



Usé Grammarly para ayudarme a escribir este artículo. Grammarly utilizó el procesamiento del lenguaje natural para ayudarme a que este artículo se vea genial.
Así de prevalentes se han vuelto los casos de uso del procesamiento del lenguaje natural. Las tecnologías de PLN han recorrido un largo camino, desde escribir un artículo y transcribir llamadas de ventas hasta recuperar grandes cantidades de información relevante y comprender verdaderamente lo que el usuario quiere decir.
La evolución de la lingüística computacional ha facilitado que las máquinas entiendan los idiomas humanos, reduciendo las brechas entre las interacciones humano-computadora. El software de procesamiento del lenguaje natural mejora la experiencia del cliente, automatiza las entradas de datos, mejora las recomendaciones de búsqueda y fortalece los esfuerzos de seguridad en todas las industrias.
¿Qué es el procesamiento del lenguaje natural?
El procesamiento del lenguaje natural (PLN) es una tecnología de inteligencia artificial (IA) que permite a los programas de computadora interpretar texto y palabras habladas para entender mejor el lenguaje humano.
El PLN utiliza algoritmos de aprendizaje automático (ML), modelado basado en reglas y modelos de aprendizaje profundo para ayudar a las computadoras a procesar datos de lenguaje para analizar la intención y el sentimiento de los mensajes.
Si has usado la navegación GPS para orientarte en una nueva ciudad o has gritado a través de la habitación a un asistente de voz para encender las luces, ¡felicidades, has conocido un programa de PLN!
Gracias al procesamiento del lenguaje natural, las aplicaciones informáticas pueden responder a comandos hablados y resumir grandes cantidades de texto en tiempo real para interactuar con los humanos de manera significativa y expresiva.
¿Cómo funciona el PLN?
El PLN está a nuestro alrededor, incluso si no necesariamente lo notamos. Asistentes virtuales, chatbots de servicio al cliente, modelos transformadores, texto predictivo: todo es posible gracias a la tecnología de PLN que entiende y filtra nuestras solicitudes. Los programas conectan computadoras y humanos para organizar operaciones comerciales, revitalizando la productividad a través de interacciones finamente ajustadas.
Las técnicas de entrenamiento de PLN se basan en el aprendizaje profundo y algoritmos para interpretar y dar sentido al lenguaje humano.
Los modelos de aprendizaje profundo procesan datos no estructurados o datos cualitativos que no pueden ser analizados usando herramientas convencionales como la voz y el texto. Los transforman en datos estructurados que pueden encajar en bases de datos con las que estamos familiarizados para proporcionar información útil.
El procesamiento del lenguaje natural extrae información contextual descomponiendo el lenguaje en palabras individuales e identificando sus relaciones. Hacer esto permite un proceso de indexación y segmentación más preciso, uno basado en el sentimiento y la intención.
Antes de que un modelo pueda procesar cualquier dato de texto, debe preprocesarlo en un formato que la máquina pueda comprender. Hay varias técnicas de procesamiento de datos disponibles.
Tokenización
La tokenización, el primer paso para convertir datos en bruto en un formato que la máquina pueda comprender, consiste en dividir el texto en unidades más pequeñas conocidas como tokens. La máquina entiende fácilmente el texto una vez que se descompone en palabras o frases. Dado que las máquinas solo entienden datos numéricos, el texto tokenizado se representa como tokens numéricos para los programas.
Ejemplo:
Considera el siguiente texto ingresado por un usuario:
"Hay un banco al otro lado del puente."
Texto entendido por la máquina después de la tokenización:
["Hay", "un", "banco", "al", "otro", "lado", "del", "puente", "."]
Eliminación de palabras vacías
El siguiente paso de preprocesamiento en PLN elimina palabras comunes con poco o ningún significado específico en el texto. Estas palabras, conocidas como palabras vacías, incluyen artículos (el/un/una), "es", "y", "son", y así sucesivamente. Este paso elimina palabras no útiles y proporciona una comprensión significativa, eficiente y precisa del texto.
