



Usei o Grammarly para me ajudar a escrever este texto. O Grammarly usou processamento de linguagem natural para me ajudar a fazer este artigo parecer ótimo.
É assim que os casos de uso de processamento de linguagem natural se tornaram prevalentes. As tecnologias de PLN percorreram um longo caminho, desde escrever um artigo e transcrever chamadas de vendas até recuperar grandes quantidades de informações relevantes e realmente entender o que o usuário quer dizer.
A evolução da linguística computacional tornou fácil para as máquinas entenderem as línguas humanas, reduzindo as lacunas entre as interações humano-computador. O software de processamento de linguagem natural melhora a experiência do cliente, automatiza entradas de dados, melhora as recomendações de busca e fortalece os esforços de segurança em diversos setores.
O que é processamento de linguagem natural?
O processamento de linguagem natural (PLN) é uma tecnologia de inteligência artificial (IA) que permite que programas de computador interpretem texto e palavras faladas para entender melhor a linguagem humana.
O PLN usa algoritmos de aprendizado de máquina (ML), modelagem baseada em regras e modelos de aprendizado profundo para ajudar os computadores a processar dados de linguagem para analisar a intenção e o sentimento das mensagens.
Se você já usou navegação GPS para se orientar em uma nova cidade ou gritou do outro lado da sala para um assistente de voz acender as luzes – parabéns, você encontrou um programa de PLN!
Graças ao processamento de linguagem natural, aplicativos de computador podem responder a comandos falados e resumir grandes quantidades de texto em tempo real para interagir com humanos de maneira significativa e expressiva.
Como o PLN funciona?
O PLN está ao nosso redor, mesmo que não o percebamos necessariamente. Assistentes virtuais, chatbots de atendimento ao cliente, modelos transformadores, texto preditivo – todos são possíveis com a tecnologia de PLN que entende e filtra nossos pedidos. Os programas fazem a ponte entre computadores e humanos para organizar operações comerciais, revitalizando a produtividade por meio de interações bem ajustadas.
As técnicas de treinamento de PLN dependem de aprendizado profundo e algoritmos para interpretar e dar sentido à linguagem humana.
Modelos de aprendizado profundo processam dados não estruturados ou dados qualitativos que não podem ser analisados usando ferramentas convencionais, como voz e texto. Eles os transformam em dados estruturados que podem ser inseridos em bancos de dados que conhecemos para fornecer insights utilizáveis.
O processamento de linguagem natural extrai informações contextuais ao decompor a linguagem em palavras individuais e identificar suas relações. Fazer isso permite um processo de indexação e segmentação mais preciso – baseado em sentimento e intenção.
Antes que um modelo possa processar qualquer dado de texto, ele precisa pré-processá-lo em um formato que a máquina possa compreender. Existem várias técnicas de processamento de dados disponíveis.
Tokenização
A tokenização, o primeiro passo para converter dados brutos em um formato que a máquina possa entender, é dividir o texto em unidades menores conhecidas como tokens. A máquina entende facilmente o texto uma vez que ele é decomposto em palavras ou frases. Como as máquinas só entendem dados numéricos, o texto tokenizado é representado como tokens numéricos para os programas.
Exemplo:
Considere o seguinte texto inserido por um usuário:
"Há um banco do outro lado da ponte."
Texto entendido pela máquina após a tokenização:
["Há", "um", "banco", "do", "outro", "lado", "da", "ponte", "."]
Remoção de palavras irrelevantes
O próximo passo de pré-processamento no PLN remove palavras comuns com pouco ou nenhum significado específico no texto. Essas palavras, conhecidas como palavras irrelevantes, incluem artigos (o/a/um), "é", "e", "são", e assim por diante. Esta etapa elimina palavras não úteis e proporciona uma compreensão significativa, eficiente e precisa do texto.
Exemplo:
Considere o mesmo texto de exemplo inserido por um usuário:
"Há um banco do outro lado da ponte."
