



La ciencia de datos une al mundo y concentra información distribuida aleatoriamente en pequeñas unidades.
Con todo el revuelo sobre los grandes datos, datos estructurados vs no estructurados, y cómo las empresas los utilizan, podrías preguntarte: “¿A qué tipos de datos nos referimos?”
Lo primero que hay que entender es que no todos los datos son creados iguales. Esto significa que los datos generados por aplicaciones de redes sociales son completamente diferentes de los datos generados por sistemas de punto de venta o de cadena de suministro.
Algunos datos están estructurados, pero la mayoría no lo están. En el backend, un software de gestión de bases de datos (DBMS) es un sistema de gestión de consultas que autentica el acceso del usuario a estos datos y la capacidad de almacenarlos, gestionarlos y recuperarlos a través de consultas de usuario.
Para aclarar, desglosaremos las diferencias únicas entre los datos estructurados y no estructurados.
¿Cuál es la diferencia entre datos estructurados y no estructurados?
Los datos estructurados están altamente organizados y formateados de manera que son fácilmente buscables en bases de datos relacionales. Los datos no estructurados no tienen un formato o organización predefinidos, lo que los hace mucho más difíciles de recopilar, procesar y analizar. Los datos estructurados son más finitos y se ordenan en matrices de datos, mientras que los datos no estructurados están dispersos y son variables.
Además de ser obtenidos, recopilados y escalados de diferentes maneras, los datos estructurados y no estructurados residirán en bases de datos completamente separadas.
¿Qué son los datos estructurados?
Los datos estructurados se categorizan más a menudo como datos cuantitativos, y es el tipo de datos con los que la mayoría de nosotros estamos acostumbrados a trabajar. Piensa en datos que encajan perfectamente dentro de campos y columnas fijos en bases de datos relacionales y hojas de cálculo.
Ejemplos de datos estructurados incluyen nombres, fechas, direcciones, números de tarjetas de crédito, información de acciones, geolocalización y más.
Los datos estructurados están altamente organizados y son fácilmente comprendidos por el lenguaje de máquina. Aquellos que trabajan dentro de bases de datos relacionales pueden ingresar, buscar y manipular rápidamente datos estructurados usando un sistema de gestión de bases de datos relacionales (RDBMS). Esta es la característica más atractiva de los datos estructurados.
El lenguaje de programación para gestionar datos estructurados se llama lenguaje de consulta estructurada, también conocido como SQL. IBM desarrolló este lenguaje a principios de los años 70, y es particularmente útil para manejar relaciones en bases de datos.
