


Menschen sind mit peripherem Sehen ausgestattet; aber Computer erreichen jetzt mit der Objekterkennung eine ähnliche Kompetenz.
Ob Tesla Autopilot oder Deebot-Staubsauger, Rechengeräte werden mit neuartigen generativen KI-Algorithmen betrieben, um die Verarbeitungsgeschwindigkeit zu erhöhen und physische Objekte zu benennen. Bekannt als Objekterkennung in Kürze, hat diese mit Bildverarbeitungssoftware entworfene Vision-Simulation den Stab des Sehens und der Sicht an Computer weitergegeben.
Der Hauptzweck der Objekterkennung besteht darin, physische oder digitale Objekte mit narrensicherer Präzision zu segmentieren, zu lokalisieren und zu annotieren, um eine bestimmte Aufgabe zu erfüllen.
Die Objekterkennung hat neue Wege der robotischen Unterstützung eröffnet, die darauf abzielen, selbstassistierende Geräte herzustellen, um mühsame Aufgaben zu erleichtern. Lernen wir das im Detail kennen.
Was ist Objekterkennung?
Objekterkennung ist ein eng gefasster KI-Ansatz, der Objekte in digitalen Fotos oder Videos identifiziert, klassifiziert und lokalisiert. Das Hauptziel der Objekterkennung ist es, die Instanzen jedes Objekts zu erkennen, sie zu segmentieren und ihre notwendigen Merkmale für die Echtzeitkategorisierung und tiefgehende Modularität zu analysieren.
Die Objekterkennung ist Teil der gesamten Datenbankarchitektur eines Unternehmens. Einige Unternehmen haben diese Technologie erfolgreich übernommen, während andere darauf warten, dass sie als erfolgreiche Datenbankverwaltungstechnik angekündigt wird.
Wichtige Beispiele für die Objekterkennung sind Sicherheit und Überwachung, Zugangskontrolle, biometrische Anwesenheit, Überwachung des Straßenzustands, selbstassistierende Maschinen und Schutz der Meeresgrenzen.
Wie funktioniert die Objekterkennung?
Die Objekterkennung funktioniert ähnlich wie die Objekterkennung. Der einzige Unterschied besteht darin, dass die Objekterkennung der Prozess der Identifizierung der richtigen Objektkategorie ist, während die Objekterkennung einfach die Anwesenheit und den Standort des Objekts in einem Bild erkennt.
Objekterkennungsaufgaben können mit zwei verschiedenen Datenanalysetechniken durchgeführt werden.
- Bildverarbeitung ist ein Teil des unüberwachten Lernens, das keine historischen Trainingsdaten benötigt, um Analysemodelle zu lehren. Die Modelle trainieren sich selbst anhand der Eingabebilder und erstellen Merkmalskarten, um Vorhersagen zu treffen. Die Bildverarbeitung erfordert keine hohe grafische Verarbeitungskapazität oder große Datensätze für die Ausführung.
- Tiefes neuronales Netzwerk: Ein tiefes neuronales Netzwerk ist im Allgemeinen ein überwachter Lernalgorithmus, der große Datensätze und hohe GPU-Rechenleistung benötigt, um Objektklassen vorherzusagen. Es ist eine genauere Methode, um teilweise verdeckte, komplexe Objekte oder in unbekannten Hintergründen platzierte Objekte in einem Bild zu klassifizieren.
Das Training eines tiefen neuronalen Netzwerks ist eine arbeitsintensive und teure Aufgabe. Einige groß angelegte Datensätze bieten jedoch die Verfügbarkeit von beschrifteten Daten.
Wussten Sie schon? COCO, ein groß angelegter Datensatz zur Objekterkennung, Segmentierung und Beschriftung, kann verwendet werden, um ein tiefes neuronales Netzwerk zu trainieren.
