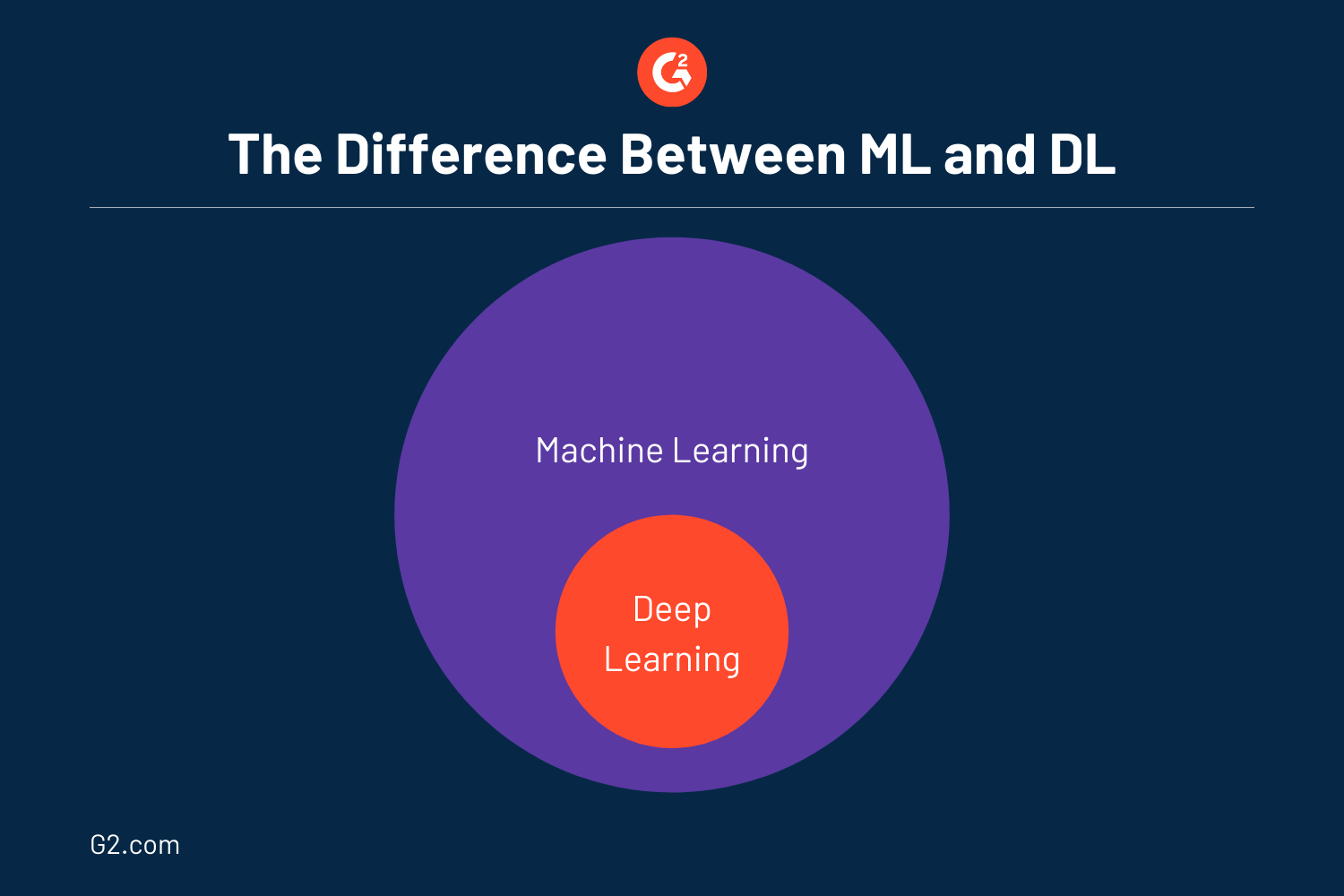
Como se mencionó anteriormente, el aprendizaje profundo es un subconjunto del aprendizaje automático, que a su vez es un subconjunto de la inteligencia artificial. Más específicamente, el aprendizaje profundo es en realidad aprendizaje automático y puede considerarse una versión evolucionada de este último. Muy a menudo, muchos usan DL y ML de manera intercambiable ya que funcionan casi de manera similar.
