



J'ai utilisé Grammarly pour m'aider à écrire cet article. Grammarly a utilisé le traitement du langage naturel pour m'aider à rendre cet article excellent.
C'est à quel point les cas d'utilisation du traitement du langage naturel sont devenus répandus. Les technologies NLP ont parcouru un long chemin, de la rédaction d'un article et de la transcription d'appels de vente à la récupération de grandes quantités d'informations pertinentes et à la véritable compréhension de ce que l'utilisateur veut dire.
L'évolution de la linguistique computationnelle a facilité la compréhension des langues humaines par les machines, réduisant les écarts entre les interactions homme-ordinateur. Les logiciels de traitement du langage naturel améliorent l'expérience client, automatisent les saisies de données, améliorent les recommandations de recherche et renforcent les efforts de sécurité dans tous les secteurs.
Qu'est-ce que le traitement du langage naturel ?
Le traitement du langage naturel (NLP) est une technologie d'intelligence artificielle (IA) qui permet aux programmes informatiques d'interpréter le texte et les mots parlés pour mieux comprendre le langage humain.
Le NLP utilise des algorithmes d'apprentissage automatique (ML), la modélisation basée sur des règles et des modèles d'apprentissage profond pour aider les ordinateurs à traiter les données linguistiques afin d'analyser l'intention et le sentiment des messages.
Si vous avez utilisé la navigation GPS pour vous orienter dans une nouvelle ville ou crié à travers la pièce à un assistant vocal pour allumer les lumières – félicitations, vous avez rencontré un programme NLP !
Grâce au traitement du langage naturel, les applications informatiques peuvent répondre à des commandes vocales et résumer de grandes quantités de texte en temps réel pour interagir avec les humains de manière significative et expressive.
Comment fonctionne le NLP ?
Le NLP est partout autour de nous, même si nous ne le remarquons pas nécessairement. Les assistants virtuels, les chatbots de service client, les modèles de transformateurs, le texte prédictif – tout cela est rendu possible grâce à la technologie NLP qui comprend et filtre nos demandes. Les programmes font le lien entre les ordinateurs et les humains pour organiser les opérations commerciales, revitalisant la productivité grâce à des interactions finement réglées.
Les techniques de formation NLP reposent sur l'apprentissage profond et les algorithmes pour interpréter et donner un sens au langage humain.
Les modèles d'apprentissage profond traitent des données non structurées ou des données qualitatives qui ne peuvent pas être analysées à l'aide d'outils conventionnels tels que la voix et le texte. Ils les transforment en données structurées qui peuvent s'intégrer dans des bases de données que nous connaissons pour fournir des informations exploitables.
Le traitement du langage naturel extrait des informations contextuelles en décomposant le langage en mots individuels et en identifiant leurs relations. Cela permet un processus d'indexation et de segmentation plus précis – basé sur le sentiment et l'intention.
Avant qu'un modèle puisse traiter des données textuelles, il doit les prétraiter dans un format que la machine peut comprendre. Il existe plusieurs techniques de traitement des données disponibles.
Tokenisation
La tokenisation, première étape pour convertir les données brutes en un format que la machine peut saisir, consiste à diviser le texte en unités plus petites appelées tokens. La machine comprend facilement le texte une fois qu'il est décomposé en mots ou en phrases. Comme les machines ne comprennent que les données numériques, le texte tokenisé est représenté sous forme de tokens numériques pour les programmes.
Exemple :
Considérez le texte suivant saisi par un utilisateur :
"Il y a une banque de l'autre côté du pont."
Texte compris par la machine après tokenisation :
["Il", "y", "a", "une", "banque", "de", "l'autre", "côté", "du", "pont", "."]
Suppression des mots vides
La prochaine étape de prétraitement dans le NLP consiste à supprimer les mots courants ayant peu ou pas de signification spécifique dans le texte. Ces mots, appelés mots vides, incluent les articles (le/la/un), "est", "et", "sont", et ainsi de suite. Cette étape élimine les mots non utiles et fournit une compréhension significative, efficace et précise du texte.
Exemple :
Considérez le même exemple de texte saisi par un utilisateur :
"Il y a une banque de l'autre côté du pont."
