


Les humains sont dotés de vision périphérique ; mais les ordinateurs atteignent maintenant une compétence avec la détection d'objets.
Que ce soit le pilote automatique de Tesla ou les aspirateurs Deebot, les dispositifs informatiques sont alimentés par de nouveaux algorithmes d'IA générative pour accélérer les puissances de traitement et nommer les objets physiques. Connue sous le nom de détection d'objets en bref, cette simulation de vision conçue avec un logiciel de reconnaissance d'images a passé le relais de la vision et de la vue aux ordinateurs.
Le but principal de la détection d'objets est de segmenter, localiser et annoter les objets physiques ou numériques avec une précision infaillible pour accomplir une tâche désignée.
La détection d'objets a ouvert de nouvelles voies d'assistance robotique visant à fabriquer des dispositifs d'auto-assistance pour faciliter les tâches fastidieuses. Apprenons-en plus en détail.
Qu'est-ce que la détection d'objets ?
La détection d'objets est une approche d'IA étroite qui identifie, classe et localise les objets dans des photographies ou vidéos numériques. Le principal objectif de la détection d'objets est de détecter les instances de chaque objet, de les segmenter et d'analyser leurs caractéristiques nécessaires pour une catégorisation en temps réel et une modularité approfondie.
La détection d'objets fait partie de l'architecture de base de données globale d'une entreprise. Certaines entreprises ont adopté avec succès cette technologie tandis que d'autres attendent qu'elle soit annoncée comme une technique de gestion de base de données réussie.
Les principaux exemples de détection d'objets incluent la sécurité et la surveillance, le contrôle d'accès, la présence biométrique, la surveillance des conditions routières, les machines d'auto-assistance et la protection des frontières maritimes.
Comment fonctionne la détection d'objets ?
La détection d'objets fonctionne de manière similaire à la reconnaissance d'objets. La seule différence est que la reconnaissance d'objets est le processus d'identification de la catégorie correcte de l'objet, tandis que la détection d'objets détecte simplement la présence et l'emplacement de l'objet dans une image.
Les tâches de détection d'objets peuvent être effectuées en utilisant deux techniques différentes d'analyse de données.
- Traitement d'image fait partie de l'apprentissage non supervisé qui ne nécessite pas de données d'entraînement historiques pour enseigner aux modèles analytiques. Les modèles s'auto-forment sur les images d'entrée et créent des cartes de caractéristiques pour faire des prédictions. Le traitement d'image ne nécessite pas de grande puissance de traitement graphique ou de grands ensembles de données pour l'exécution.
- Réseau neuronal profond : Un réseau neuronal profond est généralement un algorithme d'apprentissage supervisé qui nécessite de grands ensembles de données et une grande puissance de calcul GPU pour prédire les classes d'objets. C'est un moyen plus précis de classer des objets partiellement cachés, complexes ou placés dans des arrière-plans inconnus dans une image.
Former un réseau neuronal profond est une tâche laborieuse et coûteuse. Cependant, certains ensembles de données à grande échelle fournissent la disponibilité de données étiquetées.
Le saviez-vous ? COCO, un ensemble de données de détection d'objets, de segmentation et de légende à grande échelle, peut être utilisé pour former un réseau neuronal profond.
Voici quelques fonctionnalités que vous pouvez attendre de MS COCO :
- Segmentation d'objets
- Reconnaissance dans le contexte
- Segmentation de superpixel
- Pré-entraîné sur 33 000 images
- 1,5 million d'instances d'objets
- 80 classes d'objets
- 91 catégories de choses
- 5 légendes par image
- 250 000 personnes avec des points clés
Vous voulez en savoir plus sur Logiciel de reconnaissance d'image ? Découvrez les produits Reconnaissance d'image.
Importance de la détection d'objets
Ayant compris la méthodologie de travail, il est temps de discuter de ce qui rend la détection d'objets importante.
La détection d'objets forme la base d'autres techniques de vision IA importantes, telles que la classification d'images, la récupération d'images, le traitement d'images ou la co-segmentation d'objets, qui extraient des informations significatives des objets réels. Les développeurs et ingénieurs utilisent ces techniques pour construire des machines futuristes qui livrent des courses et des médicaments à notre porte !
