



En el espacio tecnológico de rápido crecimiento de hoy en día, las empresas tienen más datos que nunca.
Tener grandes cantidades de datos no significa nada; lo que haces con esos datos es lo que importa. Ahí es donde entra en juego la minería de datos. Da sentido a los datos mientras las empresas trabajan para implementar varios objetivos y estrategias de mejora potencial a través del proceso de convertir datos en bruto en información procesable. Hay muchas maneras de abordar esto, y todo se reduce a las técnicas de minería de datos que tu empresa elija utilizar.
La minería de datos es el proceso de encontrar y detectar patrones en los datos para obtener información relevante; las diversas técnicas son cómo se convierte los datos en bruto en observaciones precisas.
Técnicas comunes de minería de datos
A menudo se requiere una variedad de técnicas de minería de datos para descubrir información que se encuentra dentro de grandes conjuntos de datos, por lo que tendría sentido elegir más de una. Mientras que la minería de datos puede segmentar clientes, también puede ayudar a determinar la lealtad del cliente, identificar riesgos, construir modelos predictivos y mucho más.
La mayoría, pero no todas, las técnicas de minería de datos caen bajo la categoría de análisis estadístico o aprendizaje automático, dependiendo de cómo se utilicen. A continuación, profundizamos más en cada técnica.
Limpieza de datos
Una técnica necesaria cuando se trata de minería de datos es la limpieza de datos. Los datos en bruto deben ser limpiados, formateados y analizados para que sean útiles y aplicables a diferentes tipos de métodos analíticos. Esta técnica es parte de diferentes elementos de modelado de datos, transformación, agregación y migración.
¿Cómo se utiliza la limpieza de datos hoy en día?
Las empresas utilizan la limpieza de datos como un primer paso en el proceso de minería de datos porque de lo contrario, los datos encontrados son inútiles y poco fiables. Debe haber confianza en los datos y en los resultados que provienen del análisis de datos para que haya un siguiente paso valioso y procesable. La limpieza de datos es a menudo el primer paso que se lleva a cabo en el proceso de minería de datos.
Agrupamiento
Una técnica de minería de datos se llama análisis de agrupamiento, también conocido como taxonomía numérica. Esta técnica esencialmente agrupa grandes cantidades de datos en función de sus similitudes. Este modelo muestra cómo podría verse un análisis de agrupamiento.
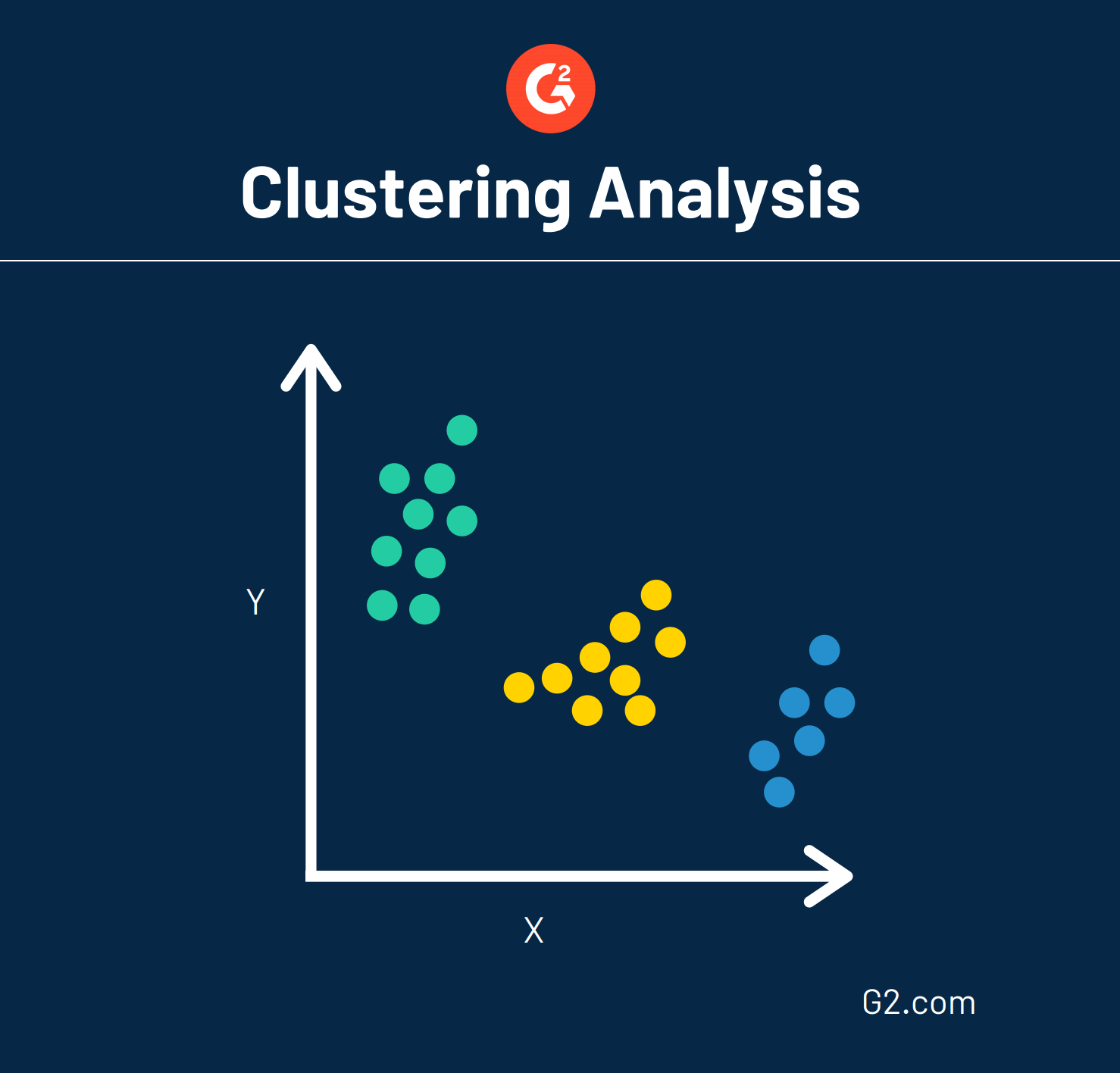
Los datos que están dispuestos de manera esporádica en un gráfico pueden agruparse de manera estratégica a través del análisis de agrupamiento. Este análisis también puede actuar como un paso de preprocesamiento, lo que significa que los datos se formatean de una manera que otras técnicas pueden aplicarse fácilmente.