Ejemplo:
Considera el mismo texto de muestra ingresado por un usuario:
"Hay un banco al otro lado del puente."
Texto entendido por la máquina después de eliminar las palabras vacías:
["Hay", "banco", "otro", "lado", "puente", "."]
Stemming y lematización
Stemming y lematización se refieren a las técnicas que las aplicaciones de PLN utilizan para simplificar palabras y análisis de texto reduciéndolas a su forma base.
Stemming es un enfoque basado en reglas que elimina prefijos y sufijos para devolver las palabras a sus formas fundamentales o raíces. El proceso no requiere mucha potencia computacional, y las palabras base resultantes pueden no tener siempre sentido, pero ayudan al programa a facilitar el análisis de texto.
Por ejemplo, la palabra "compartiendo" resultará en una raíz "compart".
Una limitación del stemming es que varias palabras semánticamente no relacionadas pueden accionista compartir una raíz.
Lematización es un enfoque basado en diccionario para convertir palabras a su forma morfológica, también conocida como lema. El proceso requiere un alto esfuerzo computacional debido a la necesidad de consultas de diccionario. El lema resultante siempre será una palabra válida contextualmente y como parte del discurso.
Por ejemplo, la palabra "compartiendo" resultará en un lema "compartir".
Extracción de características
Dado que nuestros amigos las máquinas solo entienden números y algoritmos, el texto en bruto que ingresamos debe convertirse en representaciones numéricas. La extracción de características ayuda a retener la información relevante y, al mismo tiempo, reduce la complejidad de los datos para capturar solo los patrones y relaciones más necesarios.
Se pueden utilizar diferentes técnicas para lograr este resultado según la tarea de PLN.
- Bolsa de Palabras solo considera la presencia o ausencia de palabras creando un espacio vectorial del texto. La representación del texto se realiza a través de la frecuencia de palabras en lugar del orden de las palabras.
- Frecuencia de Término-Inversa Frecuencia de Documento (TF-IDF) tiene en cuenta la importancia de cada palabra en el conjunto de datos. Las palabras que ocurren con frecuencia se valoran más.
- Embeddings de palabras capturan relaciones semánticas entre palabras, creando una representación vectorial densa. Ejemplos incluyen Word2Vec y GloVe.
- Modelado de temas extrae temas similares del texto para representar documentos distribuidos por temas. Un ejemplo de esta técnica incluye Latent Dirichlet Allocation (LDA).
Los algoritmos de PLN son generalmente basados en reglas o entrenados en modelos de aprendizaje automático. El entrenamiento continuo y los bucles de retroalimentación pueden crear grandes reservorios de conocimiento, predecir mejor la intención humana y minimizar respuestas falsas.
¿Cuáles son las tareas comunes de PLN?
El procesamiento del lenguaje natural utiliza técnicas o tareas de IA para procesar, comprender y generar lenguaje natural (humano). Mejoran la interacción humano-computadora y facilitan la comunicación efectiva a través de aplicaciones basadas en el lenguaje.
Etiquetado de partes del discurso
¿Sabes quién no ha olvidado sus lecciones de gramática de sexto grado? El PLN.
El etiquetado de partes del discurso (POS), o etiquetado gramatical, permite a las aplicaciones de PLN identificar palabras individuales en una oración para determinar su significado en el contexto de esa oración. Esto permite a las computadoras diferenciar entre sustantivos, verbos, adjetivos y adverbios y entender sus relaciones.
Como se muestra en el ejemplo a continuación, el etiquetado POS significa que los programas de PLN tienen el poder de contextualizar el verbo "gustar" en la frase "Me gusta la playa" e identificar "como" como un adverbio en la oración "Soy como Mark".