Un algorithme de détection d'objets peut détecter automatiquement les mouvements de bétail, les signaux de trafic et les voies routières afin que les véhicules autonomes puissent atteindre leur destination. Cela, à son tour, élimine le besoin pour les conducteurs de faire des courses logistiques.

La détection d'objets peut également fonctionner sur des réseaux mobiles en élaguant les couches d'un réseau neuronal profond. Elle est déjà utilisée dans les scanners de sécurité ou les détecteurs de métaux dans les aéroports pour détecter les objets indésirables et illégaux.
En dehors de cela, les entreprises utilisent la détection d'objets pour le comptage de personnes, la reconnaissance de plaques d'immatriculation, la reconnaissance vocale et la détection de preuves. Cependant, un léger manque de précision entrave parfois son efficacité à détecter des objets minuscules. Un manque de précision à cent pour cent le rend moins préférable pour des domaines critiques comme l'exploitation minière et l'armée.
Classification d'images vs détection d'objets
La détection d'objets est souvent confondue avec la classification d'images. Bien que ce soient les côtés du même cube de Rubik, voici quelques différences notables.
-png.png)
La classification d'images est un concept simple de catégorisation d'une image multispectrale en fonction de ses composants. Si vous recevez une image d'un chien, le modèle de classification d'images peut interpréter ses caractéristiques principales et étiqueter l'image comme un "chien" facilement. Si une image contient deux objets, comme un chat et un chien, le modèle utilise un classificateur multi-étiquettes pour classer ces deux objets.
Le modèle de classification d'images n'accepte aucune variable pour la localisation des objets autre que la définition de la classe d'objet. C'est là que la détection d'objets intervient.
Un algorithme de détection d'objets peut identifier la classe d'objet et prédire l'emplacement exact des objets dans une image en dessinant des boîtes englobantes autour d'eux. C'est une combinaison de classification d'images et de localisation d'objets qui permet au système de savoir où les objets sont placés dans une image et pourquoi. Il permet à un système d'analyser visuellement chaque objet et de déterminer son application dans la vie réelle, tout comme les humains le font.
Modèles de détection d'objets
Les approches les plus préférées pour la détection d'objets sont l'apprentissage automatique ou l'apprentissage profond. Les deux méthodes fonctionnent en conjonction avec une machine à vecteurs de support (SVM) pour extraire les caractéristiques, entraîner l'algorithme, et catégoriser les objets.
La détection d'objets n'est pas possible sans un ensemble de données approprié. Les ensembles de données couvrent les principales caractéristiques connues d'un objet, telles que l'emplacement, les dimensions, la catégorie ou les couleurs. En pratique, si un modèle de détection d'objets est pré-entraîné sur un ensemble de données de quelque chose avec des roues, un pare-brise, des clignotants, un moteur et un coffre, il peut classer avec précision l'objet dans l'image donnée comme une voiture.
Différents types de méthodes de détection d'objets ont différents niveaux d'efficacité et d'applicabilité dans les industries. Comprenons cela en détail :
Apprentissage automatique
Le point positif de l'utilisation d'un algorithme d'apprentissage automatique pour effectuer la détection d'objets est qu'il repose sur des données saisies manuellement pour la classification, et non sur des données d'entraînement automatiques. Cela rend l'algorithme global moins sujet aux erreurs et plus stable.
La détection d'objets est un problème d'apprentissage automatique supervisé, ce qui signifie que vous devez utiliser des modèles pré-entraînés pour déclencher des détecteurs d'objets. La liste des classes dans l'ensemble de données d'entraînement d'un algorithme ML doit appartenir à une image spécifique ou à une liste d'images.
Les approches d'apprentissage automatique comme le traitement du langage naturel (NLP) identifient et classent les objets en fonction de leur intensité d'illumination par rapport à un arrière-plan. Les algorithmes ML pour les objets 2D peuvent également être réutilisés pour détecter des objets 3D dans les images.
