



Angenommen, Sie leiten einen großen Online-Buchladen. Er ist immer geöffnet. Jede Minute oder Sekunde tätigen Kunden Bestellungen und bezahlen diese. Ihre Website muss zahlreiche Transaktionen schnell ausführen, indem sie bescheidene Daten wie Benutzer-IDs, Kreditkartennummern und Bestellinformationen verwendet.
Zusätzlich zur Durchführung der täglichen Aufgaben müssen Sie auch Ihre Leistung bewerten. Beispielsweise analysieren Sie die Verkäufe eines bestimmten Buches oder Autors aus dem Vormonat, um zu entscheiden, ob Sie für diesen Monat mehr bestellen sollten. Dies erfordert das Sammeln von Transaktionsdaten und deren Übertragung von einer Datenbank, die Transaktionen unterstützt, in ein anderes System, das große Datenmengen verwaltet. Und wie üblich müssen Daten transformiert werden, bevor sie in ein anderes Speichersystem geladen werden.
Erst nach diesen Maßnahmen können Sie Daten mit spezieller Software untersuchen. Wie bewegen Sie jedoch Daten? Wenn Sie die Antwort nicht kennen, benötigen Sie wahrscheinlich eine bessere Software-Infrastruktur, wie Daten-Austauschlösungen, ETL-Tools (Extract, Transform, Load) oder DataOps-Lösungen.
Sie müssen wahrscheinlich lernen, was eine Datenpipeline für Sie und Ihr Unternehmen tun kann. Sie müssen wahrscheinlich weiterlesen.
Was ist eine Datenpipeline?
Eine Datenpipeline ist ein Prozess, der das Einlesen von Rohdaten aus zahlreichen Datenquellen und deren Übertragung in ein Datenrepository, wie einen Data Lake oder ein Data Warehouse, zur Analyse umfasst.
Eine Datenpipeline ist eine Reihe von Schritten zur Datenverarbeitung. Wenn die Daten noch nicht in die Datenplattform importiert wurden, werden sie zu Beginn der Pipeline eingelesen. Es folgt eine Abfolge von Stufen, wobei jede ein Ergebnis liefert, das als Eingabe für den nächsten Schritt dient. Dies setzt sich fort, bis die gesamte Pipeline aufgebaut ist. Unabhängige Schritte können in einigen Fällen gleichzeitig ablaufen.
Komponenten einer Datenpipeline
Bevor wir in die Funktionsweise von Datenpipelines eintauchen, ist es wichtig, ihre Komponenten zu verstehen.
- Der Ursprung ist der Einstiegspunkt für Daten aus allen Datenquellen in der Pipeline. Die meisten Pipelines stammen aus transaktionalen Verarbeitungssystemen, Anwendungsprogrammierschnittstellen (APIs) oder IoT-Gerätesensoren oder Speichersystemen wie Data Warehouses oder Data Lakes.
- Das Ziel ist der letzte Ort, an den die Daten gelangen. Der Anwendungsfall bestimmt das endgültige Ziel.
- Datenfluss ist der Transport von Daten von der Quelle zum Ziel und die daran vorgenommenen Änderungen. ETL ist eine der am häufigsten genutzten Datenflussmethoden.
- Speicherung bezieht sich auf Systeme, die Daten in verschiedenen Stadien speichern, während sie durch die Pipeline fließen.
- Verarbeitung umfasst alle Aktivitäten und Stufen, die mit dem Konsumieren, Speichern, Ändern und Platzieren von Daten verbunden sind. Während die Datenverarbeitung mit dem Datenfluss zusammenhängt, konzentriert sich diese Stufe auf die Implementierung.
- Workflow spezifiziert eine Reihe von Prozessen und deren Abhängigkeiten voneinander.
- Überwachung stellt sicher, dass die Pipeline und ihre Stufen korrekt funktionieren und die erforderlichen Funktionen ausführen.
- Technologie bezieht sich auf die Infrastruktur und die Werkzeuge, die Datenübertragung, Verarbeitung, Speicherung, Workflow und Überwachung unterstützen.
Möchten Sie mehr über ETL-Werkzeuge erfahren? Erkunden Sie ETL-Werkzeuge Produkte.
Wie funktioniert Daten-Pipelining?