Cuando se trata de enfoques de agrupamiento, hay cinco métodos principales utilizados por los científicos de datos:
- Algoritmos de particionamiento: creando varias particiones y luego evaluándolas en función de criterios específicos
- Algoritmos jerárquicos: creando una disposición jerárquica del conjunto de datos utilizando criterios específicos
- Basado en densidad: basado en funciones de conectividad y densidad
- Basado en cuadrícula: basado en estructuras de granularidad de múltiples niveles
- Basado en modelos: primero se hipotetiza un modelo para cada uno de los grupos, luego se encuentra el mejor ajuste del modelo
De la mano con estos enfoques de agrupamiento están cinco algoritmos de agrupamiento utilizados para clasificar cada punto de datos en un grupo específico. Los puntos de datos dentro del mismo grupo tienen propiedades o características similares.
Estos algoritmos son:
- Agrupamiento K-Means: agrupa observaciones en grupos donde cada punto de datos es parte del grupo con la media más cercana
- Agrupamiento de cambio de media: asigna los puntos de datos a los grupos de manera iterativa desplazando los puntos hacia el modo. Más comúnmente utilizado en procesamiento de imágenes y visión por computadora
- Agrupamiento basado en densidad espacial de aplicaciones con ruido (DBSCAN): agrupa puntos de datos en un espacio específico que están cerca entre sí mientras marca puntos atípicos específicos en regiones de baja densidad dentro del grupo. Frecuentemente citado en literatura científica
- Agrupamiento de máxima expectativa (EM) con modelos de mezcla gaussiana (GMM): utilizado para agrupar datos no etiquetados ya que tiene en cuenta la varianza (ancho de una curva de campana) para determinar la forma de la distribución o grupo
- Agrupamiento jerárquico aglomerativo: trabaja para construir un análisis jerárquico de los grupos con un enfoque "de abajo hacia arriba". Cada observación comenzará en su propio grupo, y los pares de grupos se fusionan a medida que uno avanza en la jerarquía
¿Para qué se utiliza el agrupamiento?
Hay algunas maneras de extraer conocimiento del análisis de agrupamiento. Las compañías de seguros pueden identificar grupos de asegurados con reclamaciones promedio altas. El agrupamiento puede utilizarse en marketing para segmentar clientes en función de los beneficios que experimentarán al comprar un producto específico.
Otro ejemplo de agrupamiento es cómo los sismólogos pueden ver el origen de la actividad sísmica y la fuerza de cada terremoto, y luego aplicar esa información para diseñar rutas de evacuación.
Clasificación
La clasificación a menudo se refiere como un subconjunto del agrupamiento. La clasificación consiste en analizar varios atributos que están asociados con diferentes tipos de datos. Cuando una empresa puede identificar las características principales de estos tipos de datos, puede organizar y clasificar mejor todos los datos relacionados.
Esto es una parte vital para identificar tipos específicos de datos, como si una empresa quiere proteger más documentos con información sensible, como números de seguridad social o de tarjetas de crédito.
Detección de valores atípicos
También conocida como detección de anomalías, esta técnica de minería de datos hace quizás lo opuesto al agrupamiento. En lugar de buscar grandes grupos de datos que podrían agruparse, la detección de valores atípicos busca puntos de datos que son raros y están fuera de un grupo o promedio establecido.