Caractéristiques de canal agrégées (ACF)
L'ACF est une méthode d'apprentissage automatique qui reconnaît des objets spécifiques dans une image en fonction d'un ensemble de données d'images d'entraînement et des emplacements au sol des objets. Elle est principalement utilisée pour la détection d'objets multi-vues, comme l'identification d'objets 3D capturés à partir de trois appareils photo. Les véhicules d'auto-assistance, la détection de piétons et la détection de visages fonctionnent sur ce principe.
L'ACF combine différents canaux qui extraient des caractéristiques d'une image sous forme de gradients ou de pixels plutôt que de recadrer une image à divers endroits. Les canaux courants incluent le gris ou le RBG, selon la difficulté du problème de détection d'objets. L'ACF vous donne une compréhension plus riche des objets et accélère la vitesse de détection pour une plus grande précision.
Conseil : Pour créer un détecteur d'objets ACF, déclarez et définissez une fonction de programmation MATLAB, "trainACFObjectDetector()" et chargez les images d'entraînement. Testez la précision de la détection sur une image de test distincte.
Détection d'objets DPM
Le modèle de parties déformables (DPM) est une approche d'apprentissage automatique qui reconnaît les objets avec un mélange de modèles graphiques et de parties déformables de l'image. Il contient quatre composants principaux :
- Un filtre racine grossier définit plusieurs boîtes englobantes dans une image pour capturer les objets.
- Les filtres de parties couvrent les fragments des objets et les transforment en flèches de pixels plus sombres.
- Un modèle spatial stocke l'emplacement de tous les fragments d'objets par rapport aux boîtes englobantes dans le filtre racine.
- Un régressseur diminue la distance entre les boîtes englobantes et la vérité terrain pour prédire les objets avec précision.

Source: lilianweng.github.io/
Conseil : Extraire les caractéristiques importantes des objets saillants peut être utile lors de la collecte de données sur les chantiers de construction pour suivre l'avancement des travaux ou appliquer des normes de santé et de sécurité environnementales pendant le travail.
Apprentissage profond
Alors que les modèles d'apprentissage automatique sont construits sur la sélection manuelle des caractéristiques, les flux de travail d'apprentissage profond viennent avec une sélection automatique des caractéristiques pour s'adapter à votre pile technologique. Les approches d'apprentissage profond comme les modèles de réseaux neuronaux convolutifs produisent des prédictions d'objets plus rapides et plus précises. Bien sûr, vous avez besoin d'une unité de traitement graphique (GPU) plus élevée et de plus grands ensembles de données pour que cela se produise !
L'apprentissage profond est utilisé pour une variété de tâches de détection d'objets. Les caméras de surveillance vidéo modernes ou les systèmes de surveillance sont alimentés par des réseaux neuronaux pour détecter avec succès des visages ou des objets inconnus.
Voici quelques approches d'apprentissage profond pour aborder la détection d'objets.
Vous ne regardez qu'une fois (YOLO)
YOLO est un cadre de détection d'objets à une seule étape dédié aux applications industrielles. Son design efficace et sa haute performance le rendent convivial pour le matériel et efficace. C'est un CNN entraîné sur de grandes bases de données visuelles comme les réseaux d'images et peut être codé dans des éditeurs open-source en TensorFlow, Darknet ou Python.
YOLO produit des détections d'objets à la pointe de la technologie à une vitesse fulgurante de 45 images par seconde. À ce jour, différentes versions de YOLO, telles que YOLOv1, YOLOv2 ou YOLOv3, ont été lancées.
La dernière version, YOLOv6, peut être entraînée sur des ensembles de données personnalisés en PyTorch via des interfaces de programmation d'applications (API). Pytorch est un package Python et l'une des formes les plus préférées de recherche en apprentissage profond. YOLOv6 est exclusivement entraîné pour détecter les véhicules en mouvement sur la route.
