


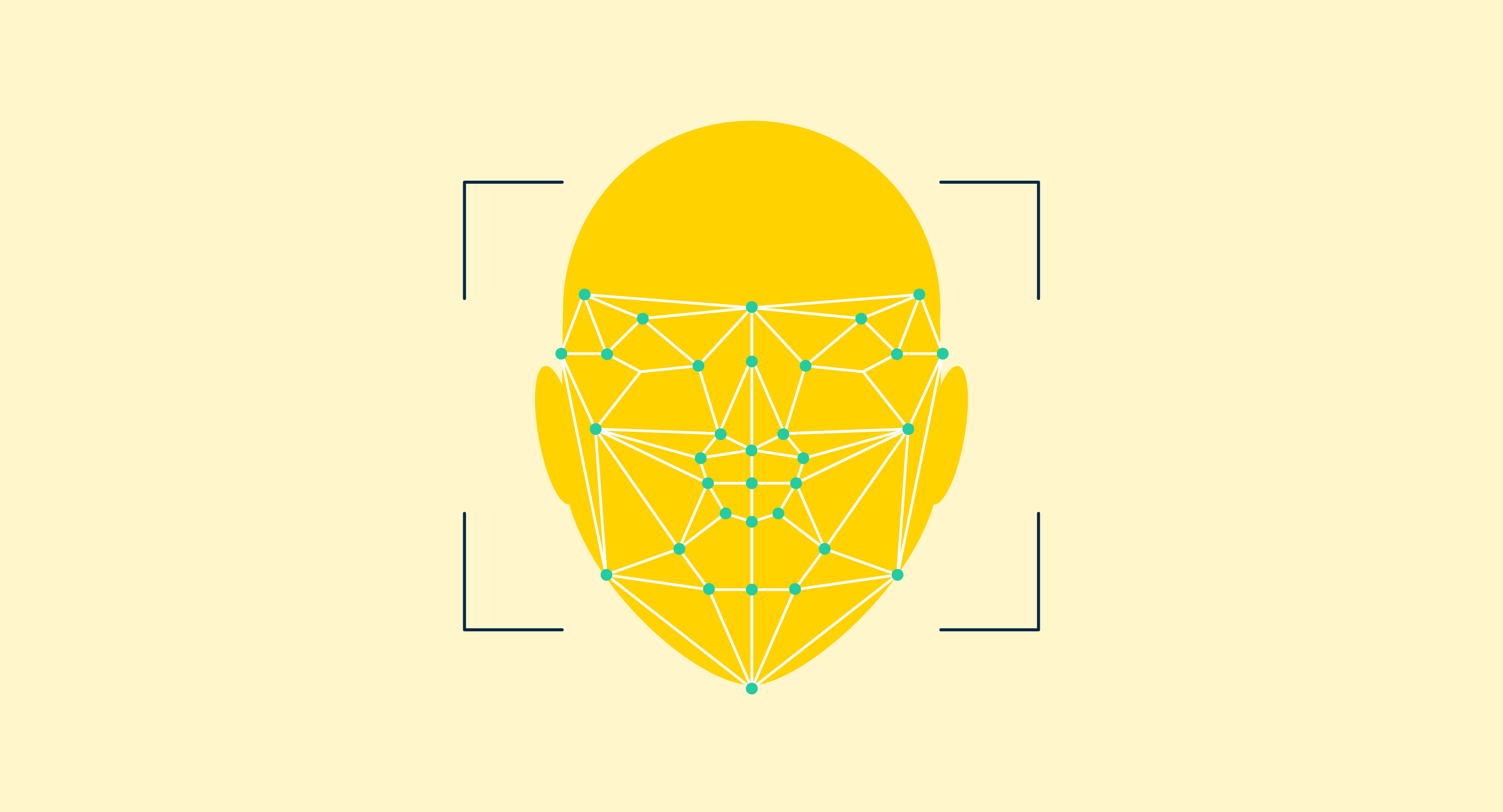
Unsere Welt ist voller Bilder, und meistens können wir Menschen genau entschlüsseln, was diese Bilder sind und was sie bedeuten, ganz einfach. Für Computer ist das nicht so einfach.