Sin embargo, sus capacidades son diferentes. Aunque los algoritmos de ML pueden aprender y mejorar gradualmente, todavía necesitan alguna forma de orientación. Por ejemplo, si el algoritmo hace una predicción incorrecta, entonces la intervención humana es esencial para hacer ajustes. Por el contrario, los algoritmos de aprendizaje profundo pueden determinar si sus predicciones son precisas o no con la ayuda de redes neuronales artificiales.
El programa AlphaGo desarrollado por DeepMind utiliza extensamente el aprendizaje profundo. Es el primer programa de computadora en vencer a un jugador profesional humano de Go. AlphaGo fue sucedido por numerosas versiones avanzadas, incluyendo MuZero, que puede dominar un juego sin que se le enseñen las reglas.
Es interesante notar que los investigadores han intentado usar técnicas tradicionales de aprendizaje automático para entrenar robots para dominar el juego durante muchos años. Pero solo tuvieron éxito cuando combinaron el aprendizaje profundo con el aprendizaje por refuerzo y otros paradigmas.
Otra forma de diferenciar entre el aprendizaje automático y el aprendizaje profundo es observando cómo aprenden. Supongamos que tienes que enseñar a una máquina a categorizar las imágenes de perros y gatos. Si estás utilizando el modelo de aprendizaje automático, tendrás que proporcionar datos estructurados, en este caso, las imágenes etiquetadas de perros y gatos, para que el algoritmo aprenda las características específicas que diferencian las imágenes de ambos animales. El algoritmo mejora con cada imagen etiquetada a la que se expone.
| Aprendizaje automático | Aprendizaje profundo | |
| Supervisión humana | Requerida | No requerida |
| Datos etiquetados | Requeridos | No requeridos |
| Tiempo de entrenamiento | Segundos o unas pocas horas | Horas o unas pocas semanas |
| Número de puntos de datos requeridos | Miles | Millones |
| Recursos computacionales | Menos recursos necesarios | Recursos masivos necesarios |
| GPU | No requerida | Requerida |
Una vez que las imágenes se procesan a través de diferentes capas de las redes neuronales profundas, el sistema tendrá acceso a identificadores específicos, que ayudarán a clasificar los animales y sus imágenes. La diferente salida procesada por cada capa de la red neuronal se combina para categorizar las imágenes de manera efectiva.
La presencia de redes neuronales también significa que los algoritmos de aprendizaje profundo requieren grandes conjuntos de datos. Eso se debe a que los algoritmos de DL solo pueden aprender cuando se exponen a un millón o más de puntos de datos. Por otro lado, los algoritmos de ML pueden aprender y mejorar con pautas predefinidas.
Otra diferencia notable entre el aprendizaje automático y el aprendizaje profundo es el tipo de hardware requerido para ambos. Dado que la complejidad de los cálculos y la cantidad de datos que se procesan es significativamente menor para el aprendizaje automático, los programas de ML pueden ejecutarse en computadoras de gama baja sin requerir mucha potencia computacional.
Por otro lado, los sistemas de aprendizaje profundo requieren recursos computacionales masivos y componentes de hardware potentes como las unidades de procesamiento gráfico (GPUs). El científico informático Andrew Ng determinó que las GPUs podrían aumentar la velocidad de los sistemas de aprendizaje profundo en más de 100 veces.
Con la ayuda de las GPUs, el tiempo necesario para entrenar modelos de aprendizaje profundo puede reducirse de días a solo horas. La mayoría de los marcos de aprendizaje profundo como PyTorch y TensorFlow ya están acelerados por GPU.
Empresas como Nvidia se han vuelto más serias acerca del aprendizaje profundo acelerado por GPU y están ajustando sus productos en consecuencia. Además, las GPUs son útiles para cálculos de matrices o vectores.
