



Todo segundo do dia, o mundo acessa, muda e depende de dados.
Funções diárias, como comprar um bilhete de trem ou sair para almoçar com colegas de trabalho, envolvem o processamento de dados. Organizações e indivíduos precisam de dados para administrar negócios, não importa se consistem em 30 ou 3.000 pessoas. Os dados estão realmente em tudo o que fazemos e nos acompanham aonde quer que vamos.
É exatamente por isso que proteger seus dados é tão importante. Um simples backup dos dados do seu negócio pode salvá-lo da ameaça de potenciais hackers, do download acidental de um vírus e até mesmo de desastres naturais.
Existem dezenas de maneiras de proteger seus dados de serem comprometidos. Um desses métodos é a replicação de dados.
O que é replicação de dados?
A replicação de dados é o processo de armazenar seus dados em mais de um local. O processo cria várias cópias de um banco de dados para melhor protegê-lo de um evento de perda de dados. A replicação de dados como processo é mais útil para melhorar a acessibilidade dos dados. Todos os usuários com acesso poderão compartilhar exatamente os mesmos dados, não importa onde estejam no mundo.
Os dados de negócios mudam centenas, às vezes milhares de vezes em um único dia. Muitas organizações preferem a replicação de dados por causa da conveniência que ela oferece ao compartilhar dados entre escritórios e continentes. Neste artigo, vamos nos aprofundar em como funciona, os diferentes tipos e métodos, e os benefícios e desafios que acompanham cada um.
Por que usar replicação de dados?
A replicação de dados é um método de backup atraente por duas razões principais: sua segurança e sua conveniência rápida. O método ajuda as organizações a manter várias cópias atualizadas de seus dados, distribuindo-os para centros de dados próximos a escritórios remotos.
Manter mais de uma cópia aumenta a segurança dos dados em caso de desastre. Se uma cópia for danificada, outra versão exata existe em outro lugar.
Não se engane, a replicação de dados não é uma cópia estática dos seus dados. Assim como a proteção contínua de dados, a replicação de dados está sempre processando seus dados de forma contínua para que cada cópia, não importa onde esteja, seja sempre precisa e atualizada para espelhar sua fonte original.
O resultado final é uma infinidade de cópias de dados em diferentes locais que os usuários podem acessar sem se preocupar em bagunçar os dados de seus colegas.
Como a replicação de dados gerencia vários locais de dados, ela também pode ajudar os usuários a acessar dados muito mais rapidamente. Pode ser especialmente útil se uma organização tiver um número substancial de escritórios internacionais.
Digamos que você trabalhe na Ásia, mas a sede da sua empresa e a fonte original de dados estão localizadas na América do Norte. Você pode experimentar latência de dados ao acessar dados de um centro de dados a milhares de quilômetros de distância. Ao usar a replicação de dados para colocar outra réplica mais próxima dos usuários internacionais, você economiza tempo e frustração.
Replicar dados também ajudará a melhorar o desempenho do servidor. Se sua organização executar várias cópias de dados em vários servidores de dados, todos os usuários poderão acessar dados muito mais rapidamente. Além disso, ao salvar todas as operações de leitura em uma réplica do original, você poderá economizar ciclos de processamento no servidor principal para operações de gravação de maior importância.
Um dos usos mais comuns da replicação de dados é para recuperação de desastres. Semelhante à proteção contínua de dados, a replicação de dados garante que sempre exista um backup atualizado em caso de falha de hardware, dano físico ou uma violação de sistema que coloque seus dados em risco.
Software de recuperação de desastres ajuda as empresas a recuperar rapidamente e eficientemente software, configurações e dados para um estado anterior em caso de falha de computador, servidor ou infraestrutura. Descubra uma lista imparcial das principais ferramentas de hoje no link acima.
Quer aprender mais sobre Replicação de Dados Software? Explore os produtos de Replicação de Dados.
Como funciona a replicação de dados?
A replicação de dados envolve copiar dados de um local e criar outra versão exata em outro local. Por exemplo, os dados podem ser replicados entre dois servidores locais, entre servidores em diferentes locais, em vários meios de armazenamento no mesmo servidor e para e de um host baseado em nuvem.