In den letzten zehn Jahren haben jedoch Fortschritte in der künstlichen Intelligenz (KI) und im maschinellen Lernen die Fähigkeit von Computern, visuelle Inhalte zu verstehen, erheblich verbessert.
Mit komplexen Bildverarbeitungstools können Computer nun verschiedene Elemente innerhalb eines Bildes identifizieren und diese Informationen an uns weitergeben. Dadurch sind sie viel besser in der Lage, zu interpretieren und zu erklären, worum es in einem Bild geht.
Bilderkennung ist eine Unterkategorie der Computer Vision, einem breiteren Feld, in dem visuelle Inhalte identifiziert und verarbeitet werden, um sie so ähnlich wie möglich der menschlichen Sicht und dem Verständnis zu machen. Je ausgefeilter die KI wird, desto ausgefeilter wird auch Bildverarbeitungssoftware und ihre Fähigkeit, visuelle Inhalte zu verstehen.
Was ist Bilderkennung?
Bilderkennung ist ein Prozess, bei dem Maschinen Objekte oder Merkmale, wie Menschen oder Tiere, innerhalb eines visuellen Bildes identifizieren. Durch einen komplexen Prozess der Analyse von Pixeln und deren Regelmäßigkeiten, Mustern, Farben und Formen können Computer bestimmen, was das Bild darstellt und es ähnlich klassifizieren, wie ein Mensch es interpretieren würde.
Als mehrstufiger Prozess umfasst die Bilderkennung das Sammeln von Anfangsdaten über ein Bild, gefolgt von der Verarbeitung durch die Maschine. Die Daten werden dann mit den realen Beispielen verglichen, mit denen die Maschine trainiert wurde. Diese Trainingsdatensätze sind entscheidend für den Aufbau einer Grundlage, von der aus die Bilderkennungssoftware lernen und die Erkennung zukünftiger Bilder genauer machen kann.
Beispiel für Bilderkennung
Einige Beispiele für Bilderkennung sind die automatische Tagging-Funktion von Facebook, die Google Lens-App, die Bilder übersetzt oder Elemente durchsucht, die Bildsuche von eBay und die automatisierte Bild- und Videoorganisation in Google Fotos. Durch die Analyse von Bildparametern kann die Bilderkennung helfen, Hindernisse zu navigieren und Aufgaben zu automatisieren, die menschliche Aufsicht erfordern.
Ein weiteres einfaches Beispiel für Bilderkennung ist optische Zeichenerkennung (OCR) Software, die gedruckten Text identifiziert und nicht bearbeitbare Dateien in formatierbare Dokumente umwandelt. Sobald der OCR-Scanner die Zeichen im Bild bestimmt hat, konvertiert er sie und speichert sie in einer Textdatei.
Es versteht sich von selbst, dass alle Bilderkennungstechniken auf Video-Feeds angewendet werden können. Denn im Grunde besteht ein Video aus einer Gruppe von Bildern, die schnell gezeigt werden. Daher kann die Technik der Bilderkennung auf Videos angewendet werden.
Möchten Sie mehr über Bildverarbeitungssoftware erfahren? Erkunden Sie Bilderkennung Produkte.
Bilderkennung vs. Objekterkennung
Bilderkennung beinhaltet das Identifizieren und Kategorisieren der Objekte, die in einem Bild oder Video gefunden werden, indem erlernte Muster und Merkmale verwendet werden, um den Inhalt genau zu bestimmen. Das Ziel ist, dass die Maschine erkennt, was im Bild passiert, ähnlich wie die menschliche Wahrnehmung.
Objekterkennung hingegen hat das spezifischere Ziel, bestimmte Objekte innerhalb eines Bildes zu identifizieren.
Mit anderen Worten, die Bilderkennung interpretiert den gesamten Inhalt eines Bildes breit, während Objekterkennung damit beauftragt ist, spezifische Teile des Bildes zu identifizieren und zu klassifizieren, wie vom Benutzer definiert.
Beide Prozesse verwenden maschinelle Lernalgorithmen, um die verschiedenen Elemente innerhalb eines Bildes zu lernen, zu verarbeiten und zu klassifizieren. Ihr Ziel und Ergebnis unterscheiden sich jedoch leicht – die Objekterkennung ist spezifischer mit einem engeren Arbeitsbereich.