El tiempo necesario para entrenar algoritmos de aprendizaje profundo y aprendizaje automático también es significativamente diferente. Como habrás adivinado, los algoritmos de aprendizaje profundo tardan mucho tiempo en entrenarse debido a la gran cantidad de datos y cálculos complejos involucrados. Puede llevar unas pocas horas o incluso semanas entrenar un sistema DL, mientras que un sistema ML puede entrenarse en unos pocos segundos o horas.
Nuevamente, elegir entre el aprendizaje profundo y el aprendizaje automático debe ser una decisión altamente informada. La decisión debe tomarse teniendo en cuenta el volumen y la naturaleza de los datos, la complejidad del problema que estás tratando de resolver y los recursos computacionales disponibles.
Aplicaciones del aprendizaje profundo
Aunque el aprendizaje profundo se considera un campo incipiente, los investigadores y las organizaciones ya están beneficiándose de sus aplicaciones. Aquí hay algunos ejemplos de aprendizaje profundo que están dando forma al mundo que nos rodea, y lo más probable es que te hayas encontrado con algunos de ellos en tu vida diaria.
Coches autónomos
Los vehículos autónomos son los beneficiarios más famosos del aprendizaje profundo. Se alimentan millones de conjuntos de datos que replican numerosos escenarios de la vida real en el sistema, que se utiliza para enseñar al vehículo cómo navegar por la carretera de manera segura.
Con la ayuda de modelos de aprendizaje profundo, los fabricantes pueden garantizar que los coches sin conductor puedan manejar escenarios imprevistos sin causar daño a los pasajeros o peatones.
Junto con ayudar a las máquinas a resolver escenarios hipotéticos, el aprendizaje profundo también les ayuda a analizar y procesar los datos en bruto recopilados de cámaras, GPS y numerosos sensores. Al hacerlo, los vehículos autónomos pueden identificar y distinguir entre carriles y divisores de carretera, barricadas, señales, peatones, coches que disminuyen la velocidad o se detienen, y más.
Procesamiento del lenguaje natural
El procesamiento del lenguaje natural (NLP) es un campo de la inteligencia artificial que otorga a las máquinas la capacidad de entender, interpretar y derivar significado de los lenguajes humanos. En pocas palabras, el NLP hace posible que las máquinas conversen con los humanos e incluso entiendan las sutilezas contextuales de un idioma.
Asistentes inteligentes como Siri y Google Assistant y aplicaciones de traducción de idiomas como Google Translate son ejemplos del mundo real de NLP. El NLP puede desglosarse aún más en generación de lenguaje natural (NLG) y comprensión del lenguaje natural (NLU).
Consejo: Consulta algunos de los mejores software de procesamiento del lenguaje natural en la industria.
A primera vista, el reconocimiento de voz puede parecer solo una cuestión de convertir sonido en palabras respectivas. Es bastante simple para los humanos, ya que la corteza auditiva de nuestro cerebro ha sido entrenada durante años para reconocer y entender un idioma hablado o más.
Un ejemplo simple para representar la complejidad de entender sonidos es "reconocer el habla" y "destrozar una playa agradable". Ambos suenan muy similares, aunque sus significados son completamente diferentes. Aunque las máquinas pueden detectar palabras en una oración, entender su significado contextual sigue siendo una tarea hercúlea. Ahí es donde entra DL para el NLP.
Casi todos los asistentes inteligentes dependen del aprendizaje profundo, y sus niveles de comprensión y precisión están aumentando con cada tarea. Google Assistant, que depende casi por completo de DL, tiene la mayor precisión.
El aprendizaje profundo también permite a las máquinas entender las complejidades de un idioma, como las tonalidades, las expresiones e incluso el sarcasmo. Entender las complejidades de un idioma también es crítico para el análisis de sentimientos en datos textuales. Solo entonces las empresas pueden monitorear la reputación de la marca y el producto, entender la opinión pública y analizar las experiencias de los clientes.
