



Dados brutos não fazem sentido. Torná-los prontos para negócios envolve muito tempo, recursos e, claro, café.
Cientistas de dados gerenciam dados de três maneiras: gestão, análise e visualização. Modelos de aprendizado de máquina (ML) são uma combinação de todos eles. Eles verificam seus dados, testam sua usabilidade e os convertem em suas expectativas.
A necessidade de modelos de aprendizado de máquina está explodindo em indústrias comerciais e não comerciais. A otimização de dados com software de operacionalização de inteligência artificial e aprendizado de máquina tornou-se o cerne de todas as operações de produção. Onde a maioria das empresas está procurando demitir clientes, os modelos de aprendizado de máquina estão trazendo uma grande revolução orientada por dados.
O que são modelos de aprendizado de máquina?
Um modelo de aprendizado de máquina é uma representação gráfica de dados do mundo real. Ele é programado em um ambiente de dados integrado e trabalha em casos de negócios da vida real. Ele treina em dados antigos e trabalha em dados novos. Leva tempo para programar, testar e validar modelos de aprendizado de máquina antes de utilizá-los para tomar decisões de negócios.
As experiências de aprendizado de máquina e inteligência artificial (IA) remontam ao século XX. A ideia da "geração de supercomputadores" ou "quinta geração de computadores" criou um surto de crescimento da tecnologia em um mundo de computadores a vácuo.
História dos modelos de aprendizado de máquina
A concepção inicial do aprendizado de máquina começou em 1943, quando o lógico Walter Pitts e o neurocientista Warren McCulloch construíram um modelo matemático de uma rede neural. Eles visavam replicar o funcionamento do cérebro humano. Uma década depois, o cientista da computação Arthur Samuel cunhou o termo "aprendizado de máquina" e o descreveu como "a capacidade de um computador de aprender sem ser explicitamente programado."
O conceito nasceu pela primeira vez em 1945, quando Joseph Weizenbaum descobriu o processamento de linguagem natural (NLP) como um desdobramento da inteligência artificial. Lentamente, conceitos mais novos de aprendizado de máquina substituíram os mais antigos. Lentamente, com a evolução do big data, o aprendizado de máquina incubou uma forma mais elevada de inteligência computacional. Essa inteligência era mais precisa, focada e leve do que as invenções anteriores.
Embora os modelos de aprendizado de máquina não fossem 100% precisos em termos de saída, eles fornecem uma previsão constante. A precisão da previsão também dependia do tipo de dados de treinamento em que trabalhavam. Esses modelos aprendiam as semelhanças entre dados externos e internos para fazer projeções.
Aprendizado de máquina ao longo dos anos
- 1945: O primeiro conceito de processamento de linguagem natural (NLP) foi criado por Joseph Weizenbaum
- 1949: The Organization of Behaviour, que falou sobre redes neurais pela primeira vez, publicado por Donald Hebb
- 1950: Invenção do teste de Turing, que foi conduzido para verificar a inteligência e fluência do computador.
- 1951: A calculadora de reforço neural estocástica analógica (SNARC) máquina, o primeiro dispositivo conceitual baseado em uma rede neural artificial, foi criado.
- 1966: Design de Shakey, o primeiro robô baseado em IA
- 1967: Algoritmo K-nearest desenvolvido
- 1979: Invenção do Stanford Cart, um carrinho autônomo controlado remotamente
- 1986: Invenção da máquina de Boltzmann restrita (RBM)
- 1995: Lançamento do "algoritmo de floresta aleatória"
- 2006: Primeira palestra sobre "algoritmos de aprendizado profundo" por Geoffrey Hinton
- 2009: Fei Fei Li desenvolveu o ImageNet, um banco de dados baseado em imagens
- 2012: Introdução do Google Brain, pela Google Inc.
- 2014: Reconhecimento facial do Facebook, DeepFace, lançado
- 2016: Vitória do Alphago, alimentado por IA do Google, contra jogadores de tabuleiro de estratégia
- 2018: Invenção de perceptrons multicamadas, redes adversariais generativas e redes de aprendizado profundo Q.
- 2020: Padronização de realidade aumentada e realidade virtual
- 2022: Internet das coisas, 5G Edge e ML automatizado
Quer aprender mais sobre Software de Redes Neurais Artificiais? Explore os produtos de Rede Neural Artificial.