Bilderkennung vs. Computer Vision
Bilderkennung ist eine Unterkategorie der Computer Vision. Viele verwenden diese beiden Begriffe austauschbar.
-png.png)
Computer Vision ist ein breites Feld, das verschiedene Werkzeuge und Strategien umfasst, die darauf abzielen, visuelle Fähigkeiten in Maschinen und Computersysteme zu integrieren. Diese Techniken umfassen Objektverfolgung, Bildsynthese, Bildsegmentierung, Szenenrekonstruktion, Objekterkennung und Bildverarbeitung. Die Computer Vision-Technik treibt mehrere Innovationen an, wie medizinische Bildgebung, anatomische Organstudien, selbstfahrende Autos, robotergestützte Prozessautomatisierung und industrielle Automatisierung. Das Hauptziel ist es, die menschlichen Sehfähigkeiten in Computersystemen zu replizieren, damit sie mehr als eine Aufgabe gleichzeitig erledigen können, indem sie ihren visuellen Zustand und ihr Erscheinungsbild erkennen.
Bilderkennung ist eine Unterkategorie innerhalb der Computer Vision-Technologie, die sich auf das Erkennen, Kategorisieren und Umstrukturieren von Bildelementen innerhalb digitaler statischer Fotografien, Videos und realer Szenarien konzentriert. Diese Software ist auf Bildsätze mit ähnlichen Merkmalen wie der des Testsatzes vortrainiert. Der Bilderkennungsalgorithmus analysiert die Position von Objekten, extrahiert Merkmale, übermittelt sie an eine Pooling-Schicht und speist die Merkmale schließlich in eine Support Vector Machine (SVM) ein, um die endgültige Klassifizierung durchzuführen. Häufige Anwendungen umfassen Gesichtserkennung, biometrische Authentifizierung, Produktidentifikation und Inhaltsmoderation.
Arten der Bilderkennung
Bilderkennung wird typischerweise in drei Kategorien unterteilt, basierend darauf, wie die Maschine trainiert wurde:
- Überwachtes Lernen. Wenn Daten gekennzeichnet sind und die Kategorien für Bildelemente im Voraus bekannt sind, ist überwachtes Lernen der beste Ansatz. Es kann verschiedene Kategorien unterscheiden, zum Beispiel „keine Katze“ und „eine Katze“, und diese Teile des Bildes erkennen.
- Unüberwachtes Lernen. Wenn Kategorien unbekannt sind und Bilder in die Maschine eingespeist werden, erkennt unüberwachtes Lernen Muster in den Daten. Die Analyse des Bildes basiert auf Attributen und Merkmalen, anstatt auf vorprogrammierten Kategorien oder Objekten.
- Selbstüberwachtes Lernen. Wenn einige Daten gekennzeichnet sind, die Maschine jedoch noch lernt, wie sie mit weniger spezifischen Informationen arbeiten kann, kann selbstüberwachtes Lernen ein guter Ansatz sein. Es ist eine Untergruppe des unüberwachten Lernens, bei dem während des Analyseprozesses Labels erstellt werden. In diesem kritischen Trainingsschritt ist mehr Aufsicht erforderlich, da er bestimmt, wie gut die Maschine zukünftige Bilder erkennen kann.
Innerhalb jeder dieser Kategorien können verschiedene Arten von Anwendungen für eine umfassendere und spezifischere Bilderkennung verwendet werden. Dazu gehören:
- Gesichtserkennung. Diese spezialisierte Art der Objekterkennung trainiert Maschinen, individuelle Gesichtszüge zu identifizieren und zu verarbeiten. Anwendungen reichen von Sicherheit und Überwachung bis hin zur Strafverfolgung. Zum Beispiel verwenden Flughafensicherheit und Grenzkontrollen jetzt häufig Gesichtserkennung, um die Merkmale eines Menschen vor der Kamera mit dem Identitätsdokument zu vergleichen, um ihre Identität zu überprüfen.
- Szenenerkennung. Landschaften und Gebäude können auch von Bilderkennungssoftware identifiziert werden. Dies kann auf verschiedene Weise genutzt werden, wie selbstfahrende Fahrzeuge, Kartensysteme oder Gaming-Software wie Augmented- und Virtual-Reality-Headsets.
