



La science des données rassemble le monde et concentre des informations distribuées aléatoirement en petites unités.
Avec tout le battage médiatique autour des big data, des données structurées vs non structurées, et de la façon dont les entreprises les utilisent, vous pouvez vous demander : « De quels types de données parlons-nous ? »
La première chose à comprendre est que toutes les données ne sont pas créées égales. Cela signifie que les données générées par les applications de médias sociaux sont complètement différentes des données générées par les systèmes de point de vente ou de chaîne d'approvisionnement.
Certaines données sont structurées, mais la plupart ne le sont pas. En arrière-plan, un logiciel de gestion de base de données (DBMS) est un système de gestion de requêtes qui authentifie l'accès de l'utilisateur à ces données et la capacité de les stocker, de les gérer et de les récupérer via des requêtes utilisateur.
Pour clarifier, décomposons les différences uniques entre les données structurées et non structurées.
Quelle est la différence entre les données structurées et non structurées ?
Les données structurées sont hautement organisées et formatées de manière à être facilement recherchées dans des bases de données relationnelles. Les données non structurées n'ont pas de format ou d'organisation prédéfinis, ce qui les rend beaucoup plus difficiles à collecter, traiter et analyser. Les données structurées sont plus finies et triées en tableaux de données, tandis que les données non structurées sont dispersées et variables.
En plus d'être sourcées, collectées et mises à l'échelle de différentes manières, les données structurées et non structurées résideront dans des bases de données entièrement séparées.
Qu'est-ce que les données structurées ?
Les données structurées sont le plus souvent catégorisées comme des données quantitatives, et c'est le type de données avec lequel la plupart d'entre nous sont habitués à travailler. Pensez aux données qui s'intègrent parfaitement dans des champs et colonnes fixes dans des bases de données relationnelles et des feuilles de calcul.
Des exemples de données structurées incluent les noms, les dates, les adresses, les numéros de carte de crédit, les informations boursières, la géolocalisation, et plus encore.
Les données structurées sont hautement organisées et facilement comprises par le langage machine. Ceux qui travaillent dans des bases de données relationnelles peuvent rapidement saisir, rechercher et manipuler des données structurées en utilisant un système de gestion de base de données relationnelle (RDBMS). C'est la caractéristique la plus attrayante des données structurées.
Le langage de programmation pour gérer les données structurées s'appelle le langage de requête structuré, également connu sous le nom de SQL. IBM a développé ce langage au début des années 1970, et il est particulièrement utile pour gérer les relations dans les bases de données.