Quando usar modelos de aprendizado de máquina
Modelos de aprendizado de máquina são usados para extrair insights de dados já existentes. Eles são usados para automatizar operações de negócios para impulsionar o crescimento. No entanto, certos problemas podem não precisar de uma abordagem orientada por dados. Tais problemas não requerem aprendizado de máquina e podem ser resolvidos com cálculos matemáticos padrão. Alguns cenários elegíveis onde o aprendizado de máquina é indispensável são:
- Incapacidade de regras: Em lugares onde é necessário detectar spam de e-mail, aplicativos de aprendizado de máquina como o HoxHunt podem ser usados. Os algoritmos do Hoxhunt preveem oportunidades de spam potenciais e impedem que você acesse a URL maliciosa através de um e-mail de spam. O e-mail de spam parece 99% genuíno e não pode ser detectado por regras simples. Um algoritmo robusto de aprendizado de máquina determina todos os fatores de phishing e impede o usuário.
- Incapacidade de escala: Você pode reconhecer alguns e-mails de phishing, mas não todos. Phishing é uma técnica de hacking invisível ao olho destreinado. Faz um e-mail parecer genuíno enquanto armazena seus detalhes privados em um banco de dados oculto. Um algoritmo de ML lida e resolve esse problema em grande escala.
- Cibersegurança: Com modelos de aprendizado de máquina, soluções de software de cibersegurança podem analisar padrões, identificar anomalias em grandes quantidades de dados de log e encontrar correlações. Isso previne ataques de segurança às empresas.
Você sabia? Você pode avaliar um modelo de aprendizado de máquina com validação cruzada. Isso envolve treinar o modelo com dados de entrada e testá-lo com dados de teste complementares. Isso previne o overfitting do modelo e ajuda a desenhar padrões semelhantes para previsões futuras.
Diferentes tipos de modelos de aprendizado de máquina
Existem três tipos principais de modelos de aprendizado de máquina. Embora todas as técnicas de modelagem de aprendizado de máquina trabalhem com um propósito comum, sua maneira de abordar um problema de dados difere.

À medida que esses modelos são expostos a mais amostras de dados e entradas, eles melhoram no aprendizado e no cálculo de valores previstos. Os modelos desenvolvem inteligência com o tempo, aprendizado constante e experimentação.
1. Aprendizado supervisionado
No aprendizado supervisionado, o modelo de aprendizado de máquina é ensinado com entradas predefinidas.
O modelo é equipado com sinais de entrada e saída. Ele só precisa descobrir como chegar a um valor de saída. O modelo de aprendizado de máquina passa pelo processo de treinamento, mapeia características e as classifica para dados de entrada.
Em seguida, ele tenta capturar o sinal de saída mais próximo à medida que o valor de entrada é armazenado. Ele usa expressões booleanas para calcular valores de dados. Cientistas de dados ou engenheiros de ML treinam esse modelo com um conjunto de dados conhecido que compreende entrada e saída. O algoritmo precisa elaborar uma estratégia de interpretação por conta própria. Se ocorrer uma discrepância, o usuário humano a corrige.
O processo se repete até que o modelo atinja um alto grau de precisão. Exemplos de aprendizado supervisionado incluem reconhecimento óptico de caracteres, reconhecimento de padrões e reconhecimento de voz.
2. Aprendizado não supervisionado
Modelos de aprendizado de máquina não supervisionados identificam padrões ocultos nos dados para formar relações e tirar conclusões. Eles processam conjuntos de dados de entrada comparando-os com informações armazenadas. A taxa de precisão de um algoritmo não supervisionado só cresce quando ele trabalha com a quantidade de dados novos necessária.
Exemplo: Se o aprendizado de máquina não supervisionado for executado em uma imagem de cães e gatos, ele não poderá dizer se a imagem é de um cão ou de um gato porque seus atributos físicos são muito semelhantes. Ele não conseguirá distinguir suas características separadas e retornará uma saída confusa. A precisão da classificação do modelo aumenta quando ele é executado em várias imagens.
3. Aprendizado por reforço
No aprendizado por reforço, o algoritmo se comporta como um agente inteligente que aprende com cada operação malsucedida. O modelo se adapta a partir de saídas incorretas e se esforça para alcançar o objetivo final. Um ciclo de feedback recompensa o modelo com inteligência adquirida quando a saída está correta. Mas quando está incorreta, o modelo aprende com seus erros.
Cada um desses três tipos de modelos de aprendizado de máquina abrange diferentes técnicas de criação de modelos. Vamos dar uma olhada nos mais populares por enquanto.