- Gestenerkennung. Während das Erkennen statischer Bilder für Computer eine Herausforderung darstellt, kann das Erkennen und Bewerten von Bewegungen, insbesondere von Menschen, noch komplexer sein. Bilderkennungstools können programmiert werden, um Handbewegungen, Gesichtsausdrücke und mehr zu lesen und zu verstehen.
- Optische Zeichenerkennung (OCR). Feste Zeichen wie Buchstaben und Zahlen sind für Computer leichter zu entschlüsseln, insbesondere wenn die Maschine darauf trainiert wurde, diese visuellen Elemente zu erkennen und vorab zugewiesene Kategorien für deren Organisation hat. Handschriftliche Dokumente müssen möglicherweise gescannt und in digitalen Text umgewandelt werden. Diese Technik ist eine der einfachsten und schnellsten Möglichkeiten, schriftliche Informationen zu digitalisieren.
Wie funktioniert Bilderkennung?
Damit ein Computer Bilder und Muster erkennen kann, verwendet er einen Prozess, der als Deep Learning bekannt ist. Dies ist eine Form des maschinellen Lernens, bei der tiefe neuronale Netzwerke die komplexen Entscheidungsfähigkeiten des menschlichen Gehirns in einer künstlichen Umgebung nachbilden.
Diese tiefen neuronalen Netzwerke bestehen aus drei oder mehr Schichten, oft Hunderte oder Tausende, die das Modell der Bilderkennungssoftware für reale Anwendungen trainieren. Ähnlich wie unser Gehirn zahlreiche miteinander verbundene Knoten enthält, um Informationen durch unseren Körper zu leiten, arbeiten diese Computernetzwerke auf vergleichbare Weise.
Diese Knoten im Netzwerk identifizieren, was der Computer sieht, wägen verschiedene Optionen ab und liefern dann ein abschließendes Ergebnis darüber, was das Bild zeigt. Das Training dieser Knoten ist entscheidend, damit die Maschine lernt und ihre Genauigkeit im Laufe der Zeit verbessert.
Die Maschine muss mit einem großen Datensatz trainiert werden, der ihr hilft, die notwendigen Merkmale verschiedener Objekte zu lernen und zu identifizieren. Sobald sie trainiert ist, folgt der Bilderkennungsprozess typischerweise diesen sechs Schritten:
- Datensammlung. Daten werden in die Maschine eingespeist, normalerweise in einem überwachten Lernumfeld mit gekennzeichneten Bildern.
- Vorverarbeitung. Bevor das Training beginnt, werden Bilder angepasst, um Verzerrungen oder Störungen zu entfernen. Dies kann das Zuschneiden, Aufhellen oder anderweitige Anpassen der Bilder umfassen, um sie für die Maschine so nützlich wie möglich zu machen.
- Merkmalextraktion. Das Isolieren der Teile des Bildes, die kategorisiert werden müssen, ist ein wesentlicher Schritt im Training. Dies hilft der Maschine, zwischen verschiedenen Teilen des Visuellen zu unterscheiden.
- Modelltraining. Mit den gekennzeichneten Datensätzen wird das neuronale Netzwerk der Maschine wiederholt trainiert, bis Muster und Merkmale mit hoher Genauigkeit erkannt werden. Tagging und Segmentierung erfolgen in dieser Phase, um dem Modell mehr Informationen zum Verständnis des Bildes zu geben.
- Modelltest. Verschiedene Datensätze werden verwendet, um den Algorithmus weiter zu trainieren und zu testen, bis er bereit für den Einsatz ist. Diese Datensätze werden im Laufe der Zeit wahrscheinlich komplexer, von gekennzeichneten zu unbeschrifteten Datensätzen, um der Maschine zu helfen, zu lernen und genauer zu werden.
- Einsatz und erneuter Test. Wenn das Modell ausreichend getestet und validiert wurde, kann es für den breiteren Einsatz bereitgestellt werden.
