



Supposons que vous gériez une grande librairie en ligne. Elle est toujours ouverte. Chaque minute ou seconde, des clients passent et paient des commandes. Votre site web doit exécuter rapidement de nombreuses transactions en utilisant des données modestes, telles que des identifiants d'utilisateur, des numéros de carte de paiement et des informations de commande.
En plus d'effectuer les tâches quotidiennes, vous devez également évaluer vos performances. Par exemple, vous analysez les ventes d'un livre ou d'un auteur spécifique du mois précédent pour décider s'il faut en commander davantage pour ce mois-ci. Cela implique de recueillir des données transactionnelles et de les transférer d'une base de données supportant les transactions à un autre système gérant de grandes quantités de données. Et, comme c'est souvent le cas, les données doivent être transformées avant d'être chargées dans un autre système de stockage.
Ce n'est qu'après ces séries d'actions que vous pouvez examiner les données avec un logiciel dédié. Comment déplacer les données, cependant ? Si vous ne connaissez pas la réponse, vous avez probablement besoin d'une meilleure infrastructure logicielle, comme des solutions d'échange de données, des outils d'extraction, transformation, chargement (ETL), ou des solutions DataOps.
Vous devez probablement apprendre ce qu'un pipeline de données peut faire pour vous et votre entreprise. Vous devez probablement continuer à lire.
Qu'est-ce qu'un pipeline de données ?
Un pipeline de données est un processus qui implique l'ingestion de données brutes provenant de nombreuses sources de données, puis leur transfert vers un dépôt de données, tel qu'un lac de données ou un entrepôt de données, pour analyse.
Un pipeline de données est un ensemble d'étapes pour le traitement des données. Si les données doivent encore être importées dans la plateforme de données, elles sont ingérées au début du pipeline. Une succession d'étapes suit, chacune produisant une sortie qui sert d'entrée pour l'étape suivante. Cela continue jusqu'à ce que l'ensemble du pipeline soit construit. Des étapes indépendantes peuvent coïncider dans certains cas.
Composants du pipeline de données
Avant de plonger dans le fonctionnement interne des pipelines de données, il est essentiel de comprendre leurs composants.
- L'origine est le point d'entrée des données de toutes les sources de données dans le pipeline. La plupart des pipelines proviennent d'applications de traitement transactionnel, d'interfaces de programmation d'applications (API), ou de capteurs d'appareils Internet des objets (IoT) ou de systèmes de stockage tels que des entrepôts de données ou des lacs de données.
- La destination est le dernier endroit où vont les données. Le cas d'utilisation détermine la destination finale.
- Le flux de données est le transport des données de la source à la destination et les modifications qui y sont apportées. L'ETL est l'une des méthodologies de flux de données les plus souvent utilisées.
- Le stockage fait référence aux systèmes qui conservent les données à divers stades au fur et à mesure qu'elles traversent le pipeline.
- Le traitement comprend toutes les activités et étapes impliquées dans la consommation, le stockage, la modification et le placement des données. Bien que le traitement des données soit lié au flux de données, cette étape se concentre sur la mise en œuvre.
- Le flux de travail spécifie une série de processus et leurs dépendances les uns par rapport aux autres.
- La surveillance garantit que le pipeline et ses étapes fonctionnent correctement et exécutent les fonctions nécessaires.
- La technologie fait référence à l'infrastructure et aux outils qui soutiennent la transmission des données, le traitement, le stockage, le flux de travail et la surveillance.
Vous voulez en savoir plus sur Outils ETL ? Découvrez les produits Outils ETL.
Comment fonctionne le pipeline de données ?
Les données sont généralement traitées avant de s'écouler dans un dépôt. Cela commence par la préparation des données, où les données sont nettoyées et enrichies, suivie de la transformation des données pour filtrer, masquer et agréger les données pour leur intégration et leur uniformité. Cela est particulièrement important lorsque la destination finale de l'ensemble de données est une base de données relationnelle. Les bases de données relationnelles ont un schéma prédéfini qui doit être aligné pour faire correspondre les colonnes et les types de données afin de mettre à jour les anciennes données avec les nouvelles.
Imaginez que vous collectiez des informations sur la façon dont les gens interagissent avec votre marque. Cela pourrait inclure leur localisation, leur appareil, les enregistrements de session, les achats et l'historique des interactions avec le service client. Ensuite, vous mettez toutes ces informations dans un entrepôt pour créer un profil pour chaque consommateur.
