



Mit dem Aufkommen der Automatisierung entwickeln sich Datenvolumen, -größe und -geschwindigkeit ständig weiter. Die größere Herausforderung, der sich Datenteams jetzt gegenübersehen, besteht darin, diese enorme Datenmenge zu verwalten. Steigende Datenmengen erfordern die Notwendigkeit, sie zu speichern. Der Prozess der Datenlagerung besteht aus drei grundlegenden Schritten: Extrahieren, Transformieren und Laden, die in der Regel mit ETL-Tools durchgeführt werden.
ETL-Tools haben zahlreiche geschäftliche Anwendungen. Traditionell waren Daten statischer und die Systemarchitektur monolithisch. ETL wurde in Chargen durchgeführt, und es dauerte einen halben bis einen ganzen Tag, bis der Prozess abgeschlossen war. Einer der ersten Anwendungsfälle von ETL war die Erstellung analytischer Berichte. Kürzlich entdeckten Datenanalysten, dass Daten operativ sind, wie z. B. Daten, die aus täglichen Transaktionen gewonnen werden.
ETL vs. ELT vs. Reverse ETL
Die aktuelle Datenlagerarchitektur führt den ETL-Prozess in drei einfachen Schritten durch. Die in verschiedenen Formen wie Flachdateien, Datenbanken und Webdiensten vorliegenden Daten werden aus mehreren Quellen extrahiert und dann zur Transformation oder Verarbeitung weitergeleitet. In diesem Schritt werden die Daten bereinigt und verarbeitet, bevor sie in das Lager geladen werden. Der ETL-Prozess endet in einem Data Mart, der sich oben im Datenlager befindet.
Was ist ein Data Mart?
Ein Data Mart ist ein hochstrukturiertes Datenrepository, in dem Daten gespeichert und verwaltet werden, bis sie benötigt werden. Es speichert themenorientierte Datenbanken für spezifische Geschäftsbereiche wie Marketing, Finanzen, Betrieb usw.
|
Tipp: Datenlager unterscheiden sich in dieser Hinsicht von Data Marts. Lager fungieren als zentrales Repository und leiten Daten an die Data Marts weiter, wenn sie benötigt werden. |
ELT hingegen umfasst die gleichen Prozesse, jedoch in einer anderen Reihenfolge. Die Daten werden aus verschiedenen Quellen extrahiert und dann in das Lager geladen. Die Daten werden dann entsprechend den verschiedenen geschäftlichen Anwendungen verarbeitet, bevor sie verwendet werden.
Reverse ETL ist eine genaue Umkehrung des ETL-Prozesses. Der Bedarf an konsistenter Kundendatensichtbarkeit über alle Systeme hinweg führte zum Aufkommen von Reverse ETL. Dieses Tool wird verwendet, um Daten in Echtzeit an verschiedene SaaS-Systeme zu senden. Zum Beispiel das Senden von Daten aus dem Lager zu Salesforce, um die Liste aller hochkarätigen Kunden zu verfolgen.

Quelle: Deloitte
ETL/ELT und Reverse ETL sind zwei Seiten derselben Medaille – eines wird für die Datenintegration verwendet, das andere für Datenoperationen.
ELT gewinnt an Popularität
Traditionell war der Ansatz für Datenbanken immer Schema-on-Write – die Datenpunkte mussten vor der Speicherung ein Template erhalten. Wenn Benutzer Daten abrufen wollten, waren sie bereits in einem handhabbaren Format. Diese Praxis diente der Konsistenz. Mit der Zeit und der Datenmenge erwies sich dies jedoch als einschränkend. Selbst leicht unstrukturierte Daten wurden abgelehnt, weil sie nicht mit dem Template übereinstimmten. ETL-Tools folgten dem Schema-on-Write. IT-Experten erkannten, dass rohe oder weniger strukturierte Daten ebenfalls wertvoll für die Organisation waren. Um Wert daraus zu ziehen, war es notwendig, den Ansatz für Datenbanken zu ändern. So entstand das Schema-on-Read.