Zum Beispiel könnte der Maschine ein Bild von zwei Hunden, die im Garten spielen, zugeführt werden. Die Bilderkennungssoftware würde beginnen, die Elemente des Bildes mit der Klassifizierung zu identifizieren, die Hunde vom Hintergrund zu trennen. Von dort aus könnten sie zurückgehen, um die einzelnen Hunde als „Hund“ und andere Elemente im Bild wie „Baum“, „Ball“ oder „Zaun“ zu kennzeichnen.
Branchen, die von Bilderkennung profitieren
Die geschäftlichen Anwendungen der Bilderkennung werden immer umfangreicher, da KI und maschinelles Lernen beispiellose Niveaus an Raffinesse und Genauigkeit erreichen. Für Aufgaben, die automatisiert werden könnten oder einen erheblichen menschlichen Aufwand erfordern, kann die Bilderkennung sowohl Zeit als auch Kosten erheblich reduzieren.
Einige der Branchen, die von dieser Technologie profitieren, sind:
- Einzelhandel. Bilderkennung in der Einzelhandelsbranche ist eine der besten Möglichkeiten, das Kundenerlebnis beim Einkaufen im Geschäft zu verbessern. Zum Beispiel kann es Outfits mit einem bestimmten Kunden basierend auf seinem aktuellen Stil kombinieren. Sicherheitssysteme können auch Bilderkennung verwenden, um potenzielle Ladendiebe oder andere Sicherheitsbedrohungen zu identifizieren.
- Gesundheitswesen. Radiologen können Bilderkennung verwenden, um schnell und einfach Probleme in MRTs und anderen medizinischen Bildgebungen zu identifizieren, was zu einer schnelleren und effektiveren Behandlung der Patienten führt.
- Landwirtschaft. Schädlinge und Krankheiten können für die Landwirtschaftsgemeinschaft verheerend sein. Mit Bilderkennungssoftware können Landwirte die visuelle Zusammensetzung von Pflanzen analysieren, sodass sie Korrekturmaßnahmen ergreifen können, bevor Probleme irreversibel werden.
- Finanzen. Menschliche Fehler in der Buchhaltung können unglaublich kostspielig sein, aber zahlreiche Aufgaben in der Finanzbranche können automatisiert werden, um Zeit und Geld zu sparen. Rechnungsverarbeitung, Ausgabenmanagement und Validierung von Finanztransaktionen sind alles Beispiele dafür, wie Bilderkennung helfen kann. Zum Beispiel können kleine Unternehmen schnell einen Papierbeleg auf ihrem Telefon scannen und in ihre Buchhaltungssoftware hochladen. Die Bilderkennung zieht die Informationen im Bild, um diese Ausgabendaten automatisch in ihre Aufzeichnungen aufzunehmen.
- Fertigung. Fehler in Produkten können kostspielige Fehler für die Fertigungsindustrie sein. Bilderkennung kann diese Fehler oder Abweichungen vom typischen Qualitätsstandard finden. Zum Beispiel kann die Bilderkennung im Bereich der pharmazeutischen Produktion leicht eine fehlende Pille aus einer Packung erkennen, bevor der Herstellungsprozess abgeschlossen ist und das Medikament in einer falschen Menge zum Verkauf verpackt wird.
Aufgaben der Bilderkennungssoftware
Bilderkennungssoftware basiert auf Deep Learning, genauer gesagt, künstlichen neuronalen Netzwerken.
Bevor wir die detaillierte Funktionsweise der Bilderkennungssoftware besprechen, lassen Sie uns die fünf häufigsten Aufgaben der Bilderkennung untersuchen: Erkennung, Klassifizierung, Tagging, Heuristik und Segmentierung.
Erkennung
Der Prozess des Auffindens eines Objekts in einem Bild wird als Erkennung bezeichnet. Sobald das Objekt gefunden ist, wird ein Begrenzungsrahmen darum gelegt.
Betrachten Sie zum Beispiel ein Bild eines Parks mit Hunden, Katzen und Bäumen im Hintergrund. Die Erkennung kann das Auffinden von Bäumen im Bild, eines Hundes, der auf dem Gras sitzt, oder einer Katze, die liegt, umfassen.