Exemples de données structurées
Si cela semble déroutant, voici un exemple d'une commande DDL (langage de définition de données) exécutée pour tabuler des données structurées. Les données sont stockées dans une table SQL, chaque ligne et colonne contribuant à un type de données spécifique.
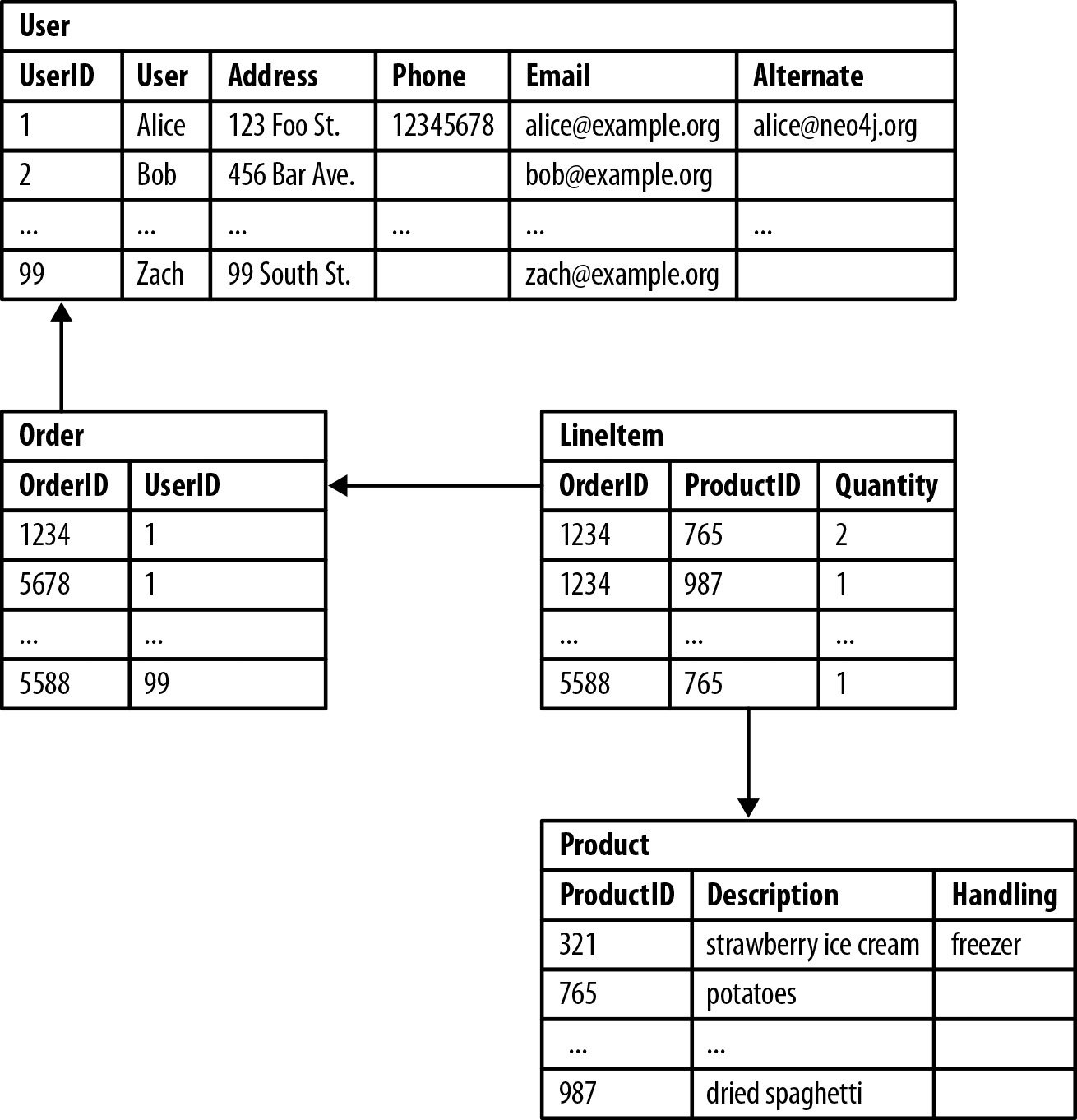
De haut en bas, nous pouvons voir que UserID 1 se réfère au client Alice, qui avait deux Order IDs de '1234' et '5678'. Ensuite, Alice avait deux ProductIDs de '765' et '987'. Enfin, nous pouvons voir qu'Alice a acheté deux paquets de pommes de terre et un paquet de spaghettis secs.
Les données structurées sont également utilisées dans les systèmes de réservation de compagnies aériennes, les systèmes de covoiturage électronique, les applications de livraison de nourriture et les données d'optimisation des moteurs de recherche (SEO). Dans chacun de ces cas, les données sont stockées dans des bases de données relationnelles et peuvent être stockées, récupérées ou gérées sous de grandes formes.
Les données structurées ont révolutionné les systèmes basés sur le papier sur lesquels les entreprises comptaient pour l'intelligence d'affaires il y a des décennies. Bien que les données structurées soient toujours utiles, de plus en plus d'entreprises cherchent à déconstruire les données non structurées pour de futures opportunités.

Source: Fivetran
Exemples de données structurées
Les données structurées sont utilisées dans plusieurs bases de données orientées vers le consommateur ou ERP, telles que :
- E-commerce : Données d'évaluation, données de prix, et numéro SKU des produits
- Santé : administration hospitalière, pharmacie, et données des patients et historique médical des patients.
- Banque : Détails des transactions financières comme le nom du bénéficiaire, les détails du compte, les informations de l'expéditeur ou du destinataire et les détails bancaires.
- Logiciel de gestion de la relation client (CRM) : données d'acquisition de leads, source, activité, etc. des leads dans la base de données CRM.
- Industrie du voyage : Données des passagers, informations sur les vols, et transactions de voyage.
Données structurées vs non structurées
Les données non structurées sont le contraire des données structurées. Voici un aperçu des différences notables entre les deux.

Les données structurées sont des données préformatées propres, soigneusement organisées en blocs de mémoire. Son format est prédéfini en lignes et colonnes et stocké dans des systèmes de bases de données relationnelles (RDBMS) ou Microsoft Excel. Les données sont connues sous le nom de "schéma à l'écriture", représentant des données pour un schéma ou un plan de base de données de grande taille. Elles sont hautement évolutives et sécurisées et nécessitent moins de gestion.