Comme son nom l'indique, les pipelines de données servent de "tuyau" pour les projets de science des données ou les tableaux de bord de business intelligence. Les données proviennent de diverses sources, y compris des API, des bases de données de langage de requête structuré (SQL) ou NoSQL ; cependant, elles ne sont pas toujours adaptées à une utilisation instantanée.
Les scientifiques ou ingénieurs en données effectuent généralement des tâches de préparation des données. Ils formatent les données pour répondre aux exigences du cas d'utilisation commercial. Une combinaison d'analyse exploratoire des données et des besoins commerciaux établis détermine souvent le type de traitement des données qu'un pipeline nécessite. Les données peuvent être conservées et mises en avant lorsqu'elles sont correctement filtrées, combinées et résumées.
Des pipelines de données bien organisés sont la base de diverses initiatives, y compris l'analyse exploratoire des données, la visualisation et les activités d'apprentissage automatique (ML).
Types de pipelines de données
Le traitement par lots et le streaming de données en temps réel sont les deux types de base de pipelines de données.
Traitement par lots de données
Comme son nom l'indique, le traitement par lots charge des "lots" de données dans un dépôt à des intervalles prédéterminés, souvent planifiés pendant les heures creuses. D'autres charges de travail ne sont pas dérangées puisque les travaux de traitement par lots fonctionnent généralement avec d'énormes quantités de données, ce qui pourrait alourdir l'ensemble du système. Lorsqu'il n'y a pas de besoin urgent d'examiner un ensemble de données spécifique (par exemple, la comptabilité mensuelle), le traitement par lots est le meilleur pipeline de données. Il est associé au processus d'intégration de données ETL.
L'ETL a trois étapes :
- Extraction : obtenir des données brutes d'une source, telle qu'une base de données, un fichier XML ou une plateforme cloud contenant des données pour des outils de marketing, des systèmes CRM ou des systèmes transactionnels.
- Transformation : changer le format ou la structure de l'ensemble de données pour correspondre au système cible.
- Chargement : transférer l'ensemble de données vers le système de destination, qui pourrait être une application ou une base de données, un data lakehouse, un lac de données ou un entrepôt de données.
Streaming de données en temps réel
Contrairement au traitement par lots, le streaming de données en temps réel signifie que les données doivent être continuellement mises à jour. Les applications et les systèmes de point de vente (PoS), par exemple, nécessitent des données en temps réel pour mettre à jour l'inventaire et l'historique des ventes de leurs articles ; cela permet aux commerçants d'informer les consommateurs si un produit est en stock. Une seule action, telle qu'une vente de produit, est appelée un "événement", et les occurrences connexes, telles que l'ajout d'un article au panier, sont généralement regroupées en un "sujet" ou un "flux". Ces événements sont ensuite acheminés via des systèmes de messagerie ou des courtiers de messages, tels qu'Apache Kafka, un produit open-source.
Les pipelines de données en streaming offrent une latence plus faible que les systèmes par lots car les événements de données sont traités immédiatement après leur occurrence. Cependant, ils sont moins fiables que les systèmes par lots car des messages peuvent être manqués par inadvertance ou passer beaucoup de temps dans la file d'attente. Les courtiers de messages aident à résoudre ce problème avec des accusés de réception, ce qui signifie qu'un consommateur vérifie le traitement du message au courtier afin qu'il puisse être retiré de la file d'attente.
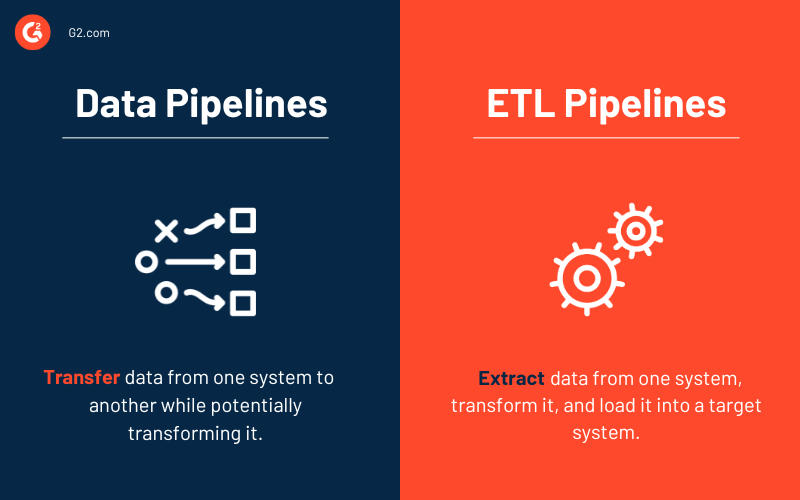
Pipelines de données vs. pipelines ETL
Certains mots, tels que pipeline de données et pipeline ETL, peuvent être utilisés de manière interchangeable. Cependant, considérez un pipeline ETL comme un sous-type du pipeline de données. Trois caractéristiques fondamentales séparent les deux types de pipelines.