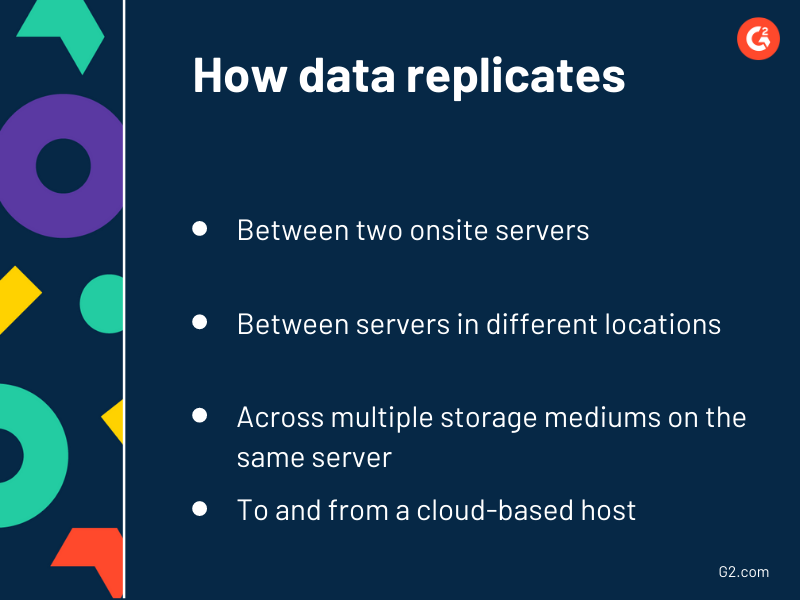
Você terá a opção de copiar dados instantaneamente, transferi-los em grandes blocos ou pequenos lotes, definir um cronograma para quando deseja que os dados sejam movidos e replicar dados em tempo real à medida que os dados do servidor mestre são escritos, alterados ou excluídos completamente.
Além disso, você pode usar a replicação completa, onde um banco de dados completo é copiado para cada local do servidor, ou replicação parcial, onde apenas alguns dos dados mais frequentemente usados são replicados entre os servidores. Falaremos mais sobre esses tipos de replicação mais tarde.
Nota: A replicação de dados pode ocorrer em uma rede local, uma rede de área de armazenamento, uma rede de área local ampla ou através da nuvem.
O processo de replicação de dados
Utilizar a replicação de dados só será útil se houver cópias exatas dos seus dados armazenadas em todos os servidores. Esse é o ponto principal do método de backup. Assim como você faria com qualquer outro método, seguir um processo de replicação ajudará a manter os dados seguros e consistentes em cada local.
O processo seguiria mais ou menos estas etapas:
- Identifique sua fonte de dados e onde deseja que ela seja replicada.
- Escolha os arquivos, pastas e aplicativos que deseja copiar da fonte.
- Planeje seu cronograma de backup e com que frequência deseja que os backups ocorram.
- Decida se usará replicação de tabela completa, baseada em chave ou baseada em log.
- Se estiver usando replicação baseada em chave, identifique as chaves de replicação (colunas que, se alteradas na fonte, copiarão os registros dos quais fazem parte no processo).
- Use uma ferramenta de replicação ou escreva um código personalizado para iniciar o processo de replicação.
- Fique de olho no processo de backup para garantir que tudo seja feito corretamente.
Vantagens da replicação de dados
Alguns dos benefícios mais óbvios da replicação de dados incluem seu papel na recuperação de desastres e o fácil acesso a dados e aplicativos de negócios cruciais. No caso de um desastre ou dano à fonte primária, uma cópia replicada dos dados estará lá para manter os fluxos de trabalho funcionando normalmente.
Como os dados existem em vários locais e em vários servidores, a replicação de dados ajuda a facilitar o compartilhamento de dados em grande escala. Também distribui o estresse da carga de rede entre cada site de servidor de dados.
Algumas vantagens adicionais que as organizações podem esperar ao usar a replicação de dados incluem:
- A replicação de dados mantém seus dados consistentes e sempre atualizados, não importa de onde os usuários estejam tentando acessar.
- Você pode esperar um aumento na disponibilidade de dados. Se um sistema falhar, for atacado ou se tornar corrupto, você poderá acessar seus dados de outro site.
- Implementar a replicação de dados pode potencialmente minimizar o trabalho do departamento de TI ao criar e manter as transações de replicação de dados da organização.