Les données non structurées sont hautement complexes, qualitatives et non organisées. Elles sont également appelées big data, qui ne se conforment à aucune norme particulière. Ces données peuvent être numériques, alphabétiques, booléennes ou un mélange de toutes. Elles sont stockées en utilisant une base de données NoSQL. Elles ne peuvent pas être stockées dans une base de données relationnelle ou RDBMS car les chaînes de données ont des types de données mixtes qui ne peuvent pas s'adapter à une ligne ou une colonne. Les types courants de données non structurées sont les données de clics, les données des médias sociaux, le texte et les multimédias.
En relation : Explorez SQL vs. NoSQL pour voir quelle base de données est faite pour vous.
Avantages des données structurées
Il est facile de stocker, récupérer et gérer les données structurées car elles ont un mécanisme de backend organisé. Utiliser des données structurées dans les affaires peut entraîner les avantages suivants.
- Les données structurées peuvent être facilement intégrées dans des modèles d'apprentissage automatique en tant qu'ensembles de données d'entrée sans aucun ajustement.
- Travailler avec des données structurées ne nécessite pas d'expertise en IA ou en ML. Toute personne ayant de bonnes informations sur le produit et des connaissances de base en science des données peut le faire.
- Les données structurées sont stockées uniformément dans des entrepôts de données ou des feuilles de calcul. Leur nature spécifique et organisée les rend faciles à manipuler et à interroger.
- Les données structurées précèdent les données non structurées, donc plus d'outils d'analyse sont disponibles pour les mesurer et les analyser.
- Les données sont de meilleure qualité, cohérence et utilisabilité que les données non structurées.
- Il existe des mécanismes de secours pour s'adapter si l'utilisateur rencontre une erreur lors de la gestion des données structurées.
- Elles sont également connues sous le nom de données quantitatives, car les entreprises utilisent leurs métriques pour prévoir les tendances commerciales et l'impact stratégique.
- Elles sont maintenues dans un référentiel centralisé stable qui améliore le flux des processus commerciaux et la prise de décision pour optimiser le retour sur investissement.
Défis des données structurées
La plupart des problèmes de données structurées soulignent leur inflexibilité et leur rigidité à évoluer vers des schémas de bases de données plus grands. Les données structurées sont "schéma à l'écriture" ou "fortement dépendantes du schéma" pour les opérations. Les défis courants des données structurées sont listés ci-dessous :
- Comme les données structurées dépendent du schéma, il est un peu difficile de les faire évoluer pour de grandes bases de données.
- Le temps nécessaire pour charger les données structurées est parfois sous-estimé. Identifier les problèmes cachés dans le système source et les mettre à jour, les récupérer et les restaurer peut empiéter sur votre stockage cloud.
- Ne s'adapte pas bien au scénario commercial changeant. Il est difficile de déterminer quelle requête entraînerait un résultat commercial spécifique. La nature des requêtes et des transactions change à mesure qu'une entreprise modifie son focus consommateur.
- Les données structurées sont saisies manuellement dans le système de gestion de base de données. L'utilisateur doit taper une commande DDL (langage de définition de données) comme Create, Insert et Select pour trier, gérer et récupérer les données du système.
Outils de données structurées
En plus d'utiliser un langage de requête structuré (SQL) ou Microsoft Excel pour gérer les manipulations de données structurées, il existe quelques extensions d'outils supplémentaires que vous pouvez utiliser.
- PL SQL : Le langage de requête procédurale ou PL SQL est une version existante de SQL qui traite des transactions de travail. Les requêtes transactionnelles courantes sont "commit" ou "rollback".
- Postgre SQL : Postgre SQL est un système de gestion de base de données relationnelle open-source qui gère de grands volumes de données. Il prend également en charge les requêtes SQL et JSON ainsi que les langages de haut niveau.
-
SQLite : C'est une base de données de haut niveau, autonome et sans serveur que les développeurs de logiciels utilisent pour extraire des données structurées pour les intégrations d'applications commerciales,
- My SQL est un environnement de données intégré standard qui utilise l'authentification utilisateur pour entrer des enregistrements de données via des requêtes dans une base de données massivement déployée.
- OLAP : Il englobe une catégorie plus large de gestion de base de données comprenant l'exploration de données, l'exploration de rapports et l'intelligence d'affaires.

Qu'est-ce que les données non structurées ?
Les données non structurées sont souvent catégorisées comme qualitatives et ne peuvent pas être traitées et analysées à l'aide d'outils et de méthodes de données conventionnels. Elles sont également connues sous le nom de "données indépendantes du schéma" ou "schéma à la lecture".
