


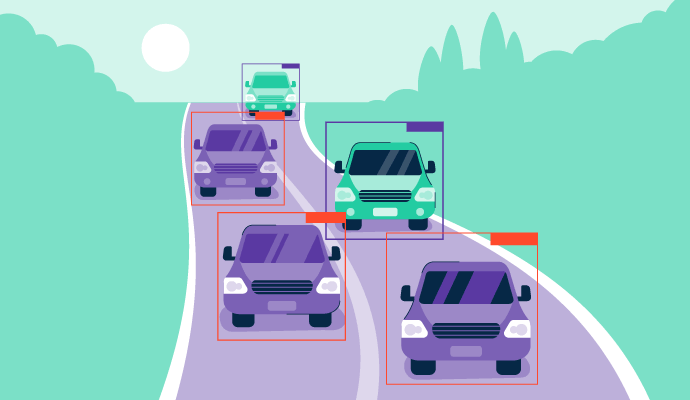
Los humanos están dotados de visión periférica; pero las computadoras están alcanzando la competencia con la detección de objetos ahora.
Ya sea el piloto automático de Tesla o las aspiradoras Deebot, los dispositivos informáticos están impulsados por nuevos algoritmos de IA generativa para acelerar las capacidades de procesamiento y nombrar objetos físicos. Conocido como detección de objetos en resumen, esta simulación de visión diseñada con software de reconocimiento de imágenes ha pasado el testigo de la visión y la vista a las computadoras.
El propósito principal de la detección de objetos es segmentar, localizar y anotar objetos físicos o digitales con precisión infalible para completar una tarea designada.
La detección de objetos ha abierto nuevos caminos de asistencia robótica que están dirigidos a fabricar dispositivos de autoasistencia para facilitar tareas tediosas. Aprendamos sobre eso en detalle.
¿Qué es la detección de objetos?
La detección de objetos es un enfoque de IA estrecha que identifica, clasifica y localiza objetos en fotografías digitales o videos. El objetivo principal de la detección de objetos es detectar las instancias de cada objeto, segmentarlas y analizar sus características necesarias para la categorización en tiempo real y la modularidad en profundidad.
La detección de objetos es parte de la arquitectura de base de datos general de una empresa. Algunas empresas han adoptado con éxito esta tecnología, mientras que otras están esperando que se anuncie como una técnica exitosa de gestión de bases de datos.
Los principales ejemplos de detección de objetos incluyen seguridad y vigilancia, control de acceso, asistencia biométrica, monitoreo de condiciones de carreteras, máquinas de autoasistencia y protección de fronteras marítimas.
¿Cómo funciona la detección de objetos?
La detección de objetos funciona de manera similar al reconocimiento de objetos. La única diferencia es que el reconocimiento de objetos es el proceso de identificar la categoría correcta del objeto, mientras que la detección de objetos simplemente detecta la presencia y ubicación del objeto en una imagen.
Las tareas de detección de objetos se pueden realizar utilizando dos técnicas diferentes de análisis de datos.
- Procesamiento de imágenes es parte del aprendizaje no supervisado que no requiere datos de entrenamiento históricos para enseñar modelos analíticos. Los modelos se autoentrenan con las imágenes de entrada y crean mapas de características para hacer predicciones. El procesamiento de imágenes no requiere un alto poder de procesamiento gráfico o grandes conjuntos de datos para su ejecución.
- Red neuronal profunda: Una red neuronal profunda es generalmente un algoritmo de aprendizaje supervisado que requiere grandes conjuntos de datos y un alto poder de computación de GPU para predecir clases de objetos. Es una forma más precisa de clasificar objetos parcialmente ocultos, complejos o colocados en fondos desconocidos en una imagen.
Entrenar una red neuronal profunda es una tarea laboriosa y costosa. Sin embargo, algunos conjuntos de datos a gran escala proporcionan la disponibilidad de datos etiquetados.
¿Sabías que? COCO, un conjunto de datos de detección, segmentación y subtitulado de objetos a gran escala, se puede utilizar para entrenar una red neuronal profunda.