Le saviez-vous ? YOLO ou les réseaux neuronaux convolutifs basés sur la région (R-CNN) utilisent la fonction de précision moyenne ou mAP(). Elle compare une boîte englobante au sol à une boîte détectée réelle et renvoie une probabilité ou un score de confiance. Plus le score est élevé, plus la prédiction est précise.
SSD (Single Shot Detector)
SSD est un détecteur d'objets personnalisé sans réseau de proposition de région spécifique (différentes parties d'une image regroupées dans un réseau) pour la prédiction d'objets. Il prédit l'emplacement et le type d'objet d'une image directement en un seul passage à travers une gamme de couches d'un modèle d'apprentissage profond.
SSD est bifurqué en deux parties :
1. Backbone
Le backbone du réseau de classification d'images pré-entraîné extrait les caractéristiques de l'image pour identifier l'image. Ces réseaux, comme ResNet, sont entraînés sur des ImageNets (grandes bases de données d'images) et séparés de la couche de classification d'images interne. Il laisse le modèle backbone comme un réseau neuronal profond, uniquement entraîné sur des millions d'images pour extraire des informations sémantiques de l'image d'entrée tout en préservant la structure spatiale de l'image.
Pour ResNet34, le backbone crée des cartes de caractéristiques 256x7x7 pour toute image d'entrée.
2. Tête
La tête du modèle de détection d'objets est juste une couche de cerveau de réseau neuronal ajoutée au backbone qui aide dans le processus de régression final de l'image. Elle produit l'emplacement spatial de l'objet et le combine avec la classe d'objet dans les étapes finales du SSD.
Source:developers.arcgis.com
Autres composants importants
Voici les composants importants qui composent un modèle SSD pour effectuer la détection d'objets en temps réel.
- Cellule de grille : Tout comme l'algorithme YOLO, l'algorithme SSD divise la boîte englobante en une grille 5x5. Chaque cellule de la grille est responsable de la sortie de la forme, de l'emplacement, de la couleur et de l'étiquette de l'objet qu'elle contient.
- Boîte d'ancrage : Comme le CNN divise l'image en une grille, chaque cellule de la grille se voit attribuer plus d'une boîte d'ancrage. Le modèle SSD utilise une technique de correspondance de modèles pendant la période d'entraînement pour faire correspondre la boîte englobante avec chaque objet de vérité terrain de l'image.

Source: pyimagesearch.com
Voici, la boîte englobante prédite est dessinée en rouge, tandis que la boîte englobante de vérité terrain (étiquetée à la main) est en vert. Comme il y a un haut degré de chevauchement, cette boîte d'ancrage est responsable de l'identification de la présence d'objets. L'Intersection sur Union (IoU) ici peut être mesurée comme
- Rapport d'aspect : Chaque objet a une forme et une configuration différentes. Certains sont plus ronds et plus grands, tandis que d'autres sont rétrécis et plus courts. L'architecture SSD aide à déclarer les rapports d'aspect à l'avance grâce à un paramètre de ratio.
- Niveau de zoom : Le paramètre de zoom peut agrandir les objets plus petits dans chaque cellule de grille pour identifier leur présence, leur catégorie et leur emplacement. Par exemple, si nous devons identifier un bâtiment et un parc depuis un hélicoptère, nous devons dimensionner l'algorithme SSD de manière à ce qu'il détecte à la fois les objets plus grands et plus petits.
- Champ réceptif : Le champ réceptif est défini comme l'ensemble de pixels en mouvement de l'image sur lequel l'algorithme travaille actuellement. Différentes couches d'un modèle CNN calculent différentes régions d'une image d'entrée. À mesure qu'il va plus en profondeur, la taille de l'objet augmente. Tout comme un microscope, un modèle CNN agrandit chaque pixel de l'objet pour calculer à quelle catégorie il appartient.
Intersection sur Union (IoU) : Aire de chevauchement / Aire d'union
EfficientNet
EfficientNet est une architecture de réseau neuronal convolutif qui échelonne uniformément toutes les dimensions d'un objet avant de les détecter. Ces réseaux neuronaux sont développés à un coût fixe de logiciels d'application. En ce qui concerne la disponibilité des ressources, les algorithmes EfficientNet peuvent être échelonnés dans un domaine d'application pour obtenir de meilleurs résultats de détection d'objets.