Des exemples de données non structurées incluent le texte, les fichiers vidéo, les fichiers audio, l'activité mobile, les publications sur les réseaux sociaux, les images satellites, les images de surveillance – la liste est longue.
Les données non structurées sont difficiles à déconstruire car elles n'ont pas de modèle de données prédéfini, ce qui signifie qu'elles ne peuvent pas être organisées dans des bases de données relationnelles. Au lieu de cela, les bases de données non relationnelles ou bases de données NoSQL sont les mieux adaptées pour gérer les données non structurées.
Une autre façon de gérer les données non structurées est de les faire circuler dans un lac de données ou une piscine, leur permettant d'être dans leur format brut et non structuré.
Trouver l'information enfouie dans les données non structurées n'est pas une tâche facile. Cela nécessite des analyses avancées et une expertise technique élevée pour faire la différence. L'analyse des données peut être un changement coûteux pour de nombreuses entreprises.
95%
des entreprises citent le besoin de gérer les données non structurées comme un problème pour leur entreprise.
Source: Techjury
Exemples de données non structurées
Ceux qui sont capables d'exploiter les données non structurées, cependant, ont un avantage concurrentiel. Alors que les données structurées nous donnent une vue d'ensemble des clients, les données non structurées ou big data peuvent nous donner des informations détaillées sur les actions quotidiennes des consommateurs.
Par exemple, les techniques de fouille de données appliquées aux données non structurées d'un site de vente au détail peuvent aider les entreprises à apprendre les habitudes d'achat des clients et le moment, les modèles d'achat, le sentiment envers un produit spécifique, et bien plus encore.
Les données non structurées sont également essentielles pour les logiciels d'analyse prédictive. Par exemple, les données de capteurs attachées à des machines industrielles peuvent alerter les fabricants d'une activité étrange à l'avance. Avec cette information, une réparation peut être effectuée avant que la machine ne subisse une panne coûteuse.
Plus d'exemples de données non structurées :
Les données non structurées sont tout événement ou alerte envoyé et reçu par tout utilisateur au sein d'une organisation sans format de fichier approprié ou co-dépendance commerciale directe.
- Médias riches : Médias sociaux, divertissement, surveillance, informations satellites, données géospatiales, prévisions météorologiques, podcasts
- Documents : Factures, dossiers, historique web, e-mails, applications de productivité
- Données des médias et du divertissement, données de surveillance, données géospatiales, audio, données météorologiques
- Internet des objets : données de capteurs, données de ticker
- Analytique : Apprentissage automatique, intelligence artificielle (IA)
Avantages des données non structurées
Les données non structurées, également connues sous le nom de big data de nos jours, sont libres et natives à chaque entreprise spécifique. Elles sont indépendantes du schéma et sont connues sous le nom de "schéma à la lecture". Personnaliser ces données selon vos stratégies commerciales peut vous donner un avantage concurrentiel sur les concurrents encore coincés dans la prise de décision traditionnelle. Et voici pourquoi.
- Les données non structurées sont facilement disponibles et ont suffisamment d'informations que les entreprises peuvent collecter pour apprendre la réponse de leur produit.
- Les données non structurées sont indépendantes du schéma. Par conséquent, de légères modifications de la base de données n'impactent pas le coût, le temps ou les ressources.
- Les données non structurées peuvent être stockées sur des serveurs cloud partagés ou hybrides avec des dépenses minimales en gestion de base de données.
- Les données non structurées sont dans leur format natif, donc les scientifiques ou ingénieurs de données ne les définissent pas jusqu'à ce qu'elles soient nécessaires. Cela ouvre l'expansibilité des formats de fichiers, car elles sont disponibles dans différents formats comme .mp3, .opus, .pdf, .png, etc.
- Les lacs de données viennent avec une tarification "payez à l'utilisation", ce qui aide les entreprises à réduire leurs coûts et leur consommation de ressources.
Défis des données non structurées
Les données non structurées sont la méthode de collecte et de manipulation de données la plus tendance aujourd'hui. De nombreuses entreprises passent à des modèles commerciaux plus "centrés sur le client" et misent sur les données des consommateurs. Cependant, travailler sur des données non structurées entraîne les défis suivants.
- Les données non structurées ne sont pas les plus faciles à comprendre. Les utilisateurs nécessitent un solide bagage en science des données et en apprentissage automatique pour les préparer, les analyser et les intégrer avec des algorithmes d'apprentissage automatique.
- Les données non structurées reposent sur des serveurs partagés moins authentiques et cryptés, qui sont plus sujets aux ransomwares et aux cyberattaques.