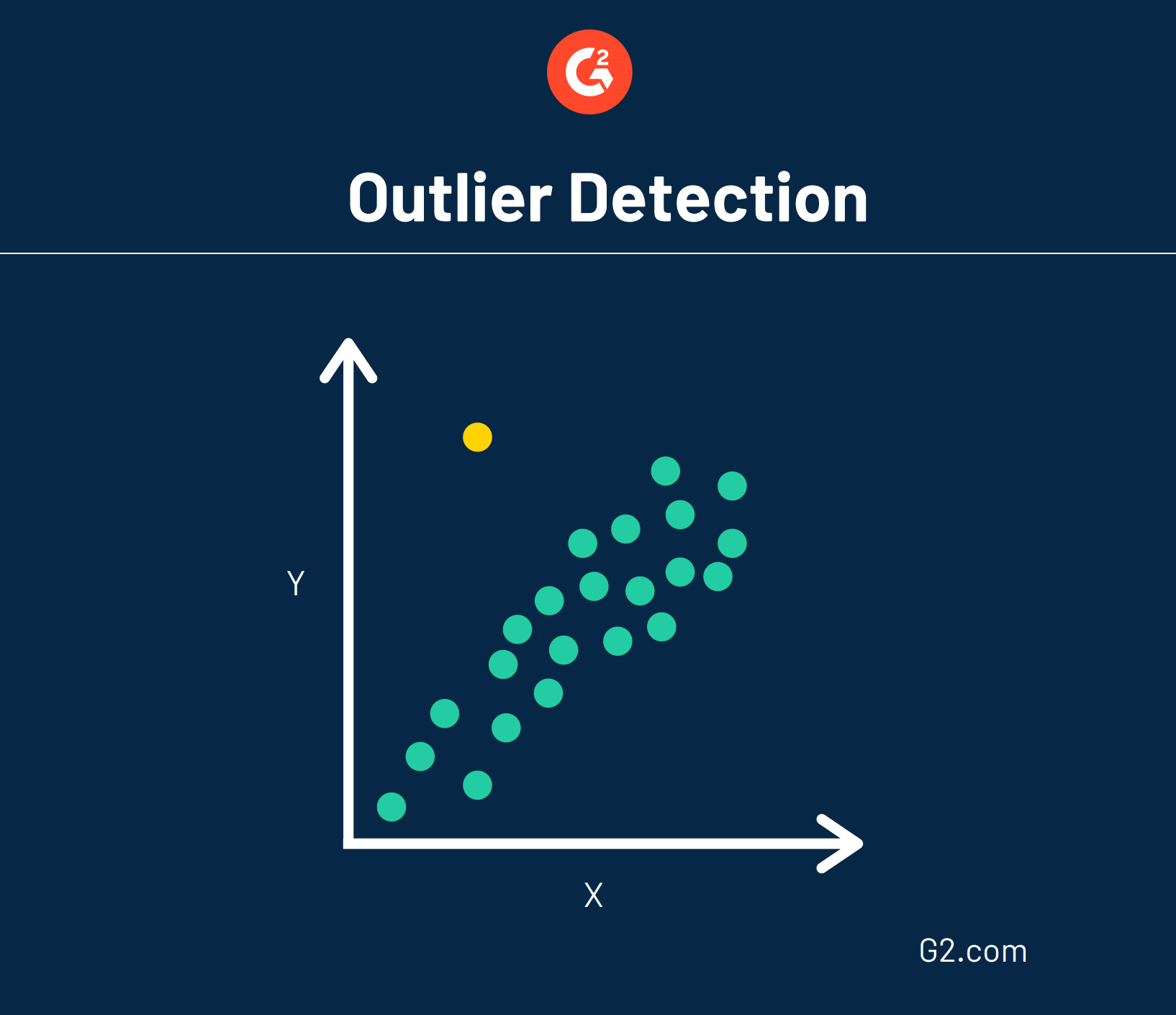
Debido a que los datos son bastante aleatorios, las anomalías no necesariamente apuntan hacia una tendencia. En cambio, los datos que van en contra de la corriente podrían indicar que algo anormal está ocurriendo y requiere un análisis más profundo.
Una vez que una empresa u organización encuentra estas rarezas dentro de los datos, se vuelve más fácil entender por qué ocurren estas anomalías y prepararse para cualquier otra que pueda surgir en el futuro.
Hay dos tipos de valores atípicos:
- Univariado: un punto de datos que consiste en un valor extremo en una variable
- Multivariado: una combinación de puntuaciones inusuales en al menos dos variables
De estos dos tipos, hay cuatro técnicas de valores atípicos:
- Valor atípico numérico: detección de valores atípicos en un espacio unidimensional
- Puntuación Z: detección de valores atípicos paramétricos en un espacio unidimensional o de baja dimensión
- DBSCAN: detección de valores atípicos basada en densidad en un espacio unidimensional o multidimensional
- Bosque de aislamiento: método no paramétrico para grandes conjuntos de datos en un espacio unidimensional o multidimensional
¿Para qué se utiliza la detección de valores atípicos?
La detección de valores atípicos se utiliza más comúnmente para detectar comportamientos fraudulentos. Por ejemplo, la detección de valores atípicos puede identificar actividad sospechosa en tarjetas de crédito y desencadenar una respuesta (como el congelamiento de una cuenta).
