



Aprendizado profundo é a maneira de uma máquina inteligente aprender coisas.
É um método de aprendizado para máquinas, inspirado na estrutura do cérebro humano e em como aprendemos.
É uma tecnologia crítica que torna veículos autônomos uma realidade e também é a razão pela qual o assistente de voz do seu smartphone melhora em ajudá-lo com o tempo. Em outras palavras, o aprendizado profundo é nossa melhor chance de criar máquinas com inteligência semelhante à humana.
O que é aprendizado profundo?
Aprendizado profundo (DL) é um subcampo do aprendizado de máquina que imita o funcionamento do cérebro humano no processamento de dados. DL permite que máquinas aprendam sem supervisão humana e lhes concede a capacidade de reconhecer fala, traduzir idiomas, detectar objetos e até mesmo tomar decisões baseadas em dados.
Em outras palavras, aprendizado profundo é um tipo de aprendizado de máquina (ML) inspirado na estrutura do cérebro humano. Na prática, DL é uma imitação dos neurônios do cérebro humano e tenta imitar suas funções.
Embora o aprendizado profundo seja um ramo do aprendizado de máquina, os sistemas de DL não são restritos por uma capacidade finita de aprender como os algoritmos tradicionais de ML. Em vez disso, os sistemas de DL podem aprender e melhorar seu desempenho com acesso a volumes maiores de dados.
O aprendizado profundo permite que sistemas de inteligência artificial imitem a maneira como os humanos adquirem certos tipos de conhecimento. Os algoritmos de DL tentam tirar conclusões – semelhante a como os humanos fazem – analisando continuamente dados. Para alcançar isso, DL usa redes neurais artificiais (ANNs).
DL imita o funcionamento do cérebro humano, principalmente as funções como processamento de dados e criação de padrões para tomada de decisão. É interessante notar que cientistas e pesquisadores de IA começaram a construir ANNs para que as máquinas pudessem eventualmente exibir as características da inteligência humana, como habilidades de resolução de problemas, autoconsciência, percepção, criatividade e empatia, para citar alguns.
O aprendizado profundo não teria sido possível sem que os computadores se tornassem mais baratos, rápidos e menores. O mesmo é verdade para dispositivos de armazenamento, já que grandes quantidades de dados precisam ser armazenadas e processadas para que o aprendizado profundo se torne uma realidade. É por isso que, embora o aprendizado profundo tenha sido teorizado na década de 1980, tornou-se viável apenas recentemente.
Processar volumes tão enormes de dados não estruturados é virtualmente impossível para humanos. Mesmo que consigamos adquirir a mão de obra necessária, pode levar anos para analisar e extrair informações relevantes desses grandes conjuntos de dados. No entanto, com o aprendizado profundo, esse processo é surpreendentemente simplificado.
Com a ajuda do aprendizado profundo, um sistema de IA pode aprender e melhorar sem qualquer supervisão humana. DL também permite que máquinas aprendam a partir de dados que não são rotulados ou estruturados, ou ambos. No entanto, observe que o processo de aprendizado pode ser não supervisionado, semi-supervisionado ou supervisionado.
O aprendizado profundo também é uma parte crítica da ciência de dados. É benéfico para cientistas de dados coletar, analisar e interpretar grandes volumes de dados e torna processos como modelagem preditiva mais rápidos e eficientes.
Ramos da inteligência artificial, como visão computacional e processamento de linguagem natural, são viáveis devido ao aprendizado profundo. Antes de entrarmos mais nisso, vamos ver como o aprendizado profundo funciona para nos ajudar.
Como o aprendizado profundo funciona?
Em termos mais simples, o processo de aprendizado do DL ocorre modificando as ações do sistema com base em um ciclo contínuo de feedback. O sistema de aprendizado é recompensado por cada ação correta e punido pelas erradas. O sistema tenta ajustar suas ações para maximizar a recompensa.
O aprendizado profundo usa modelos de aprendizado supervisionado, semi-supervisionado, bem como não supervisionado para treinar.
Os neurônios que formam as redes neurais podem ser classificados em três categorias com base em sua hierarquia: camadas de entrada, ocultas e de saída.
- A camada de entrada, que é a primeira camada de neurônios, recebe os dados de entrada e os passa para a primeira camada oculta.