Tipos de aprendizado supervisionado
Classificação, regressão e previsão são técnicas de análise de dados sob aprendizado supervisionado.
Classificação
Em tarefas de classificação, a modelagem de ml ajuda a atribuir uma categoria aos dados. Eles devem tirar conclusões a partir de valores observados para classificar a saída. Por exemplo, ao classificar dados de pacientes como "novo" ou "antigo", um modelo de ML deve olhar para as datas de registro existentes para categorizar os dados.
Os dois tipos de algoritmos de classificação são classificação binária e classificação multiclasse. Classificadores binários retornam a saída como sim/não ou verdadeiro/ falso. Eles são responsáveis apenas por verificar se uma determinada classe de dados está presente ou não. Por outro lado, se o problema tiver mais de dois resultados possíveis, é chamado de problema de classificação multiclasse.
Regressão
Regressão é um método de aprendizado de máquina focado em uma variável dependente para uma série de variáveis de saída. A análise de um algoritmo de regressão torna as previsões precisas e úteis. Ela passa por uma série de etapas como direcionalidade dos dados, análise de variância (ANOVA), teste de hipóteses e criação final do modelo.
Modelos de aprendizado de máquina resolvem sete tipos de problemas de regressão:
-
Regressão linear é uma técnica de análise de dados que analisa a relação entre variáveis de entrada e saída. Pode haver vários modelos de regressão linear para um problema. Ela ajuda a correlacionar melhor os dados e criar uma relação de variável para variável, como o impacto da pressão atmosférica na mudança topográfica.
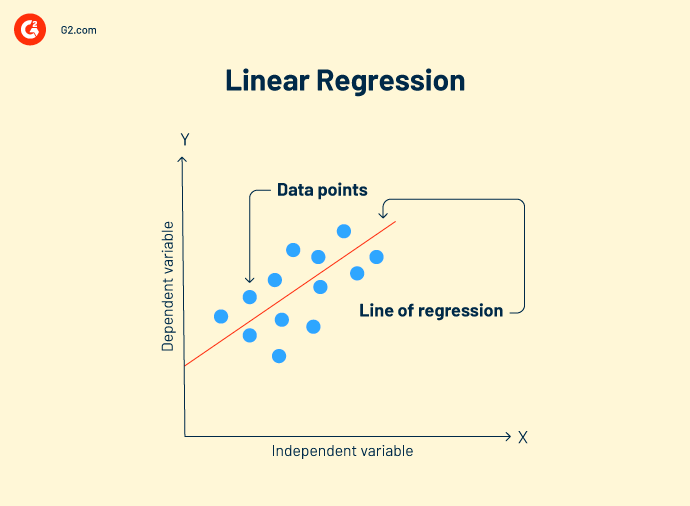
Fórmula de regressão linear:
Y = mx+c+e
Y = valor previsto
m = variável dependente
c = constante
e = resíduo de erro
O objetivo da regressão linear é encontrar um modelo de bom ajuste que mostre previsões precisas em dados de teste.
-
Regressão logística trabalha com dados categóricos. Seu conceito de funcionamento é semelhante ao da regressão linear. Ela estabelece uma relação entre variáveis dependentes e independentes para calcular variáveis previstas. No entanto, a variável de saída só pode ter dois valores, sim ou não.
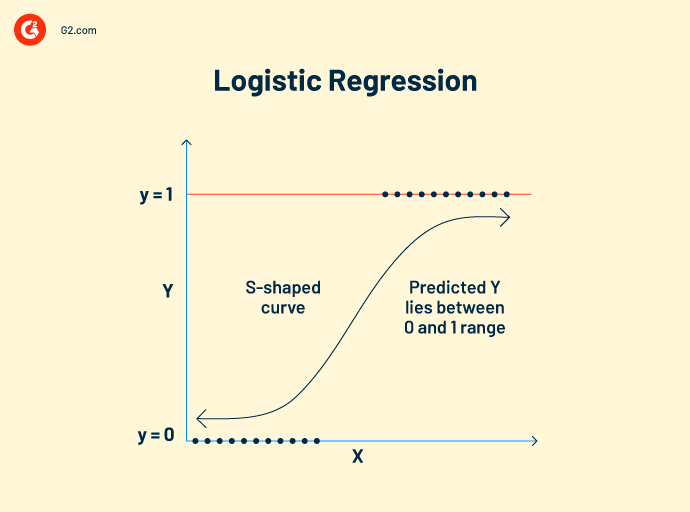
O modelo de regressão logística prevê valores booleanos como 0 e 1 ou verdadeiro e falso. Isso o torna popular como um algoritmo de visão computacional para detectar a presença de obstáculos externos.