Algunas características que puedes esperar de MS COCO:
- Segmentación de objetos
- Reconocimiento en contexto
- Segmentación de cosas en superpíxeles
- Preentrenado en 33,000 imágenes
- 1.5 millones de instancias de objetos
- 80 clases de objetos
- 91 categorías de cosas
- 5 subtítulos por imagen
- 250,000 personas con puntos clave
¿Quieres aprender más sobre Software de reconocimiento de imágenes? Explora los productos de Reconocimiento de imágenes.
Importancia de la detección de objetos
Habiendo entendido la metodología de trabajo, es hora de discutir qué hace que la detección de objetos sea importante.
La detección de objetos forma la base para otras técnicas importantes de visión de IA, como la clasificación de imágenes, la recuperación de imágenes, el procesamiento de imágenes o la co-segmentación de objetos, que extraen información significativa de objetos de la vida real. ¡Los desarrolladores e ingenieros están utilizando estas técnicas para construir máquinas futuristas que entregan comestibles y medicinas a nuestras puertas!
Un algoritmo de detección de objetos puede detectar automáticamente movimientos de ganado, señales de tráfico y carriles de carretera para que los vehículos autónomos puedan llegar a sus destinos. Esto, a su vez, elimina la necesidad de que los conductores realicen tareas logísticas.

La detección de objetos también puede funcionar en redes móviles al podar las capas de una red neuronal profunda. Ya se está utilizando en escáneres de seguridad o detectores de metales en aeropuertos para detectar objetos no deseados e ilegales.
Aparte de esto, las empresas utilizan la detección de objetos para el conteo de personas, el reconocimiento de matrículas, el reconocimiento de voz y la detección de evidencias. Sin embargo, una ligera falta de precisión a veces obstaculiza su eficiencia en la detección de objetos diminutos. La falta de precisión al cien por ciento lo hace menos preferible para dominios críticos como la minería y el ejército.
Clasificación de imágenes vs. detección de objetos
La detección de objetos a menudo se confunde con la clasificación de imágenes. Aunque son las caras del mismo cubo de Rubik, aquí hay algunas diferencias notables.
-png.png)
La clasificación de imágenes es un concepto simple de categorizar una imagen multiespectral basada en sus componentes. Si te dan una imagen de un perro, el modelo de clasificación de imágenes puede interpretar sus características principales y etiquetar la imagen como "perro" fácilmente. Si una imagen contiene dos objetos, como un gato y un perro, el modelo utiliza un clasificador de etiquetas múltiples para clasificar ambos objetos.
El modelo de clasificación de imágenes no acepta ninguna variable para la localización de objetos aparte de definir la clase del objeto. Aquí es donde entra en juego la detección de objetos.
Un algoritmo de detección de objetos puede identificar la clase del objeto y predecir la ubicación exacta de los objetos en una imagen dibujando cuadros delimitadores alrededor de ellos. Es una combinación de clasificación de imágenes y localización de objetos que permite al sistema saber dónde están colocados los objetos en una imagen y por qué. Permite a un sistema analizar visualmente cada objeto y determinar su aplicación en la vida real, tal como lo hacen los humanos.
Modelos de detección de objetos
Los enfoques más preferidos para la detección de objetos son el aprendizaje automático o el aprendizaje profundo. Ambos métodos funcionan en conjunto con una máquina de vectores de soporte (SVM) para extraer las características, entrenar el algoritmo, y categorizar objetos.
La detección de objetos no es posible sin un conjunto de datos adecuado. Los conjuntos de datos cubren las características principales conocidas de un objeto, como ubicación, dimensiones, categoría o colores. En la práctica, si un modelo de detección de objetos está preentrenado en un conjunto de datos de algo con ruedas, un parabrisas, intermitentes, un motor y un maletero, puede clasificar con precisión el objeto en la imagen dada como un coche.
Diferentes tipos de métodos de detección de objetos tienen diferentes niveles de efectividad y aplicabilidad en diversas industrias. Vamos a entender esto en detalle:
Aprendizaje automático
El punto a favor de usar un algoritmo de aprendizaje automático para realizar la detección de objetos es que se basa en datos ingresados manualmente para la clasificación, no en datos de entrenamiento automáticos. Esto hace que el algoritmo general sea menos propenso a errores y más estable.