- As camadas ocultas realizam cálculos específicos, como reconhecimento de imagem, nos dados recebidos.
- Uma vez que os cálculos são concluídos, a camada de saída gera a saída necessária.
Como mencionado anteriormente, o aprendizado profundo é possibilitado por redes neurais artificiais. Elas são construídas inspirando-se nas redes neurais do cérebro humano. Um número massivo de perceptrons – a contraparte artificial dos neurônios – é empilhado para formar ANNs.
O termo "profundo" é usado para especificar o número de camadas ocultas que as redes neurais possuem. Enquanto redes neurais tradicionais contêm duas a três camadas ocultas, redes profundas podem ter até 150 camadas.
Uma maneira fácil de entender como o aprendizado profundo funciona é olhando para redes neurais convolucionais (CNNs). É um dos tipos mais populares de redes neurais profundas, além de redes neurais recorrentes (RNNs), redes adversárias generativas (GANs) e redes neurais feedforward.
CNN extrai características diretamente das imagens, eliminando a necessidade de extração manual de características. Nenhuma das características é pré-treinada; em vez disso, elas são aprendidas pela rede quando ela treina no conjunto de imagens fornecido. Essa característica de extração automática de características torna os modelos de aprendizado profundo altamente eficazes para classificação de objetos e outras aplicações de visão computacional.
A razão pela qual as redes neurais profundas são altamente precisas na identificação de características e classificação de imagens é devido às centenas de camadas que possuem. Cada camada aprenderia a identificar características específicas, e à medida que o número de camadas aumenta, a complexidade das características de imagem aprendidas aumenta.
Quer aprender mais sobre Software de Redes Neurais Artificiais? Explore os produtos de Rede Neural Artificial.
Aprendizado profundo vs. aprendizado de máquina
Aprendizado de máquina é uma aplicação de IA que permite que máquinas aprendam e avancem automaticamente a partir da experiência, sem serem explicitamente programadas para isso.
O algoritmo de filtragem de spam presente na sua conta de e-mail é um excelente exemplo de um algoritmo de aprendizado de máquina. Algoritmos de ML também são usados em plataformas OTT como Netflix para recomendar filmes e séries que você provavelmente assistirá e gostará.
Algoritmos de ML são capazes de analisar dados, identificar padrões e fazer previsões. Eles aprendem e se adaptam à medida que novos conjuntos de dados são introduzidos a eles. De certa forma, o aprendizado de máquina torna os computadores mais humanos ao conceder a capacidade de aprender e progredir.