En una era donde los ciberataques son más robustos y comunes que nunca, la detección de valores atípicos ayuda a identificar brechas de datos en sitios web para que puedan resolverse rápidamente. Esto se llama detección de intrusiones.
Minería de reglas de asociación
Buscar grupos y valores atípicos son algunas maneras de extraer conocimiento, pero otra técnica llamada minería de reglas de asociación observa cómo una variable se relaciona con otra al descubrir un patrón oculto en el conjunto de datos.
Los científicos de datos buscan eventos o atributos específicos que estén altamente correlacionados con otro evento o atributo. La información de la minería de reglas de asociación también puede ayudar a las empresas a identificar correlaciones potenciales. Por ejemplo, si ocurre el evento A, entonces es probable que el evento B siga. Si el evento A es una tormenta de nieve, podemos asumir que el evento B, las cancelaciones de vuelos, es probable que ocurra a continuación. Si alguna vez te han sugerido productos en un sitio de comercio electrónico basado en lo que tienes en tu carrito, entonces has visto la minería de reglas de asociación en acción.
Por ejemplo, esto es lo que Amazon recomienda que compre basado en artículos que he comprado en el pasado.

¿Para qué se utiliza la minería de reglas de asociación?
Walmart aplicó esta técnica de minería de datos de manera impecable en 2004 durante el huracán Frances. Al minar datos de transacciones e inventario, los analistas descubrieron que las ventas de Pop-Tarts de fresa eran siete veces más altas justo antes de que el huracán golpeara. También se reveló que la cerveza era el artículo más vendido antes del huracán. Con esta información en mano, Walmart se aseguró de abastecerse. Al igual que Walmart, las pequeñas y medianas empresas pueden utilizar estos datos de la misma manera.
Regresión
Si una empresa busca hacer una predicción basada en el efecto que una variable tiene sobre otras, puede referirse a una técnica de minería de datos llamada análisis de regresión. Este método de datos identifica y analiza la relación entre variables.
Recuerda: La regresión y la asociación a menudo se confunden entre sí. La regresión en el análisis estadístico es la ecuación utilizada para especificar y asociar datos para dos o más variables. La asociación es la relación entre dos cantidades medidas que las hará dependientes o correlacionadas.
¿Para qué se utiliza la regresión?