Fórmula de regressão logística:
Esta fórmula é denotada pela função logit, que mede a relação entre a variável alvo e as variáveis independentes.
Logit (p) = In(p/(1-p)) = b0+b1X2+b2X2……+bkXk
p = probabilidade de uma característica
-
Árvores de decisão ou fluxos de decisão agrupam todos os possíveis resultados de um evento em uma estrutura semelhante a uma árvore. A árvore tem nós definidos, ramos e gatilhos de eventos. Cada nó interno é uma representação de dados de teste. Dados de teste são executados em nós internos para prever resultados.
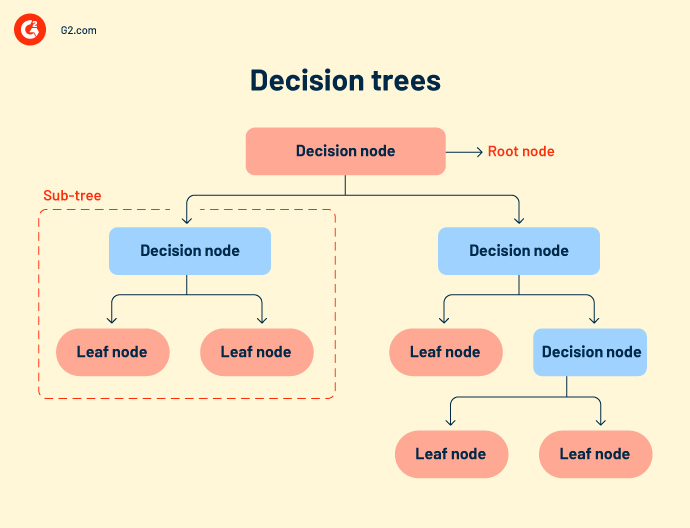
Embora as árvores de decisão sejam simples e intuitivas, elas carecem de precisão. Como compreendem muitos nós, às vezes o sistema fica confuso durante o cálculo da saída.
Árvores de decisão são usadas principalmente em pesquisa e desenvolvimento de produtos, análise operacional e planejamento financeiro estratégico. - Floresta aleatória refere-se a um grande número de árvores de decisão que são agrupadas. Cada nó da árvore prevê a presença de uma categoria através de um agregador de votação. Se a maioria dos nós votar para a mesma saída, essa saída é escolhida. A floresta aleatória é mais complexa do que outros algoritmos de regressão. Pode ser usada tanto para classificação quanto para correlações.
- K-nearest neighbors (KNN) é um dos algoritmos de aprendizado mais simples. Ele classifica seus dados com base nos pontos de dados mais próximos de uma categoria. O algoritmo KNN assume que os novos dados são do mesmo contexto que os dados antigos e processa rapidamente a saída.
- Classificadores Naive Bayes são baseados no teorema de Bayes. É um classificador probabilístico que determina a probabilidade de uma classe para os dados. É um dos modelos de ML mais novos, rápidos e precisos. Equipes de dados o usam para realizar análise de consumidores, análise de sentimentos e classificação de artigos.
- Máquina de Vetores de Suporte (SVM) é um modelo de classificação e regressão usado principalmente para reconhecimento de imagem ou reconhecimento de objetos. Mapas de características extraídos do modelo principal e a localização dos dados são alimentados a um classificador SVM, que combina esses dados para prever a categoria necessária.
3. Previsão
Previsão é uma metodologia baseada em tendências que prevê o futuro com dados do presente ou do passado. É usada principalmente para extrapolar tendências de negócios atuais e potencial de mercado para empresas que tomam decisões de investimento. O método mais proeminente de previsão é a previsão de séries temporais.
Previsão de séries temporais é um método de análise de dados para fazer previsões científicas. Envolve a construção de modelos através da análise de dados históricos ao longo de um período específico. Exemplos incluem previsão do tempo, previsão de desastres naturais e previsão de epidemias. A precisão da previsão de séries temporais é certa, pois trabalha com dados evidenciais.
Exemplos são XGboost, suavização exponencial, autorregressivo e DeepAR.
Tipos de aprendizado não supervisionado
Cientistas de dados ou engenheiros de ML usam aprendizado não supervisionado para construir modelos de aprendizado de máquina autônomos. Esses modelos aprendem e melhoram por conta própria, sem dados externos.