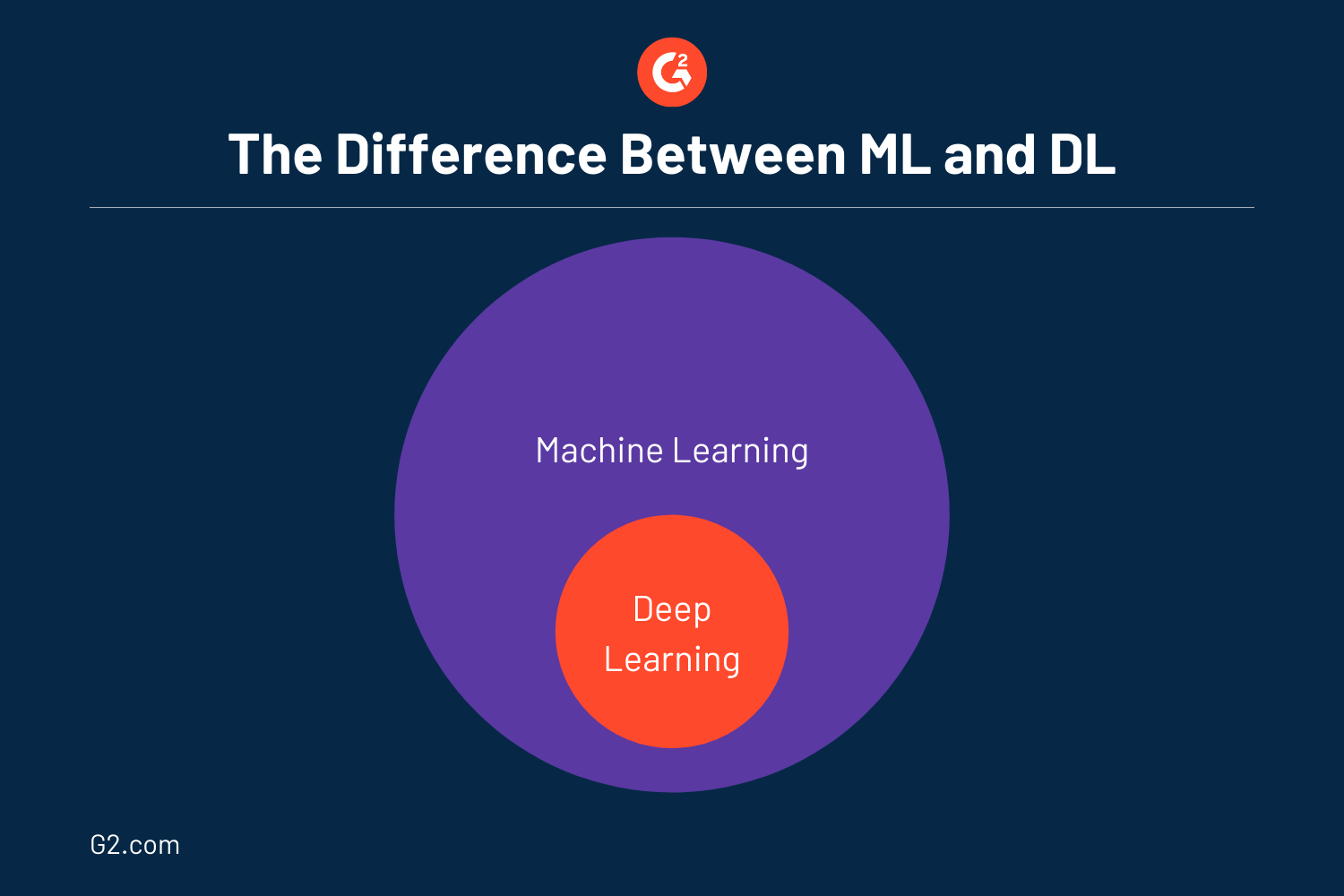
Como mencionado anteriormente, o aprendizado profundo é um subconjunto do aprendizado de máquina, que por sua vez é um subconjunto da inteligência artificial. Mais especificamente, o aprendizado profundo é na verdade aprendizado de máquina e pode ser considerado uma versão evoluída deste último. Muitas vezes, muitos usam DL e ML de forma intercambiável, pois funcionam de maneira quase semelhante.
No entanto, suas capacidades são diferentes. Embora os algoritmos de ML possam aprender e melhorar gradualmente, eles ainda precisam de algum tipo de orientação. Por exemplo, se o algoritmo fizer uma previsão incorreta, então a intervenção humana é essencial para fazer ajustes. Pelo contrário, os algoritmos de aprendizado profundo podem determinar se suas previsões são precisas ou não com a ajuda de redes neurais artificiais.
O programa AlphaGo desenvolvido pela DeepMind usa extensivamente aprendizado profundo. É o primeiro programa de computador a vencer um jogador profissional de Go humano. AlphaGo foi sucedido por inúmeras versões avançadas, incluindo MuZero, que pode dominar um jogo sem ser ensinado as regras.
É interessante notar que pesquisadores tentaram usar técnicas tradicionais de aprendizado de máquina para treinar robôs a dominar o jogo por muitos anos. Mas eles só tiveram sucesso quando combinaram aprendizado profundo com aprendizado por reforço e outros paradigmas.
Outra maneira de diferenciar entre aprendizado de máquina e aprendizado profundo é olhando para como eles aprendem. Suponha que você tenha que ensinar uma máquina a categorizar as imagens de cães e gatos. Se você estiver usando o modelo de aprendizado de máquina, terá que fornecer dados estruturados – neste caso, as imagens rotuladas de cães e gatos – para que o algoritmo aprenda as características específicas que diferenciam as imagens de ambos os animais. O algoritmo melhora a cada imagem rotulada exposta a ele.
| Aprendizado de máquina | Aprendizado profundo | |
| Supervisão humana | Necessária | Não necessária |
| Dados rotulados | Necessários | Não necessários |
| Tempo de treinamento | Segundos ou algumas horas | Horas ou algumas semanas |
| Número de pontos de dados necessários | Milhares | Milhões |
| Recursos computacionais | Menos recursos necessários | Recursos massivos necessários |
| GPU | Não necessária | Necessária |
Uma vez que as imagens são processadas através de diferentes camadas das redes neurais profundas, o sistema terá acesso a identificadores específicos, que ajudarão na classificação dos animais e suas imagens. A saída diferente processada por cada camada da rede neural é combinada para categorizar as imagens de forma eficaz.
