



Avec l'avènement de l'automatisation, le volume, la taille et la vitesse des données évoluent constamment. La plus grande préoccupation des équipes de données est désormais de gérer cette énorme quantité de données. L'augmentation des quantités de données entraîne le besoin de les entreposer. Le processus d'entreposage de données se compose de trois étapes de base : extraire, transformer et charger, généralement effectuées à l'aide d'outils ETL.
Les outils ETL ont de nombreuses utilisations commerciales. Traditionnellement, les données étaient plus statiques et l'architecture système était monolithique. L'ETL était effectué par lots, et le processus prenait une demi-journée à une journée entière pour se terminer. L'un des premiers cas d'utilisation de l'ETL était de créer des rapports analytiques. Récemment, les analystes de données ont découvert que les données sont opérationnelles, comme les données obtenues à partir des transactions quotidiennes.
ETL vs. ELT vs. Reverse ETL
L'architecture actuelle de l'entrepôt de données effectue le processus ETL en trois étapes simples. Les données présentes sous diverses formes comme des fichiers plats, des bases de données et des services web sont extraites de plusieurs sources, puis transmises pour transformation ou traitement. À cette étape, les données sont nettoyées et traitées, après quoi elles sont chargées dans l'entrepôt. Le processus d'ETL se termine par un data mart qui est présent au sommet de l'entrepôt de données.
Qu'est-ce qu'un data mart ?
Un data mart est un dépôt de données hautement structuré où les données sont stockées et gérées jusqu'à ce qu'elles soient nécessaires. Il stocke des bases de données orientées sujet pour des fonctions commerciales spécifiques, comme le marketing, la finance, les opérations, etc.
|
Conseil : L'entrepôt de données diffère des data marts à cet égard. Les entrepôts agissent comme un dépôt central et transmettent les données aux data marts au besoin. |
L'ELT, en revanche, implique les mêmes processus mais dans un ordre différent. Les données sont extraites de diverses sources, puis chargées dans l'entrepôt. Les données sont ensuite traitées selon les différentes utilisations commerciales avant d'être utilisées.
Reverse ETL est un renversement exact du processus ETL. Le besoin de visibilité constante des données clients à travers tous les systèmes a donné naissance à l'émergence du reverse ETL. Cet outil est utilisé pour envoyer des données en temps réel à divers systèmes SaaS. Par exemple, envoyer des données de l'entrepôt à Salesforce pour suivre la liste de tous les clients de haut niveau.

Source : Deloitte
ETL/ELT et Reverse ETL sont deux faces d'une même pièce : l'un est utilisé pour l'intégration des données, et l'autre pour les opérations de données.
L'ELT gagne en popularité
Traditionnellement, l'approche des bases de données a toujours été le schéma à l'écriture : les points de données devaient être donnés un modèle avant le stockage. Lorsque les utilisateurs voulaient récupérer des données, elles étaient déjà dans un format gérable. Cette pratique visait à maintenir la cohérence. Cependant, avec le temps et la quantité de données, cela est apparu comme restrictif. Même des données légèrement non structurées étaient rejetées car elles ne correspondaient pas au modèle. Les outils ETL suivaient le schéma à l'écriture. Les experts en informatique ont réalisé que les données brutes ou moins structurées étaient également précieuses pour l'organisation. Et pour en extraire de la valeur, il était nécessaire de modifier l'approche des bases de données. Ainsi est venu le schéma à la lecture.