Texte compris par la machine après suppression des mots vides :
["Il", "banque", "côté", "pont", "."]
Racinisation et lemmatisation
La racinisation et la lemmatisation se réfèrent aux techniques utilisées par les applications NLP pour simplifier les mots et l'analyse de texte en les réduisant à leur forme de base.
La racinisation est une approche basée sur des règles qui supprime les préfixes et les suffixes pour ramener les mots à leurs formes fondamentales ou racines. Le processus ne nécessite pas beaucoup de puissance de calcul, et les mots de base résultants peuvent ne pas toujours avoir de sens, mais ils aident le programme à faciliter l'analyse de texte.
Par exemple, le mot "partageant" donnera une racine "partag".
Une limitation de la racinisation est que plusieurs mots sémantiquement non liés peuvent actionnaire partager une même racine.
La lemmatisation est une approche basée sur le dictionnaire pour convertir les mots en leur forme morphologique, alias lemme. Le processus nécessite un effort de calcul élevé en raison de la nécessité de recherches dans le dictionnaire. Le lemme résultant sera toujours un mot valide contextuellement et en tant que partie du discours.
Par exemple, le mot "partageant" donnera un lemme "partager".
Extraction de caractéristiques
Comme nos amis machines ne comprennent que les nombres et les algorithmes, le texte brut que nous saisissons doit être converti en représentations numériques. L'extraction de caractéristiques aide à conserver les informations pertinentes tout en réduisant simultanément la complexité des données pour capturer uniquement les motifs et relations les plus nécessaires.
Différentes techniques peuvent être utilisées pour atteindre ce résultat en fonction de la tâche NLP.
- Sac de mots ne considère que la présence ou l'absence de mots en créant un espace vectoriel du texte. La représentation du texte se fait par la fréquence des mots plutôt que par l'ordre des mots.
- Fréquence des termes-Inverse Fréquence des Documents (TF-IDF) prend en compte l'importance de chaque mot dans l'ensemble de données. Les mots fréquemment utilisés ont plus de valeur.
- Incorporations de mots capturent les relations sémantiques entre les mots, créant une représentation vectorielle dense. Des exemples incluent Word2Vec et GloVe.
- Modélisation de sujets extrait des sujets similaires du texte pour représenter des documents distribués par sujet. Un exemple de cette technique inclut l'Allocation de Dirichlet Latente (LDA).
Les algorithmes NLP sont généralement basés sur des règles ou formés sur des modèles d'apprentissage automatique. Une formation continue et des boucles de rétroaction peuvent créer de grands réservoirs de connaissances, mieux prédire l'intention humaine et minimiser les réponses erronées.
Quelles sont les tâches NLP courantes ?
Le traitement du langage naturel utilise des techniques ou des tâches d'IA pour traiter, comprendre et générer un langage naturel (humain). Elles améliorent l'interaction homme-ordinateur et facilitent une communication efficace grâce à des applications basées sur le langage.
Étiquetage des parties du discours
Vous savez qui n'a pas oublié ses leçons de grammaire de 6e année ? Le NLP.
L'étiquetage des parties du discours (POS), ou étiquetage grammatical, permet aux applications NLP d'identifier les mots individuels dans une phrase pour déterminer leur signification dans le contexte de cette phrase. Cela permet aux ordinateurs de faire la différence entre les noms, les verbes, les adjectifs et les adverbes et de comprendre leurs relations.
Comme le montre l'exemple ci-dessous, l'étiquetage POS signifie que les programmes NLP ont le pouvoir de contextualiser le verbe "aimer" dans la phrase "J'aime la plage" et d'identifier "aimer" comme un adverbe dans la phrase "Je suis comme Mark."
.png)
Désambiguïsation du sens des mots
Le concept n'est pas aussi compliqué qu'il n'y paraît ; cela signifie simplement que les programmes NLP peuvent identifier le sens voulu du même mot lorsqu'il est utilisé dans différents contextes.
Grâce à l'analyse sémantique (c'est-à-dire l'extraction de sens à partir de texte et l'analyse), les ordinateurs peuvent interpréter les phrases et les relations entre les mots individuels pour donner le plus de sens dans un contexte particulier.