En la superficie, los datos son caóticos. Hay mucho ensayo y error involucrado al examinar la relación entre un conjunto de datos y otro, especialmente cuando una empresa está tratando de averiguar probabilidades de eventos y hacer predicciones. El análisis de regresión puede guiar estas predicciones en la dirección correcta.
Un ejemplo de análisis de regresión en la industria de la salud es examinar los efectos que el índice de masa corporal, o IMC, tiene sobre otras variables. También usarías la regresión para determinar cómo el precio de un producto impactará el número de ventas que tiene tu empresa o cómo la cantidad de lluvia impactará el crecimiento de los cultivos.
Regresión lineal
Un tipo común de regresión se llama regresión lineal.
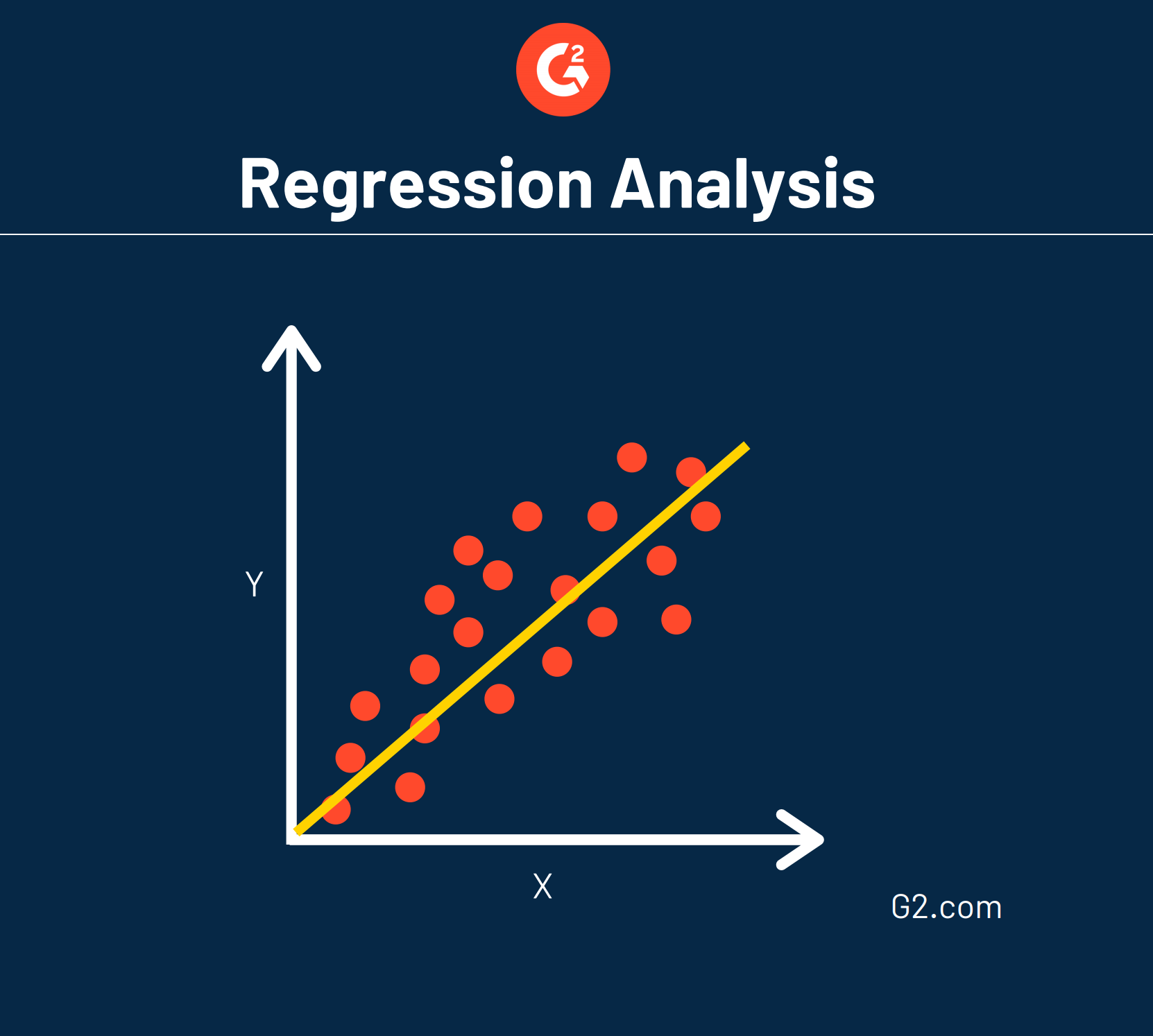
Esto significa que se puede trazar una línea recta para mostrar cómo cada variable se relaciona entre sí.
Relacionado: Aprende más sobre la regresión, la diferencia entre correlación vs regresión, y cuándo deberías usar estas dos medidas estadísticas.
Árbol de decisión
Una de las técnicas de minería de datos más visuales se llama análisis de árbol de decisión, y es un método popular para la toma de decisiones importantes.
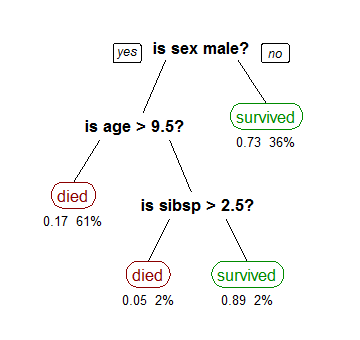
Fuente: Research Gate
Hay dos tipos de análisis de árbol de decisión. Uno de ellos se llama clasificación, que es lo que ves en el ejemplo anterior determinando si un pasajero habría sobrevivido en el Titanic. La clasificación se basa en la lógica, utilizando una variedad de condiciones de si/entonces o sí/no hasta que todos los datos relevantes estén mapeados.
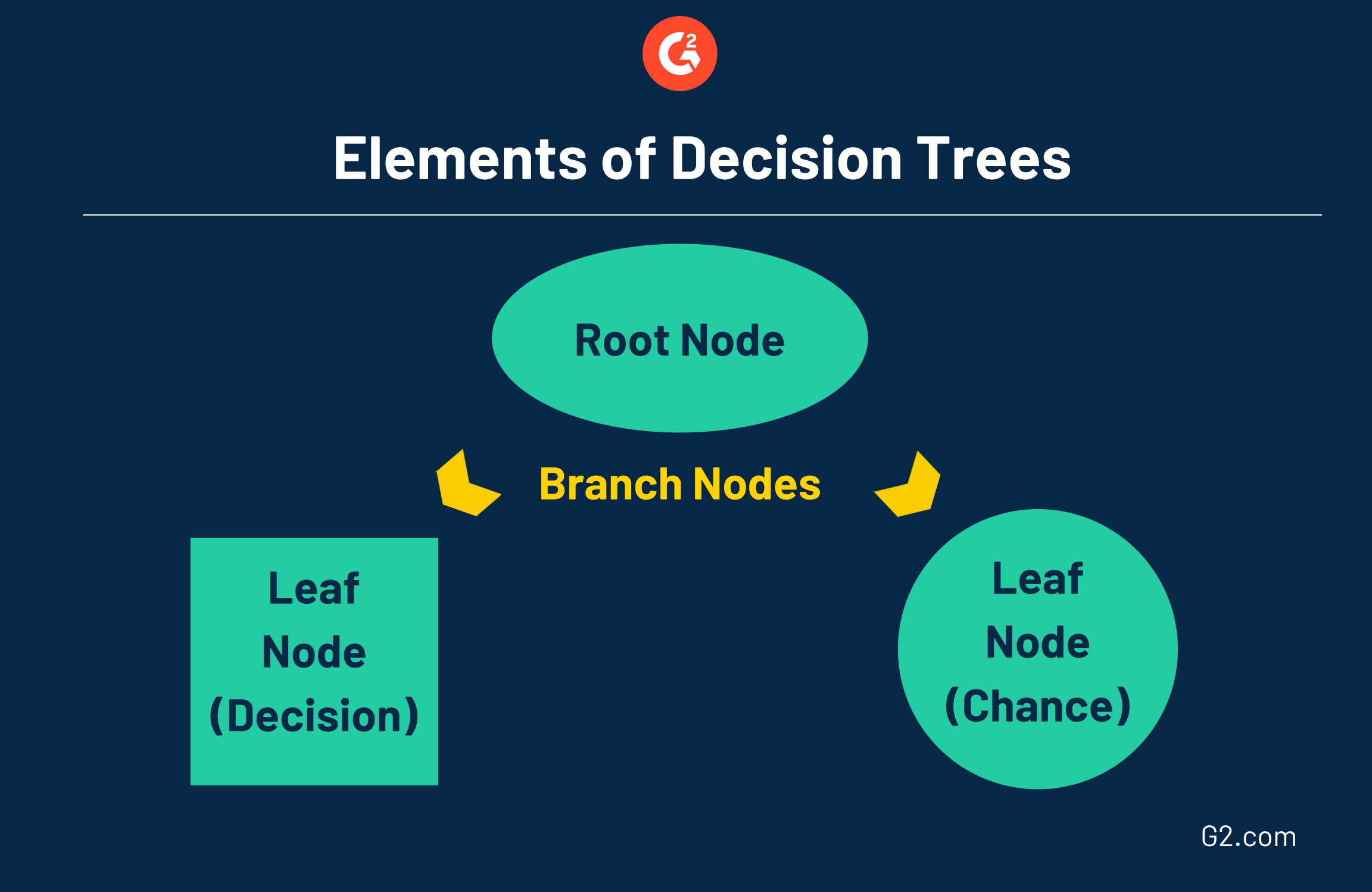
Estos árboles consisten en tres elementos diferentes:
- Nodo raíz: el nodo de nivel superior que representa el objetivo o decisión final que estás tratando de tomar.
- Ramas: que se extienden desde la raíz, las ramas representan diferentes opciones o cursos de acción, que comúnmente se representan con una flecha.
- Nodo hoja: adjunto al final de las ramas, los nodos hoja representan los posibles resultados para cada acción. Un nodo cuadrado indica que se necesita tomar otra decisión, mientras que un nodo hoja circular indica un evento de azar o resultado desconocido.
El otro árbol de decisión se llama regresión, que se utiliza cuando la decisión objetivo es un valor numérico. Por ejemplo, la regresión podría utilizarse al determinar el valor de una casa. Ambos árboles de decisión pueden ejecutarse a través de programas de aprendizaje automático.
¿No estás seguro de qué software de aprendizaje automático utilizar para ejecutar tu árbol de decisión? ¡Echa un vistazo a cientos de reseñas imparciales que G2 te ofrece gratis!