Daten werden typischerweise verarbeitet, bevor sie in ein Repository fließen. Dies beginnt mit der Datenvorbereitung, bei der die Daten bereinigt und angereichert werden, gefolgt von der Datentransformation zum Filtern, Maskieren und Aggregieren von Daten für ihre Integration und Einheitlichkeit. Dies ist besonders wichtig, wenn das endgültige Ziel des Datensatzes eine relationale Datenbank ist. Relationale Datenbanken haben ein vordefiniertes Schema, das angepasst werden muss, um Datenkolonnen und -typen abzugleichen, um die alten Daten mit den neuen zu aktualisieren.
Stellen Sie sich vor, Sie sammeln Informationen darüber, wie Menschen mit Ihrer Marke interagieren. Dies könnte ihren Standort, ihr Gerät, Sitzungsaufzeichnungen, Käufe und die Interaktionshistorie mit dem Kundenservice umfassen. Dann geben Sie all diese Informationen in ein Warehouse ein, um ein Profil für jeden Verbraucher zu erstellen.
Wie der Name schon sagt, dienen Datenpipelines als "Rohr" für Data-Science-Projekte oder Business-Intelligence-Dashboards. Daten stammen aus verschiedenen Quellen, einschließlich APIs, Structured Query Language (SQL) oder NoSQL-Datenbanken; sie sind jedoch nicht immer sofort nutzbar.
In der Regel führen Datenwissenschaftler oder -ingenieure Aufgaben zur Datenvorbereitung durch. Sie formatieren die Daten, um die Anforderungen des geschäftlichen Anwendungsfalls zu erfüllen. Eine Kombination aus explorativer Datenanalyse und etablierten Geschäftsanforderungen entscheidet oft über die Art der Datenverarbeitung, die eine Pipeline benötigt. Daten können gespeichert und angezeigt werden, wenn sie korrekt gefiltert, kombiniert und zusammengefasst werden.
Gut organisierte Datenpipelines sind die Grundlage für verschiedene Initiativen, einschließlich explorativer Datenanalyse, Visualisierung und Machine-Learning (ML)-Aktivitäten.
Arten von Datenpipelines
Batch-Verarbeitung und Streaming-Echtzeit-Datenpipelines sind die beiden grundlegenden Arten von Datenpipelines.
Batch-Verarbeitung von Daten
Wie der Name schon sagt, lädt die Batch-Verarbeitung "Batches" von Daten in ein Repository zu festgelegten Intervallen, oft während der Geschäftszeiten mit geringer Auslastung. Andere Arbeitslasten werden nicht gestört, da Batch-Verarbeitungsjobs typischerweise mit enormen Datenmengen arbeiten, die das gesamte System belasten könnten. Wenn es keinen dringenden Bedarf gibt, einen bestimmten Datensatz zu untersuchen (z. B. monatliche Buchhaltung), ist die Batch-Verarbeitung die beste Datenpipeline. Sie ist mit dem ETL-Datenintegrationsprozess verbunden.
ETL hat drei Stufen:
- Extrahieren: Rohdaten aus einer Quelle erhalten, wie einer Datenbank, einer XML-Datei oder einer Cloud-Plattform, die Daten für Marketing-Tools, CRM-Systeme oder Transaktionssysteme enthält.
- Transformieren: Das Format oder die Struktur des Datensatzes ändern, um das Zielsystem anzupassen.
- Laden: Den Datensatz in das Zielsystem übertragen, das eine Anwendung oder eine Datenbank, ein Data Lakehouse, ein Data Lake oder ein Data Warehouse sein könnte.
Streaming-Echtzeitdaten
Im Gegensatz zur Batch-Verarbeitung bedeutet Streaming-Echtzeitdaten, dass Daten kontinuierlich aktualisiert werden müssen. Apps und Point-of-Sale (PoS)-Systeme benötigen beispielsweise Echtzeitdaten, um den Bestand und die Verkaufshistorie ihrer Artikel zu aktualisieren; dies ermöglicht es Händlern, Verbraucher darüber zu informieren, ob ein Produkt auf Lager ist. Eine einzelne Aktion, wie ein Produktverkauf, wird als "Ereignis" bezeichnet, und verwandte Vorkommnisse, wie das Hinzufügen eines Artikels zum Warenkorb, werden normalerweise als "Thema" oder "Stream" gruppiert. Diese Ereignisse werden anschließend über Nachrichtensysteme oder Nachrichtenbroker wie Apache Kafka, ein Open-Source-Produkt, geleitet.