EfficientNet est considéré comme l'un des meilleurs modèles CNN existants pour la détection d'objets car il a atteint une précision à la pointe de la technologie sur des ensembles de données d'apprentissage comme Flowers (98,8%) tout en étant 6,1 fois plus rapide que d'autres modèles de détection d'objets.
Mask R-CNN
Cela étend Faster R-CNN en regroupant le réseau de proposition de région et le CNN pré-entraîné comme AlexNet. Un réseau de proposition de région est un réseau de régions séparées par des boîtes englobantes. Mask R-CNN extrait des caractéristiques de l'image et crée des cartes de caractéristiques pour détecter la présence d'objets. Il génère également un masque de haute qualité (boîte englobante) pour chaque objet afin de le séparer du reste.
Comment fonctionne Mask R-CNN ?
Mask R-CNN a été construit en utilisant Faster R-CNN et Fast R-CNN. Alors que Faster R-CNN a une couche softmax qui bifurque les sorties en deux parties, une prédiction de classe et un décalage de boîte englobante, Mask R-CNN est l'ajout d'une troisième branche qui décrit le masque de l'objet qui est la forme de l'objet. Il est distinct des autres catégories et nécessite l'extraction des coordonnées graphiques de l'objet pour prédire avec précision l'emplacement.
Mask R-CNN est une combinaison de deux CNN qui fonctionne en regroupant une couche de masque d'objet, également connue sous le nom de Région d'Intérêt (ROI), en parallèle avec le localisateur de boîte englobante existant.
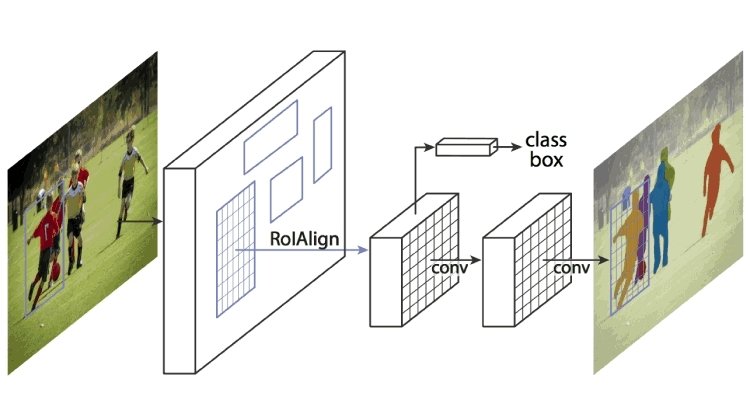
Source: viso.ai
Caractéristiques de Mask R-CNN
Discutons brièvement de quelques caractéristiques.
- C'est un modèle extrêmement simple à entraîner et fonctionne à une vitesse de 5 images par seconde (FPS)
- Il fonctionne miraculeusement bien pour détecter les visages humains dans différentes configurations.
- Il surpasse toutes les entrées de modèle unique sur chaque tâche de détection d'objets.
- Mask R-CNN peut facilement se généraliser à d'autres tâches. Il peut également être utilisé pour estimer les poses humaines dans un cadre particulier.
- Il sert de base solide pour créer des robots d'auto-assistance qui prédiront notre environnement futur.
Tous les algorithmes de détection d'objets supervisés dépendent des ensembles de données étiquetés, ce qui signifie que les humains doivent appliquer leurs connaissances pour entraîner le réseau neuronal sur différentes entrées. Les label_maps peuvent récupérer les objets étiquetés dans un ensemble de données () fonctions pour inférer la catégorie d'objet correcte.
Qu'est-ce que les cartes d'étiquettes ?
La fonction label-map() dans la programmation Tensorflow mappe les numéros de sortie à la classe d'objet. Si la sortie d'un algorithme de détection d'objets est 4, cette fonction scanne les données d'entraînement et renvoie la classe correspondant au numéro "4". Si "4" est mentionné comme "avion", le texte de sortie sera "avion".