Le mot "bark" dans l'exemple ci-dessus a deux significations différentes.
Les applications NLP distinguent entre l'aboiement d'un chien et l'écorce d'un arbre grâce à la désambiguïsation du sens des mots.
Reconnaissance d'entités nommées
Les applications de traitement du langage naturel peuvent identifier des mots pour des catégories spécifiques, telles que les noms de personnes, les lieux et les noms d'organisations. Grâce à la reconnaissance d'entités nommées (NER), le logiciel NLP extrait des entités et comprend leur relation avec le reste du texte.
.png)
Dans l'exemple ci-dessus, la tâche NLP de reconnaissance d'entités nommées identifie "Microsoft" et "Bill Gates" comme une organisation et une personne, respectivement.
Applications de la reconnaissance d'entités nommées
- Extraction de faits à partir de fausses nouvelles : La NER peut identifier des entités importantes qui peuvent aider à vérifier les sources d'information.
- Récupération d'informations : Pour aider à créer des systèmes de récupération où les utilisateurs peuvent rechercher des informations spécifiques pour accéder à des documents pertinents.
Résolution de coréférence
Les tâches NLP de haut niveau telles que la réponse aux questions et la récupération d'informations (plus à ce sujet plus tard) nécessitent que les ordinateurs identifient tous les mots qui se réfèrent à la même entité. Ce processus, connu sous le nom de résolution de coréférence, aide les programmes à déterminer les personnes/objets connectés à des pronoms spécifiques.
La résolution de coréférence est également la raison pour laquelle les ordinateurs savent quand une expression idiomatique fait partie d'un texte.
Reconnaissance vocale
Les programmes NLP bénéficient de la compréhension du processus de conversion du langage parlé en – plus ou moins – langage informatique. La reconnaissance vocale est essentielle pour faciliter des interactions homme-ordinateur naturelles et intuitives.
Voyons quelques exemples de reconnaissance vocale dans le cadre du traitement du langage naturel.
- Assistants vocaux : Nos meilleurs amis virtuels Siri, Alexa et Google Assistant répondent à nos commandes en utilisant des techniques de reconnaissance vocale pour fournir des réponses pertinentes.
- Transcription et dictée : Les transcriptions d'enregistrements audio et les conversions de langage parlé en texte sont fondamentales pour la création de contenu, les secteurs juridiques et éducatifs.
- Prétraitement des données : La reconnaissance vocale est importante pour transformer les données brutes en une forme plus compréhensible. Le prétraitement peut être effectué pour les données audio et textuelles.
Récupération d'informations
Les programmes NLP trouveront toujours ce document important juste quand vous en avez besoin grâce à leur puissante capacité à récupérer des informations à partir de grands ensembles de données. L'objectif de la récupération d'informations en tant que tâche NLP est d'offrir aux utilisateurs des informations précises et utiles à partir de collections de textes grâce à l'extraction de texte.
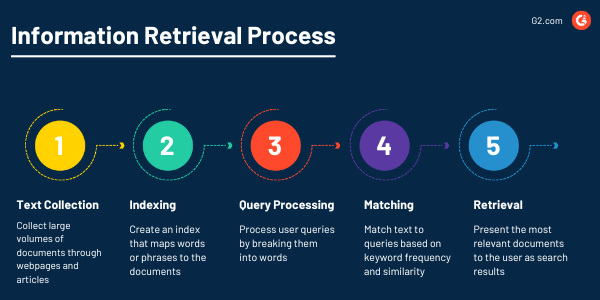
Analyse de sentiment
Vous vous êtes déjà demandé comment les bots de service client peuvent presque toujours deviner comment vous vous sentez ? C'est grâce à l'analyse de sentiment – un processus automatisé qui reconnaît le ton émotionnel et les sentiments exprimés dans divers cas d'utilisation.
Les modèles d'apprentissage automatique peuvent être formés à l'analyse de sentiment en utilisant la classification de l'étiquetage des sentiments (positif, négatif, neutre), le post-traitement et l'évaluation des sentiments.
L'analyse de sentiment est un excellent moyen pour les entreprises d'obtenir des informations sur les clients grâce aux avis sur les produits et de surveiller leurs marques en fonction des sentiments sur les réseaux sociaux.