Streaming-Datenpipelines bieten eine geringere Latenz als Batch-Systeme, da Datenereignisse sofort nach ihrem Auftreten verarbeitet werden. Dennoch sind sie weniger zuverlässig als Batch-Systeme, da Nachrichten versehentlich übersehen werden oder lange in der Warteschlange bleiben könnten. Nachrichtenbroker helfen, dieses Problem mit Bestätigungen zu lösen, was bedeutet, dass ein Verbraucher die Verarbeitung der Nachricht an den Broker bestätigt, damit sie aus der Warteschlange entfernt werden kann.
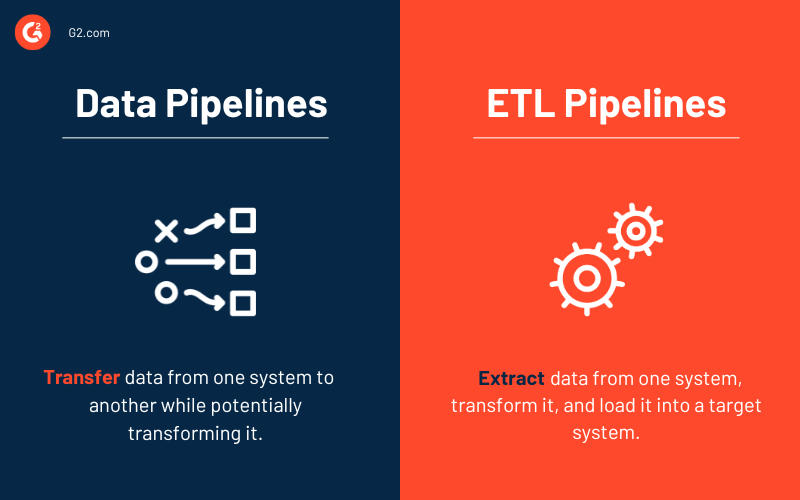
Datenpipelines vs. ETL-Pipelines
Einige Begriffe, wie Datenpipeline und ETL-Pipeline, können austauschbar verwendet werden. Betrachten Sie jedoch eine ETL-Pipeline als einen Untertyp der Datenpipeline. Drei grundlegende Merkmale unterscheiden die beiden Arten von Pipelines.
- ETL-Pipelines folgen einer vorgegebenen Reihenfolge. Wie das Akronym andeutet, extrahieren, konvertieren, laden und speichern sie Daten in einem Repository. Diese Reihenfolge ist nicht für alle Datenpipelines erforderlich. Tatsächlich hat das Aufkommen von cloud-nativen Lösungen die Nutzung von ETL-Pipelines erhöht. Die Datenaufnahme erfolgt bei diesem Pipeline-Typ immer noch zuerst, aber alle Transformationen erfolgen, nachdem die Daten in das Cloud-Datenwarehouse geladen wurden.
- Obwohl der Umfang von Datenpipelines größer ist, beinhalten ETL-Pipelines häufig Batch-Verarbeitung. Sie könnten auch Stream-Verarbeitung umfassen.
- Schließlich benötigen Datenpipelines im Allgemeinen nicht immer Datenumwandlungen, im Gegensatz zu ETL-Pipelines. Fast jede Datenpipeline verwendet Transformationen, um die Analyse zu erleichtern.
Datenpipeline-Architektur
Das Design einer Datenpipeline umfasst drei Hauptphasen.
- Datenaufnahme. Daten werden aus vielen Quellen erfasst, einschließlich strukturierter und unstrukturierter Daten. Diese Rohdatenquellen werden im Kontext von Streaming-Daten häufig als Produzenten, Publisher oder Sender bezeichnet. Während Organisationen möglicherweise entscheiden, Daten nur dann zu extrahieren, wenn sie bereit sind, sie zu analysieren, ist es besser, die Rohdaten zuerst bei einem Cloud-Datenwarehouse-Anbieter zu speichern. Dies ermöglicht es dem Unternehmen, vergangene Daten zu ändern, falls sie die Datenverarbeitungsoperationen ändern müssen.