A presença de redes neurais também significa que os algoritmos de aprendizado profundo requerem grandes conjuntos de dados. Isso porque os algoritmos de DL só podem aprender quando expostos a um milhão ou mais pontos de dados. Por outro lado, os algoritmos de ML podem aprender e melhorar com diretrizes predefinidas.
Outra diferença notável entre aprendizado de máquina e aprendizado profundo é o tipo de hardware necessário para ambos. Como a complexidade dos cálculos e a quantidade de dados sendo processados é significativamente menor para aprendizado de máquina, programas de ML podem rodar em computadores de baixo custo sem exigir muito poder computacional.
Por outro lado, sistemas de aprendizado profundo requerem recursos computacionais massivos e componentes de hardware poderosos, como unidades de processamento gráfico (GPUs). O cientista da computação Andrew Ng determinou que GPUs podem aumentar a velocidade dos sistemas de aprendizado profundo em mais de 100 vezes.
Com a ajuda de GPUs, o tempo necessário para treinar modelos de aprendizado profundo pode ser reduzido de dias para apenas horas. A maioria dos frameworks de aprendizado profundo, como PyTorch e TensorFlow, já são acelerados por GPU.
Empresas como Nvidia estão se tornando mais sérias sobre aprendizado profundo acelerado por GPU e estão ajustando seus produtos de acordo. Além disso, GPUs são úteis para cálculos de matriz ou vetor.
O tempo necessário para treinar algoritmos de aprendizado profundo e aprendizado de máquina também é significativamente diferente. Como você pode ter adivinhado, algoritmos de aprendizado profundo levam muito tempo para treinar devido à enorme quantidade de dados e cálculos complexos envolvidos. Pode levar algumas horas ou até semanas para treinar um sistema de DL, enquanto um sistema de ML pode ser treinado em alguns segundos ou horas.
Novamente, escolher entre aprendizado profundo e aprendizado de máquina deve ser uma decisão altamente informada. A decisão deve ser tomada levando em consideração o volume e a natureza dos dados, a complexidade do problema que você está tentando resolver e os recursos computacionais disponíveis.
Aplicações de aprendizado profundo
Embora o aprendizado profundo seja considerado um campo emergente, pesquisadores e organizações já estão se beneficiando de suas aplicações. Aqui estão alguns exemplos de aprendizado profundo que estão moldando o mundo ao nosso redor, e muito provavelmente, você pode ter encontrado alguns deles em sua vida diária.
Carros autônomos
Veículos autônomos são os beneficiários mais famosos do aprendizado profundo. Milhões de conjuntos de dados que replicam inúmeros cenários da vida real são alimentados no sistema, que é usado para ensinar o veículo a navegar na estrada com segurança.
Com a ajuda de modelos de aprendizado profundo, os fabricantes podem garantir que carros sem motorista possam lidar com cenários imprevistos sem causar danos aos passageiros ou pedestres.
Além de ajudar as máquinas a resolver cenários hipotéticos, o aprendizado profundo também as ajuda a analisar e processar os dados brutos coletados de câmeras, GPS e inúmeros sensores. Fazer isso permite que os veículos autônomos identifiquem e distingam entre faixas e divisores de estrada, barricadas, sinais, pedestres, carros em desaceleração ou parados, e mais.
Processamento de linguagem natural
Processamento de linguagem natural (NLP) é um campo da inteligência artificial que concede às máquinas a capacidade de entender, interpretar e derivar significado das línguas humanas. Simplificando, NLP torna possível que máquinas conversem com humanos e até mesmo entendam as nuances contextuais de uma língua.
Assistentes inteligentes como Siri e Google Assistant e aplicativos de tradução de idiomas como Google Translate são exemplos do mundo real de NLP. NLP pode ser ainda dividido em geração de linguagem natural (NLG) e compreensão de linguagem natural (NLU).