- Você verá uma melhoria no desempenho geral da rede ao usar a replicação de dados. Ao armazenar seus dados em vários locais (especialmente se sua organização tiver escritórios internacionais), seus funcionários não experimentarão tanta latência de acesso aos dados. Como os dados estão armazenados perto deles, eles serão carregados mais rapidamente.
- Você verá um aumento no desempenho do sistema de teste. As ferramentas de replicação de dados podem tornar a sincronização e distribuição de dados para sistemas de teste muito mais rápidas e fáceis.
- A replicação de dados pode aumentar o suporte à análise de dados. Copiar dados para um data warehouse dará às equipes de análise o suporte para trabalhar em projetos de inteligência de negócios.
Plataformas de inteligência de negócios permitem que as empresas analisem dados e revelem insights acionáveis que podem ajudar a melhorar a tomada de decisões e informar a estratégia. As plataformas de BI se conectam a bancos de dados, data warehouses ou distribuições de big data e oferecem aos analistas a capacidade de mexer com dados para descobrir insights.
Desvantagens da replicação de dados
Vimos que a replicação de dados tem um bom número de vantagens, mas as organizações devem sempre avaliar as desvantagens que podem enfrentar ao implementar uma nova ferramenta. Um dos desafios mais comuns com a replicação de dados pode surgir de atrasos de dados ou interrupções de serviço enquanto os dados estão sendo transferidos ou copiados.
Além disso, à medida que a distância entre os sistemas de dados replicados e a cópia original aumenta, o processo de replicação de dados pode se tornar mais oneroso.
Algumas desvantagens adicionais que as organizações podem esperar ao usar a replicação de dados incluem:
- Manter todos os dados atualizados pode ser um desafio. Quanto mais locais você armazena seus dados, mais você terá que implementar sistemas complexos para acompanhar o que é o quê.
- Você precisará de mais espaço de armazenamento à medida que seus dados continuarem a crescer. Esse espaço pode custar uma boa parte do orçamento da sua equipe.
Quando se trata disso, os desafios principais que você enfrentará ao usar a replicação de dados estão todos relacionados a recursos limitados.
- Quando você usa ferramentas de replicação de dados, manter um número de réplicas em alguns, talvez até uma dúzia de locais, pode levar sua organização a gastar mais dinheiro com custos mais altos de processador e armazenamento.
- Alguém tem que ser responsável pelo processo de backup. Implementar a replicação de dados no processo de backup de uma organização leva tempo para a equipe dedicada aperfeiçoar.
- Manter todas as cópias de dados consistentes requer uma revisão nos procedimentos e aumenta o tráfego de rede, potencialmente desacelerando o trabalho.
Tipos de replicação
Quando se trata de replicação, existem três tipos principais que você pode escolher, cada um com diferentes vantagens. Garantir que você saiba qual funcionaria melhor para sua organização é um ótimo começo para usar ferramentas de replicação de dados.
1. Replicação transacional
Ao usar a replicação transacional, você receberá uma cópia completa do seu banco de dados e será continuamente enviado atualizações à medida que seus dados mudam. Isso facilita o acompanhamento do que é alterado e se os dados são perdidos.
A consistência transacional é uma garantia com esse tipo de replicação. Os dados serão replicados em tempo real e enviados do publicador (o servidor principal) para os assinantes (servidores secundários) na ordem exata em que acontecem.
A replicação transacional não apenas copia suas alterações de dados, ela replica continuamente cada alteração com grande precisão. Normalmente, esse tipo é usado em ambientes de servidor para servidor.
2. Replicação de instantâneo
A replicação de instantâneo ocorre quando uma imagem do banco de dados é tirada e distribuída entre os servidores. Os dados são enviados exatamente como aparecem em um momento específico (o momento do instantâneo). Esse tipo não faz anotações sobre atualizações nos dados; em vez disso, envia aos assinantes (servidores secundários) uma visão geral dos dados em um instante.
Normalmente, a replicação de instantâneo será usada quando as alterações nos dados forem esparsas. Esse tipo de replicação é ótimo ao realizar a sincronização inicial entre o publicador e o assinante, mas tende a ser um pouco mais lento. Isso ocorre porque cada instantâneo enviado está tentando mover vários registros de dados de uma extremidade para a outra.