Einige Funktionen, die Sie von MS COCO erwarten können:
- Objektsegmentierung
- Erkennung im Kontext
- Superpixel-Stuff-Segmentierung
- Vortrainiert auf 33OK-Bildern
- 1,5 Millionen Objektinstanzen
- 80 Objektklassen
- 91 Stuff-Kategorien
- 5 Beschriftungen pro Bild
- 250.000 Personen mit Schlüsselpunkten
Möchten Sie mehr über Bildverarbeitungssoftware erfahren? Erkunden Sie Bilderkennung Produkte.
Wichtigkeit der Objekterkennung
Nachdem wir die Arbeitsmethodik verstanden haben, ist es an der Zeit zu diskutieren, was die Objekterkennung wichtig macht.
Die Objekterkennung bildet die Grundlage für andere wichtige KI-Visionstechniken wie Bildklassifizierung, Bildabruf, Bildverarbeitung oder Objekt-Co-Segmentierung, die bedeutungsvolle Informationen aus realen Objekten extrahieren. Entwickler und Ingenieure nutzen diese Techniken, um futuristische Maschinen zu bauen, die Lebensmittel und Medikamente an unsere Haustüren liefern!
Ein Objekterkennungsalgorithmus kann automatisch Bewegungen von Vieh, Verkehrszeichen und Fahrspuren erkennen, sodass selbstfahrende Fahrzeuge ihre Ziele erreichen können. Dies wiederum eliminiert die Notwendigkeit für Fahrer, logistische Besorgungen zu erledigen.

Die Objekterkennung kann auch in Mobilfunknetzen betrieben werden, indem die Schichten eines tiefen neuronalen Netzwerks reduziert werden. Sie wird bereits in Sicherheitsscannern oder Metalldetektoren an Flughäfen eingesetzt, um unerwünschte und illegale Objekte zu erkennen.
Abgesehen davon nutzen Unternehmen die Objekterkennung für die Zählung von Personen, die Erkennung von Nummernschildern, Spracherkennung und die Beweiserkennung. Ein leichter Mangel an Genauigkeit beeinträchtigt jedoch manchmal ihre Effizienz bei der Erkennung von kleinen Objekten. Ein Mangel an hundertprozentiger Genauigkeit macht sie für kritische Bereiche wie Bergbau und Militär weniger bevorzugt.
Bildklassifizierung vs. Objekterkennung
Die Objekterkennung wird oft mit der Bildklassifizierung verwechselt. Während dies die Seiten desselben Rubik's Cube sind, gibt es hier einige bemerkenswerte Unterschiede.
-png.png)
Bildklassifizierung ist ein einfaches Konzept zur Kategorisierung eines multispektralen Bildes basierend auf seinen Komponenten. Wenn Ihnen ein Bild eines Hundes gegeben wird, kann das Bildklassifizierungsmodell seine Kerneigenschaften interpretieren und das Bild leicht als „Hund“ kennzeichnen. Wenn ein Bild zwei Objekte enthält, wie eine Katze und einen Hund, verwendet das Modell einen Multi-Label-Klassifikator, um beide Objekte zu klassifizieren.
Das Bildklassifizierungsmodell akzeptiert keine Variable zur Objektlokalisierung, außer der Definition der Objektklasse. Hier kommt die Objekterkennung ins Spiel.
Ein Objekterkennungsalgorithmus kann die Objektklasse identifizieren und den genauen Standort der Objekte in einem Bild vorhersagen, indem er Begrenzungsrahmen um sie herum zeichnet. Es ist eine Kombination aus Bildklassifizierung und Objektlokalisierung, die es dem System ermöglicht, zu wissen, wo Objekte in einem Bild platziert sind und warum. Es befähigt ein System, jedes Objekt visuell zu analysieren und seine Anwendung im realen Leben zu bestimmen, genau wie Menschen es tun.
Objekterkennungsmodelle
Die bevorzugtesten Ansätze zur Objekterkennung sind maschinelles Lernen oder tiefes Lernen. Beide Methoden arbeiten in Verbindung mit einer Support Vector Machine (SVM), um die Merkmale zu extrahieren, den Algorithmus zu trainieren, und Objekte zu kategorisieren.