Otra aplicación del aprendizaje profundo es la resumen de documentos. La resumen de documentos o simplemente la resumen de texto es la tarea de extraer información crucial de un gran pasaje de texto y crear un resumen conciso de este. Además de ahorrar tiempo a los humanos, la resumen de documentos también puede ayudar a los programas de computadora que necesitan procesar grandes cantidades de datos en un corto período de tiempo.
El reconocimiento de hablantes es otra aplicación útil del aprendizaje profundo y se está volviendo cada vez más precisa. Los gobiernos pueden usar esta tecnología para identificar a terroristas que hacen llamadas telefónicas anónimas al comparar sus muestras de voz con una base de datos que contiene voces reconocidas.
Reconocimiento de imágenes
Antes del aprendizaje profundo, el campo del reconocimiento de imágenes dependía en gran medida de la sintonización manual. Esto significa que muchos procesos tenían que ser realizados por humanos y tomaban mucho tiempo. El aprendizaje profundo elimina la necesidad de procesamiento de imágenes manual o tradicional y acelera significativamente todo el proceso.
En esta década, la mayoría de los sistemas precisos de detección de objetos que encuentras dependen únicamente del aprendizaje profundo. Google Photos es un excelente ejemplo. Utiliza el aprendizaje profundo para clasificar y agrupar imágenes.
Incluso si no has hecho ningún etiquetado manual, puedes buscar en tu álbum de Google Photos algo como "insectos en flores" y obtener resultados, siempre que tengas imágenes relacionadas almacenadas. Incluso puedes buscar animales según sus especies o razas y aún así obtener todas las fotos que contengan el animal en particular.
Mientras que los sistemas tradicionales que no son de aprendizaje profundo tienen dificultades para identificar los objetos de una imagen, el aprendizaje profundo va varios pasos más allá. Hace un trabajo impresionante al reconocer rostros humanos, animales, lugares y cosas con alta precisión y casi sin errores.
Manufactura
Con la introducción del Internet de las Cosas (IoT), las fábricas se están volviendo más inteligentes que nunca. La automatización no es nueva en la industria manufacturera, y el aprendizaje profundo hace que las cosas sean más eficientes.
Con la ayuda de arquitecturas de aprendizaje profundo como CNN, las empresas pueden reemplazar a la mayoría de los operadores humanos que de otro modo eran fundamentales para detectar productos defectuosos en la línea de ensamblaje.
De esta manera, detectar problemas de calidad se vuelve más preciso y rentable, y se eliminan las posibilidades de error humano. Estos sistemas también son altamente escalables y pueden entrenarse para detectar problemas de calidad en cualquier punto de la línea de producción.
Otra aplicación del aprendizaje profundo en la manufactura es el mantenimiento predictivo. Al recopilar y analizar los datos de salud de la maquinaria durante un período de tiempo, los algoritmos de aprendizaje profundo pueden predecir las posibilidades de que un activo de manufactura se descomponga.
Determinar cuándo reparar un equipo es crítico desde el punto de vista financiero de una empresa, ya que una máquina defectuosa podría detener toda la producción. Dado que el mantenimiento irregular también puede causar daños costosos e irreparables a las máquinas y accidentes catastróficos en la fábrica en el peor de los casos, las empresas pueden ahorrar mucho con el mantenimiento predictivo. Saber cuándo reparar también ayudará a las empresas a planificar con anticipación y buscar alternativas para reducir el tiempo de inactividad de la fábrica.
La optimización de insumos de fábrica es otra aplicación beneficiosa del aprendizaje profundo. Con los consumidores cada vez más preocupados por la huella de carbono de los productos y las reformas ecológicas realizadas por sus creadores, las empresas no tienen más remedio que optimizar el uso de recursos físicos.
Además, optimizar los recursos ayudará a las empresas a obtener más ganancias de cada producto, de ahí la optimización de insumos de fábrica. Al rastrear el uso de recursos (principalmente el consumo de electricidad y agua) de diferentes maquinarias y procesos de producción, los sistemas de aprendizaje profundo pueden sugerir dinámicamente las mejores prácticas de optimización.