3. Replicação de mesclagem
Esse tipo de replicação ocorre quando dois ou mais bancos de dados são combinados em um único banco de dados. A replicação de mesclagem permite que quaisquer alterações nos dados sejam enviadas do publicador (servidor principal) para um ou mais assinantes (servidores secundários).
Esse tipo de replicação é o mais complexo porque permite que tanto o publicador quanto os assinantes façam alterações no banco de dados. É tipicamente usado em um ambiente de servidor para cliente.
Técnicas de replicação de dados
Anteriormente, mencionamos as três técnicas de replicação de dados: incremental baseada em chave, tabela completa e incremental baseada em log. Ao falar sobre replicação de banco de dados, você precisará saber a diferença entre os três métodos para entender completamente como a replicação de dados funciona.
1. Replicação de tabela completa
A replicação de tabela completa copiará cada pedaço de dados da fonte original para o destino. Isso inclui quaisquer dados novos, existentes e atualizados.
A principal desvantagem dessa técnica é que ela exige mais poder de processamento e resulta em maior estresse na carga de rede. Como copia todos os dados a cada vez, isso pode torná-la mais lenta do que outras técnicas. O custo do backup aumentará à medida que seus dados continuarem a crescer.
Essa técnica é mais útil se os dados forem regularmente excluídos da fonte ou se a fonte não tiver uma coluna adequada para outras técnicas.
2. Replicação incremental baseada em chave
A replicação incremental baseada em chave atualizará apenas os dados que foram alterados desde a última atualização. Como cada vez menos dados são copiados durante essas atualizações, essa técnica de replicação de dados é mais eficiente do que a replicação de tabela completa.
A principal desvantagem da replicação incremental baseada em chave é sua falha em replicar dados já excluídos (já que os dados são excluídos uma vez que o original é excluído).
Nota: A replicação incremental baseada em chave também é chamada de captura incremental de dados baseada em chave e carregamento incremental baseado em chave.
3. Replicação incremental baseada em log
A replicação incremental baseada em log é uma técnica única. Ela só funciona para fontes de banco de dados e replica dados com base nas informações do arquivo de log do banco de dados (um arquivo que registra alterações no banco de dados). A baseada em log é a mais eficiente das três técnicas, mas deve ter suporte do banco de dados de origem.
Essa técnica de replicação será mais adequada para você se a estrutura do seu banco de dados de origem for relativamente estática. Se os tipos de dados mudarem ou se alguma coluna for removida, toda a configuração do sistema baseado em log terá que ser atualizada para espelhar essas mudanças. Isso é tipicamente um desperdício de tempo para todas as partes envolvidas.
Por causa disso, a replicação de tabela completa ou baseada em chave pode ser mais adequada para suas necessidades se você souber que a estrutura do seu banco de dados de origem mudará frequentemente.
Esquemas de replicação
As organizações podem realizar a replicação de dados seguindo um esquema para mover os dados. Eles diferem das técnicas listadas acima porque não são usados como uma estratégia contínua para mover dados. Em vez disso, eles decidem como os dados podem ser replicados para atender às necessidades específicas de um negócio. Os dados podem ser movidos de uma só vez ou em seções.
Existem três principais esquemas de replicação que são usados na replicação de dados.
1. Replicação completa
A replicação completa do banco de dados ocorre quando todo o banco de dados é replicado para vários usuários. Os dados estarão acessíveis a quase todos os locais ou usuários na rede.
Esse esquema oferece a melhor disponibilidade de dados e pode ajudar com problemas internacionais. Se um usuário estiver com dificuldades para acessar dados do servidor europeu da organização, ele pode acessar os mesmos dados de outros servidores ao redor do mundo como backup.
Vantagens da replicação completa
- Melhora a disponibilidade geral dos dados em todo o sistema, pois tudo pode operar normalmente enquanto pelo menos um site estiver funcionando.
- A execução de consultas é mais rápida.
- Como os dados podem ser obtidos de qualquer site, há uma maior taxa de recuperação de consultas globais.
Desvantagens da replicação completa
- Como uma atualização deve ser realizada em todos os bancos de dados para manter cópias exatas dos dados, a atualização levará mais tempo.
- O controle de concorrência é difícil de alcançar, já que os dados estão sempre mudando.
2. Sem replicação
Na ausência de replicação, seus fragmentos serão armazenados em apenas um site. Isso pode dificultar o acesso regular à informação para usuários distantes desse site.