Sobald das Objekt erkannt ist, wird ein Begrenzungsrahmen darum gelegt. Natürlich können Objekte in allen Formen und Größen vorkommen. Abhängig von der Komplexität des Objekts werden Techniken wie Polygon-, semantische und Schlüsselpunktannotation zur Erkennung verwendet.
Klassifizierung
Es ist der Prozess der Bestimmung der Klasse oder Kategorie eines Bildes. Ein Bild kann nur eine einzige Klasse haben. Im vorherigen Beispiel, wenn es einen Welpen im Hintergrund gibt, kann er als "Hunde" oder einfach als Hundebilder klassifiziert werden. Wenn es Hunde verschiedener Rassen oder Farben gibt, können sie auch als "Hunde" klassifiziert werden.
Tagging
Tagging ist ähnlich wie Klassifizierung, zielt jedoch auf eine bessere Genauigkeit ab. Es versucht, mehrere Objekte in einem Bild zu identifizieren. Daher kann ein Bild ein oder mehrere Tags haben. Zum Beispiel kann ein Bild eines Parks Tags wie "Hunde", "Katzen", "Menschen" und "Bäume" haben.
Heuristik
Der Algorithmus sagt eine "Heuristik" für jedes Element innerhalb eines Bildes voraus, was eine projektive Bewertung eines Elements ist, das zu einer bestimmten Bildkategorie gehört. Die Heuristik ist ein geschätztes Maß, das normalerweise über eine Distanzmetrik wie die euklidische oder Minkowski-Metrik gemessen wird. Die Heuristik wird dann mit einem "Tensor"-Wert verglichen, der durch Kreuzmultiplikation von Dateneigenschaften in eine Anzahl von Gittern berechnet wird, in die das Bild unterteilt ist. Der Heuristikwert setzt ein vorbestimmtes Ziel für den Bilderkennungsalgorithmus, das erreicht werden soll.
Segmentierung
Die Bildsegmentierung ist eine Erkennungsaufgabe, die versucht, Objekte in einem Bild bis zum nächsten Pixel zu lokalisieren. Sie ist in Situationen nützlich, in denen Präzision entscheidend ist. Die Bildsegmentierung wird häufig in der medizinischen Bildgebung verwendet, um Bildpixel zu erkennen und zu kennzeichnen.
Das Verarbeiten eines gesamten Bildes ist nicht immer eine gute Idee, da es unnötige Informationen enthalten kann. Das Bild wird in Unterteile segmentiert, und die Pixeleigenschaften jedes Teils werden berechnet, um seine Beziehung zum Gesamtbild zu verstehen. Andere Faktoren werden ebenfalls berücksichtigt, wie Bildbeleuchtung, Farbe, Gradient und Gesichtsvektordarstellungen.
Wenn Sie beispielsweise versuchen, Autos auf einem Parkplatz zu erkennen und zu segmentieren, sind Werbetafeln oder Schilder möglicherweise nicht sehr nützlich. Hier wird die Unterteilung des Bildes in verschiedene Segmente entscheidend. Ähnliche Pixel in einem Bild werden zusammen segmentiert und geben Ihnen ein detailliertes Verständnis der Objekte im Bild.
Vorteile der Bilderkennung
Sowohl für Unternehmen als auch für Verbraucher hat die Bilderkennungssoftware mehrere bedeutende Vorteile.
Schützt Menschen vor Online-Kriminalität
Heutzutage sind unsere Gesichter überall im Internet, zusammen mit scheinbar endlosen persönlichen Informationen. Mit Bilderkennungstools können Bildsuchen durchgeführt werden, um die unbefugte Nutzung Ihrer Informationen für Betrug zu überprüfen.
Für visuelle Künstler ist dies auch eine gute Möglichkeit, zu erkennen, ob jemand Ihr Kunstwerk stiehlt oder missbraucht.
Verarbeitet Daten schnell
KI-Bilderkennung kann große Datensätze exponentiell schneller verarbeiten als ein Mensch. Dies befreit nicht nur Ihr Team, um andere Aufgaben zu erledigen, die geschäftskritischer sind, sondern erledigt die Arbeit auch in viel kürzerer Zeit.
Skalierbare Lösungen für jedes visuelle Projekt
KI-Systeme haben eine Vielzahl von Anwendungen, was bedeutet, dass sie für fast alles verwendet werden können. Das macht Bilderkennungssoftware zu einer der anpassungsfähigsten und flexibelsten Optionen für jedes Projekt, unabhängig von der Größe.