Dica: Confira alguns dos melhores softwares de processamento de linguagem natural da indústria.
À primeira vista, o reconhecimento de fala pode parecer apenas uma questão de converter som em palavras respectivas. É bastante simples para os humanos, já que o córtex auditivo do nosso cérebro foi treinado por anos para reconhecer e entender uma língua falada ou mais.
Um exemplo simples para representar a complexidade de entender sons é "recognize speech" e "wreck a nice beach". Ambos soam muito semelhantes, embora seus significados sejam completamente diferentes. Embora as máquinas possam detectar palavras em uma frase, entender seu significado contextual ainda é uma tarefa hercúlea. É aí que DL entra em cena para NLP.
Quase todos os assistentes inteligentes dependem de aprendizado profundo, e seus níveis de compreensão e precisão estão aumentando a cada tarefa. O Google Assistant, que depende quase inteiramente de DL, tem a maior precisão.
O aprendizado profundo também permite que as máquinas entendam as complexidades de uma língua, como nuances tonais, expressões e até mesmo sarcasmo. Entender as complexidades de uma língua também é crítico para análise de sentimento em dados textuais. Só então as empresas podem monitorar a reputação da marca e do produto, entender a opinião pública e analisar as experiências dos clientes.
Outra aplicação do aprendizado profundo é a resumação de documentos. A resumação de documentos ou simplesmente a sumarização de texto é a tarefa de extrair informações cruciais de um grande trecho de texto e criar um resumo conciso dele. Além de economizar tempo para os humanos, a resumação de documentos também pode ajudar programas de computador que precisam processar grandes quantidades de dados em um curto período de tempo.
Reconhecimento de locutor é outra aplicação útil do aprendizado profundo e está se tornando cada vez mais precisa. Governos podem usar essa tecnologia para identificar terroristas fazendo chamadas telefônicas anônimas, comparando suas amostras de voz com um banco de dados contendo vozes reconhecidas.
Reconhecimento de imagem
Antes do aprendizado profundo, o campo do reconhecimento de imagem dependia fortemente de ajustes manuais. Isso significa que muitos processos tinham que ser realizados por humanos e levavam muito tempo. O aprendizado profundo elimina a necessidade de processamento de imagem manual ou tradicional e acelera significativamente todo o processo.
Nesta década, a maioria dos sistemas precisos de detecção de objetos que você encontra depende exclusivamente do aprendizado profundo. O Google Photos é um excelente exemplo. Ele usa aprendizado profundo para classificar e agrupar imagens.
Mesmo que você não tenha feito nenhuma rotulagem manual, você pode pesquisar em seu álbum do Google Photos por algo como "insetos em flores" e obter resultados, desde que você tenha imagens relacionadas armazenadas. Você pode até pesquisar por animais com base em suas espécies ou raças e ainda obter todas as fotos contendo o animal em particular.
Enquanto sistemas tradicionais não baseados em aprendizado profundo têm dificuldade em identificar os objetos de uma imagem, o aprendizado profundo vai vários passos além. Ele faz um trabalho impressionante de reconhecer rostos humanos, animais, lugares e coisas com alta precisão e quase zero erro.
Manufatura
Com a introdução da Internet das Coisas (IoT), as fábricas estão ficando mais inteligentes do que nunca. A automação não é nova para a indústria de manufatura, e o aprendizado profundo torna as coisas mais eficientes.
Com a ajuda de arquiteturas de aprendizado profundo como CNN, as empresas podem substituir a maioria dos operadores humanos que eram, de outra forma, essenciais para identificar produtos defeituosos na linha de montagem.
Dessa forma, identificar problemas de qualidade se torna mais preciso e econômico, e as chances de erro humano são eliminadas. Esses sistemas também são altamente escaláveis e podem ser treinados para detectar problemas de qualidade em qualquer ponto da linha de produção.
Outra aplicação do aprendizado profundo na manufatura é a manutenção preditiva. Ao coletar e analisar os dados de saúde das máquinas ao longo do tempo, os algoritmos de aprendizado profundo podem prever as chances de um ativo de manufatura quebrar.