La detección de objetos es un problema de aprendizaje automático supervisado, lo que significa que debes usar modelos preentrenados para activar detectores de objetos. La lista de clases en el conjunto de datos de entrenamiento de un algoritmo de ML debe pertenecer a una imagen específica o lista de imágenes.
Los enfoques de aprendizaje automático como el procesamiento del lenguaje natural (NLP) identifican y clasifican objetos basándose en su intensidad de iluminación contra un fondo. Los algoritmos de ML para objetos 2D también se pueden reutilizar para detectar objetos 3D en imágenes.
Características de canal agregado (ACF)
ACF es un método de aprendizaje automático que reconoce objetos específicos en una imagen basándose en un conjunto de datos de imágenes de entrenamiento y las ubicaciones de los objetos en el suelo. Se utiliza principalmente para la detección de objetos en múltiples vistas, como la identificación de objetos 3D capturados desde tres equipos de cámaras. Los vehículos de autoasistencia, la detección de peatones y la detección facial funcionan con este principio.
ACF combina diferentes canales que extraen características de una imagen como gradientes o píxeles en lugar de recortar una imagen en varias ubicaciones. Los canales comunes incluyen escala de grises o RBG, dependiendo de la dificultad del problema de detección de objetos. ACF te da una comprensión más rica de los objetos y acelera la velocidad de detección para una mayor precisión.
Consejo: Para crear un detector de objetos ACF, declara y define una función de programación MATLAB, "trainACFObjectDetector()" y carga las imágenes de entrenamiento. Prueba la precisión de detección en una imagen de prueba separada.
Detección de objetos DPM
El modelo de partes deformables (DPM) es un enfoque de aprendizaje automático que reconoce objetos con una mezcla de modelos gráficos y partes deformables de la imagen. Contiene cuatro componentes principales:
- Un filtro de raíz gruesa define varios cuadros delimitadores en una imagen para capturar los objetos.
- Los filtros de partes cubren los fragmentos de los objetos y los convierten en flechas de píxeles más oscuros.
- Un modelo espacial almacena la ubicación de todos los fragmentos de objetos en relación con los cuadros delimitadores en el filtro de raíz.
- Un regresor disminuye la distancia entre los cuadros delimitadores y la verdad del suelo para predecir objetos con precisión.

Fuente: lilianweng.github.io/
Consejo: Extraer características importantes de objetos destacados puede ser útil al recopilar datos de sitios de construcción para rastrear el progreso del trabajo o hacer cumplir la salud y seguridad ambiental durante el trabajo.
Aprendizaje profundo
Mientras que los modelos de aprendizaje automático se construyen sobre la selección manual de las características, los flujos de trabajo de aprendizaje profundo vienen con selección automática de características para adaptarse a tu pila tecnológica. Los enfoques de aprendizaje profundo como los modelos de redes neuronales convolucionales producen predicciones de objetos más rápidas y precisas. ¡Por supuesto, necesitas una unidad de procesamiento gráfico (GPU) más alta y conjuntos de datos más grandes para que eso suceda!
El aprendizaje profundo se utiliza para una variedad de tareas de detección de objetos. Las cámaras de vigilancia modernas o los sistemas de monitoreo están impulsados por redes neuronales para detectar con éxito rostros u objetos desconocidos.
Aquí hay algunos enfoques de aprendizaje profundo para abordar la detección de objetos.
Solo Miras Una Vez (YOLO)
YOLO es un marco de detección de objetos de una sola etapa dedicado a aplicaciones industriales. Su diseño eficiente y alto rendimiento lo hacen amigable con el hardware y eficiente. Es una CNN entrenada en grandes bases de datos visuales como redes de imágenes y se puede codificar en editores de código abierto en TensorFlow, Darknet o Python.
YOLO produce detecciones de objetos de última generación a una velocidad increíble de 45 cuadros por segundo. Hasta la fecha, se han lanzado diferentes versiones de YOLO, como YOLOv1, YOLOv2 o YOLOv3, han sido lanzadas.