Ejemplos de datos estructurados
Si esto suena confuso, aquí hay un ejemplo de un comando DDL (lenguaje de definición de datos) ejecutado para tabular datos estructurados. Los datos se almacenan en una tabla SQL, cada fila y columna contribuyendo a un tipo de dato específico.
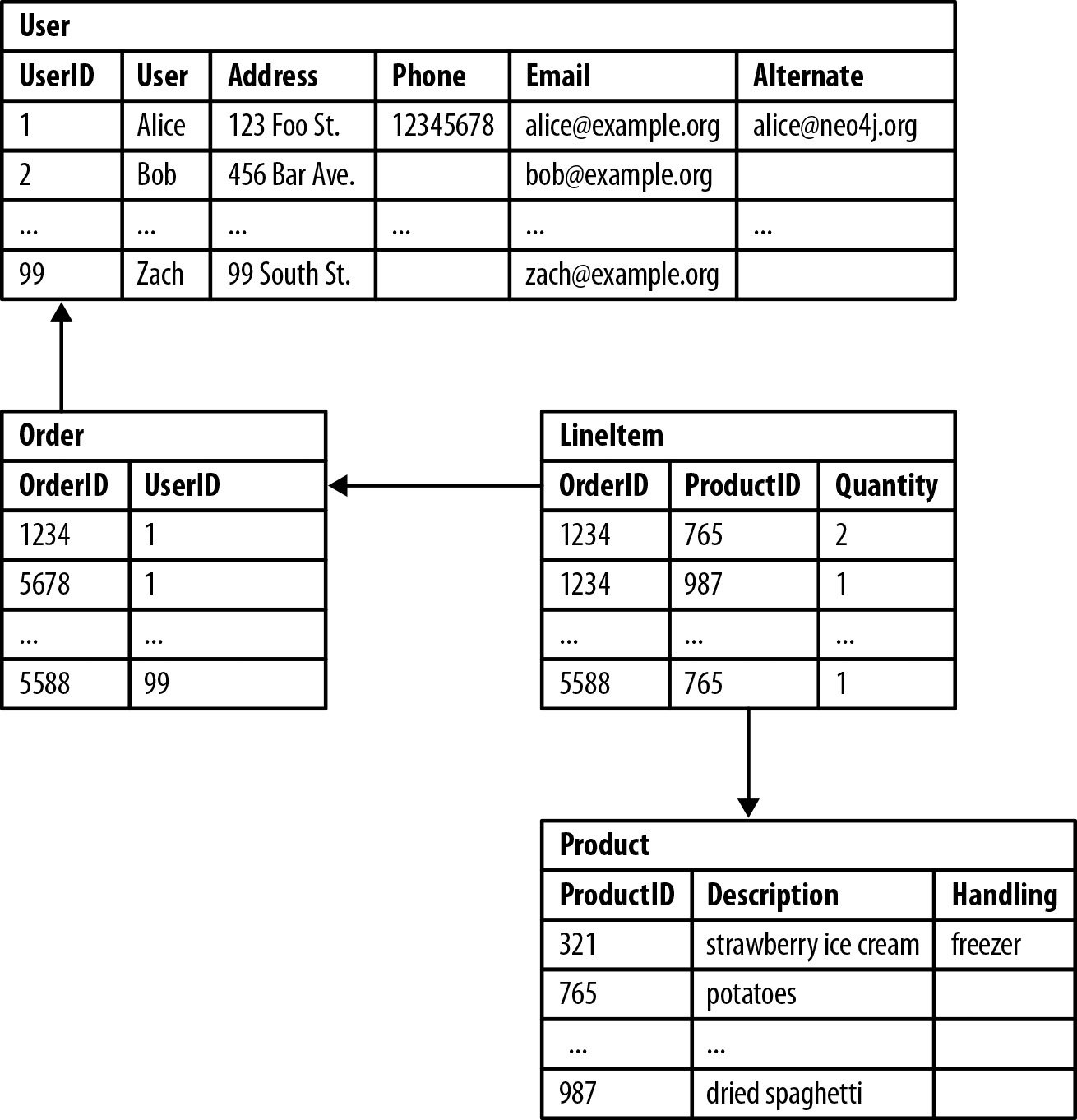
De arriba hacia abajo, podemos ver que el UserID 1 se refiere a la cliente Alice, quien tuvo dos Order IDs de ‘1234’ y ‘5678’. Luego, Alice tuvo dos ProductIDs de '765’ y ‘987’. Finalmente, podemos ver que Alice compró dos paquetes de papas y un paquete de espaguetis secos.
Los datos estructurados también se utilizan en sistemas de reservas de aerolíneas, sistemas electrónicos de transporte compartido, aplicaciones de comida y entrega, y optimización de motores de búsqueda (datos SEO). En cada uno de estos casos, los datos se almacenan en bases de datos relacionales y pueden ser almacenados, recuperados o gestionados en grandes formas.
Los datos estructurados revolucionaron los sistemas basados en papel de los que las empresas dependían para inteligencia empresarial hace décadas. Aunque los datos estructurados siguen siendo útiles, más empresas están buscando descomponer los datos no estructurados para futuras oportunidades.

Fuente: Fivetran
Ejemplos de datos estructurados
Los datos estructurados se utilizan en múltiples bases de datos orientadas al consumidor o ERPs, tales como:
- Comercio electrónico: Datos de reseñas, datos de precios y número SKU de productos
- Salud: administración hospitalaria, farmacia, y datos de pacientes e historial médico de pacientes.
- Banca: Detalles de transacciones financieras como nombre del beneficiario, detalles de cuenta, información del remitente o receptor y detalles bancarios.
- Software de gestión de relaciones con clientes (CRM): datos de adquisición de clientes potenciales, fuente, actividad y así sucesivamente de clientes potenciales en la base de datos CRM.
- Industria de viajes: Datos de pasajeros, información de vuelos y transacciones de viajes.
Datos estructurados vs. no estructurados
Los datos no estructurados son el polo opuesto de los datos estructurados. Aquí hay un resumen de las diferencias notables entre los dos.

Los datos estructurados están preformateados y ordenados en bloques de memoria. Su formato está predefinido en filas y columnas y se almacenan en sistemas de bases de datos relacionales (RDBMS) o Microsoft Excel. Los datos se conocen como "esquema al escribir", representando datos para un esquema o plano de base de datos grande. Es altamente escalable y seguro y requiere menos gestión.