Determinar quando reparar um equipamento é crítico do ponto de vista financeiro de uma empresa, pois uma máquina defeituosa pode parar toda a produção. Como a manutenção irregular também pode causar danos caros e irreparáveis às máquinas e acidentes catastróficos na fábrica no pior cenário, as empresas podem economizar muito com a manutenção preditiva. Saber quando reparar também ajudará as empresas a planejar com antecedência e procurar alternativas para reduzir o tempo de inatividade da fábrica.
Otimização de insumos da fábrica é outra aplicação benéfica do aprendizado profundo. Com os consumidores se tornando mais preocupados com a pegada de carbono dos produtos e as reformas ecológicas feitas por seus criadores, as empresas não têm escolha a não ser otimizar o uso de recursos físicos.
Além disso, otimizar recursos ajudará as empresas a lucrar mais com cada produto, daí a otimização de insumos da fábrica. Ao rastrear o uso de recursos (consumo de eletricidade e água, principalmente) de diferentes máquinas e processos de produção, os sistemas de aprendizado profundo podem sugerir dinamicamente as melhores práticas de otimização.
Descoberta de medicamentos
A descoberta de medicamentos é incrivelmente demorada e cara. O aprendizado profundo pode tornar esse processo mais barato e rápido. O aprendizado profundo pode ajudar a prever a afinidade de ligação de medicamentos com proteínas específicas e até mesmo os efeitos tóxicos de compostos específicos.
AtomNet é uma rede neural convolucional profunda usada para o design racional de medicamentos. É uma tecnologia de ponta capaz de encontrar compostos de medicamentos novos e não óbvios e pode ser uma ferramenta notável para projetos acelerados de reposicionamento de medicamentos. AtomNet também foi usado para prever novos candidatos a biomoléculas para Ebola e esclerose múltipla (EM).
Hospitalidade
Hospitalidade é uma indústria multibilionária sempre ansiosa para adotar novas tecnologias, e a tecnologia de aprendizado profundo não é exceção. Com DL, as organizações podem encontrar novos meios de melhorar a experiência e satisfação do cliente e até mesmo identificar processos caros e substituíveis.
O aprendizado profundo pode ajudar as organizações a planejar com antecedência, prevendo demandas sazonais. Um sistema de aprendizado profundo pode encontrar facilmente a correlação entre fatores que causam demandas sazonais e prever tendências futuras, analisando dados passados.
Ao analisar dados de clientes, os modelos de DL também podem ajudar as empresas a construir estratégias de clientes para melhores taxas de retenção e satisfação. As empresas também podem usar várias técnicas de aprendizado de máquina para precificação competitiva, considerando múltiplos fatores, como sazonalidade, eventos em tempo real, promoções de terceiros, eventos locais e dados de reservas passadas.
Finanças
Como o processamento de big data complexo é uma especialidade do aprendizado profundo, ele tem um imenso potencial na indústria financeira. Ao analisar dados históricos, vários parâmetros de mercado e fatores externos que podem afetar o desempenho de uma empresa, os algoritmos de aprendizado profundo podem prever valores de ações com precisão impressionante.
Como os algoritmos de DL podem analisar vastos volumes de dados de várias fontes simultaneamente, é incrivelmente mais rápido do que os humanos e, portanto, é usado para criar estratégias de negociação lucrativas.
Redes neurais profundas também são usadas no processo de aprovação de empréstimos. Ao analisar dados históricos sobre aprovações e rejeições, os bancos podem avaliar corretamente os riscos de aprovar um empréstimo para uma entidade.
Restauração de imagem
A restauração de imagem é outra façanha impressionante que o aprendizado profundo pode realizar. A restauração de imagem geralmente se refere à recuperação de uma imagem clara e não degradada a partir de uma imagem degradada. A degradação pode ocorrer devido a vários fatores, sendo o ruído da imagem um deles.
Se o ruído da imagem for o culpado, então o processo de restauração é chamado de remoção de ruído da imagem. Da mesma forma, as imagens podem ter resolução mais baixa e, pelo processo de super-resolução, imagens de resolução mais alta podem ser criadas.
Com o aprendizado profundo, esses processos de restauração se tornam mais precisos e menos demorados. Métodos de aprendizado como Deep Image Prior são utilizados para o processo de restauração. Em termos simples, Deep Image Prior é uma rede neural convolucional usada para aprimorar uma imagem sem qualquer dado de treinamento prévio além da própria imagem.