.png)
Desambiguación del sentido de las palabras
El concepto no es tan complicado como parece; simplemente significa que los programas de PLN pueden identificar el significado intencionado de la misma palabra cuando se usa en diferentes contextos.
A través del análisis semántico (es decir, la extracción de significado del texto y el análisis), las computadoras pueden interpretar oraciones y relaciones entre palabras individuales para tener el mayor sentido en un contexto particular.

La palabra "bark" en el ejemplo anterior tiene dos significados diferentes.
Las aplicaciones de PLN distinguen entre el ladrido de un perro y la corteza de un árbol a través de la desambiguación del sentido de las palabras.
Reconocimiento de entidades nombradas
Las aplicaciones de procesamiento del lenguaje natural pueden identificar palabras para categorías específicas, como nombres de personas, lugares y nombres de organizaciones. A través del reconocimiento de entidades nombradas (NER), el software de PLN extrae entidades y comprende su relación con el resto del texto.
.png)
En el ejemplo anterior, la tarea de PLN de reconocimiento de entidades nombradas identifica "Microsoft" y "Bill Gates" como una organización y una persona, respectivamente.
Aplicaciones del reconocimiento de entidades nombradas
- Extracción de hechos de noticias falsas: NER puede identificar entidades importantes que pueden ayudar a verificar fuentes de noticias.
- Recuperación de información: Para ayudar a crear sistemas de recuperación donde los usuarios puedan buscar información específica para acceder a documentos relevantes.
Resolución de correferencias
Tareas de PLN de alto nivel, como responder preguntas y recuperar información (más sobre eso más adelante), requieren que las computadoras identifiquen todas las palabras que se refieren a la misma entidad. Este proceso, conocido como resolución de correferencias, ayuda a los programas a determinar personas/objetos conectados a pronombres específicos.
La resolución de correferencias también es la razón por la que las computadoras saben cuándo una expresión idiomática es parte de un texto.
Reconocimiento de voz
Los programas de PLN se benefician de entender el proceso de convertir el lenguaje hablado en, más o menos, lenguaje de computadora. El reconocimiento de voz es esencial para facilitar interacciones humano-computadora naturales e intuitivas.
Veamos un par de ejemplos de reconocimiento de voz como parte del procesamiento del lenguaje natural.
- Asistentes de voz: Nuestros mejores amigos virtuales Siri, Alexa y Google Assistant responden a nuestros comandos utilizando técnicas de reconocimiento de voz para proporcionar respuestas relevantes.
- Transcripción y dictado: Las transcripciones de grabaciones de audio y las conversiones de lenguaje hablado a texto son fundamentales para los sectores de creación de contenido, legal y educativo.
- Preprocesamiento de datos: El reconocimiento de voz es importante para transformar datos en bruto en una forma más comprensible. El preprocesamiento se puede realizar para datos de audio y datos textuales.
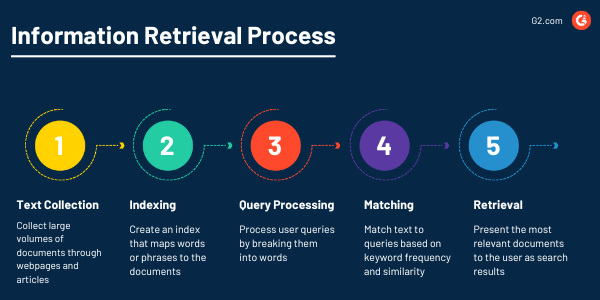
Recuperación de información
Los programas de PLN siempre encontrarán ese documento importante justo cuando lo necesites debido a su poderosa capacidad para recuperar información de grandes conjuntos de datos. El objetivo de la recuperación de información como tarea de PLN es ofrecer a los usuarios información precisa y útil de la colección de texto a través de minería de texto.