Traduction automatique
La tâche NLP de traduction automatique de texte ou de contenu parlé d'une langue à une autre est largement utilisée dans les logiciels de traduction automatique. La traduction automatique vise à fournir des traductions précises et cohérentes tout en maintenant la précision contextuelle.
Les modèles de traduction utilisent également la reconnaissance vocale. Ils sont conçus pour améliorer la communication mondiale et briser les barrières linguistiques dans les affaires, l'éducation, la santé et les relations internationales.
Détection de spam
Vous avez déjà pensé qu'un e-mail était légitime et y avez répondu, mais c'était juste du spam ? Moi aussi.
La tâche NLP de reconnaissance automatique des messages non pertinents dans un grand groupe de messages, tels que les e-mails et les publications sur les réseaux sociaux, et de les supprimer s'appelle la détection de spam.
Le processus aide à distinguer les messages frauduleux des messages authentiques et garantit la sécurité des utilisateurs sur les plateformes de communication.
Bibliothèques et frameworks NLP
Les langages de programmation sont au NLP ce qu'un papillon de nuit est à une flamme. Bien que de nombreux langages et bibliothèques prennent en charge les tâches de traitement du langage naturel, quelques-uns sont populaires.
Python
Le langage de programmation le plus utilisé pour les tâches NLP, les bibliothèques et les frameworks d'apprentissage profond est écrit pour Python.
- Natural Language Toolkit (NLTK) : L'une des premières bibliothèques NLP écrites en Python, le NLTK est connu pour ses interfaces faciles à utiliser et ses bibliothèques de traitement de texte pour l'étiquetage, la racinisation et l'analyse sémantique.
- spaCy : Une bibliothèque NLP open-source, spaCy fournit des vecteurs pré-entraînés. Vous pouvez l'utiliser pour la NER, l'étiquetage des parties du discours, la classification et l'analyse morphologique.
- Bibliothèques d'apprentissage profond : PyTorch et TensorFlow sont des outils courants pour développer des modèles de données NLP.
R
Les statisticiens utilisent largement le langage de programmation pour les modèles NLP de calcul statistique et de graphiques écrits en R. Cela inclut Word2Vec et TidyText.
Applications commerciales du NLP
Les techniques de traitement du langage naturel sont utilisées dans de nombreux cas d'affaires pour améliorer l'efficacité opérationnelle, la productivité et les processus critiques pour la mission.
Chatbots et assistants virtuels
L'essor de l'IA conversationnelle a transformé la façon dont les chatbots et les assistants virtuels interagissent avec les humains, en particulier dans le service client.
Le NLP alimente les capacités humaines des chatbots pour étendre le support client automatisé tout en maintenant des opérations économiques. Les bots de chat et de voix peuvent offrir des recommandations personnalisées et des fonctionnalités de chat localisées pour aider dans le processus d'achat, répondre aux FAQ et assister les utilisateurs en temps réel.
Les fonctionnalités de conversion de la parole en texte sont également bénéfiques pour suivre les analyses des centres d'appels afin de transcrire les données vocales en texte.
Surveillance des réseaux sociaux
L'analyse de sentiment sur les plateformes sociales aide à évaluer les retours et avis des clients pour comprendre la satisfaction des consommateurs grâce à des informations précieuses sur les données.
Les outils de surveillance des réseaux sociaux sont alimentés par le traitement du langage naturel pour offrir des fonctionnalités d'écoute, de suivi et de collecte de contenu. Ces applications sont largement utilisées pour effectuer des recherches de marché, suivre l'analyse des tendances et identifier des motifs sur différents réseaux sociaux.
Extraction d'informations et détection de fraude
Les industries de la santé et du droit utilisent la technologie NLP pour extraire des informations de haute qualité et pertinentes à partir de grands volumes de données d'essais cliniques, de littérature scientifique et de contrats juridiques.
Comme pour la détection de spam, la technologie NLP peut détecter les activités frauduleuses en percevant des motifs dans les données. Cela est particulièrement utile dans le secteur financier pour surveiller les transactions.