- Les pipelines ETL suivent un ordre prédéterminé. Comme le suggère l'acronyme, ils extraient, convertissent, chargent et stockent les données dans un dépôt. Cet ordre n'est pas requis pour tous les pipelines de données. En fait, l'émergence de solutions cloud-native a augmenté l'utilisation des pipelines ETL. L'ingestion de données vient toujours en premier avec ce type de pipeline, mais toutes les transformations viennent après que les données ont été chargées dans l'entrepôt de données cloud.
- Bien que la portée des pipelines de données soit plus grande, les pipelines ETL impliquent fréquemment un traitement par lots. Ils pourraient également inclure le traitement en flux.
- Enfin, contrairement aux pipelines ETL, les pipelines de données dans leur ensemble peuvent ne pas toujours nécessiter de transformations de données. Presque tous les pipelines de données utilisent des transformations pour faciliter l'analyse.
Architecture du pipeline de données
La conception d'un pipeline de données comprend trois phases clés.
- Ingestion des données. Les données sont acquises à partir de nombreuses sources, y compris des données structurées et non structurées. Ces sources de données brutes sont communément appelées producteurs, éditeurs ou expéditeurs dans le contexte des données en streaming. Bien que les organisations puissent choisir d'extraire les données uniquement lorsqu'elles sont prêtes à les analyser, il est préférable de d'abord déposer les données brutes chez un fournisseur d'entrepôt de données cloud. Cela permet à l'entreprise de modifier toutes les données passées si elle doit changer les opérations de traitement des données.
- Transformation des données. Au cours de cette étape, une série de tâches sont effectuées pour convertir les données dans le format requis par le dépôt de données de destination. Ces tâches intègrent l'automatisation et la gouvernance pour les flux de travail répétés, tels que les rapports commerciaux, garantissant que les données sont constamment nettoyées et converties. Un flux de données, par exemple, peut être au format JavaScript object notation (JSON) en couches, et l'étape de transformation des données tentera de dérouler ce JSON pour extraire les champs essentiels pour l'analyse.
- Dépôt de données. Les données transformées sont ensuite stockées dans un dépôt et mises à la disposition de plusieurs parties prenantes. Les données modifiées sont parfois appelées consommateurs, abonnés ou récepteurs.
Avantages des pipelines de données
Les entreprises ont tendance à apprendre sur les pipelines de données et comment ils aident les entreprises à gagner du temps et à garder leurs données structurées lorsqu'elles se développent ou recherchent de meilleures solutions. Voici quelques avantages des pipelines de données que les entreprises pourraient trouver attrayants.
- Qualité des données fait référence à la facilité avec laquelle les utilisateurs finaux peuvent surveiller et accéder aux données pertinentes au fur et à mesure qu'elles passent de la source à la destination.
- Les pipelines permettent aux utilisateurs de générer des flux de données itérativement. Vous pouvez prendre une petite tranche de données de la source de données et la présenter à l'utilisateur.
- Réplicabilité des modèles peut être réutilisée et réaffectée pour de nouveaux flux de données. Ils sont un réseau de pipelines qui génère une méthode de pensée dans laquelle les pipelines individuels sont considérés comme des exemples de modèles dans un design plus large.
Défis avec les pipelines de données
Construire un pipeline de données bien architecturé et performant nécessite de planifier et de concevoir plusieurs aspects du stockage des données, tels que la structure des données, la conception du schéma, la gestion des changements de schéma, l'optimisation du stockage et l'extension rapide pour répondre aux augmentations inattendues du volume de données d'application. Cela nécessite souvent l'utilisation d'une technique ETL pour organiser la transformation des données en plusieurs phases. Vous devez également garantir que les données ingérées sont vérifiées pour la qualité ou la perte de données et que les échecs de tâches et les exceptions sont surveillés.