Análisis de sentimientos
¿Alguna vez te has preguntado cómo los bots de servicio al cliente casi siempre pueden saber cómo te sientes? Todo es gracias al análisis de sentimientos, un proceso automatizado que reconoce el tono emocional y los sentimientos expresados en varios casos de uso.
Los modelos de aprendizaje automático pueden ser entrenados en análisis de sentimientos utilizando clasificación de etiquetado de sentimientos (positivo, negativo, neutral), post-procesamiento y evaluación de sentimientos.
El análisis de sentimientos es una excelente manera para que las empresas obtengan información del cliente a través de reseñas de productos y monitoreen sus marcas basándose en los sentimientos de las redes sociales.
Traducción automática
La tarea de PLN de traducir automáticamente texto o contenido hablado de un idioma a otro se utiliza mucho en software de traducción automática. La traducción automática tiene como objetivo proporcionar traducciones precisas y coherentes manteniendo la precisión contextual.
Los modelos de traducción también utilizan el reconocimiento de voz. Están diseñados para mejorar la comunicación global y romper las barreras del idioma en los negocios, la educación, la atención médica y las relaciones internacionales.
Detección de spam
¿Alguna vez pensaste que un correo electrónico era legítimo y respondiste, pero resultó ser solo spam? Yo también.
La tarea de PLN de reconocer automáticamente mensajes irrelevantes de un gran grupo de mensajes, como correos electrónicos y publicaciones en redes sociales, y eliminarlos se llama detección de spam.
El proceso ayuda a distinguir mensajes fraudulentos de los genuinos y garantiza la seguridad de los usuarios en las plataformas de comunicación.
Bibliotecas y marcos de PLN
Los lenguajes de programación son para el PLN lo que una polilla es para una llama. Aunque muchos lenguajes y bibliotecas admiten tareas de procesamiento del lenguaje natural, existen algunos populares.
Python
El lenguaje de programación más utilizado para tareas de PLN, bibliotecas y marcos de aprendizaje profundo está escrito para Python.
- Toolkit de Lenguaje Natural (NLTK): Una de las primeras bibliotecas de PLN escritas en Python, el NLTK es conocido por sus interfaces fáciles de usar y bibliotecas de procesamiento de texto para etiquetado, stemming y análisis semántico.
- spaCy: Una biblioteca de PLN de código abierto, spaCy proporciona vectores preentrenados. Puedes usarlo para NER, etiquetado de partes del discurso, clasificación y análisis morfológico.
- Bibliotecas de aprendizaje profundo: PyTorch y TensorFlow son herramientas comunes para desarrollar modelos de datos de PLN.
R
Los estadísticos utilizan ampliamente el lenguaje de programación para modelos de PLN de computación estadística y gráficos escritos en R. Esto incluye Word2Vec y TidyText.
Aplicaciones empresariales del PLN
Las técnicas de procesamiento del lenguaje natural se utilizan en muchos casos empresariales para mejorar la eficiencia operativa, la productividad y los procesos críticos para la misión.
Chatbots y asistentes virtuales
El auge de la IA conversacional ha transformado la forma en que los chatbots y los asistentes virtuales interactúan con los humanos, especialmente en el servicio al cliente.
El PLN impulsa las capacidades humanas de los chatbots para escalar el soporte al cliente automatizado mientras mantiene operaciones económicas. Los bots de chat y voz pueden ofrecer recomendaciones personalizadas y funcionalidades de chat localizadas para ayudar en el proceso de compra, responder preguntas frecuentes y asistir a los usuarios en tiempo real.
Las funciones de voz a texto también son beneficiosas para rastrear análisis de centros de llamadas para transcribir datos de voz en texto.
Monitoreo de redes sociales
El análisis de sentimientos en plataformas sociales ayuda a evaluar los comentarios y reseñas de los clientes para comprender la satisfacción del consumidor a través de valiosos conocimientos de datos.