Em 2017, os pesquisadores da equipe do Google Brain treinaram uma rede neural profunda para analisar imagens de rostos de resolução muito baixa e prever os rostos. Este método é chamado de Super Resolução Recursiva de Pixels e pode melhorar significativamente a resolução das imagens. A rede neural pode identificar com facilidade as características distintivas de uma pessoa.
O aprendizado profundo também é amplamente usado para colorir fotos em preto e branco. Você pode conferir ferramentas online como Algorithmia para ver como imagens específicas em preto e branco teriam se parecido se tiradas com uma câmera colorida.
Publicidade móvel
O aprendizado profundo permite que anunciantes móveis publiquem anúncios que podem capturar a atenção de seu público-alvo e oferecer um retorno sobre o investimento (ROI) mais alto. Técnicas de aprendizado profundo, como publicidade preditiva baseada em dados, são usadas para aumentar a relevância dos anúncios também.
Numerosas redes de anúncios móveis em tempo real usam APIs de aprendizado profundo, que ajudam os anunciantes a maximizar a taxa de cliques (CTR). Os tempos de resposta mais rápidos dos sistemas de aprendizado profundo também permitem que os anunciantes exibam os anúncios certos no momento e espaço certos.
Detectar atrasos no desenvolvimento
O diagnóstico e tratamento precoces de distúrbios do desenvolvimento, autismo ou distúrbios da fala podem impactar positivamente o futuro de uma criança. Um humano não notaria inúmeros sinais em estágio inicial, mas um sistema de aprendizado profundo certamente pode.
Usando aprendizado profundo, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT e do Instituto de Profissões de Saúde do Hospital Geral de Massachusetts criaram um sistema de computador que pode identificar distúrbios da fala mesmo antes de uma criança entrar no jardim de infância.
Além disso, crianças que estão no espectro do autismo têm dificuldade em reconhecer os estados emocionais das pessoas ao seu redor. Por exemplo, crianças com autismo terão dificuldade em diferenciar entre um rosto feliz e um rosto assustado.
Como remédio para esse problema, alguns médicos usam robôs amigáveis para crianças, alimentados por aprendizado profundo, para envolver as crianças em imitar emoções e responder a elas de maneiras apropriadas. À medida que o robô interage, ele analisa o interesse e o engajamento da criança observando suas respostas.
O aprendizado profundo permite que o robô extraia as informações mais cruciais dos dados coletados sem precisar de qualquer assistência humana. Com a ajuda de DL, os pesquisadores descobriram inúmeros fatos fascinantes, como as diferenças culturais entre crianças de diferentes países.
Eles observaram que durante episódios de alto engajamento, crianças do Japão mostraram mais movimentos corporais. Por outro lado, grandes movimentos corporais foram associados a episódios de desengajamento para crianças da Sérvia.
Uma das maiores razões pelas quais esse tipo de tratamento é eficaz é que o robô é preparado para atrair a atenção das crianças. Além disso, os humanos tendem a mudar suas expressões com frequência e expressar a mesma emoção de maneiras diferentes. Mas o robô sempre faz isso da mesma maneira para que o processo de aprendizado seja muito menos frustrante para a criança.
Previsão de som
A produção de som é uma parte integral da produção cinematográfica. Embora certos sons, como passos, batidas na porta ou pneus rangendo, possam ser emprestados de áudios de estoque, muitas vezes eles precisam ser recriados para melhorar a experiência cinematográfica.
Pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) criaram um algoritmo de aprendizado profundo que prevê som. Quando dado um clipe de vídeo silencioso de um objeto sendo atingido, o algoritmo pode produzir sons realistas. O som previsto é realista o suficiente para enganar os humanos.
Para treinar o algoritmo, os pesquisadores filmaram aproximadamente 1.000 vídeos de cerca de 46.000 sons que constituem diferentes objetos sendo atingidos, cutucados e raspados com uma baqueta. Eles usaram uma baqueta especificamente porque oferecia um método consistente para produzir um som.
Sistemas de previsão de som não apenas tornarão as coisas melhores para a indústria cinematográfica, mas também poderão ajudar máquinas inteligentes a navegar pelo mundo e entender as propriedades dos objetos.