Beste Bilderkennungssoftware
Mit ihrer Vielzahl an Fähigkeiten hängt die richtige Bilderkennungssoftware von Ihrem spezifischen Bedarf und den gewünschten Ergebnissen ab. Die meisten Tools können eine Vielzahl von Dateneingaben verarbeiten, einschließlich der besten kostenlosen Bilderkennungssoftware. Aber für komplexere Projekte ist kostenpflichtige Software oft die beste Wahl.
Um in die Kategorie der Bilderkennungssoftware aufgenommen zu werden, müssen Plattformen:
- Einen Deep-Learning-Algorithmus speziell für die Bilderkennung bereitstellen
- Mit Bilddatensätzen verbunden sein, um eine spezifische Lösung oder Funktion zu erlernen
- Die Bilddaten als Eingabe konsumieren und eine ausgegebene Lösung bereitstellen
- Bilderkennungsfähigkeiten in andere Anwendungen, Prozesse oder Dienste integrieren
* Unten sind die fünf führenden Bilderkennungssoftwarelösungen aus dem G2 Spring 2024 Grid Report aufgeführt. Einige Bewertungen können zur Klarheit bearbeitet sein.
1. Google Cloud Vision API
Google Cloud Vision API ermöglicht es Entwicklern, die Leistungsfähigkeit von KI und maschinellem Lernen einfach zu nutzen, um Bilder mit branchenführender Vorhersagegenauigkeit zu erkennen und zu bewerten. Die Tools ermöglichen es Ihnen, Bilder direkt hochzuladen, wobei die Vision API als Objektlokalisierer fungiert, um Objekte und Labels innerhalb des Bildes selbst zu erkennen.
Was Benutzer am meisten mögen:
„Wir verwenden die API in einem Projekt, bei dem wir den Nährwert von Lebensmitteln kennen müssen, also erhalten wir den Lebensmittelnamen durch Bilderkennung und berechnen dann seine Nährstoffe gemäß den Lebensmittelinhalten. Es ist sehr einfach, es in unsere Anwendung zu integrieren, und die API-Antwortzeit ist auch sehr schnell.“
- Google Cloud Vision API Review, Badal O.
Was Benutzer nicht mögen:
„Je nach Nutzung können sich die mit der Nutzung der Google Cloud Vision API verbundenen Kosten summieren. Benutzer sollten das Preismodell sorgfältig überprüfen und die potenziellen Ausgaben für ihre spezifischen Anwendungsfälle schätzen.“
- Google Cloud Vision API Review, Piyush D.
2. Syte
Unterstützt von KI ist Syte die weltweit erste Produktentdeckungsplattform. Mit Kamerasuche, Personalisierung und intelligenten E-Commerce-Tools können Unternehmen Kunden helfen, Produkte mit einem hyper-personalisierten Erlebnis in ihrem Online-Shop zu entdecken und zu kaufen.
Was Benutzer am meisten mögen:
„Das Tool zum ähnlichen Shoppen war ein großartiges Tool, seit wir es auf unseren Websites implementiert haben. Das Syte-Tool war entscheidend für die Produkterkennung und hat Kunden geholfen, visuell ähnliche Produkte zu finden, wenn sie ihre Größe nicht finden können.“
- Syte Review, Emely C.
Was Benutzer nicht mögen:
„Die Backend-Merch-Plattform ist nicht so intuitiv wie andere Plattformen. Das „Look vervollständigen“ zeigt nicht die genauen Produkte als Teil des Looks, sondern nur ähnliche.“
- Syte Review, Cristina F.
3. Carifai
Carifai ist eine vollständige KI-Plattform für Entwickler und Teams, um an Audio- und visuellen KI-Produktionen zusammenzuarbeiten. Die benutzerdefinierten Sprachlernmodelle sind Open Source, mit häufigen Updates, und können multimodale Anwendungen über eine Vielzahl von Projekten und Branchen hinweg bedienen.