Die Objekterkennung ist ohne einen geeigneten Datensatz nicht möglich. Datensätze decken die wichtigsten bekannten Merkmale eines Objekts ab, wie Standort, Abmessungen, Kategorie oder Farben. In der Praxis, wenn ein Objekterkennungsmodell auf einem Datensatz von etwas mit Rädern, einer Windschutzscheibe, Blinkern, einem Motor und einem Kofferraum vortrainiert ist, kann es das Objekt im gegebenen Bild genau als Auto klassifizieren.
Verschiedene Arten von Objekterkennungsmethoden haben unterschiedliche Wirksamkeits- und Anwendbarkeitsniveaus in verschiedenen Branchen. Lassen Sie uns dies im Detail verstehen:
Maschinelles Lernen
Der Vorteil der Verwendung eines maschinellen Lernalgorithmus zur Durchführung der Objekterkennung besteht darin, dass er sich auf manuell eingegebene Daten zur Klassifizierung stützt, nicht auf automatische Trainingsdaten. Dies macht den gesamten Algorithmus weniger fehleranfällig und stabiler.
Die Objekterkennung ist ein überwachtes maschinelles Lernproblem, was bedeutet, dass Sie vortrainierte Modelle verwenden müssen, um Objektdetektoren auszulösen. Die Liste der Klassen im Trainingsdatensatz eines ML-Algorithmus muss zu einem bestimmten Bild oder einer Liste von Bildern gehören.
Maschinelle Lernansätze wie Natural Language Processing (NLP) identifizieren und klassifizieren Objekte basierend auf ihrer Beleuchtungsintensität vor einem Hintergrund. ML-Algorithmen für 2D-Objekte können auch wiederverwendet werden, um 3D-Objekte in Bildern zu erkennen.
Aggregate Channel Features (ACF)
ACF ist eine maschinelle Lernmethode, die spezifische Objekte in einem Bild basierend auf einem Trainingsbilddatensatz und den Bodenstandorten der Objekte erkennt. Es wird hauptsächlich für die Erkennung von Objekten aus mehreren Ansichten verwendet, wie z.B. die Identifizierung von 3D-Objekten, die von drei Kamerarigs aufgenommen wurden. Selbstassistierende Fahrzeuge, Fußgängererkennung und Gesichtserkennung arbeiten nach diesem Prinzip.
ACF kombiniert verschiedene Kanäle, die Merkmale aus einem Bild als Gradienten oder Pixel extrahieren, anstatt ein Bild an verschiedenen Stellen zu beschneiden. Zu den gängigen Kanälen gehören Graustufen oder RBG, abhängig von der Schwierigkeit des Objekterkennungsproblems. ACF gibt Ihnen ein reichhaltigeres Verständnis von Objekten und beschleunigt die Erkennungsgeschwindigkeit für höhere Genauigkeit.
Tipp: Um einen ACF-Objektdetektor zu erstellen, deklarieren und definieren Sie eine MATLAB-Programmfunktion, „trainACFObjectDetector()“ und laden Sie die Trainingsbilder. Testen Sie die Erkennungsgenauigkeit an einem separaten Testbild.
DPM-Objekterkennung
Das Deformable Parts Model (DPM) ist ein maschineller Lernansatz, der Objekte mit einer Mischung aus grafischen Modellen und deformierbaren Teilen des Bildes erkennt. Es enthält vier Hauptkomponenten:
- Ein grober Wurzelfilter definiert mehrere Begrenzungsrahmen in einem Bild, um die Objekte zu erfassen.
- Teilfilter decken die Fragmente der Objekte ab und verwandeln sie in Pfeile dunklerer Pixel.
- Ein räumliches Modell speichert den Standort aller Objektfragmente relativ zu den Begrenzungsrahmen im Wurzelfilter.
- Ein Regressor verringert den Abstand zwischen Begrenzungsrahmen und Bodenwahrheit, um Objekte genau vorherzusagen.

Quelle: lilianweng.github.io/
Tipp: Das Extrahieren wichtiger Merkmale von auffälligen Objekten kann nützlich sein, während Daten von Baustellen gesammelt werden, um den Arbeitsfortschritt zu verfolgen oder Umweltschutz und Sicherheit während der Arbeit durchzusetzen.