Descubrimiento de fármacos
El descubrimiento de fármacos es increíblemente lento y costoso. El aprendizaje profundo puede hacer que este proceso sea más barato y rápido. El aprendizaje profundo puede ayudar a predecir la afinidad de unión de los fármacos con proteínas particulares e incluso los efectos tóxicos de compuestos específicos.
AtomNet es una red neuronal convolucional profunda utilizada para el diseño racional de fármacos. Es una tecnología de vanguardia capaz de encontrar compuestos de fármacos novedosos y no obvios y puede ser una herramienta notable para proyectos acelerados de reposicionamiento de fármacos. AtomNet también se utilizó para predecir nuevos biomoléculas candidatas para el Ébola y la esclerosis múltiple (EM).
Hospitalidad
La hospitalidad es una industria multimillonaria siempre ansiosa por adoptar nuevas tecnologías, y la tecnología de aprendizaje profundo no es una excepción. Con DL, las organizaciones pueden encontrar nuevos medios para mejorar la experiencia y satisfacción del cliente e incluso identificar procesos costosos y reemplazables.
El aprendizaje profundo puede ayudar a las organizaciones a planificar con anticipación al predecir demandas estacionales. Un sistema de aprendizaje profundo puede encontrar fácilmente la correlación entre los factores que causan demandas estacionales y predecir tendencias futuras al analizar datos pasados.
Al analizar los datos de los clientes, los modelos de DL también pueden ayudar a las empresas a construir estrategias de clientes para mejores tasas de retención y satisfacción. Las empresas también pueden usar varias técnicas de aprendizaje automático para precios competitivos al considerar múltiples factores como la estacionalidad, eventos en tiempo real, promociones de terceros, eventos locales y datos de reservas pasadas.
Finanzas
Dado que el procesamiento de datos complejos es una especialidad del aprendizaje profundo, tiene un inmenso potencial en la industria financiera. Al analizar datos históricos, varios parámetros del mercado y factores externos que pueden afectar el rendimiento de una empresa, los algoritmos de aprendizaje profundo pueden predecir valores de acciones con una precisión impresionante.
Dado que los algoritmos de DL pueden analizar grandes volúmenes de datos de múltiples fuentes simultáneamente, es increíblemente más rápido que los humanos y, por lo tanto, se utiliza para crear estrategias comerciales rentables.
Las redes neuronales profundas también se utilizan en el proceso de aprobación de préstamos. Al analizar datos históricos sobre aprobaciones y rechazos, los bancos pueden evaluar correctamente los riesgos de aprobar un préstamo a una entidad.
Restauración de imágenes
La restauración de imágenes es otra hazaña impresionante que el aprendizaje profundo puede lograr. La restauración de imágenes generalmente se refiere a la recuperación de una imagen clara no degradada a partir de una imagen degradada. La degradación puede ocurrir debido a varios factores, siendo el ruido de imagen uno de ellos.
Si el ruido de imagen es el culpable, entonces el proceso de restauración se llama eliminación de ruido de imagen. Del mismo modo, las imágenes pueden tener una resolución más baja, y mediante el proceso de superresolución, se pueden crear imágenes de mayor resolución.
Con el aprendizaje profundo, tales procesos de restauración se vuelven más precisos y menos lentos. Los métodos de aprendizaje como Deep Image Prior se utilizan para el proceso de restauración. En términos simples, Deep Image Prior es una red neuronal convolucional utilizada para mejorar una imagen sin ningún dato de entrenamiento previo que no sea la propia imagen.
En 2017, los investigadores del equipo de Google Brain entrenaron una red neuronal profunda para analizar imágenes de rostros de muy baja resolución y predecir los rostros. Este método se llama Superresolución Recursiva de Píxeles y puede mejorar significativamente la resolución de las imágenes. La red neuronal puede identificar con facilidad las características distintivas de una persona.
El aprendizaje profundo también se utiliza extensamente para colorear fotos en blanco y negro. Puedes consultar herramientas en línea como Algorithmia para ver cómo se verían ciertas imágenes en blanco y negro si se tomaran con una cámara en color.