NLP vs. NLU vs. NLG
Bien qu'il n'y ait qu'un seul terme différenciant dans le traitement du langage naturel, la compréhension du langage naturel et la génération du langage naturel, quelques différences existent entre les trois concepts.
Traitement du langage naturel
Le NLP est une branche de l'IA qui aide les ordinateurs à comprendre, interpréter et générer le langage humain. Les tâches NLP courantes incluent la reconnaissance vocale, l'analyse de sentiment et la reconnaissance d'entités nommées.
Le NLP est largement utilisé dans l'assistance vocale pour résumer de grandes quantités de texte et les services de traduction.
Compréhension du langage naturel (NLU)
Un sous-ensemble du NLP, le logiciel NLU se concentre sur la compréhension du texte pour extraire le sens des données. Il combine la logique logicielle, la linguistique, le ML et l'IA pour donner un sens au langage naturel.
Les tâches NLU courantes incluent :
- Reconnaissance d'intention. Les modèles NLU sont utilisés pour identifier l'intention de différentes entités à des fins de classification et de catégorisation de texte. Par exemple, créer différentes sections pour les actualités, le divertissement et les affaires d'une entreprise.
- Analyse de contenu. Comprendre les connexions entre les morceaux de contenu, le NLU peut effectuer une analyse approfondie des entités pour mettre en évidence des sentiments et des relations complexes.
- Recherche cognitive. Le NLU analyse et extrait des données non structurées, lui permettant de tirer des informations pertinentes à partir de divers ensembles de données. Cela améliore les résultats des requêtes de recherche et fournit des informations pertinentes sur l'intention à l'aide de l'analyse prédictive.
Top 5 des logiciels NLU
1. Amazon Comprehend2. IBM Watson Natural Language Classifier
3. Azure Translator Speech API
4. Azure Translator Text API
5. Apace cTAKES
*Ces données ont été extraites du rapport G2 Summer Grid le 19 juillet 2023, basé sur notre méthodologie de notation.
Génération du langage naturel (NLG)
À l'autre extrémité du NLU se trouve la technologie NLG, la branche de l'IA qui génère du texte écrit ou parlé à partir d'un ensemble de données. Elle permet aux ordinateurs de fournir des retours aux humains dans un langage compréhensible pour nous, pas pour les machines.
Les tâches NLG courantes incluent :
- Conversion de données. Les modèles NLG convertissent les données structurées en textes lisibles par les humains.
- Interactions avec les clients. Ceux-ci fournissent des réponses sonnant comme un langage naturel, un appariement des sentiments et des communications client personnalisées.
Top 5 des logiciels NLG
1. Anyword2. Quill
3. AX Semantics
4. Wordsmith
5. Phrazor by vPhrase
*Ces données ont été extraites du rapport G2 Summer Grid le 19 juillet 2023, basé sur notre méthodologie de notation.

Déverrouiller le mystère du langage naturel
Bien que le NLP puisse sembler être un sorcier, il ne l'est pas. Il combine diverses capacités computationnelles puissantes le rendant utile dans de nombreuses tâches qui rendent les tâches humaines plus efficaces.
Que ce soit à travers les salutations des chatbots ou la synthèse de texte, le monde du NLP continue de s'efforcer de fournir des informations précieuses à partir de grands ensembles de données de langage humain. Les technologies NLP rendent nos vies personnelles et professionnelles plus engageantes, personnalisées et interactives alors que nous naviguons dans notre nouveau monde centré sur les données.
L'une des fonctionnalités NLP les plus populaires est son utilisation dans les assistants vocaux. En savoir plus sur le fonctionnement de la reconnaissance vocale et les fonctionnalités qu'elle offre qui vous permettent de crier des commandes.
Cet article a été publié à l'origine en 2019. Il a été mis à jour selon de nouvelles directives éditoriales, avec de nouvelles ressources et des exemples récents.

Aayushi Sanghavi
Aayushi Sanghavi is a Campaign Coordinator at G2 for the Content and SEO teams at G2 and is exploring her interests in project management and process optimization. Previously, she has written for the Customer Service and Tech Verticals space. In her free time, she volunteers at animal shelters, dances, or attempts to learn a new language.