Tiefes Lernen
Während maschinelle Lernmodelle auf der manuellen Auswahl der Merkmale basieren, kommen tiefe Lernworkflows mit automatischer Merkmalsauswahl, um Ihren Tech-Stack zu unterstützen. Tiefe Lernansätze wie konvolutionale neuronale Netzwerke erzeugen schnellere und genauere Objektvorhersagen. Natürlich benötigen Sie dafür eine höhere Grafikverarbeitungseinheit (GPU) und größere Datensätze!
Tiefes Lernen wird für eine Vielzahl von Objekterkennungsaufgaben verwendet. Moderne Videoüberwachungskameras oder Überwachungssysteme werden von neuronalen Netzwerken betrieben, um unbekannte Gesichter oder Objekte erfolgreich zu erkennen.
Hier sind einige tiefe Lernansätze zur Bewältigung der Objekterkennung.
You Only Look Once (YOLO)
YOLO ist ein einstufiges Objekterkennungsframework, das für industrielle Anwendungen entwickelt wurde. Sein effizientes Design und seine hohe Leistung machen es hardwarefreundlich und effizient. Es ist ein CNN, das auf großen visuellen Datenbanken wie Image Nets trainiert wurde und in Open-Source-Editoren in TensorFlow, Darknet oder Python codiert werden kann.
YOLO erzeugt modernste Objekterkennungen mit blitzschnellen 45 Bildern pro Sekunde. Bis heute wurden verschiedene Versionen von YOLO, wie YOLOv1, YOLOv2 oder YOLOv3, veröffentlicht.
Die neueste Version, YOLOv6, kann auf benutzerdefinierten Datensätzen in PyTorch über Anwendungsprogrammierschnittstellen (APIs) trainiert werden. Pytorch ist ein Python-Paket und eine der bevorzugtesten Formen der tiefen Lernforschung. YOLOv6 ist ausschließlich darauf trainiert, sich bewegende Fahrzeuge auf der Straße zu erkennen.
Wussten Sie schon? YOLO oder regionenbasierte konvolutionale neuronale Netzwerke (R-CNN) verwenden die Funktion Mean Average Precision oder mAP(). Es vergleicht einen Bodenbegrenzungsrahmen mit einem tatsächlich erkannten Rahmen und gibt eine Wahrscheinlichkeit oder einen Vertrauensscore zurück. Je höher der Score, desto genauer die Vorhersage.
SSD (Single Shot Detector)
SSD ist ein benutzerdefinierter Objektdetektor ohne spezifisches Region Proposal Network (verschiedene Teile eines Bildes, die in einem Netzwerk zusammengefasst sind) zur Objektvorhersage. Es sagt den Standort und die Art des Objekts in einem Bild direkt in einem einzigen Durchgang durch eine Reihe von Schichten eines tiefen Lernmodells voraus.
SSD ist in zwei Teile unterteilt:
1. Backbone
Das Backbone des vortrainierten Bildklassifizierungsnetzwerks extrahiert die Merkmale aus dem Bild, um das Bild zu identifizieren. Diese Netzwerke, wie ResNet, sind auf ImageNets (große Bilddatenbanken) trainiert und von der internen Bildklassifizierungsschicht getrennt. Es lässt das Backbone-Modell als tiefes neuronales Netzwerk, das ausschließlich auf Millionen von Bildern trainiert ist, um semantische Informationen aus dem Eingabebild zu extrahieren und gleichzeitig die räumliche Struktur des Bildes zu bewahren.
Für ResNet34 erstellt das Backbone 256x7x7 Merkmalskarten für jedes Eingabebild.
2. Kopf
Der Kopf des Objekterkennungsmodells ist nur eine neuronale Netzwerk-Hirnschicht, die dem Backbone hinzugefügt wird und im letzten Regressionsprozess des Bildes hilft. Es gibt den räumlichen Standort des Objekts aus und kombiniert ihn mit der Objektklasse in den letzten SSD-Stufen.