Tradução visual
Você já tentou traduzir idiomas estrangeiros com o aplicativo Google Translate? O aplicativo não apenas "traduz" as palavras, mas sobrepõe a imagem com a tradução. O aplicativo faz isso com a ajuda de redes neurais profundas e é uma das muitas maneiras pelas quais o Google espreme o aprendizado profundo em um smartphone.
Uma vez que o aplicativo encontra onde as letras estão localizadas na imagem analisando seus pixels, uma rede neural convolucional treinada em letras e não-letras tenta reconhecer o que cada letra é. Uma vez que as letras são identificadas, o aplicativo consulta um dicionário para obter traduções.
A tradução é então renderizada sobre as letras originais no mesmo estilo da imagem original. Essas traduções visuais são super rápidas se realizadas nos data centers do Google. Mas como a maioria dos usuários possui um smartphone de baixo custo e tem conexões de internet instáveis, o Google desenvolveu uma pequena rede neural com inúmeras limitações.
Sistemas de recomendação
Algoritmos de aprendizado profundo são usados em sistemas de recomendação para sugerir conteúdo que os usuários têm mais probabilidade de assistir. A eficácia desses algoritmos é crítica para plataformas como Netflix, pois somente se os usuários encontrarem frequentemente conteúdo interessante, eles continuarão a assinatura. A Amazon e inúmeras outras plataformas de comércio eletrônico também dependem fortemente de algoritmos de aprendizado profundo para recomendar os produtos certos e aumentar as vendas.
Detecção de fraude
Perdas e danos relacionados a fraudes são uma triste realidade da indústria financeira. Os golpistas financeiros estão crescendo.
$1,9 bilhão
foi perdido devido a roubo de identidade e fraude em 2019.
No entanto, pode haver inúmeros comportamentos de usuários que sistemas baseados em regras podem não identificar como suspeitos, mas sistemas de detecção de fraude baseados em DL certamente identificariam. O poder de processamento para sistemas baseados em DL também é notável, e eles também reduzem a necessidade de trabalho manual – ao contrário de sistemas baseados em regras que exigem supervisão humana frequente e correções manuais.
Como criar e treinar modelos de aprendizado profundo
Existem três maneiras comuns de treinar um modelo de aprendizado profundo para realizar classificação de objetos. Você pode treiná-lo do zero, usar aprendizado por transferência ou usar uma rede como extrator de características. Vamos dar uma olhada rápida em cada uma.
1. Treinamento do zero
Para treinar redes neurais profundas do zero, você precisa adquirir grandes volumes de conjuntos de dados rotulados – por exemplo, as imagens rotuladas de gatos e cães. Depois disso, você precisa projetar uma arquitetura de rede que possa aprender as características distintas dos animais. Dependendo do volume de dados, taxa de aprendizado e poder de processamento, as redes podem levar dias ou semanas para treinar.
2. Abordagem de aprendizado por transferência
A maneira mais comum de treinar redes neurais profundas é pela abordagem de aprendizado por transferência. Nesse processo, um modelo pré-treinado é ajustado para realizar uma nova tarefa. Você pode começar com uma rede existente e alimentar novos conjuntos de dados contendo classes anteriormente desconhecidas para ela.
Você pode ajustar a rede de acordo com seus requisitos, neste caso, identificar e distinguir entre as imagens de gatos e cães. Como esse processo requer menos quantidade de dados, o tempo de computação cai significativamente.
3. Usando extrator de características
Outra abordagem para treinar um modelo de aprendizado profundo é usar uma rede como extrator de características. Como cada camada da rede é designada para aprender características específicas de imagens, você pode realmente extrair essas características da rede durante o processo de treinamento. Essas características podem então ser inseridas em um modelo de aprendizado de máquina. Fazer isso pode reduzir a necessidade de recursos computacionais enormes.
Aprendizado profundo: quanto mais, melhor
Uma propriedade interessante do aprendizado profundo é que ele melhora se você fornecer mais dados e mais recursos computacionais. Embora os algoritmos de aprendizado profundo possam parecer muito exigentes, eles são altamente precisos e requerem pouca ou nenhuma assistência humana na maioria dos casos.
O aprendizado profundo também será nossa chave para desbloquear a inteligência geral artificial, um sistema de IA capaz de pensar, aprender e agir como humanos.
Saiba mais sobre inteligência geral artificial e veja por si mesmo se uma máquina tão inteligente seria amiga ou inimiga.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