Los datos no estructurados son altamente complejos, cualitativos y desorganizados. También se les conoce como grandes datos, que no se ajustan a ningún estándar particular. Estos datos pueden ser numéricos, alfabéticos, booleanos o una mezcla de todos ellos. Se almacenan usando una base de datos NoSQL. No pueden almacenarse en una base de datos relacional o RDBMS ya que las cadenas de datos tienen tipos de datos mixtos que no pueden encajar en una fila o columna. Tipos comunes de datos no estructurados son datos de clics, datos de redes sociales, texto y multimedia.
Relacionado: Explora SQL vs. NoSQL para ver qué base de datos es adecuada para ti.
Beneficios de los datos estructurados
Es fácil almacenar, recuperar y gestionar datos estructurados ya que tienen un mecanismo de backend organizado. Usar datos estructurados en los negocios puede resultar en los siguientes beneficios.
- Los datos estructurados pueden ser fácilmente alimentados en modelos de aprendizaje automático como conjuntos de datos de entrada sin necesidad de recortes.
- Trabajar con datos estructurados no requiere experiencia en IA o ML. Cualquiera con buena información de producto y conocimientos básicos de ciencia de datos puede hacerlo.
- Los datos estructurados se almacenan uniformemente en almacenes de datos o hojas de cálculo. Su naturaleza específica y organizada facilita su manipulación y consulta.
- Los datos estructurados preceden a los datos no estructurados, por lo que hay más herramientas de análisis disponibles para medirlos y analizarlos.
- Los datos son de mayor calidad, consistencia y usabilidad que los datos no estructurados.
- Existen mecanismos de respaldo para adaptarse si el usuario encuentra un error al gestionar datos estructurados.
- También se les conoce como datos cuantitativos, ya que las empresas utilizan sus métricas para prever tendencias empresariales e impacto estratégico.
- Se mantienen en un repositorio estable y centralizado que mejora el flujo de procesos empresariales y la toma de decisiones para optimizar el ROI.
Desafíos de los datos estructurados
La mayoría de los problemas de datos estructurados destacan su inflexibilidad y rigidez al escalar esquemas de bases de datos más grandes. Los datos estructurados son "esquema al escribir" o "fuertemente dependientes del esquema" para las operaciones. Los desafíos comunes de los datos estructurados se enumeran a continuación:
- Como los datos estructurados dependen del esquema, es un poco difícil escalarlos para bases de datos grandes.
- El tiempo necesario para cargar datos estructurados a veces se subestima. Identificar problemas ocultos en el sistema fuente y actualizarlos, recuperarlos y restaurarlos puede consumir tu almacenamiento en la nube.
- No se adapta bien al cambio de escenario empresarial. Es difícil determinar qué consulta resultaría en un resultado empresarial específico. La naturaleza de las consultas y transacciones cambia a medida que una empresa cambia su enfoque al consumidor.
- Los datos estructurados se ingresan manualmente en el sistema de gestión de bases de datos. El usuario tiene que escribir un comando DDL (lenguaje de definición de datos) como Crear, Insertar y Seleccionar para ordenar, gestionar y recuperar datos del sistema.
Herramientas de datos estructurados
Aparte de usar un lenguaje de consulta estructurada (SQL) o Microsoft Excel para gestionar manipulaciones de datos estructurados, hay algunas extensiones de herramientas más que puedes usar.
- PL SQL: Lenguaje de Consulta Procedural o PL SQL es una versión existente de SQL que maneja transacciones de trabajo. Las consultas transaccionales comunes son "commit" o "rollback".
- Postgre SQL: Postgre SQL es un sistema de gestión de bases de datos relacionales de código abierto que maneja grandes volúmenes de datos. También soporta consultas SQL y JSON junto con lenguajes de alto nivel.
-
SQLite: Es una base de datos de alto nivel, autónoma y sin servidor que los desarrolladores de software utilizan para extraer datos estructurados para integraciones de aplicaciones empresariales,
- My SQL es un entorno de datos integrado estándar que utiliza autenticación de usuario para ingresar registros de datos a través de consultas en una base de datos desplegada masivamente.
- OLAP: Abarca una categoría más amplia de gestión de bases de datos que comprende minería de datos, minería de informes e inteligencia empresarial.

¿Qué son los datos no estructurados?
Los datos no estructurados a menudo se categorizan como cualitativos y no pueden ser procesados y analizados usando herramientas y métodos de datos convencionales. También se les conoce como datos "independientes del esquema" o "esquema al leer".