- Datentransformation. Während dieser Phase werden eine Reihe von Aufgaben durchgeführt, um Daten in das vom Ziel-Datenrepository benötigte Format zu konvertieren. Diese Aufgaben beinhalten Automatisierung und Governance für wiederkehrende Arbeitsabläufe, wie Geschäftsberichte, um sicherzustellen, dass Daten ständig bereinigt und konvertiert werden. Ein Datenstrom kann beispielsweise im geschichteten JavaScript Object Notation (JSON)-Format vorliegen, und der Datentransformationsschritt wird versuchen, dieses JSON zu entrollen, um die wesentlichen Felder für die Analyse zu extrahieren.
- Datenrepository. Die transformierten Daten werden anschließend in einem Repository gespeichert und mehreren Stakeholdern zur Verfügung gestellt. Die veränderten Daten werden manchmal als Verbraucher, Abonnenten oder Empfänger bezeichnet.
Vorteile von Datenpipelines
Unternehmen neigen dazu, über Datenpipelines zu lernen und wie sie Unternehmen helfen, Zeit zu sparen und ihre Daten strukturiert zu halten, wenn sie wachsen oder nach besseren Lösungen suchen. Die folgenden sind einige Vorteile von Datenpipelines, die Unternehmen ansprechend finden könnten.
- Datenqualität bezieht sich darauf, wie einfach es für Endbenutzer ist, relevante Daten zu überwachen und darauf zuzugreifen, während sie sich von der Quelle zum Ziel bewegen.
- Pipelines ermöglichen es Benutzern, Datenflüsse iterativ zu erzeugen. Sie können einen kleinen Ausschnitt von Daten aus der Datenquelle erfassen und dem Benutzer präsentieren.
- Musterreplizierbarkeit kann wiederverwendet und für neue Datenflüsse umfunktioniert werden. Sie sind ein Netzwerk von Pipelines, das eine Denkweise erzeugt, in der einzelne Pipelines als Beispiele für Muster in einem größeren Design betrachtet werden.
Herausforderungen bei Datenpipelines
Der Aufbau einer gut konzipierten und leistungsstarken Datenpipeline erfordert die Planung und Gestaltung mehrerer Aspekte der Datenspeicherung, wie Datenstruktur, Schema-Design, Schema-Änderungsbehandlung, Speicheroptimierung und schnelle Skalierung, um unerwarteten Anstiegen im Anwendungsdatenvolumen gerecht zu werden. Dies erfordert oft die Verwendung einer ETL-Technik, um die Datentransformation in vielen Phasen zu organisieren. Sie müssen auch sicherstellen, dass die aufgenommenen Daten auf Datenqualität oder -verlust überprüft werden und dass Jobfehler und Ausnahmen überwacht werden.
Nachfolgend sind einige der häufigsten Probleme aufgeführt, die bei der Arbeit mit Datenpipelines auftreten.
- Zunahme des Verarbeitungsdatenvolumens
- Änderungen in der Struktur der Quelldaten
- Schlechte Datenqualität
- Unzureichende Datenintegrität in den Quelldaten
- Datenverdopplung
- Verzögerung von Quelldateien
- Fehlende Entwickleroberfläche zum Testen
Anwendungsfälle von Datenpipelines
Datenmanagement wird zu einem zunehmend wichtigen Anliegen, da umfangreiche Daten zunehmen. Während Datenpipelines verschiedenen Zwecken dienen, sind die folgenden drei primären kommerziellen Anwendungen.
- Explorative Datenanalyse (EDA) bewertet und untersucht Datensätze und berichtet über ihre primären Eigenschaften, typischerweise unter Verwendung von Datenvisualisierungstechniken. Es hilft zu bestimmen, wie Datenquellen modifiziert werden müssen, um die erforderlichen Antworten zu erhalten, was es Datenwissenschaftlern erleichtert, Muster zu entdecken, Anomalien zu erkennen, Hypothesen zu testen und Annahmen zu validieren.
- Datenvisualisierungen verwenden beliebte Visualisierungen, um Daten zu beschreiben: Diagramme, Grafiken, Infografiken und Animationen. Diese Informationsvisualisierungen erklären komplexe Datenbeziehungen und datengesteuerte Erkenntnisse auf eine leicht verständliche Weise.
- Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz (KI) und der Informatik, der Daten und Algorithmen verwendet, um zu imitieren, wie Menschen lernen, und dabei allmählich die Genauigkeit zu verbessern. Algorithmen werden gelehrt, Klassifikationen oder Vorhersagen mit statistischen Methoden zu erzeugen, wodurch wichtige Erkenntnisse in Data-Mining-Initiativen aufgedeckt werden.
Reale Beispiele für Datenpipelines
Nachfolgend sind einige IRL-Datenpipeline-Beispiele von Unternehmen aufgeführt, die moderne für ihre Anwendung erstellt haben.
- Uber benötigt Echtzeitdaten, um dynamische Preisgestaltung zu implementieren, die wahrscheinlichste Ankunftszeit zu berechnen und Nachfrage und Angebot vorherzusagen. Sie setzen Streaming-Pipelines ein, die aktuelle Daten von Fahrer- und Passagier-Apps mit Technologien wie Apache Flink einlesen. Diese Echtzeitdaten werden in maschinelle Lernalgorithmen integriert, die minutengenaue Vorhersagen liefern.
- Hewlett Packard Enterprise wollte das Kundenerlebnis mit seiner vorausschauenden Wartungsfunktion verbessern. Sie bauten eine effiziente Datenpipeline mit Streaming-Engines wie Akka Streams, Apache Spark und Apache Kafka.
- Dollar Shave Club benötigte Echtzeitdaten, um mit jedem Verbraucher separat zu interagieren. Nachdem Informationen in ihr Empfehlungssystem eingespeist wurden, wählte das Programm aus, welche Produkte für die Aufnahme in eine monatliche E-Mail an einzelne Kunden beworben werden sollten. Sie erstellten eine automatisierte Datenpipeline mit Apache Spark für diese Praxis.
Best Practices für Datenpipelines
Sie können die erheblichen Gefahren schlecht konstruierter Datenpipelines vermeiden, indem Sie die unten aufgeführten empfohlenen Praktiken befolgen.
- Einfache Fehlerbehebung: Durch das Entfernen unnötiger Abhängigkeiten zwischen den Komponenten der Datenpipeline müssen Sie nur bis zur Fehlerstelle zurückverfolgen. Die Vereinfachung verbessert die Vorhersehbarkeit der Datenpipeline.
- Skalierbarkeit: Da Arbeitslasten und Datenvolumen exponentiell wachsen, sollte ein ideales Datenpipeline-Design in der Lage sein, zu skalieren und zu expandieren.
- End-to-End-Sichtbarkeit: Sie können Konsistenz und proaktive Sicherheit mit kontinuierlicher Überwachung und Qualitätsinspektionen sicherstellen.
- Testen: Nachdem Sie basierend auf den Qualitätstests Anpassungen vorgenommen haben, haben Sie jetzt einen zuverlässigen Datensatz, den Sie durch die Pipeline laufen lassen können. Nachdem Sie einen Testsatz definiert haben, können Sie ihn in einer separaten Testumgebung ausführen; dann vergleichen Sie ihn mit der Produktionsversion Ihrer Datenpipeline und der neuen Version.
- Wartbarkeit: Wiederholbare Verfahren und strikte Protokolleinhaltung unterstützen eine langfristige Datenpipeline.
Datenpipeline-Tools
Datenpipeline-Tools unterstützen den Datenfluss, die Speicherung, Verarbeitung, den Workflow und die Überwachung. Viele Faktoren beeinflussen die Auswahl, einschließlich Unternehmensgröße und Branche, Datenmengen, Datenanwendungsfälle, Budget und Sicherheitsanforderungen.
Die folgenden sind häufig verwendete Lösungsgruppen zum Aufbau von Datenpipelines.
ETL-Tools
ETL-Tools umfassen Datenvorbereitungs- und Datenintegrationslösungen. Sie werden hauptsächlich verwendet, um Daten zwischen Datenbanken zu verschieben. Sie replizieren auch Daten, die dann in Datenbankverwaltungssystemen und Data Warehouses gespeichert werden.
Top 5 ETL-Tools:
* Oben sind die fünf führenden ETL-Lösungen aus dem G2 Summer 2023 Grid® Report aufgeführt.