La última versión, YOLOv6, se puede entrenar en conjuntos de datos personalizados en PyTorch a través de interfaces de programación de aplicaciones (APIs). Pytorch es un paquete de Python y una de las formas más preferidas de investigación de aprendizaje profundo. YOLOv6 está entrenado exclusivamente para detectar vehículos en movimiento en la carretera.
¿Sabías que? YOLO o redes neuronales convolucionales basadas en regiones (R-CNN) utilizan la función de precisión media o mAP(). Compara un cuadro delimitador de referencia con un cuadro detectado real y devuelve una probabilidad o puntuación de confianza. Cuanto mayor sea la puntuación, más precisa será la predicción.
SSD (Detector de Disparo Único)
SSD es un detector de objetos personalizado sin una red de propuestas de regiones específica (diferentes partes de una imagen agrupadas en una red) para la predicción de objetos. Predice la ubicación y el tipo de objeto de una imagen directamente en un solo paso a través de una gama de capas de un modelo de aprendizaje profundo.
SSD se bifurca en dos partes:
1. Espina dorsal
La espina dorsal de la red de clasificación de imágenes preentrenada extrae las características de la imagen para identificar la imagen. Estas redes, como ResNet, están entrenadas en ImageNets (grandes bases de datos de imágenes) y separadas de la capa de clasificación de imágenes interna. Deja el modelo de espina dorsal como una red neuronal profunda, entrenada exclusivamente en millones de imágenes para extraer información semántica de la imagen de entrada mientras preserva la estructura espacial de la imagen.
Para ResNet34, la espina dorsal crea mapas de características de 256x7x7 para cualquier imagen de entrada.
2. Cabeza
La cabeza del modelo de detección de objetos es solo una capa de cerebro de red neuronal añadida a la espina dorsal que ayuda en el proceso de regresión final de la imagen. Produce la ubicación espacial del objeto y la combina con la clase del objeto en las etapas finales de SSD.
Fuente:developers.arcgis.com
Otros componentes importantes
Aquí están los componentes importantes que conforman un modelo SSD para realizar la detección de objetos en tiempo real.
- Celda de cuadrícula: Al igual que el algoritmo YOLO, el algoritmo SSD divide el cuadro delimitador en una cuadrícula de 5x5. Cada celda de la cuadrícula es responsable de producir la forma, ubicación, color y etiqueta del objeto que contiene.
- Caja de anclaje: A medida que la CNN divide la imagen en una cuadrícula, a cada celda de la cuadrícula se le asigna más de una caja de anclaje. El modelo SSD utiliza una técnica de coincidencia de plantillas durante el período de entrenamiento para hacer coincidir el cuadro delimitador con cada objeto de verdad del suelo de la imagen.

Fuente: pyimagesearch.com
Aquí, el cuadro delimitador predicho se dibuja en rojo, mientras que el cuadro delimitador de verdad del suelo (etiquetado a mano) está en verde. Como hay un alto grado de superposición, esta caja de anclaje es responsable de identificar la presencia de objetos. La Intersección sobre Unión (IoU) aquí se puede medir como
- Relación de aspecto: Cada objeto tiene una forma y configuración diferente. Algunos son más redondeados y grandes, mientras que otros son más pequeños y cortos. La arquitectura SSD ayuda a declarar relaciones de aspecto de antemano a través de un parámetro de relación.
- Nivel de zoom: El parámetro de zoom puede magnificar objetos más pequeños en cada celda de la cuadrícula para identificar su presencia, categoría y ubicación. Por ejemplo, si necesitamos identificar un edificio y un parque desde un helicóptero, necesitamos escalar el algoritmo SSD de manera que detecte tanto los objetos más grandes como los más pequeños.
- Campo receptivo: El campo receptivo se define como el conjunto móvil de píxeles de la imagen en el que el algoritmo está trabajando actualmente. Diferentes capas de un modelo CNN computan diferentes regiones de una imagen de entrada. A medida que se profundiza, el tamaño del objeto aumenta. Al igual que un microscopio, un modelo CNN magnifica cada píxel del objeto para calcular a qué categoría pertenece.