Un árbol de decisión permite a un usuario comprender claramente cómo los datos de entrada afectan los resultados. Cuando se combinan más de un árbol de decisión para un análisis de predicción, esto se convierte en lo que se conoce como un bosque aleatorio. Cuando un modelo de bosque aleatorio se vuelve demasiado complejo, se le llama técnica de aprendizaje automático de caja negra porque es difícil entender sus resultados basados en las entradas.
Predicción
Como su nombre indica, la predicción o análisis predictivo utiliza una combinación de otras técnicas de minería de datos, como el agrupamiento y la clasificación, para analizar eventos pasados o instancias en la secuencia correcta para predecir un evento futuro.
En la mayoría de los casos, reconocer y comprender las tendencias históricas es suficiente para realizar una predicción precisa de lo que podría suceder en el futuro. Hay muchos enfoques para el análisis de predicción, desde el aprendizaje automático hasta la inteligencia artificial. Sin embargo, la predicción precisa no depende de estas dos técnicas; también puede determinarse utilizando varios algoritmos.
¿Para qué se utiliza la predicción?
Muchas organizaciones utilizan la predicción para obtener información sobre qué tendencias ocurrirán a continuación dentro de sus datos. Al igual que la detección de valores atípicos, el análisis predictivo también puede detectar fraudes, vulnerabilidades de día cero y amenazas persistentes. Un ejemplo específico es cómo Staples utilizó la predicción para analizar el comportamiento y proporcionar una imagen completa de sus clientes, lo que resultó en un aumento del 137% en el ROI.
Visualización de datos
La visualización de datos trabaja para proporcionar a los usuarios información adicional sobre su información mediante el uso de gráficos y tablas en tiempo real para comprender mejor los objetivos de rendimiento. Esta técnica es popular debido al hecho de que la visualización de datos puede consumir datos de cualquier fuente a través de cargas de archivos, consultas de bases de datos y conectores de aplicaciones.
¿Cómo se utiliza la visualización de datos hoy en día?
Gracias a los paneles creados utilizando software de visualización de datos, encontrar diversas ideas, tendencias e indicadores clave de rendimiento en los datos es más fácil que nunca. Muchas de estas herramientas proporcionan funcionalidad de arrastrar y soltar y otras capacidades no técnicas, por lo que el usuario promedio de negocios puede construir los paneles necesarios.