Agrupamento
Agrupamento é o processo de dividir dados de entrada em cestas de categorias semelhantes para posterior classificação. Dois métodos eficazes de agrupamento são mais adequados para seus dados.
-
Agrupamento exclusivo: Este método coloca pontos de dados semelhantes em grupos definidos. Os clusters de dados são mutuamente exclusivos. Por exemplo, todos os estados da América do Norte serão colocados em um cluster e a América do Sul em outro. Os clusters não se sobreporão em nenhuma etapa do processo de análise.
- Agrupamento hierárquico: Também conhecido como agrupamento de baixo para cima, este é um modo mais refinado e organizado de agrupar seus dados. O algoritmo trata cada conjunto de dados como um único cluster e os mescla em um superconjunto. Ao agrupar dados, você pode escolher entre agrupamento aglomerativo ou divisivo.
Amostragem aleatória
Amostragem aleatória é um método de interpretação estatística que cria amostras aleatórias de dados. Ela agrupa dados em diferentes clusters com base em sua natureza, tipo e comportamento. É usada para calcular censo, oferta e demanda de produtos e arrecadação de receita em áreas específicas. A amostragem aleatória é semelhante ao agrupamento, mas não é confiável em termos de precisão.
Aprendizado de regras de associação
O aprendizado de regras de associação impõe certas regras para a classificação de dados. Ele cria relações e padrões interessantes entre os dados e mapeia co-dependências de uma forma que gera o máximo de lucro. Exemplos são mineração de dados ou análise de cesta de mercado.
Redução de dimensionalidade
Esta técnica elimina dados sujos, outliers e valores irregulares, tornando o conjunto de dados de entrada mais limpo e nítido. Exemplos incluem análise de componentes principais ou agrupamento K-means.
Aprendizado profundo
Aprendizado profundo requer grandes conjuntos de dados e alta potência computacional gráfica (GPU) para prever a classe de variáveis de entrada. Envolve redes neurais que são compostas por função de ativação e nós de gatilho. A rede aceita entrada através da camada de entrada, aciona nós de decisão através da função de ativação e processa a saída. Os modelos mais significativos são:
- Autoencoders
- Máquina de Boltzmann
- o Redes Neurais Convolucionais
- o Perceptron multicamadas
- o Redes Neurais Recorrentes
Tipos de aprendizado por reforço
Errar é humano. Errar também é das máquinas.
O aprendizado por reforço designa um agente inteligente para trabalhar com dados. Essas ações inteligentes tomam medidas em um ambiente de aprendizado de máquina para prever resultados corretos. Se o aprendizado por reforço prevê uma saída correta, ele recebe uma recompensa cumulativa. É um dos três paradigmas básicos de aprendizado por reforço.
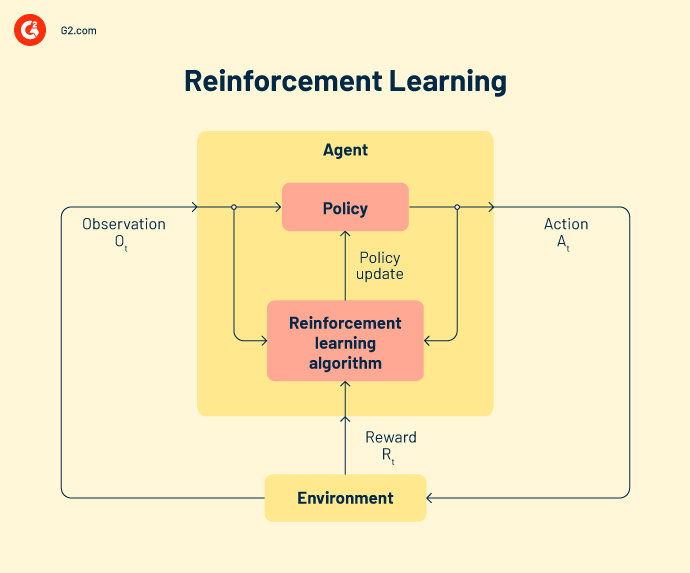
Alguns modelos de reforço populares incluem.
Q-learning é um algoritmo de reforço popular que ajuda agentes de IA a tomar decisões sábias. Com este algoritmo, você pode calcular o valor q, tomar a ação necessária e maximizar os pontos de recompensa.
State-action-reward-state-action (SARSA) é um algoritmo on-policy que calcula o valor q para cada par estado-ação. Para cada estado específico da entrada, há uma saída designada e uma recompensa designada caso a saída seja precisa. Cada letra em SARSA representa uma linha.