Voici quelques-uns des problèmes les plus courants qui surviennent lors du travail avec des pipelines de données.
- Augmentation du volume de données à traiter
- Changements dans la structure des données sources
- Données de mauvaise qualité
- Intégrité insuffisante des données dans les données sources
- Duplication des données
- Retard des fichiers de données sources
- Absence d'une interface développeur pour les tests
Cas d'utilisation des pipelines de données
La gestion des données devient une préoccupation de plus en plus importante à mesure que les données volumineuses se développent. Bien que les pipelines de données servent à diverses fins, voici trois applications commerciales principales.
- Analyse exploratoire des données (EDA) évalue et examine les ensembles de données et rend compte de leurs principales propriétés, généralement en utilisant des approches de visualisation des données. Elle aide à déterminer comment modifier les sources de données pour obtenir les réponses nécessaires, facilitant ainsi la découverte de modèles, la détection d'anomalies, le test d'hypothèses et la validation d'assumptions par les scientifiques des données.
- Visualisations de données utilisent des visuels populaires pour décrire les données : graphiques, diagrammes, infographies et animations. Ces visuels d'information expliquent les relations complexes entre les données et les insights basés sur les données de manière facile à comprendre.
- L'apprentissage automatique est un sous-domaine de l'intelligence artificielle (IA) et de l'informatique qui utilise des données et des algorithmes pour imiter la façon dont les gens apprennent, améliorant progressivement sa précision. Les algorithmes sont enseignés pour générer des classifications ou des prédictions en utilisant des approches statistiques, révélant des insights cruciaux dans les initiatives de fouille de données.
Exemples réels de pipelines de données
Voici quelques exemples IRL de pipelines de données d'entreprises qui ont créé des pipelines modernes pour leur application.
- Uber a besoin de données en temps réel pour mettre en œuvre des prix dynamiques, calculer le temps d'arrivée le plus probable et anticiper la demande et l'offre. Ils déploient des pipelines de streaming qui ingèrent des données actuelles des applications de conducteurs et de passagers en utilisant des technologies telles qu'Apache Flink. Ces données en temps réel sont intégrées dans des algorithmes d'apprentissage automatique, qui fournissent des prévisions minute par minute.
- Hewlett Packard Enterprise espérait améliorer l'expérience client avec sa capacité de maintenance prédictive. Ils ont construit un pipeline de données efficace avec des moteurs de streaming comme Akka Streams, Apache Spark, et Apache Kafka.
- Dollar Shave Club nécessitait des données en temps réel pour interagir avec chaque consommateur séparément. Après avoir alimenté les informations dans son système de recommandation, le programme choisissait quels produits promouvoir pour inclusion dans un e-mail mensuel adressé à des clients individuels. Ils ont créé un pipeline de données automatisé en utilisant Apache Spark pour cette pratique.
Meilleures pratiques pour les pipelines de données
Vous pouvez éviter les dangers importants des pipelines de données mal construits en suivant les pratiques recommandées ci-dessous.
- Dépannage simple : En supprimant les dépendances inutiles entre les composants du pipeline de données, vous n'avez qu'à remonter jusqu'au site de l'échec. Simplifier les choses améliore la prévisibilité du pipeline de données.
- Évolutivité : À mesure que les charges de travail et les volumes de données augmentent de manière exponentielle, une conception de pipeline de données idéale devrait être capable de s'adapter et de s'étendre.
- Visibilité de bout en bout : Vous pouvez assurer la cohérence et la sécurité proactive avec une surveillance continue et des inspections de qualité.
- Tests : Après ajustement basé sur les tests de qualité, vous avez maintenant un ensemble de données fiable à faire passer par le pipeline. Une fois que vous avez défini un ensemble de tests, vous pouvez l'exécuter dans un environnement de test séparé ; puis le comparer à la version de production de votre pipeline de données et à la nouvelle version.
- Maintenabilité : Des procédures répétables et une adhérence rigoureuse aux protocoles soutiennent un pipeline de données à long terme.
Outils de pipeline de données
Les outils de pipeline de données soutiennent le flux de données, le stockage, le traitement, le flux de travail et la surveillance. De nombreux facteurs influencent leur sélection, y compris la taille de l'entreprise et l'industrie, les quantités de données, les cas d'utilisation des données, le budget et les besoins en sécurité.