Vantagens de não replicar
- Os dados são mais facilmente recuperados.
- A concorrência pode ser alcançada com esse esquema.
Desvantagens de não replicar
- A execução de consultas pode ser mais lenta porque vários usuários estão acessando um servidor.
- Como não há replicação, os dados não estão facilmente disponíveis.
3. Replicação parcial
A replicação parcial replica apenas alguns fragmentos do banco de dados. Nesse esquema, os dados no banco de dados são divididos em seções. Cada seção é armazenada em diferentes locais com base na frequência com que é acessada por esse local. Pense nisso como um sistema que analisa quais dados são mais importantes para cada local. Se o escritório chinês estiver usando um conjunto específico de planilhas enquanto o local norte-americano raramente o faz, esses dados serão replicados apenas no local chinês.
A replicação parcial é mais útil para pessoas que trabalham em finanças e vendas. Elas podem levar partes de seu banco de dados com elas em laptops e outros dispositivos e sincronizá-los quando precisarem de dados do servidor de dados principal. A replicação parcial mantém dados importantes próximos aos usuários que precisam deles. Caso um usuário precise acessar dados que normalmente não utiliza, um arquivo mestre de dados sempre será mantido no servidor da sede.
Vantagens da replicação parcial
- A quantidade de réplicas de dados depende da importância dos dados nesse fragmento.
Desvantagens da replicação parcial
- Como apenas partes de certos dados são replicadas para diferentes servidores, isso pode atrasar o progresso quando os usuários precisam acessar dados que normalmente não usam do servidor principal.
Antes de implementar o software de replicação de dados...
Antes de seguir em frente e decidir dar uma boa tentativa à replicação de dados, há algumas coisas que você deve ter em mente.
Mais uso de armazenamento
Se grandes organizações estão considerando a replicação de dados, elas devem dedicar tempo para avaliar quais técnicas e esquemas desejam usar. É provável que, se a organização for grande, haja muitos dados para respaldá-la.
Armazenar dados da empresa em vários lugares consumirá espaço de armazenamento. Antes de seguir em frente, saiba que mais armazenamento significa mais dinheiro, o que pode ser um fator decisivo.
A chance de dados inconsistentes
Replicar dados em várias fontes pode potencialmente causar inconsistências. Se você estiver replicando dados em horários diferentes e apenas em determinados servidores, a chance de dados fora de sincronia é alta, e pode ser difícil colocar todos os locais na mesma página. Os administradores devem criar um processo de replicação personalizado e sempre verificar cada local de servidor para garantir a consistência em todo o mundo.
A necessidade de maior capacidade de rede e poder de processamento
Embora ter sites de dados mais próximos dos usuários internacionais torne o acesso aos dados mais fácil para eles, há uma desvantagem. Gerenciar vários locais pode sobrecarregar sua rede e desacelerar, além de consumir poder de processamento. Um processo de replicação de dados mais eficaz, adaptado especificamente para sua organização, pode ajudá-lo a gerenciar essa carga aumentada.
Encontre o par perfeito
Pode ser assustador começar a busca por uma solução de replicação de dados que funcione para suas necessidades específicas. Mas encontrar essa solução tornará o processo muito mais fácil no futuro.
Seu departamento de TI pode escrever código e lidar com o processo de replicação por conta própria, mas isso apresenta seu próprio conjunto de dificuldades. Você precisará dedicar tempo para manter seus dados, gastar dinheiro em aplicativos e talvez até contratar algumas pessoas extras para agilizar o processo. Além disso, você deve estar ciente da ameaça sempre presente do erro humano.
É por isso que a replicação de dados e o backup de banco de dados são tão úteis. As soluções de backup de banco de dados ajudam as empresas a proteger seus dados com cópias de backup em caso de dados corrompidos, erro do usuário ou falha de hardware. Ao utilizar soluções de backup de banco de dados, as empresas podem garantir que seus dados estejam sempre disponíveis, mesmo que seu banco de dados principal falhe.
Navegue pelas soluções de backup de banco de dados mais bem avaliadas para encontrar a combinação certa para sua organização.

Alexa Drake
Alexa is a former content associate at G2. Born and raised in Chicago, she went to Columbia College Chicago and entered the world of all things event marketing and social media. In her free time, she likes being outside with her dog, creating playlists, and dabbling in Illustrator. (she/her/hers)