Schema-on-Read ermöglicht es, sowohl unstrukturierte als auch strukturierte Daten im System zu speichern und bei Bedarf zu formatieren. ELT-Tools folgen diesem Ansatz, um Daten nützlich zu machen und sind flexibler in der Anwendung. Anfangs wurden Daten auf lokalen Servern gespeichert; daher war die Datenspeicherung viel teurer als heute. Viele ELT- und ETL-Tools arbeiten heute Hand in Hand mit Cloud-Datenlagern, die sich mit den Datenvolumen automatisch skalieren. Mit dem Aufkommen von Cloud-Datenlagern ist die Datenspeicherung zu niedrigen Kosten möglich. ETL- und ELT-Tools sind Mittel zur Datenintegration mit unterschiedlichen Ansätzen.
Wird Reverse ETL ETL/ELT ersetzen?
Da wir nun genau wissen, was ETL- und ELT-Tools tun, ist es an der Zeit, tiefer in Reverse ETL einzutauchen. Einige Leute könnten fragen, wenn es bereits zwei Ansätze zur Speicherung von Daten im Lager gibt, warum dann umkehren? Soll es ETL und ELT ersetzen?
Die kurze Antwort ist nein. Unternehmen haben Unmengen von Daten, die im Lager liegen und ungenutzt bleiben. Sie müssen sichtbar gemacht werden, um zu wissen, welchen Wert sie bieten und weiter aktiviert werden können. Während Datenwissenschaftler Customer Data Platforms (CDPs) entwickelt haben, die alle Kundendaten unter einem Dach integrieren, kann dies nur eine Teillösung zur Aufdeckung der verborgenen Daten sein. Hier benötigen Unternehmen Reverse ETL.
Während ETL- und ELT-Tools den Geschäftsbereichen saubere und verarbeitete Daten liefern, ist es wichtig zu verstehen, ob sie diese Daten tatsächlich nutzen können, um Entscheidungen zu treffen. Zum Beispiel können Marketingteams Daten in Hubspot für Kampagnen speichern, Reverse ETL hilft diesen Teams jedoch, auf kampagnenbezogene Daten zuzugreifen, um das Targeting spezifischer zu gestalten. Ebenso hilft eine Kundendatenbank in Salesforce den Vertriebsteams, sie mit spezifischen Nachrichten anzusprechen. Viele Reverse ETL-Tools verschieben Daten von Datenlagern zu verschiedenen CRMs, damit verschiedene Geschäftsbereiche auf diese Daten zugreifen und Entscheidungen treffen können. Reverse ETL macht die Daten operativer und bereichert sie, um sie für die Kunden relevant zu machen.
Reverse ETL-Tools helfen, Silos zu durchbrechen und verschiedenen Teams die Sichtbarkeit der benötigten Daten zu geben, um die Datenaktivierung zu erfüllen. Operative Analytik ist ein aufkommender Ansatz zur Nutzung von Daten; genau das tut Reverse ETL. Unternehmen müssen die Daten aus zentralisierten Silos herausholen und in verschiedene Geschäftsbereiche einbringen.
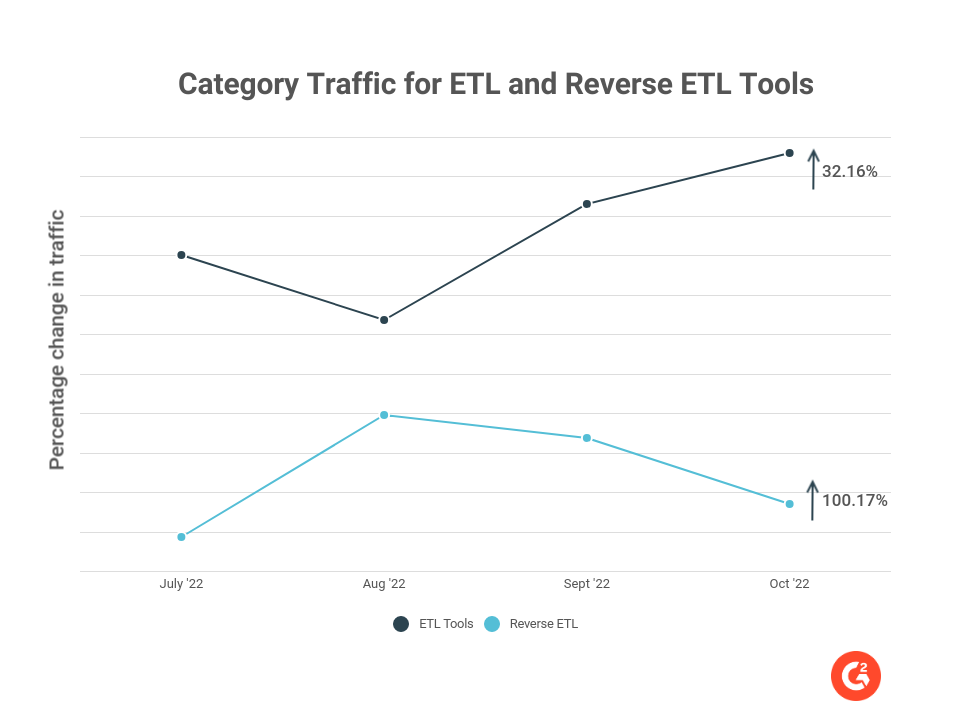
Die neu geschaffene Reverse ETL-Kategorie auf G2 hat seit ihrer Erstellung an Verkehr zugenommen. Käufer haben Interesse an sowohl ETL- als auch Reverse ETL-Tools gezeigt, was aus dem Verkehr auf G2 ersichtlich ist. Der Verkehr zur Reverse ETL-Kategorie auf G2 ist seit ihrer Einführung um mehr als 100 % gewachsen. Der Verkehr zur ETL-Tools-Kategorie-Seite auf G2 wächst stetig – 32 % seit Juli 2022. Es ist klar, dass Unternehmen daran interessiert sind, die Kombination der Tools auszuprobieren, was wir als zukünftigen Trend im ETL-Bereich sehen.
Die Zukunft der ETL-Tools
Der ETL-Prozess wird seit den alten Datenlagerungsmethoden verwendet und hat sich im Laufe der Zeit verändert. ELT ist der moderne Ansatz zur Speicherung von Daten mit skalierbaren Ressourcen, während Reverse ETL externe Systeme mit bereinigten Daten unter Verwendung von ETL/ELT anreichert.
Eine Kombination aus ETL/ELT und Reverse ETL kann Organisationen helfen, bessere Einblicke aus den gewonnenen Daten zu gewinnen. Betriebszentrierte Teams können auf diese bereinigten Daten zugreifen, um neue Verkaufs- und Marketingkampagnen durchzuführen und die Daten in die Anwendungen zu kopieren.
Bearbeitet von Jigmee Bhutia
Möchten Sie mehr über ETL-Werkzeuge erfahren? Erkunden Sie ETL-Werkzeuge Produkte.

Shalaka Joshi
Shalaka is a Senior Research Analyst at G2, with a focus on data and design. Prior to joining G2, she has worked as a merchandiser in the apparel industry and also had a stint as a content writer. She loves reading and writing in her leisure.