Publicidad móvil
El aprendizaje profundo permite a los anunciantes móviles publicar anuncios que pueden captar la atención de su audiencia objetivo y ofrecer un mayor retorno de la inversión (ROI). Las técnicas de aprendizaje profundo, como la publicidad predictiva basada en datos, también se utilizan para aumentar la relevancia de los anuncios.
Numerosas redes de anuncios móviles en tiempo real utilizan APIs de aprendizaje profundo, que ayudan a los anunciantes a maximizar la tasa de clics (CTR). Los tiempos de respuesta más rápidos de los sistemas de aprendizaje profundo también permiten a los anunciantes servir los anuncios correctos en el momento y espacio adecuados.
Detección de retrasos en el desarrollo
El diagnóstico y tratamiento temprano de trastornos del desarrollo, autismo o trastornos del habla puede tener un impacto positivo en el futuro de un niño. Un humano no notaría numerosos signos en etapas tempranas, pero un sistema de aprendizaje profundo sí puede.
Usando el aprendizaje profundo, los investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT y el Instituto de Profesiones de la Salud del Hospital General de Massachusetts han creado un sistema informático que puede identificar trastornos del habla incluso antes de que un niño entre al jardín de infancia.
Además, los niños que están en el espectro del autismo tienen dificultades para reconocer los estados emocionales de las personas que los rodean. Por ejemplo, los niños con autismo tendrán dificultades para diferenciar entre una cara feliz y una temerosa.
Como remedio a este problema, algunos médicos utilizan robots amigables para niños impulsados por aprendizaje profundo para involucrar a los niños en la imitación de emociones y responder a ellas de manera adecuada. A medida que el robot interactúa, analiza el interés y el compromiso del niño observando sus respuestas.
El aprendizaje profundo permite al robot extraer la información más crucial de los datos recopilados sin necesidad de asistencia humana. Con la ayuda de DL, los investigadores descubrieron numerosos hechos fascinantes, como las diferencias culturales entre niños de diferentes países.
Observaron que durante episodios de alto compromiso, los niños de Japón mostraban más movimientos corporales. Por otro lado, los grandes movimientos corporales se asociaron con episodios de desinterés para los niños de Serbia.
Una de las mayores razones por las que este tipo de tratamiento es efectivo es que el robot está preparado para atraer la atención de los niños. Además, los humanos tienden a cambiar sus expresiones con frecuencia y expresar la misma emoción de diferentes maneras. Pero el robot siempre lo hace de la misma manera para que el proceso de aprendizaje sea mucho menos frustrante para el niño.
Predicción de sonido
La producción de sonido es una parte integral de la realización de películas. Aunque ciertos sonidos como pasos, golpes en la puerta o chirridos de neumáticos pueden tomarse de audios de archivo, muchas veces tienen que recrearse para mejorar la experiencia cinematográfica.
Investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del MIT han creado un algoritmo de aprendizaje profundo que predice el sonido. Cuando se le da un clip de video silencioso de un objeto siendo golpeado, el algoritmo puede producir sonidos realistas. El sonido predicho es lo suficientemente realista como para engañar a los humanos.
Para entrenar el algoritmo, los investigadores filmaron aproximadamente 1,000 videos de casi 46,000 sonidos que constituyen diferentes objetos siendo golpeados, empujados y raspados con un baqueta. Usaron específicamente una baqueta porque ofrecía un método consistente para producir un sonido.
Los sistemas de predicción de sonido no solo mejorarán las cosas para la industria cinematográfica, sino que podrían ayudar a las máquinas inteligentes a navegar por el mundo y entender las propiedades de los objetos.
Traducción visual
¿Alguna vez has intentado traducir idiomas extranjeros con la aplicación Google Translate? No solo la aplicación "traduce" las palabras, sino que superpone la imagen con la traducción. La aplicación hace esto con la ayuda de redes neuronales profundas y es una de las muchas formas en que Google exprime el aprendizaje profundo en un smartphone.
Una vez que la aplicación encuentra dónde están ubicadas las letras en la imagen al analizar sus píxeles, una red neuronal convolucional entrenada en letras y no letras intenta reconocer qué es cada letra. Una vez que se identifican las letras, la aplicación busca en un diccionario para obtener traducciones.