- Actuellement, il n'y a pas beaucoup d'outils qui peuvent manipuler les données non structurées à part les serveurs de commodité cloud et les DBMS NoSQL open-source.
Outils de données non structurées
En plus d'utiliser un NoSQL pour gérer les manipulations de données non structurées, il existe quelques autres outils que vous pouvez utiliser.
- Hadoop : Un cadre de calcul distribué pour traiter de grandes quantités de données non structurées.
- Apache Spark : Un cadre de calcul en cluster rapide et polyvalent pour traiter les données structurées et non structurées.
- Outils de traitement du langage naturel (NLP) : Pour extraire des informations à partir de données textuelles non structurées.
- Bibliothèques d'apprentissage automatique : Pour construire des modèles pour analyser et prédire des modèles dans les données non structurées.
Plus de types de données
En plus des types de données ci-dessus, les données semi-structurées et les métadonnées jouent un rôle crucial dans la gestion de la complexité et de la diversité croissantes des sources de données modernes.
Qu'est-ce que les données semi-structurées ?
Les données semi-structurées sont un type de données structurées qui se situe à mi-chemin entre les données structurées et non structurées. Elles n'ont pas de modèle de données relationnel ou tabulaire spécifique mais incluent des balises et des marqueurs sémantiques qui échelonnent les données en enregistrements et champs dans un ensemble de données.
Des exemples courants de données semi-structurées sont JSON et XML. Les données semi-structurées sont plus complexes que les données structurées mais moins complexes que les données non structurées. Elles sont également relativement plus faciles à stocker que les données non structurées, comblant le fossé entre les deux types de données.
Un plan de site XML contient des informations de page pour un site web. Il intègre des URL, des scores de domaine, des pages do-follow et des balises méta.
Qu'est-ce que les métadonnées ?
Les métadonnées sont souvent utilisées dans l'analyse des big data et sont un ensemble de données maître qui décrit d'autres types de données. Elles ont des champs prédéfinis qui contiennent des informations supplémentaires sur un ensemble de données spécifique.
Les métadonnées ont une structure définie identifiée par un schéma de balisage de métadonnées qui inclut des modèles et des normes de métadonnées. Elles contiennent des détails précieux pour aider les utilisateurs à mieux analyser les données et à prendre des décisions éclairées.
Par exemple, un article en ligne peut afficher des métadonnées telles qu'un titre, un extrait, une image en vedette, un texte alternatif d'image, un slug, et d'autres informations connexes. Ces informations aident à différencier un contenu d'un autre contenu similaire sur le web. Par conséquent, les métadonnées sont un ensemble de données pratique qui agit comme le cerveau pour tous les types de données.
Outils de gestion de base de données
Les outils de gestion de base de données fournissent l'infrastructure pour stocker, gérer, et analyser les données efficacement, assurant une gestion efficace des données et des informations précieuses. Utiliser le bon outil de gestion de base de données permettra aux entreprises de :
- Réduire les coûts opérationnels
- Suivre les métriques actuelles et en créer de nouvelles
- Comprendre ses clients à un niveau bien plus profond
- Révéler des campagnes marketing plus intelligentes et plus ciblées
- Découvrir de nouvelles opportunités et offres de produits
Top 5 des outils de gestion de données :
*Ci-dessus sont les cinq principales solutions logicielles de gestion de données du rapport Grid® de l'été 2024 de G2.
Comme les données, comme les décisions
Le volume des big data continue d'augmenter, mais l'importance du stockage des big data cessera bientôt d'exister.
Que les données soient structurées ou non structurées, avoir les sources de données les plus précises et pertinentes sera essentiel pour les entreprises cherchant à prendre l'avantage sur leurs concurrents.
Plus il y a de variétés de données créées par les data scientists, plus de nouveaux algorithmes avancés seront créés, ce qui facilitera la conformité au RGPD.
Les données s'infiltrent dans chaque grande industrie du monde. Les marques s'éloignent des astuces marketing non essentielles pour se tourner vers le marketing consommateur basé sur les données. Les informations que les données nous fournissent sont apprises et analysées en tandem avec l'intelligence artificielle et le calcul en réseau pour créer des solutions robustes et hyperconnectées.
À la fin de la journée, c'est au consommateur de déterminer à quel point il est à l'aise avec les façons dont ses données sont utilisées.
Nouveau dans l'analyse des big data mais souhaitez en savoir plus ? Apprenez à obtenir des informations en temps réel à partir de vos données avec le bon logiciel d'analyse des big data.
Cet article a été publié à l'origine en 2021. Il a été mis à jour avec de nouvelles informations.

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)