Texto entendido pela máquina após a remoção de palavras irrelevantes:
["Há", "banco", "outro", "lado", "ponte", "."]
Stemming e lematização
Stemming e lematização referem-se às técnicas que aplicativos de PLN usam para simplificar palavras e análise de texto, reduzindo-as à sua forma base.
Stemming é uma abordagem baseada em regras que remove prefixos e sufixos para retornar as palavras às suas formas fundamentais ou raízes. O processo não requer muito poder computacional, e as palavras base resultantes podem nem sempre fazer sentido, mas ajudam o programa a facilitar a análise de texto.
Por exemplo, a palavra "compartilhando" resultará em uma raiz "compartilh".
Uma limitação do stemming é que várias palavras semanticamente não relacionadas podem acionista compartilhar uma raiz.
Lematização é uma abordagem baseada em dicionário para converter palavras em sua forma morfológica, também conhecida como lema. O processo requer alto esforço computacional devido à necessidade de consultas ao dicionário. O lema resultante será sempre uma palavra válida contextualmente e como parte do discurso.
Por exemplo, a palavra "compartilhando" resultará em um lema "compartilhar".
Extração de características
Como nossos amigos das máquinas só entendem números e algoritmos, o texto bruto que inserimos deve ser convertido em representações numéricas. A extração de características ajuda a reter as informações relevantes e, ao mesmo tempo, reduz a complexidade dos dados para capturar apenas os padrões e relações mais necessários.
Diferentes técnicas podem ser usadas para alcançar esse resultado com base na tarefa de PLN.
- Saco de Palavras considera apenas a presença ou ausência de palavras, criando um espaço vetorial do texto. A representação do texto é feita por meio da frequência das palavras, em vez da ordem das palavras.
- Frequência de Termo-Inverso da Frequência de Documento (TF-IDF) leva em conta a importância de cada palavra no conjunto de dados. Palavras que ocorrem com frequência recebem mais valor.
- Incorporação de palavras captura relações semânticas entre palavras, criando uma representação vetorial densa. Exemplos incluem Word2Vec e GloVe.
- Modelagem de tópicos extrai tópicos semelhantes do texto para representar documentos distribuídos por tópicos. Um exemplo dessa técnica inclui Alocação de Dirichlet Latente (LDA).
Os algoritmos de PLN são geralmente baseados em regras ou treinados em modelos de aprendizado de máquina. Treinamento contínuo e ciclos de feedback podem criar grandes reservatórios de conhecimento, prever melhor a intenção humana e minimizar respostas falsas.
Quais são as tarefas comuns de PLN?
O processamento de linguagem natural usa técnicas ou tarefas de IA para processar, compreender e gerar linguagem natural (humana). Elas melhoram a interação humano-computador e facilitam a comunicação eficaz por meio de aplicativos baseados em linguagem.
Marcação de parte do discurso
Você sabe quem não esqueceu suas lições de gramática da 6ª série? O PLN.
A marcação de parte do discurso (POS), ou marcação gramatical, permite que aplicativos de PLN identifiquem palavras individuais em uma frase para determinar seu significado no contexto dessa frase. Isso permite que os computadores diferenciem substantivos, verbos, adjetivos e advérbios e entendam suas relações.
Como mostrado no exemplo abaixo, a marcação de POS significa que os programas de PLN têm o poder de contextualizar o verbo "gostar" na frase "Eu gosto da praia" e identificar "gostar" como um advérbio na frase "Eu sou como o Mark."
.png)
Desambiguação de sentido de palavras
O conceito não é tão complicado quanto parece; significa apenas que os programas de PLN podem identificar o significado pretendido da mesma palavra quando usada em diferentes contextos.
Por meio da análise semântica (ou seja, extração de significado do texto e análise), os computadores podem interpretar frases e relações entre palavras individuais para fazer mais sentido em um contexto específico.