Intersección sobre Unión (IoU): Área de superposición / Área de unión
EfficientNet
EfficientNet es una arquitectura de red neuronal convolucional que escala uniformemente todas las dimensiones de un objeto antes de detectarlas. Estas redes neuronales se desarrollan a un costo fijo de software de aplicación. Sobre la disponibilidad de recursos, los algoritmos EfficientNet se pueden escalar en un dominio de aplicación para lograr mejores resultados de detección de objetos.
EfficientNet se considera uno de los mejores modelos CNN existentes para la detección de objetos, ya que ha logrado precisión de última generación en conjuntos de datos de aprendizaje como Flores (98.8%) mientras es 6.1 veces más rápido que otros modelos de detección de objetos.
Mask R-CNN
Esto extiende Faster R-CNN al agrupar la red de propuestas de regiones y la CNN preentrenada como AlexNet. Una red de propuestas de regiones es una red de regiones separadas por cuadros delimitadores. Mask R-CNN extrae características de la imagen y crea mapas de características para detectar la presencia de objetos. También genera una máscara de alta calidad (cuadro delimitador) para cada objeto para separarlo del resto.
¿Cómo funciona Mask R-CNN?
Mask R-CNN se construyó utilizando Faster R-CNN y Fast R-CNN. Mientras que Faster R-CNN tiene una capa softmax que bifurca las salidas en dos partes, una predicción de clase y un desplazamiento de cuadro delimitador, Mask R-CNN es la adición de una tercera rama que describe la máscara del objeto, que es la forma del objeto. Es distinta de otras categorías y requiere la extracción de las coordenadas gráficas del objeto para predecir con precisión la ubicación.
Mask R-CNN es una combinación de dos CNN que funciona agrupando en una capa de máscara de objeto, también conocida como Región de Interés (ROI), en paralelo con el localizador de cuadros delimitadores existente.
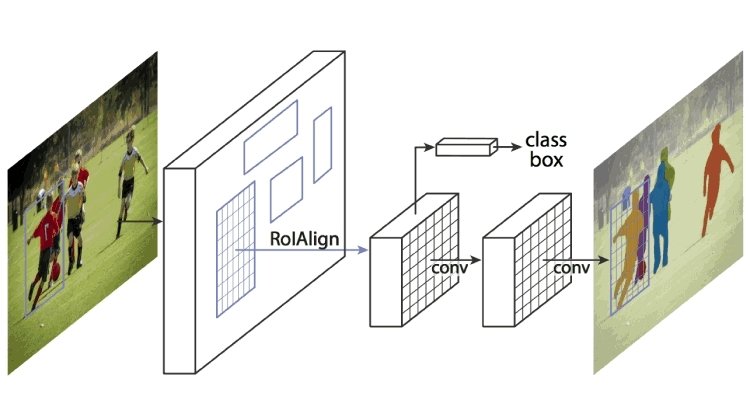
Fuente: viso.ai
Características de Mask R-CNN
Discutamos brevemente algunas características.
- Es un modelo extremadamente simple de entrenar y funciona a una velocidad de 5 cuadros por segundo (FPS)
- Funciona milagrosamente bien para detectar rostros humanos en diferentes configuraciones.
- Supera a todas las entradas de modelo único en cada tarea de detección de objetos.
- Mask R-CNN puede generalizarse fácilmente a otras tareas. También se puede usar para estimar poses humanas en un marco particular.
- Sirve como una base sólida para crear robots de autoasistencia que predecirán nuestro entorno futuro.
Todos los algoritmos de detección de objetos supervisados dependen de conjuntos de datos etiquetados, lo que significa que los humanos deben aplicar su conocimiento para entrenar la red neuronal en diferentes entradas. Label_maps puede obtener los objetos etiquetados en un conjunto de datos () funciones para inferir la categoría de objeto correcta.
¿Qué son los mapas de etiquetas?
El label-map() en la programación de Tensorflow asigna números de salida a la clase de objeto. Si la salida de un algoritmo de detección de objetos es 4, esta función escanea los datos de entrenamiento y devuelve la clase correspondiente al número "4". Si "4" se menciona como "avión", el texto de salida será "avión".