Ejemplos de datos no estructurados incluyen texto, archivos de video, archivos de audio, actividad móvil, publicaciones en redes sociales, imágenes satelitales, imágenes de vigilancia – la lista sigue y sigue.
Los datos no estructurados son difíciles de descomponer porque no tienen un modelo de datos predefinido, lo que significa que no pueden ser organizados en bases de datos relacionales. En su lugar, las bases de datos no relacionales o bases de datos NoSQL son la mejor opción para gestionar datos no estructurados.
Otra forma de gestionar datos no estructurados es hacer que fluyan hacia un lago de datos o piscina, permitiendo que estén en su formato crudo y no estructurado.
Encontrar la información enterrada dentro de los datos no estructurados no es una tarea fácil. Requiere análisis avanzados y alta experiencia técnica para marcar la diferencia. El análisis de datos puede ser un cambio costoso para muchas empresas.
95%
de las empresas citan la necesidad de gestionar datos no estructurados como un problema para su negocio.
Fuente: Techjury
Ejemplos de datos no estructurados
Aquellos que pueden aprovechar los datos no estructurados, sin embargo, tienen una ventaja competitiva. Mientras que los datos estructurados nos dan una vista de pájaro de los clientes, los datos no estructurados o grandes datos pueden darnos información detallada sobre las acciones cotidianas de los consumidores.
Por ejemplo, las técnicas de minería de datos aplicadas a datos no estructurados de un sitio web minorista pueden ayudar a las empresas a aprender hábitos de compra de clientes y tiempos, patrones de compra, sentimiento hacia un producto específico y mucho más.
Los datos no estructurados también son clave para el software de análisis predictivo. Por ejemplo, los datos de sensores adjuntos a maquinaria industrial pueden alertar a los fabricantes de actividad extraña con anticipación. Con esta información, se puede realizar una reparación antes de que la máquina sufra una costosa avería.
Más ejemplos de datos no estructurados:
Los datos no estructurados son cualquier evento o alerta enviada y recibida por cualquier usuario dentro de una organización sin un formato de archivo adecuado o co-dependencia empresarial directa.
- Medios enriquecidos: Redes sociales, entretenimiento, vigilancia, información satelital, datos geoespaciales, pronóstico del tiempo, podcasts
- Documentos: Facturas, registros, historial web, correos electrónicos, aplicaciones de productividad
- Datos de medios y entretenimiento, datos de vigilancia, datos geoespaciales, audio, datos meteorológicos
- Internet de las cosas: datos de sensores, datos de ticker
- Análisis: Aprendizaje automático, inteligencia artificial (IA)
Beneficios de los datos no estructurados
Los datos no estructurados, también conocidos como grandes datos hoy en día, son de flujo libre y nativos de cada empresa específica. Son independientes del esquema y se conocen como "esquema al leer". Personalizar estos datos según tus estrategias empresariales puede darte una ventaja competitiva sobre los competidores que aún están atrapados en la toma de decisiones tradicional. Y aquí está el porqué.
- Los datos no estructurados están fácilmente disponibles y tienen suficientes conocimientos que las empresas pueden recopilar para aprender sobre la respuesta de su producto.
- Los datos no estructurados son independientes del esquema. Por lo tanto, las alteraciones menores a la base de datos no impactan en el costo, tiempo o recursos.
- Los datos no estructurados pueden almacenarse en servidores en la nube compartidos o híbridos con un gasto mínimo en gestión de bases de datos.
- Los datos no estructurados están en su formato nativo, por lo que los científicos o ingenieros de datos no los definen hasta que se necesitan. Abre la expandibilidad de formatos de archivo, ya que está disponible en diferentes formatos como .mp3, .opus, .pdf, .png, y así sucesivamente.
- Los lagos de datos vienen con precios "paga según usas", lo que ayuda a las empresas a reducir sus costos y consumo de recursos.
Desafíos de los datos no estructurados
Los datos no estructurados son el método de recopilación y manipulación de datos más popular hoy en día. Muchas empresas están cambiando a modelos de negocio más "centrados en el cliente" y apostando por los datos de los consumidores. Sin embargo, trabajar con datos no estructurados resulta en los siguientes desafíos.
- Los datos no estructurados no son los más fáciles de entender. Los usuarios requieren un conocimiento profundo en ciencia de datos y aprendizaje automático para prepararlos, analizarlos e integrarlos con algoritmos de aprendizaje automático.
- Los datos no estructurados descansan en servidores compartidos menos auténticos y encriptados, que son más propensos a ataques de ransomware y cibernéticos.