DataOps-Plattformen
DataOps-Plattformen orchestrieren Menschen, Prozesse und Technologie, um ihren Benutzern eine vertrauenswürdige Datenpipeline bereitzustellen. Diese Systeme integrieren alle Aspekte der Erstellung und des Betriebs von Datenprozessen.
Top 5 DataOps-Plattformen:
* Oben sind die fünf führenden DataOps-Lösungen aus dem G2 Summer 2023 Grid® Report aufgeführt.
Daten-Austauschlösungen
Unternehmen verwenden Daten-Austauschtools während des Erwerbs, um Daten zu senden, zu erwerben oder anzureichern, ohne ihren primären Zweck zu ändern. Daten werden so übertragen, dass sie von einem empfangenden System einfach aufgenommen werden können, oft indem sie vollständig normalisiert werden.
41,8%
der kleinen Unternehmen in der IT-Branche verwenden Daten-Austauschlösungen.
Quelle: G2-Kundenbewertungsdaten
Verschiedene Datenlösungen können mit Datenaustauschen arbeiten, einschließlich Datenmanagement-Plattformen (DMPs), Daten-Mapping-Software beim Verschieben erworbener Daten in den Speicher und Datenvisualisierungssoftware zum Konvertieren von Daten in lesbare Dashboards und Grafiken.
Top 5 Daten-Austauschsoftware-Tools:
* Oben sind die fünf führenden Daten-Austauschlösungen aus dem G2 Summer 2023 Grid® Report aufgeführt.
Andere Lösungsgruppen für Datenpipelines umfassen die folgenden.
- Data Warehouses sind zentrale Repositories zur Speicherung von Daten, die für einen bestimmten Zweck konvertiert wurden. Alle wichtigen Data Warehouse-Lösungen streamen jetzt das Laden von Daten und ermöglichen ETL- und Emergency Locator Transmitter (ELT)-Operationen.
- Benutzer speichern Rohdaten in Data Lakes , bis sie sie für die Datenanalyse benötigen. Unternehmen entwickeln ELT-basierte Big-Data-Pipelines für maschinelle Lerninitiativen unter Verwendung von Data Lakes.
- Unternehmen können Batch-Workflow-Planer verwenden, um Workflows programmatisch als Aufgaben mit Abhängigkeiten zu deklarieren und diese Operationen zu automatisieren.
- Echtzeit-Datenstreaming-Software verarbeitet kontinuierlich von Quellen wie mechanischen Sensoren, IoT- und Internet of Medical Things (IoMT)-Geräten oder Transaktionssystemen erzeugte Daten.
- Big-Data-Tools umfassen Datenstreaming-Lösungen und andere Technologien, die einen End-to-End-Datenfluss ermöglichen.

Detaillierte Daten datieren tief
Früher wurden Datenmengen aus verschiedenen Quellen in separaten Silos gespeichert, die nicht auf dem Weg zugegriffen, verstanden oder analysiert werden konnten. Um die Sache noch schlimmer zu machen, waren die Daten weit entfernt von Echtzeit.
Aber heute? Da die Anzahl der Datenquellen wächst, ist die Geschwindigkeit, mit der Informationen Organisationen und ganze Sektoren durchqueren, schneller als je zuvor. Datenpipelines sind das Rückgrat digitaler Systeme. Sie übertragen, transformieren und speichern Daten und geben Unternehmen wie Ihrem bedeutungsvolle Einblicke. Datenpipelines müssen jedoch aktualisiert werden, um mit der zunehmenden Komplexität und Anzahl der Datensätze Schritt zu halten.
Die Modernisierung erfordert Zeit und Mühe, aber effiziente und moderne Datenpipelines werden Sie und Ihre Teams befähigen, bessere und schnellere Entscheidungen zu treffen, was Ihnen einen Wettbewerbsvorteil verschafft.
Möchten Sie mehr über Datenmanagement erfahren? Erfahren Sie, wie Sie Drittanbieterdaten kaufen und verkaufen können!

Samudyata Bhat
Samudyata Bhat is a Content Marketing Specialist at G2. With a Master's degree in digital marketing, she currently specializes her content around SaaS, hybrid cloud, network management, and IT infrastructure. She aspires to connect with present-day trends through data-driven analysis and experimentation and create effective and meaningful content. In her spare time, she can be found exploring unique cafes and trying different types of coffee.