Aplicaciones de detección de objetos en diversas industrias
Hasta ahora, la detección de objetos ha logrado hazañas en dominios críticos como la seguridad, el transporte, la medicina y el ejército. Las empresas de software lo utilizan para recuperar y categorizar automáticamente grandes conjuntos de datos relacionales para aumentar la eficiencia de producción. Este proceso también se conoce como etiquetado de datos o anotación de datos.
Aquí hay algunas aplicaciones de la vida real que citan la importancia de los sistemas de detección de objetos impulsados por IA:
- Policía y forense: La detección de objetos puede rastrear y localizar objetos específicos como una persona, vehículo o mochila de cuadro a cuadro. Permite a los oficiales de policía y profesionales forenses inspeccionar cada rincón y esquina de un sitio del crimen para recopilar pruebas evidenciales. Sin embargo, debido al gran volumen de datos, el proceso de detección de objetos es un poco complicado y requiere horas de metraje para identificar qué puede ayudar en el éxito de un caso.
- Pago sin contacto: Muchos restaurantes utilizan el seguimiento de objetos RFID para calcular el monto del cheque escaneando platos vacíos. Este proceso agrega automáticamente el precio de todos los artículos al total y elimina las transacciones habituales en efectivo y crédito en un restaurante.
- Inventario y almacenamiento: Los profesionales de logística pueden detectar, clasificar y recoger fácilmente productos terminados para el transporte a través de la detección de objetos en tiempo real. Algunas empresas incluso han desarrollado almacenamiento automático para navegar más fácilmente por los estantes de los almacenes. También puede automatizar y regular la gestión de la cadena de suministro al rastrear los niveles de inventario para determinar el flujo de producción óptimo.
- Sistema de estacionamiento: Los detectores visuales preintegrados en los automóviles pueden detectar espacios de estacionamiento abiertos en lotes de superficie o garajes de estacionamiento. También puede proporcionar al conductor una vista frontal y trasera del espacio de estacionamiento y otros vehículos para estacionar el automóvil de manera segura.
- Respuesta a desastres: Las recientes fluctuaciones en nuestros ecosistemas, como el deterioro de la capa de ozono, el aumento de los gases de efecto invernadero y el calentamiento global, han llevado a los desarrolladores e ingenieros a crear aplicaciones de detección de objetos. Al ajustar finamente las redes neuronales y utilizar herramientas esenciales, se pueden construir modelos rápidos y precisos para la respuesta y gestión de desastres.
- Reconocimiento biométrico y facial: Los controles de seguridad en aeropuertos emplean reconocimiento facial cerca de las puertas de salida para atestiguar la identidad de los viajeros. Los dispositivos de reconocimiento facial comparan documentos de identidad con otras tecnologías biométricas, como huellas dactilares, para prevenir el fraude y el robo de identidad. Durante las transferencias internacionales, los departamentos de inmigración y aduanas utilizan coincidencias faciales para comparar el retrato del viajero con la foto en el pasaporte.
Las 5 principales plataformas de reconocimiento de imágenes
- API de Cloud Vision
- Amazon Rekognition
- Google Cloud AutoML vision
- Kit de herramientas de reconocimiento de gestos
- Syte
*Estos son los 5 principales software de reconocimiento de imágenes según el Informe de G2 Fall 2024 Grid en diciembre de 2024

Un escudo para la visión humana
La detección de objetos no es solo el resultado de la generación de supercomputadoras; también es una promesa de un futuro seguro para la humanidad. Además de alimentar máquinas con visión habilitada por IA, ha descubierto, analizado y desentrañado nuestros problemas mundanos mejor de lo que lo hemos hecho nosotros.
La detección de objetos puede que no sea extensa, todavía. Pero ha abierto el camino inicial del éxito a través de cadenas de negocios. No hay vuelta atrás desde aquí.
Explora cómo la IA se está extendiendo más allá de los límites con software de texto a voz para apoyar a personas con discapacidad visual y mejorar la accesibilidad de datos.Este artículo fue publicado originalmente en 2022. Ha sido actualizado con nueva información.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