Les groupes de solutions suivants sont couramment utilisés pour construire des pipelines de données.
Outils ETL
Les outils ETL incluent des solutions de préparation et d'intégration de données. Ils sont principalement utilisés pour déplacer des données entre des bases de données. Ils répliquent également les données, qui sont ensuite stockées dans des systèmes de gestion de bases de données et des entrepôts de données.
Top 5 des outils ETL :
* Ci-dessus sont les cinq principales solutions ETL du rapport Grid® de l'été 2023 de G2.
Plateformes DataOps
Les plateformes DataOps orchestrent les personnes, les processus et la technologie pour fournir un pipeline de données fiable à leurs utilisateurs. Ces systèmes intègrent tous les aspects de la création et des opérations de processus de données.
Top 5 des plateformes DataOps :
* Ci-dessus sont les cinq principales solutions DataOps du rapport Grid® de l'été 2023 de G2.
Solutions d'échange de données
Les entreprises utilisent des outils d'échange de données tout au long de l'acquisition pour envoyer, acquérir ou enrichir des données sans altérer leur objectif principal. Les données sont transférées de manière à pouvoir être simplement ingérées par un système récepteur, souvent en les normalisant complètement.
41,8%
des petites entreprises dans l'industrie informatique utilisent des solutions d'échange de données.
Source : données d'avis clients de G2
Diverses solutions de données peuvent fonctionner avec des échanges de données, y compris des plateformes de gestion de données (DMP), des logiciels de cartographie de données lors du déplacement des données acquises vers le stockage, et des logiciels de visualisation de données pour convertir les données en tableaux de bord et graphiques lisibles.
Top 5 des logiciels d'échange de données :
* Ci-dessus sont les cinq principales solutions d'échange de données du rapport Grid® de l'été 2023 de G2.
D'autres groupes de solutions pour les pipelines de données incluent les suivants.
- Les entrepôts de données sont des dépôts centraux pour stocker des données converties à des fins spécifiques. Toutes les principales solutions d'entrepôt de données permettent désormais le chargement de données en streaming et permettent les opérations ETL et émetteur de localisation d'urgence (ELT).
- Les utilisateurs stockent des données brutes dans des lacs de données jusqu'à ce qu'ils en aient besoin pour l'analyse des données. Les entreprises développent des pipelines de Big Data basés sur l'ELT pour les initiatives d'apprentissage automatique en utilisant des lacs de données.
- Les entreprises peuvent utiliser des planificateurs de flux de travail par lots pour déclarer de manière programmatique des flux de travail en tant que tâches avec des dépendances et automatiser ces opérations.
- Les logiciels de streaming de données en temps réel traitent les données continuellement créées par des sources telles que des capteurs mécaniques, des appareils IoT et Internet des objets médicaux (IoMT), ou des systèmes de transaction.
- Les outils de Big Data incluent des solutions de streaming de données et d'autres technologies permettant le flux de données de bout en bout.

Des données détaillées datent profondément
Autrefois, des volumes de données provenant de diverses sources étaient stockés dans des silos séparés qui ne pouvaient pas être accessibles, compris ou analysés en cours de route. Pour aggraver les choses, les données étaient loin d'être en temps réel.
Mais aujourd'hui ? À mesure que la quantité de sources de données augmente, la vitesse à laquelle l'information traverse les organisations et les secteurs entiers est plus rapide que jamais. Les pipelines de données sont le squelette des systèmes numériques. Ils transfèrent, transforment et stockent les données, donnant aux entreprises comme la vôtre des insights significatifs. Cependant, les pipelines de données doivent être mis à jour pour suivre le rythme de la complexité croissante et du nombre de jeux de données.
La modernisation nécessite du temps et des efforts, mais des pipelines de données efficaces et contemporains vous permettront, vous et vos équipes, de prendre des décisions meilleures et plus rapides, vous donnant un avantage concurrentiel.
Vous voulez en savoir plus sur la gestion des données ? Découvrez comment vous pouvez acheter et vendre des données tierces !

Samudyata Bhat
Samudyata Bhat is a Content Marketing Specialist at G2. With a Master's degree in digital marketing, she currently specializes her content around SaaS, hybrid cloud, network management, and IT infrastructure. She aspires to connect with present-day trends through data-driven analysis and experimentation and create effective and meaningful content. In her spare time, she can be found exploring unique cafes and trying different types of coffee.