Quelle:developers.arcgis.com
Andere wichtige Komponenten
Hier sind die wichtigen Komponenten, die ein SSD-Modell ausmachen, um die Objekterkennung in Echtzeit durchzuführen.
- Gitterzelle: Genau wie der YOLO-Algorithmus teilt der SSD-Algorithmus den Begrenzungsrahmen in ein 5x5-Gitter. Jede Gitterzelle ist dafür verantwortlich, die Form, den Standort, die Farbe und das Label des Objekts auszugeben, das sie enthält.
- Ankerbox: Während das CNN das Bild in ein Gitter unterteilt, wird jeder Zelle im Gitter mehr als eine Ankerbox zugewiesen. Das SSD-Modell verwendet eine Vorlagenabgleichstechnik während der Trainingsperiode, um den Begrenzungsrahmen mit jedem Bodenwahrheitsobjekt des Bildes abzugleichen.

Quelle: pyimagesearch.com
Hier wird der vorhergesagte Begrenzungsrahmen in Rot gezeichnet, während der Bodenwahrheitsbegrenzungsrahmen (handbeschriftet) in Grün ist. Da es einen hohen Grad an Überlappung gibt, ist diese Ankerbox dafür verantwortlich, die Anwesenheit von Objekten zu identifizieren. Der Intersection over Union (IoU) kann hier gemessen werden als
- Seitenverhältnis: Jedes Objekt hat eine andere Form und Konfiguration. Einige sind runder und größer, während andere geschrumpft und kürzer sind. Die SSD-Architektur hilft, Seitenverhältnisse im Voraus durch einen Verhältnisparameter zu deklarieren.
- Zoomstufe: Der Zoomparameter kann kleinere Objekte in jeder Gitterzelle vergrößern, um ihre Anwesenheit, Kategorie und ihren Standort zu identifizieren. Wenn wir beispielsweise ein Gebäude und einen Park aus einem Hubschrauber identifizieren müssen, müssen wir den SSD-Algorithmus so skalieren, dass er sowohl die größeren als auch die kleineren Objekte erkennt.
- Rezeptives Feld: Das rezeptive Feld wird als das bewegliche Set von Pixeln des Bildes definiert, an dem der Algorithmus gerade arbeitet. Verschiedene Schichten eines CNN-Modells berechnen verschiedene Regionen eines Eingabebildes. Je tiefer es geht, desto größer wird die Größe des Objekts. Genau wie ein Mikroskop vergrößert ein CNN-Modell jedes Pixel des Objekts, um zu berechnen, zu welcher Kategorie es gehört.
Intersection over Union (IoU): Fläche der Überlappung / Fläche der Vereinigung
EfficientNet
EfficientNet ist eine Architektur für konvolutionale neuronale Netzwerke, die alle Dimensionen eines Objekts gleichmäßig skaliert, bevor sie erkannt werden. Diese neuronalen Netzwerke werden zu festen Kosten von Anwendungssoftware entwickelt. Über die Verfügbarkeit von Ressourcen hinaus können EfficientNet-Algorithmen über einen Anwendungsbereich hinweg skaliert werden, um bessere Objekterkennungsergebnisse zu erzielen.
EfficientNet gilt als eines der besten bestehenden CNN-Modelle für die Objekterkennung, da es state-of-the-art Genauigkeit auf Lerndatensätzen wie Flowers (98,8%) erreicht hat, während es 6,1x schneller ist als andere Objekterkennungsmodelle.
Mask R-CNN
Dies erweitert Faster R-CNN durch das Pooling des Region Proposal Network und vortrainierte CNNs wie AlexNet. Ein Region Proposal Network ist ein Netzwerk von Regionen, die durch Begrenzungsrahmen getrennt sind. Mask R-CNN extrahiert Merkmale aus dem Bild und erstellt Merkmalskarten, um die Anwesenheit von Objekten zu erkennen. Es erzeugt auch eine hochwertige Maske (Begrenzungsrahmen) für jedes Objekt, um es vom Rest zu trennen.
Wie funktioniert Mask R-CNN?