A palavra "latido" no exemplo acima tem dois significados diferentes.
Os aplicativos de PLN distinguem entre o latido de um cachorro e a casca de uma árvore por meio da desambiguação de sentido de palavras.
Reconhecimento de entidades nomeadas
Os aplicativos de processamento de linguagem natural podem identificar palavras para categorias específicas, como nomes de pessoas, lugares e nomes de organizações. Por meio do reconhecimento de entidades nomeadas (NER), o software de PLN extrai entidades e entende sua relação com o restante do texto.
.png)
No exemplo acima, a tarefa de PLN de reconhecimento de entidade nomeada identifica "Microsoft" e "Bill Gates" como uma organização e uma pessoa, respectivamente.
Aplicações do reconhecimento de entidades nomeadas
- Extração de fatos de notícias falsas: O NER pode identificar entidades importantes que podem ajudar a verificar fontes de notícias.
- Recuperação de informações: Para ajudar na criação de sistemas de recuperação onde os usuários podem buscar informações específicas para acessar documentos relevantes.
Resolução de co-referência
Tarefas de PLN de alto nível, como resposta a perguntas e recuperação de informações (mais sobre isso depois), exigem que os computadores identifiquem todas as palavras que se referem à mesma entidade. Esse processo, conhecido como resolução de co-referência, ajuda os programas a determinar pessoas/objetos conectados a pronomes específicos.
A resolução de co-referência também é o motivo pelo qual os computadores sabem quando uma expressão idiomática faz parte de um texto.
Reconhecimento de fala
Os programas de PLN se beneficiam de entender o processo de conversão da linguagem falada em – mais ou menos – linguagem de computador. O reconhecimento de fala é essencial para facilitar interações humano-computador naturais e intuitivas.
Vamos ver alguns exemplos de reconhecimento de fala como parte do processamento de linguagem natural.
- Assistentes de voz: Nossos melhores amigos virtuais Siri, Alexa e Google Assistant respondem aos nossos comandos usando técnicas de reconhecimento de fala para fornecer respostas relevantes.
- Transcrição e ditado: Transcrições de gravações de áudio e conversões de linguagem falada para texto são fundamentais para os setores de criação de conteúdo, jurídico e educacional.
- Pré-processamento de dados: O reconhecimento de fala é importante na transformação de dados brutos em uma forma mais compreensível. O pré-processamento pode ser feito para dados de áudio e dados textuais.
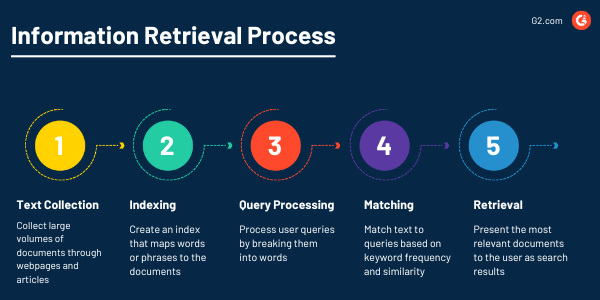
Recuperação de informações
Os programas de PLN sempre encontrarão aquele documento importante exatamente quando você precisar, graças à sua poderosa capacidade de recuperar informações de grandes conjuntos de dados. O objetivo da recuperação de informações como uma tarefa de PLN é oferecer aos usuários informações precisas e úteis de uma coleção de textos por meio de mineração de texto.
Análise de sentimento
Já se perguntou como os bots de atendimento ao cliente quase sempre sabem como você está se sentindo? É tudo graças à análise de sentimento – um processo automatizado que reconhece o tom emocional e os sentimentos expressos em vários casos de uso.
Modelos de aprendizado de máquina podem ser treinados em análise de sentimento usando classificação de rotulagem de sentimento (positivo, negativo, neutro), pós-processamento e avaliação de sentimento.
A análise de sentimento é uma ótima maneira para as empresas obterem insights dos clientes por meio de avaliações de produtos e monitorarem suas marcas com base nos sentimentos das redes sociais.