Applications de la détection d'objets dans les industries
Jusqu'à présent, la détection d'objets a réalisé des exploits dans des domaines critiques comme la sécurité, le transport, le médical et l'armée. Les entreprises de logiciels l'utilisent pour récupérer et catégoriser automatiquement de grands ensembles de données relationnelles pour augmenter l'efficacité de la production. Ce processus est également connu sous le nom de étiquetage de données ou annotation de données.
Voici quelques applications réelles qui citent l'importance des systèmes de détection d'objets alimentés par l'IA :
- Police et médecine légale : La détection d'objets peut suivre et localiser des objets spécifiques tels qu'une personne, un véhicule ou un sac à dos d'une image à l'autre. Elle permet aux policiers et aux professionnels de la médecine légale d'inspecter chaque recoin d'un site de crime pour collecter des preuves. Cependant, en raison du grand volume de données, le processus de détection d'objets est un peu délicat et nécessite des heures de séquences pour identifier ce qui peut aider au succès d'une affaire.
- Encaissement sans contact : De nombreux restaurants utilisent le suivi d'objets RFID pour calculer le montant de l'addition en scannant les assiettes vides. Ce processus ajoute automatiquement le prix de tous les articles au total et élimine les transactions habituelles en espèces et par carte de crédit dans un restaurant.
- Inventaire et entreposage : Les professionnels de la logistique peuvent facilement détecter, classer et récupérer des produits finis pour le transport grâce à la détection d'objets en temps réel. Certaines entreprises ont même développé l'auto-entreposage pour naviguer plus facilement dans les rayons des entrepôts. Elle peut également automatiser et réguler la gestion de la chaîne d'approvisionnement en suivant les niveaux d'inventaire pour déterminer le flux de production optimal.
- Système de stationnement : Les détecteurs visuels pré-intégrés dans les voitures peuvent détecter les places de stationnement ouvertes dans les parkings de surface ou les garages. Ils peuvent également fournir au conducteur une vue avant et arrière de l'espace de stationnement et des autres véhicules pour garer la voiture en toute sécurité.
- Réponse aux catastrophes : Les récentes fluctuations de nos écosystèmes, telles que la détérioration de la couche d'ozone, l'augmentation des gaz à effet de serre et le réchauffement climatique, ont poussé les développeurs et les ingénieurs à créer des applications de détection d'objets. En ajustant finement les réseaux neuronaux et en utilisant des outils essentiels, des modèles rapides et précis peuvent être construits pour la réponse et la gestion des catastrophes.
- Reconnaissance biométrique et faciale : Les contrôles de sécurité dans les aéroports utilisent la reconnaissance faciale près des portes de départ pour attester de l'identité des voyageurs. Les dispositifs de reconnaissance faciale comparent les documents d'identité avec d'autres technologies biométriques, telles que les empreintes digitales, pour prévenir la fraude et le vol d'identité. Lors des transferts internationaux, les départements d'immigration et de douane utilisent des correspondances faciales pour comparer le portrait du voyageur avec la photo dans le passeport.
Top 5 des plateformes de reconnaissance d'images
*Ce sont les 5 principaux logiciels de reconnaissance d'images basés sur le rapport G2 Fall 2024 Grid en décembre 2024

Un bouclier pour la vision humaine
La détection d'objets n'est pas seulement le résultat de la génération de superordinateurs ; c'est aussi une promesse d'un avenir sécurisé pour l'humanité. En plus d'alimenter les machines avec une vision activée par l'IA, elle a découvert, analysé et démêlé nos problèmes mondiaux mieux que nous ne l'avons fait.
La détection d'objets n'est peut-être pas encore étendue. Mais elle a tracé le chemin initial du succès à travers les chaînes d'entreprises. Il n'y a pas de retour en arrière à partir d'ici.
Explorez comment l'IA se répand au-delà des limites avec les logiciels de synthèse vocale pour soutenir les malvoyants et améliorer l'accessibilité des données.Cet article a été publié à l'origine en 2022. Il a été mis à jour avec de nouvelles informations.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