La traducción se renderiza luego sobre las letras originales en el mismo estilo que la imagen original. Tales traducciones visuales son súper rápidas si se realizan en los centros de datos de Google. Pero dado que la mayoría de los usuarios poseen un smartphone de gama baja y tienen conexiones a internet inestables, Google desarrolló una pequeña red neuronal con numerosas limitaciones.
Sistemas de recomendación
Los algoritmos de aprendizaje profundo se utilizan en sistemas de recomendación para sugerir contenido que los usuarios tienen más probabilidades de ver. La efectividad de estos algoritmos es crítica para plataformas como Netflix, ya que solo si los usuarios encuentran contenido interesante con frecuencia, continuarán la suscripción. Amazon y numerosas otras plataformas de comercio electrónico también dependen en gran medida de los algoritmos de aprendizaje profundo para recomendar los productos correctos y aumentar las ventas.
Detección de fraude
Las pérdidas y daños relacionados con el fraude son una triste realidad de la industria financiera. Los estafadores financieros están creciendo.
$1.9 mil millones
se perdieron debido al robo de identidad y fraude en 2019.
Sin embargo, puede haber numerosos comportamientos de usuario que los sistemas basados en reglas no identificarían como sospechosos, pero los sistemas de detección de fraude basados en DL seguramente lo harían. La potencia de procesamiento de los sistemas basados en DL también es notable, y también reducen la necesidad de trabajo manual, a diferencia de los sistemas basados en reglas que requieren supervisión humana frecuente y correcciones manuales.
Cómo crear y entrenar modelos de aprendizaje profundo
Hay tres formas comunes en las que puedes entrenar un modelo de aprendizaje profundo para realizar la clasificación de objetos. Podrías entrenarlo desde cero, usar el aprendizaje por transferencia o usar una red como extractor de características. Echemos un vistazo rápido a cada uno.
1. Entrenamiento desde cero
Para entrenar redes neuronales profundas desde cero, necesitas adquirir grandes volúmenes de conjuntos de datos etiquetados, por ejemplo, las imágenes etiquetadas de gatos y perros. Después de eso, necesitas diseñar una arquitectura de red que pueda aprender las características distintivas de los animales. Dependiendo del volumen de datos, la tasa de aprendizaje y la potencia de procesamiento, las redes pueden tardar días o semanas en entrenarse.
2. Enfoque de aprendizaje por transferencia
La forma más común de entrenar redes neuronales profundas es mediante el enfoque de aprendizaje por transferencia. En este proceso, un modelo preentrenado se ajusta para realizar una nueva tarea. Puedes comenzar con una red existente y alimentarle nuevos conjuntos de datos que contengan clases previamente desconocidas.
Puedes ajustar la red según tus requisitos, en este caso, identificar y distinguir entre las imágenes de gatos y perros. Dado que este proceso requiere menos cantidad de datos, el tiempo de cómputo se reduce significativamente.
3. Usar extractor de características
Otro enfoque para entrenar un modelo de aprendizaje profundo es usar una red como extractor de características. Dado que cada capa de la red está designada para aprender características específicas de las imágenes, puedes realmente extraer estas características de la red durante el proceso de entrenamiento. Estas características pueden luego ser ingresadas en un modelo de aprendizaje automático. Hacer esto puede reducir la necesidad de enormes recursos computacionales.
Aprendizaje profundo: cuanto más, mejor
Una propiedad interesante del aprendizaje profundo es que mejora si proporcionas más datos y más recursos computacionales. Aunque los algoritmos de aprendizaje profundo pueden parecer demasiado exigentes, son altamente precisos y requieren poca o ninguna asistencia humana en la mayoría de los casos.
El aprendizaje profundo también será nuestra clave para desbloquear la inteligencia artificial general, un sistema de IA capaz de pensar, aprender y actuar como los humanos.
Aprende más sobre la inteligencia artificial general y descubre por ti mismo si una máquina tan inteligente sería un amigo o un enemigo.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