Tradução automática
A tarefa de PLN de traduzir automaticamente texto ou conteúdo falado de um idioma para outro é amplamente utilizada em software de tradução automática. A tradução automática visa fornecer traduções precisas e coerentes, mantendo a precisão contextual.
Os modelos de tradução também usam reconhecimento de fala. Eles são construídos para melhorar a comunicação global e quebrar barreiras linguísticas nos negócios, educação, saúde e relações internacionais.
Detecção de spam
Já pensou que um e-mail era legítimo e respondeu a ele, mas era apenas spam? Eu também.
A tarefa de PLN de reconhecer automaticamente mensagens irrelevantes de um grande grupo de mensagens, como e-mails e postagens em redes sociais, e removê-las é chamada de detecção de spam.
O processo ajuda a distinguir mensagens fraudulentas de genuínas e garante a segurança dos usuários em plataformas de comunicação.
Bibliotecas e frameworks de PLN
As linguagens de programação são para o PLN o que uma mariposa é para uma chama. Embora muitas linguagens e bibliotecas suportem tarefas de processamento de linguagem natural, algumas populares existem.
Python
A linguagem de programação mais usada para tarefas de PLN, bibliotecas e frameworks de aprendizado profundo é escrita para Python.
- Toolkit de Linguagem Natural (NLTK): Uma das primeiras bibliotecas de PLN escritas em Python, o NLTK é conhecido por suas interfaces fáceis de usar e bibliotecas de processamento de texto para marcação, stemming e análise semântica.
- spaCy: Uma biblioteca de PLN de código aberto, spaCy fornece vetores pré-treinados. Você pode usá-lo para NER, marcação de parte do discurso, classificação e análise morfológica.
- Bibliotecas de aprendizado profundo: PyTorch e TensorFlow são ferramentas comuns para desenvolver modelos de dados de PLN.
R
Estatísticos usam amplamente a linguagem de programação para modelos de PLN de computação estatística e gráficos escritos em R. Isso inclui Word2Vec e TidyText.
Aplicações comerciais de PLN
Técnicas de processamento de linguagem natural são usadas em muitos casos de negócios para melhorar a eficiência operacional, produtividade e processos críticos para a missão.
Chatbots e assistentes virtuais
O aumento da IA conversacional transformou a forma como chatbots e assistentes virtuais interagem com humanos, especialmente no atendimento ao cliente.
O PLN alimenta as capacidades semelhantes às humanas dos chatbots para escalar o suporte ao cliente automatizado, mantendo operações econômicas. Bots de chat e voz podem oferecer recomendações personalizadas e funcionalidades de chat localizadas para ajudar no processo de compra, responder a perguntas frequentes e auxiliar os usuários em tempo real.
Recursos de fala para texto também são benéficos no rastreamento de análises de call centers para transcrever dados de voz em texto.
Monitoramento de redes sociais
A análise de sentimento em plataformas sociais ajuda a avaliar o feedback e as avaliações dos clientes para entender a satisfação do consumidor por meio de insights valiosos de dados.
Ferramentas de monitoramento de redes sociais são alimentadas por processamento de linguagem natural para conceder funcionalidades de escuta, rastreamento e coleta de conteúdo. Essas aplicações são amplamente utilizadas na realização de pesquisas de mercado, análise de tendências e identificação de padrões em diferentes redes sociais.
Extração de insights e detecção de fraudes
As indústrias de saúde e jurídica usam tecnologia de PLN para extrair dados de alta qualidade e relevantes de grandes volumes de dados de ensaios clínicos, literatura científica e contratos legais.
Assim como na detecção de spam, a tecnologia de PLN pode detectar atividades fraudulentas percebendo padrões nos dados. Isso é especialmente útil no setor financeiro para monitorar transações.