Uma rede Q. profunda, ou rede neural Q. profunda, é uma rede neural artificial que possui muitas camadas computacionais. Ela processa a saída com base na entrada, pesos e viés adicionado.
Diferentes modelos de aprendizado de máquina têm diferentes utilidades e alcançam diferentes conjuntos de objetivos. Você deve escolher qual modelo funcionará melhor para você a longo prazo.
Algoritmo vs. modelo de aprendizado de máquina vs. modelo de aprendizado profundo
Independentemente da abordagem, o resultado final é sempre um modelo que age sobre os dados. Aprendizado profundo. Aprendizado de máquina ou algoritmo é o segundo nome da gestão de dados, como seu cientista de dados pode atestar.
-png.png)
Algoritmos são um conjunto de expressões de programação que são autoexplicativas. Eles executam uma sequência de comandos nos dados de entrada. Um algoritmo de aprendizado de máquina é codificado em ferramentas de código aberto como Python, Java ou TensorFlow. Você precisa chamar um pacote específico da biblioteca de pacotes e instalar seus diretórios. Depois disso, você pode carregar seus conjuntos de dados, definir o eixo e criar modelos. Alguns pacotes são Scikit learn, NumPy ou Matplotlib.
O modelo de aprendizado de máquina é a criação final de um algoritmo de dados. Os modelos são categorizados como enviesados, normais ou de bom ajuste. As propriedades dos dados e a precisão do algoritmo são os principais contribuintes para um modelo de aprendizado de máquina. O modelo é implantado em dados de teste e estendido para os aplicativos de fluxo de trabalho de uma organização.
O modelo de aprendizado profundo está um passo à frente dos modelos de aprendizado de máquina. Esses modelos são treinados para extrair e armazenar características individuais dos dados e depois usá-las para fazer previsões precisas. No entanto, esses sistemas de computação precisam de grandes conjuntos de dados, conjuntos de imagens e alta potência computacional gráfica (GPU). Exemplos são a rede neural convolucional (CNN), rede neural convolucional recorrente (R-CNN) e "você só olha uma vez" (YOLO).
Compreender as tecnicalidades dos dados pode ser muito complicado. E muita complicação reside em como você escolhe seus modelos de ML.
Dica: Você pode usar aprendizado de máquina como serviço (MLaaS) para terceirizar processos de aprendizado de máquina para seus fluxos de trabalho de negócios. Este serviço é uma coleção de diferentes softwares baseados em nuvem que implantam ferramentas de aprendizado de máquina para fornecer soluções de análise preditiva para suas equipes de ML para vários casos de uso de negócios.
Como escolher o melhor modelo de aprendizado de máquina para o seu negócio
Para encontrar o melhor modelo, dê uma boa olhada em sua infraestrutura de TI existente. Sua rede local atual pavimentará o caminho para a compatibilidade futura de hardware e software. Considere seu orçamento, largura de banda, rede local (LAN), largura de banda dos cientistas de dados e outras políticas de manutenção de instalações para fazer seus modelos de aprendizado de máquina funcionarem em conjunto.
Uma maneira segura é começar pequeno. Construa uma estrutura de prova de conceito e avalie sua maturidade em IA. Use atributos de dados existentes, volume, características e complexidade para construir um modelo de aprendizado de máquina intermediário. Valide e teste-o para pequenos projetos e casos de uso de negócios. Quando seu modelo se ajustar aos dados, implante-o em uma escala maior.
À medida que você avança, conte com mais largura de banda da equipe, orçamento e esforços dos cientistas de dados. Muito esforço é necessário para gerenciar, treinar e diagnosticar modelos de ML, o que pode consumir seus recursos de negócios.
Você sabia? O mercado global de inteligência artificial foi avaliado em $93,5 bilhões em 2021 e está projetado para expandir a uma taxa de crescimento anual composta de 38,1% de 2022 a 2030.
Fonte: Grand View Research
Embora o modelo de aprendizado de máquina represente seus dados matematicamente, ele não entra em ação por conta própria.
Seus dados são sua pista de decolagem
O aprendizado de máquina é o presente, mas também ilumina o caminho para um futuro digital. Reúna uma quantidade copiosa de pesquisa, estude processos existentes e decida qual opção o colocará na vanguarda do mercado de software.
saiba como você pode escolher o modelo correto de ciência de dados e aprendizado de máquina para o seu negócio.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