Le schéma à la lecture permet de stocker à la fois des données non structurées et structurées sur le système et de les formater à chaque récupération. Les outils ELT suivent cette approche pour rendre les données utiles et sont plus flexibles à utiliser. Initialement, les données étaient stockées sur des serveurs sur site ; ainsi, le stockage des données était bien plus coûteux qu'aujourd'hui. De nombreux outils ELT et ETL fonctionnent aujourd'hui main dans la main avec des entrepôts de données cloud qui s'adaptent automatiquement aux volumes de données. Avec l'arrivée des entrepôts de données cloud, le stockage des données est possible à faible coût. Les outils ETL et ELT sont des moyens d'intégration des données utilisant différentes approches.
Le reverse ETL remplacera-t-il l'ETL/ELT ?
Maintenant que nous savons exactement ce que font les outils ETL et ELT, il est temps d'approfondir le reverse ETL. Certaines personnes peuvent se demander, s'il existe déjà deux approches pour stocker des données dans l'entrepôt, pourquoi aller à l'envers ? Est-ce pour remplacer l'ETL et l'ELT ?
La réponse courte est non. Les entreprises ont des tonnes de données qui se trouvent dans l'entrepôt et restent inutilisées. Elles doivent être rendues visibles pour savoir quelle valeur elles ont à offrir et être activées. Bien que les data scientists aient construit des plateformes de données clients (CDP) qui intègrent toutes les données clients sous un même toit, cela ne peut être qu'une solution partielle pour découvrir les données cachées. C'est là que les entreprises ont besoin du reverse ETL.
Alors que les outils ETL et ELT fournissent aux fonctions commerciales des données propres et traitées, il est crucial de comprendre si elles peuvent réellement utiliser ces données pour prendre des décisions. Par exemple, alors que les équipes marketing peuvent stocker des données dans Hubspot pour des campagnes, le reverse ETL aide ces équipes à accéder aux données liées aux campagnes pour rendre le ciblage plus spécifique. De même, une base de données de clients dans Salesforce aide les équipes de vente à les cibler avec des messages spécifiques. De nombreux outils de reverse ETL déplacent les données des entrepôts de données vers divers CRM pour que différentes fonctions commerciales accèdent à ces données et prennent des décisions. Le reverse ETL rend les données plus opérationnelles et les enrichit pour les rendre pertinentes pour les clients.
Les outils de reverse ETL aident à briser les silos et donnent à diverses équipes la visibilité sur les données requises, remplissant l'activation des données. L'analytique opérationnelle est une approche émergente pour utiliser les données ; c'est exactement ce que fait le reverse ETL. Les entreprises doivent sortir les données des silos centralisés et les mettre dans diverses fonctions commerciales.
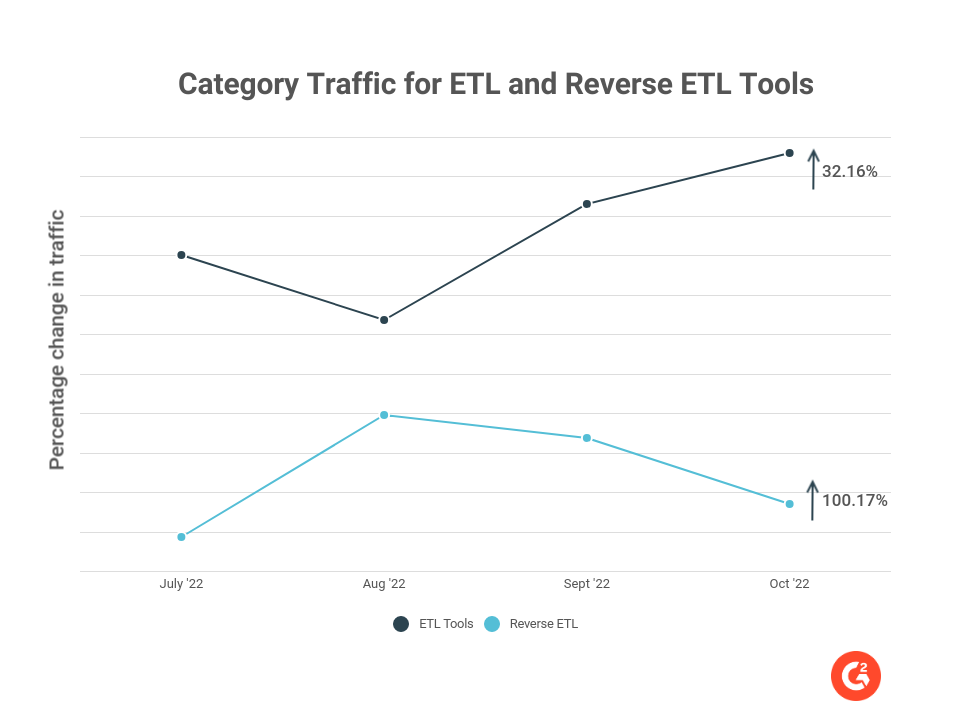
La catégorie nouvellement créée Reverse ETL sur G2 a connu une croissance du trafic depuis sa création. Les acheteurs ont montré de l'intérêt pour les outils ETL et reverse ETL, ce qui est évident à partir du trafic sur G2. Le trafic vers la catégorie Reverse ETL sur G2 a connu une croissance de plus de 100 % depuis sa création. Le trafic vers la page de catégorie Outils ETL sur G2 augmente régulièrement — 32 % depuis juillet 2022. Il est clair que les entreprises sont intéressées à essayer la combinaison des outils, ce que nous voyons comme une tendance future dans l'espace ETL.
L'avenir des outils ETL
Le processus ETL est utilisé depuis les anciennes méthodes d'entreposage de données, et celles-ci ont évolué au fil du temps. L'ELT est l'approche moderne pour stocker des données en utilisant des ressources évolutives, tandis que le reverse ETL enrichit les systèmes externes avec des données nettoyées en utilisant ETL/ELT.
Une combinaison d'ETL/ELT et de reverse ETL peut aider les organisations à tirer de meilleurs insights des données qu'elles obtiennent. Les équipes centrées sur les opérations peuvent accéder à ces données nettoyées pour lancer de nouvelles campagnes de vente et de marketing et copier les données dans les applications.
Édité par Jigmee Bhutia
Vous voulez en savoir plus sur Outils ETL ? Découvrez les produits Outils ETL.

Shalaka Joshi
Shalaka is a Senior Research Analyst at G2, with a focus on data and design. Prior to joining G2, she has worked as a merchandiser in the apparel industry and also had a stint as a content writer. She loves reading and writing in her leisure.