Este tipo de software es utilizado por ejecutivos de nivel C y equipos dentro de los sectores de ventas, marketing, servicio al cliente y recursos humanos. Como ejemplo, aquellos en tu equipo de ventas utilizarían este software para rastrear números de ingresos en los acuerdos que han cerrado, mientras que los equipos de marketing utilizan estas herramientas para analizar el tráfico web, campañas de correo electrónico e impresiones en redes sociales.
Relacionado: Aprende más sobre los 67 tipos de visualizaciones de datos que tu empresa puede utilizar para ver el panorama general.
Redes neuronales
El aprendizaje neuronal es un tipo específico de modelo de aprendizaje automático y técnica estadística que a menudo se utiliza junto con la inteligencia artificial y el aprendizaje profundo, y son algunos de los modelos de aprendizaje automático más precisos que utilizamos hoy en día.
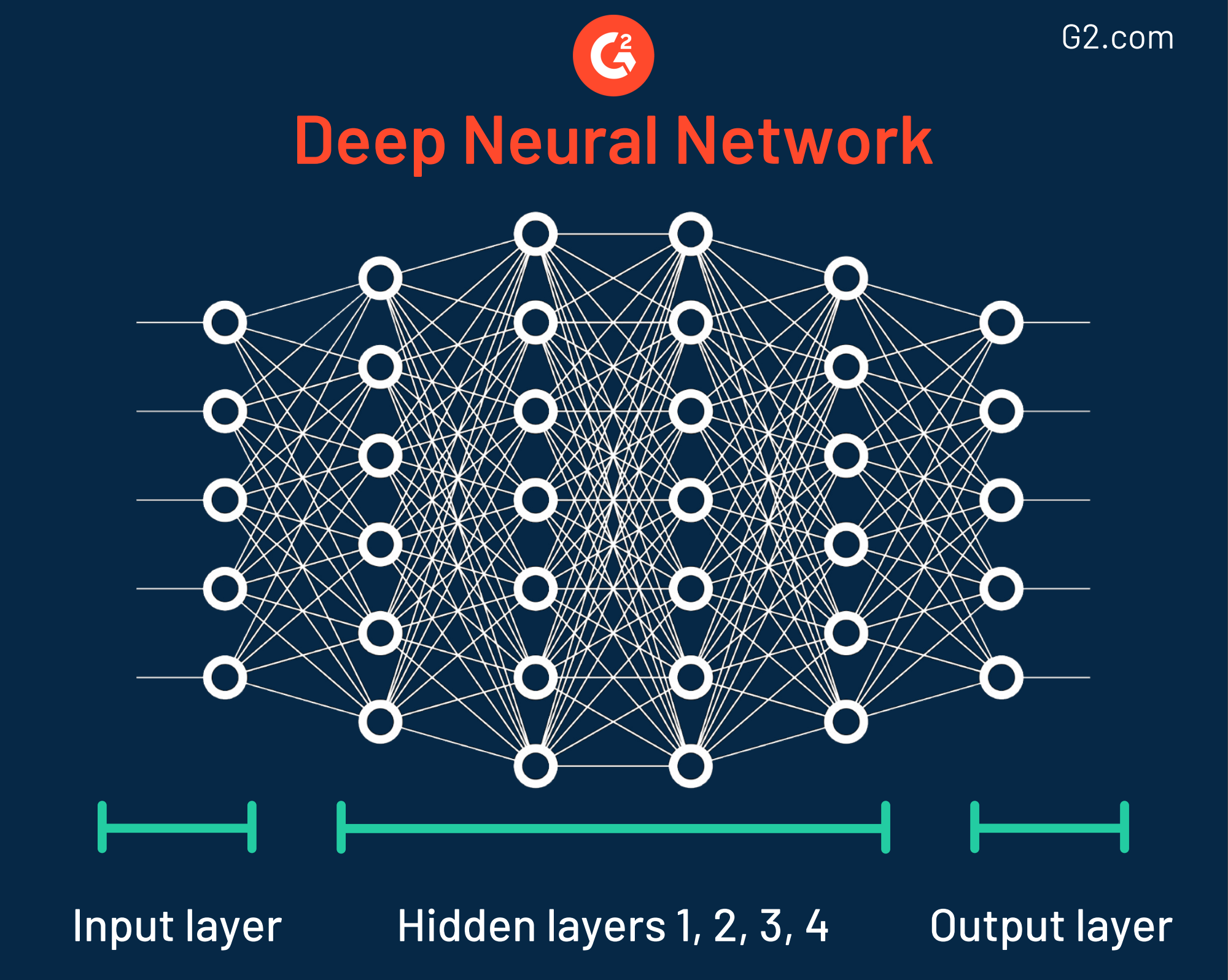
Esta técnica de minería de datos fue nombrada cuando se descubrió en la década de 1940 porque tiene diferentes capas, todas ellas semejantes a la forma en que las neuronas trabajan en el cerebro humano. A pesar de su precisión, las organizaciones que utilizan redes neuronales deben tener cuidado con el hecho de que algunos de estos modelos son extremadamente complejos, lo que hace que sea un desafío entender cómo se determina el resultado.