Mask R-CNN wurde mit Faster R-CNN und Fast R-CNN gebaut. Während Faster R-CNN eine Softmax-Schicht hat, die die Ausgaben in zwei Teile unterteilt, eine Klassenprädiktion und eine Begrenzungsrahmenverschiebung, ist Mask R-CNN die Hinzufügung eines dritten Zweigs, der die Objektmaske beschreibt, die die Form des Objekts ist. Es ist von anderen Kategorien unterscheidbar und erfordert die Extraktion der grafischen Koordinaten des Objekts, um den Standort genau vorherzusagen.
Mask R-CNN ist eine Kombination aus zwei CNNs, die durch das Poolen einer Schicht von Objektmasken, auch bekannt als Region of Interest (ROI), parallel zum bestehenden Begrenzungsrahmen-Locator funktioniert.
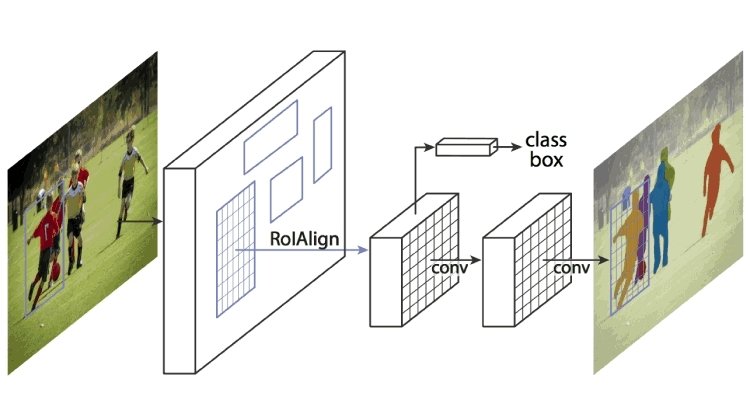
Quelle: viso.ai
Merkmale von Mask R-CNN
Lassen Sie uns kurz einige Merkmale besprechen.
- Es ist ein extrem einfaches Modell zu trainieren und läuft mit einer Geschwindigkeit von 5 Bildern pro Sekunde (FPS)
- Es funktioniert wunderbar gut, um menschliche Gesichter in verschiedenen Konfigurationen zu erkennen.
- Es übertrifft alle Einzelmodelleinträge bei jeder Objekterkennungsaufgabe.
- Mask R-CNN kann leicht auf andere Aufgaben verallgemeinert werden. Es kann auch verwendet werden, um menschliche Posen in einem bestimmten Rahmen zu schätzen.
- Es dient als solide Grundlage, um selbstassistierende Roboter zu schaffen, die unsere zukünftige Umgebung vorhersagen werden.
Alle überwachten Objekterkennungsalgorithmen hängen von beschrifteten Datensätzen ab, was bedeutet, dass Menschen ihr Wissen anwenden müssen, um das neuronale Netzwerk auf verschiedenen Eingaben zu trainieren. Label_maps können die beschrifteten Objekte in einem Datensatz () Funktionen abrufen, um die richtige Objektkategorie abzuleiten.
Was sind Label Maps?
Die Label-Map() in der Tensorflow-Programmierung ordnet Ausgabennummern der Objektklasse zu. Wenn die Ausgabe eines Objekterkennungsalgorithmus 4 ist, scannt diese Funktion die Trainingsdaten und gibt die Klasse zurück, die der Zahl „4“ entspricht. Wenn „4“ als „Flugzeug“ angegeben ist, wird der Ausgabetext „Flugzeug“ sein.
Objekterkennungsanwendungen in verschiedenen Branchen
Bisher hat die Objekterkennung Erfolge in kritischen Bereichen wie Sicherheit, Transport, Medizin und Militär erzielt. Softwareunternehmen nutzen sie, um große relationale Datensätze automatisch abzurufen und zu kategorisieren, um die Produktionseffizienz zu steigern. Dieser Prozess ist auch als Datenkennzeichnung oder Datenannotation bekannt.