- Actualmente, no hay muchas herramientas que puedan manipular datos no estructurados aparte de los servidores de commodities en la nube y los DBMS NoSQL de código abierto.
Herramientas de datos no estructurados
Aparte de usar un NoSQL para gestionar manipulaciones de datos no estructurados, hay algunas herramientas más que puedes usar.
- Hadoop: Un marco de computación distribuida para procesar grandes cantidades de datos no estructurados.
- Apache Spark: Un marco de computación en clúster rápido y de propósito general para procesar datos estructurados y no estructurados.
- Herramientas de Procesamiento de Lenguaje Natural (NLP): Para extraer información de datos de texto no estructurados.
- Bibliotecas de aprendizaje automático: Para construir modelos para analizar y predecir patrones en datos no estructurados.
Más tipos de datos
Aparte de los tipos de datos mencionados, los datos semiestructurados y los metadatos son cruciales para manejar la creciente complejidad y diversidad de las fuentes de datos modernas.
¿Qué son los datos semiestructurados?
Los datos semiestructurados son un tipo de datos estructurados que se encuentran a medio camino entre los datos estructurados y no estructurados. No tienen un modelo de datos relacional o tabular específico, pero incluyen etiquetas y marcadores semánticos que escalan los datos en registros y campos en un conjunto de datos.
Ejemplos comunes de datos semiestructurados son JSON y XML. Los datos semiestructurados son más complejos que los datos estructurados pero menos complejos que los datos no estructurados. También son relativamente más fáciles de almacenar que los datos no estructurados, cerrando la brecha entre los dos tipos de datos.
Un mapa del sitio XML contiene información de página para un sitio web. Incorpora URLs, puntuaciones de dominio, páginas do-follow y metaetiquetas.
¿Qué son los metadatos?
Los metadatos se utilizan a menudo en análisis de grandes datos y son un conjunto de datos maestro que describe otros tipos de datos. Tienen campos preestablecidos que contienen información adicional sobre un conjunto de datos específico.
Los metadatos tienen una estructura definida identificada por un esquema de marcado de metadatos que incluye modelos y estándares de metadatos. Contienen detalles valiosos para ayudar a los usuarios a analizar mejor los datos y tomar decisiones informadas.
Por ejemplo, un artículo en línea puede mostrar metadatos como un titular, un fragmento, una imagen destacada, un texto alternativo de imagen, un slug y otra información relacionada. Esta información ayuda a diferenciar una pieza de contenido de varias otras piezas similares de contenido en la web. Por lo tanto, los metadatos son un conjunto de datos útil que actúa como el cerebro para todos los tipos de datos.
Herramientas de gestión de bases de datos
Las herramientas de gestión de bases de datos proporcionan la infraestructura para almacenar, gestionar, y analizar datos de manera efectiva, asegurando una gestión de datos eficiente y conocimientos valiosos. Utilizar la herramienta de gestión de bases de datos adecuada permitirá a las empresas:
- Reducir costos operativos
- Rastrear métricas actuales y crear nuevas
- Entender a sus clientes a un nivel mucho más profundo
- Revelar campañas de marketing más inteligentes y dirigidas
- Encontrar nuevas oportunidades y ofertas de productos
Las 5 principales herramientas de gestión de datos:
*Arriba están las cinco principales soluciones de software de gestión de datos del informe Grid® de verano de 2024 de G2.
Como los datos, como las decisiones
El volumen de grandes datos sigue aumentando, pero la importancia del almacenamiento de grandes datos pronto dejará de existir.
Ya sea que los datos estén estructurados o no estructurados, tener las fuentes de datos más precisas y relevantes será clave para las empresas que buscan obtener una ventaja sobre sus competidores.
Cuantas más variedades de datos creen los científicos de datos, más algoritmos nuevos y avanzados se crearán, lo que facilitará la línea de cumplimiento del RGPD.
Los datos están infiltrándose en todas las industrias importantes del mundo. Las marcas están alejándose de los trucos de marketing no esenciales hacia el marketing de consumo basado en datos. La información que los datos nos proporcionan está siendo aprendida y analizada en conjunto con la inteligencia artificial y la computación en red para crear soluciones robustas e hiperconectadas.
Al final del día, depende del consumidor determinar cuán cómodo se siente con las formas en que se utilizan sus datos.
¿Nuevo en el análisis de grandes datos pero quieres aprender más? Aprende cómo obtener información en tiempo real de tus datos con el software de análisis de grandes datos adecuado.
Este artículo fue publicado originalmente en 2021. Ha sido actualizado con nueva información.

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)