De hecho, algunas redes neuronales son tan increíblemente intrincadas que tienen hasta 150 capas ocultas. Cada capa juega un papel clave en descomponer características de datos en bruto. Esto se llama formalmente extracción de características.
¿Cómo se utilizan las redes neuronales hoy en día?
Las redes neuronales con solo unas pocas capas se utilizan en bancos y oficinas de correos para reconocer estilos de escritura a mano. Esto es útil al cobrar cheques con tu teléfono móvil.
Redes neuronales más complejas con muchas capas se están utilizando en este momento para desarrollar coches sin conductor. Extraer elementos de la carretera, reconocer pasos de peatones y señales de tráfico, y entender patrones de movimiento de otros vehículos son solo algunos de los muchos tipos de datos en bruto que se descomponen pieza por pieza en redes neuronales complejas.
Análisis de componentes principales
La técnica de minería de datos análisis de componentes principales (PCA) se utiliza para ilustrar conexiones ocultas entre variables de entrada mientras crea nuevas variables que visualizan la misma información capturada utilizando datos originales pero con menos variables. Esencialmente, este método combina información correlacionada para formar un número menor de variables llamadas "componentes principales" que representan la mayor parte de la varianza en los datos.
El objetivo de reducir el número de variables, mientras se transmite la misma cantidad de información, es que los analistas de datos puedan mejorar la precisión de los modelos de minería de datos supervisados. Esencialmente, hace que tus datos sean fáciles de explorar y visualizar.
¿Cómo se utiliza el análisis de componentes principales hoy en día?
El PCA se utiliza más comúnmente por aquellos en el sector financiero por aquellos que realizan y analizan diversas tasas de interés. Aquellos que trabajan con acciones y el mercado de valores también utilizan el PCA para determinar qué acciones comerciar y cuándo.
Seguimiento de patrones
Cuando se trata de técnicas de minería de datos, el seguimiento de patrones es una fundamental. El seguimiento de patrones implica identificar y monitorear tendencias y patrones en los datos para hacer una suposición inteligente y calculada sobre los resultados empresariales.
¿Cuándo se utilizan los patrones de seguimiento hoy en día?
Supongamos que una organización identifica una tendencia en sus datos de ventas y la utiliza como punto de partida para capitalizar una idea específica. Si los datos muestran que un cierto producto se vende mejor que otros para un grupo demográfico particular, pueden decidir usar esos datos para crear productos o servicios similares. De manera similar, podrían optar por abastecer mejor el producto original para ese grupo demográfico.
Almacenamiento de datos
También conocido como almacenamiento de datos empresariales, el almacenamiento de datos implica almacenar datos estructurados en sistemas de gestión de bases de datos relacionales para que puedan ser analizados para el uso de informes e inteligencia empresarial. Las técnicas de minería de datos y almacenamiento de datos de hoy en día utilizan tanto almacenes de datos en la nube para un almacenamiento más seguro de estos conocimientos.
La información almacenada en estos almacenes puede utilizarse para:
- Ajuste de estrategias de producción: comparando ventas de productos ya sea trimestral o anualmente para gestionar carteras y reposicionar productos
- Análisis del cliente: echando un vistazo más profundo a las preferencias de compra del cliente, ciclos de presupuesto, tiempo de compra y más
- Análisis de operaciones: ayudando a analizar las operaciones empresariales, relaciones con los clientes y cómo hacer conexiones ambientales adecuadas
¿Cómo se utiliza el almacenamiento de datos hoy en día?
Las industrias de inversión y seguros utilizan el almacenamiento de datos para analizar patrones de datos, tendencias de clientes y para rastrear movimientos del mercado. Aquellos en el comercio minorista utilizan almacenes de datos para rastrear artículos, patrones de compra de clientes, promociones y para determinar la política de precios.
Descubre lo desconocido
Utilizar la técnica de minería de datos adecuada seguramente proporcionará una visión sin precedentes de tu riqueza de datos. A medida que la tecnología se vuelve más avanzada, la minería de datos solo continuará creciendo y encontrando ideas más profundas.
Arremángate y sumérgete profundamente en lo que tus datos te están mostrando; podrías sorprenderte con lo que encuentres.
Lleva todo este conocimiento un paso más allá y aprende sobre análisis empresarial y cómo puede utilizarse para lograr el éxito.
¿Quieres aprender más sobre Software de aprendizaje automático? Explora los productos de Aprendizaje Automático.

Mara Calvello
Mara Calvello is a Content and Communications Manager at G2. She received her Bachelor of Arts degree from Elmhurst College (now Elmhurst University). Mara writes content highlighting G2 newsroom events and customer marketing case studies, while also focusing on social media and communications for G2. She previously wrote content to support our G2 Tea newsletter, as well as categories on artificial intelligence, natural language understanding (NLU), AI code generation, synthetic data, and more. In her spare time, she's out exploring with her rescue dog Zeke or enjoying a good book.