PLN vs. NLU vs. NLG
Embora haja apenas um termo diferenciador em processamento de linguagem natural, compreensão de linguagem natural e geração de linguagem natural, existem algumas diferenças entre os três conceitos.
Processamento de linguagem natural
O PLN é um ramo da IA que ajuda os computadores a entender, interpretar e gerar linguagem humana. Tarefas comuns de PLN incluem reconhecimento de fala, análise de sentimento e reconhecimento de entidades nomeadas.
O PLN é amplamente utilizado em assistentes de voz para resumir grandes quantidades de texto e serviços de tradução.
Compreensão de linguagem natural (NLU)
Um subconjunto do PLN, o software de NLU foca na compreensão do texto para extrair significado dos dados. Ele combina lógica de software, linguística, ML e IA para dar sentido à linguagem natural.
Tarefas comuns de NLU incluem:
- Reconhecimento de intenção. Modelos de NLU são usados para identificar a intenção de diferentes entidades para fins de classificação e categorização de texto. Por exemplo, criar diferentes seções para notícias, entretenimento e negócios de uma empresa.
- Análise de conteúdo. Entendendo conexões entre peças de conteúdo, o NLU pode realizar uma análise aprofundada de entidades para destacar sentimentos e relações complexas.
- Busca cognitiva. O NLU analisa e extrai dados não estruturados, permitindo que ele obtenha informações relevantes de conjuntos de dados diversos. Isso melhora os resultados de consultas de busca e fornece informações relevantes de intenção usando análise preditiva.
Top 5 softwares de NLU
1. Amazon Comprehend2. IBM Watson Natural Language Classifier
3. Azure Translator Speech API
4. Azure Translator Text API
5. Apace cTAKES
*Este dado foi retirado do G2 Summer Grid Report em 19 de julho de 2023, com base em nossa metodologia de pontuação.
Geração de linguagem natural (NLG)
No outro extremo do NLU está a tecnologia NLG, o ramo da IA que gera texto escrito ou falado a partir de um conjunto de dados. Ela permite que os computadores forneçam feedback aos humanos em uma linguagem que é compreensível para nós, não para as máquinas.
Tarefas comuns de NLG incluem:
- Conversão de dados. Modelos de NLG convertem dados estruturados em textos legíveis para humanos.
- Interações com clientes. Estas fornecem respostas que soam como linguagem natural, correspondência de sentimentos e comunicações personalizadas com clientes.
Top 5 softwares de NLG
1. Anyword2. Quill
3. AX Semantics
4. Wordsmith
5. Phrazor by vPhrase
*Este dado foi retirado do G2 Summer Grid Report em 19 de julho de 2023, com base em nossa metodologia de pontuação.

Desvendando o mistério da linguagem natural
Embora o PLN possa parecer um feiticeiro, não é. Ele combina várias habilidades computacionais poderosas, tornando-o útil em muitas tarefas que tornam as tarefas humanas mais eficientes.
Seja por meio de saudações de chatbots ou resumo de texto, o mundo do PLN continua a se esforçar para fornecer insights valiosos a partir de grandes conjuntos de dados de linguagem humana. As tecnologias de PLN estão tornando nossas vidas pessoais e profissionais mais envolventes, personalizadas e interativas enquanto navegamos em nosso novo mundo centrado em dados.
Uma das funcionalidades de PLN mais populares é seu uso em assistentes de voz. Saiba mais sobre como o reconhecimento de voz funciona e os recursos que ele oferece que permitem que você grite comandos para ele.
Este artigo foi publicado originalmente em 2019. Foi atualizado de acordo com novas diretrizes editoriais, com novos recursos e exemplos recentes.

Aayushi Sanghavi
Aayushi Sanghavi is a Campaign Coordinator at G2 for the Content and SEO teams at G2 and is exploring her interests in project management and process optimization. Previously, she has written for the Customer Service and Tech Verticals space. In her free time, she volunteers at animal shelters, dances, or attempts to learn a new language.