Hier sind einige Anwendungen aus dem wirklichen Leben, die die Bedeutung von KI-gestützten Objekterkennungssystemen verdeutlichen:
- Polizei und Forensik: Die Objekterkennung kann bestimmte Objekte wie eine Person, ein Fahrzeug oder einen Rucksack von Bild zu Bild verfolgen und lokalisieren. Sie ermöglicht es Polizeibeamten und Forensikern, jeden Winkel eines Tatorts zu inspizieren, um Beweismaterial zu sammeln. Aufgrund des großen Datenvolumens ist der Objekterkennungsprozess jedoch etwas knifflig und erfordert Stunden von Filmmaterial, um zu identifizieren, was zum Erfolg eines Falls beitragen kann.
- Kontaktloses Bezahlen: Viele Restaurants verwenden RFID-Objektverfolgung, um den Rechnungsbetrag durch Scannen leerer Teller zu berechnen. Dieser Prozess fügt automatisch den Preis aller Artikel zur Gesamtsumme hinzu und eliminiert die üblichen Bar- und Kredittransaktionen in einem Restaurant.
- Inventar und Lagerhaltung: Logistikfachleute können fertige Waren durch Echtzeit-Objekterkennung leicht erkennen, klassifizieren und für den Transport aufnehmen. Einige Unternehmen haben sogar eine automatische Lagerhaltung entwickelt, um die Navigation in Lagerregalen zu erleichtern. Es kann auch die Lieferkettenverwaltung automatisieren und regulieren, indem es Bestandsniveaus verfolgt, um den optimalen Produktionsfluss zu bestimmen.
- Parksystem: Vorintegrierte visuelle Detektoren in Autos können offene Parkplätze auf Parkplätzen oder in Parkhäusern erkennen. Sie können dem Fahrer auch eine Vorder- und Rückansicht des Parkplatzes und anderer Fahrzeuge bieten, um das Auto sicher zu parken.
- Katastrophenhilfe: Jüngste Schwankungen in unseren Ökosystemen, wie der Abbau der Ozonschicht, der Anstieg der Treibhausgase und die globale Erwärmung, haben Entwickler und Ingenieure dazu veranlasst, Objekterkennungsanwendungen zu erstellen. Durch die Feinabstimmung neuronaler Netzwerke und die Verwendung wesentlicher Toolkits können schnelle und genaue Modelle für die Katastrophenhilfe und -verwaltung erstellt werden.
- Biometrische und Gesichtserkennung: Sicherheitskontrollen an Flughäfen verwenden Gesichtserkennung in der Nähe der Abflugschalter, um die Identität von Reisenden zu bestätigen. Gesichtserkennungsgeräte vergleichen Identitätsdokumente mit anderen biometrischen Technologien, wie Fingerabdrücken, um Betrug und Identitätsdiebstahl zu verhindern. Bei internationalen Transfers verwenden Einwanderungs- und Zollabteilungen Gesichtserkennungen, um das Porträt des Reisenden mit dem Bild im Pass zu vergleichen.
Top 5 Bildverarbeitungsplattformen
*Dies sind die 5 führenden Bildverarbeitungssoftware basierend auf dem G2 Fall 2024 Grid Report im Dezember 2024

Ein Schutzschild für das menschliche Sehen
Die Objekterkennung ist nicht nur das Ergebnis der Supercomputer-Generation; sie ist auch ein Versprechen einer sicheren Zukunft für die Menschheit. Neben der Ausstattung von Maschinen mit KI-gestützter Vision hat sie unsere weltlichen Probleme besser entdeckt, analysiert und entwirrt als wir selbst.
Die Objekterkennung ist vielleicht noch nicht umfangreich – aber sie hat den ersten Weg des Erfolgs über Geschäftsketten hinweg geebnet. Es gibt kein Zurück mehr von hier.
Erkunden Sie, wie KI über Grenzen hinausgeht mit Text-to-Speech-Software, um Sehbehinderte zu unterstützen und die Datenzugänglichkeit zu verbessern.Dieser Artikel wurde ursprünglich 2022 veröffentlicht. Er wurde mit neuen Informationen aktualisiert.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