Was Benutzer am meisten mögen:
„Einfach zu navigieren und eine sehr große Auswahl an benutzererstellten Modellen, mit denen man spielen und lernen kann. Fühlt sich an wie GitHub, aber mit KI. Einfach für einen Anfänger wie mich, das zu finden, wonach ich suche. Schnelle und einfache Anmeldung und man kann sofort loslegen, ohne vorher einen lästigen Democall oder Verkaufsgespräch zu führen.“
- Clarifai Review, Tate T.
Was Benutzer nicht mögen:
„Es wäre gut, die Trainingsbibliothek noch weiter auszubauen, da die Anwendungsfälle und Modelle relativ neu sind. Es wäre gut, Anleitungen zu haben, wie man Modelle von Anfang bis Ende für verschiedene Modelltypen implementiert.“
- Clarifai Review, Sam G.
4. Gesture Recognition Toolkit
Gesture Recognition Toolkit ist eine Open-Source- und plattformübergreifende Tool-Suite, die Entwicklern die Freiheit und Flexibilität bietet, Echtzeit-Gestenerkennungssoftware zu entwerfen und zu erstellen. Weitgehend in der Spieleentwicklung und virtuellen Realität verwendet, können Benutzer des Toolkits von Grund auf neu erstellen oder mit anderen Community-Mitgliedern zusammenarbeiten, um Open-Source-Anwendungen zu nutzen, um ihre Sprachlernmodelle zu erstellen.
Was Benutzer am meisten mögen:
„Ich mag, wie es darauf ausgelegt ist, mit Echtzeit-Sensordaten zu arbeiten und gleichzeitig die traditionelle Offline-Maschinenlernaufgabe zu erfüllen. Ich mag, dass es eine doppelte Präzisions-Float hat und leicht in eine einfache Präzision geändert werden kann, was es zu einem sehr flexiblen Tool macht.“
- Gesture Review, Diana Grace Q.
Was Benutzer nicht mögen:
"Es hat gelegentlich Verzögerungen und einen weniger reibungslosen Implementierungsprozess. Die Reaktionszeit des Kundensupports könnte schneller sein.
- Gesture Review, Civic V.
5. SuperAnnotate
SuperAnnotate ist eine führende Plattform zum Erstellen, Trainieren, Testen und Bereitstellen von KI-Modellen mit hochwertigen Trainingsdaten. Fortschrittliche Annotations- und Bilderkennungstools ermöglichen es Benutzern, erfolgreiche maschinelle Lernpipelines zu erstellen und Automatisierungsarbeitslasten zu verwalten.
Was Benutzer am meisten mögen:
„SuperAnnotate hat eine intuitive Benutzeroberfläche. Es war einfach, sich mit den verschiedenen Funktionen und Tools, die die Plattform bietet, vertraut zu machen. Es ist einfach, sich in den Tausenden von Bildern in unserem Datensatz zurechtzufinden - sowohl im Annotationsmodus als auch außerhalb. Dies war in Situationen sehr nützlich, in denen ich bestimmte Bilder finden musste, um einige Änderungen am Datensatz vorzunehmen. Darüber hinaus ist die Label-Übersichtsfunktion nützlich, um Inkonsistenzen in unseren Anmerkungen zu erkennen und zu korrigieren.“
- SuperAnnotate Review, Camilla M.
Was Benutzer nicht mögen:
„Die Plattform kann mehr Filteroptionen für Managerkonten und zusätzliche Funktionen für Annotatoren bereitstellen, um versehentlich gesendete Aufgaben zu beheben.“
- SuperAnnotate Review, Hoang D.

Es ist fast nicht erkennbar...aber nicht ganz!
Visuelle Bilder und Videos spielen eine entscheidende Rolle in unserem Leben, sowohl persönlich als auch am Arbeitsplatz. Die Technologie, die uns zur Verfügung steht, die diese visuellen Inhalte fast auf die gleiche Weise wie ein menschliches Gehirn erkennen und bewerten kann, ist ein bedeutender Schritt in der künstlichen Intelligenz, mit endlosen Möglichkeiten, wie diese Tools unser tägliches Leben bereichern können.
Erfahren Sie mehr über KI-Anwendungen, damit Sie mehr Aufgaben und alltägliche Funktionen in Ihrem Unternehmen automatisieren können.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