Las herramientas de monitoreo de redes sociales están impulsadas por el procesamiento del lenguaje natural para otorgar funcionalidades de escucha, seguimiento y recopilación de contenido. Estas aplicaciones se utilizan ampliamente para realizar investigaciones de mercado, realizar análisis de tendencias e identificar patrones en diferentes redes sociales.
Extracción de información y detección de fraudes
Las industrias de la salud y legal utilizan la tecnología de PLN para extraer datos de alta calidad y relevantes de grandes volúmenes de datos de ensayos clínicos, literatura científica y contratos legales.
Al igual que con la detección de spam, la tecnología de PLN puede detectar actividades fraudulentas al percibir patrones en los datos. Esto es especialmente útil en el sector financiero para monitorear transacciones.
PLN vs. NLU vs. NLG
Si bien solo hay un término diferenciador en el procesamiento del lenguaje natural, la comprensión del lenguaje natural y la generación del lenguaje natural, existen algunas diferencias entre los tres conceptos.
Procesamiento del lenguaje natural
El PLN es una rama de la IA que ayuda a las computadoras a entender, interpretar y generar lenguaje humano. Las tareas comunes de PLN incluyen el reconocimiento de voz, el análisis de sentimientos y el reconocimiento de entidades nombradas.
El PLN se utiliza ampliamente en la asistencia por voz para resumir grandes cantidades de texto y servicios de traducción.
Comprensión del lenguaje natural (NLU)
Un subconjunto del PLN, el software de NLU se centra en la comprensión del texto para extraer significado de los datos. Combina lógica de software, lingüística, ML e IA para dar sentido al lenguaje natural.
Las tareas comunes de NLU incluyen:
- Reconocimiento de intenciones. Los modelos de NLU se utilizan para identificar la intención de diferentes entidades para propósitos de clasificación y categorización de texto. Por ejemplo, crear diferentes secciones para noticias, entretenimiento y negocios de una empresa.
- Análisis de contenido. Comprendiendo las conexiones entre piezas de contenido, el NLU puede realizar un análisis en profundidad de entidades para resaltar sentimientos y relaciones complejas.
- Búsqueda cognitiva. El NLU analiza y extrae datos no estructurados, permitiéndole extraer información relevante de conjuntos de datos diversos. Esto mejora los resultados de las consultas de búsqueda y proporciona información relevante de intención utilizando análisis predictivo.
Top 5 software de NLU
1. Amazon Comprehend2. IBM Watson Natural Language Classifier
3. Azure Translator Speech API
4. Azure Translator Text API
5. Apace cTAKES
*Estos datos fueron extraídos del Informe de Verano de G2 el 19 de julio de 2023, basado en nuestra metodología de puntuación.
Generación del lenguaje natural (NLG)
En el otro extremo del NLU está la tecnología NLG, la rama de la IA que genera texto escrito o hablado a partir de un conjunto de datos. Permite a las computadoras proporcionar retroalimentación a los humanos en un lenguaje que es comprensible para nosotros, no para las máquinas.
Las tareas comunes de NLG incluyen:
- Conversión de datos. Los modelos de NLG convierten datos estructurados en textos legibles para humanos.
- Interacciones con el cliente. Estas proporcionan respuestas que suenan a lenguaje natural, coincidencia de sentimientos y comunicaciones personalizadas con el cliente.
Top 5 software de NLG
1. Anyword2. Quill
3. AX Semantics
4. Wordsmith
5. Phrazor by vPhrase
*Estos datos fueron extraídos del Informe de Verano de G2 el 19 de julio de 2023, basado en nuestra metodología de puntuación.

Desbloqueando el misterio del lenguaje natural
Si bien el PLN puede parecer un hechicero, no lo es. Combina varias habilidades computacionales poderosas que lo hacen útil en muchas tareas que hacen que las tareas humanas sean más eficientes.
Ya sea a través de saludos de chatbots o resúmenes de texto, el mundo del PLN continúa esforzándose por proporcionar valiosos conocimientos a partir de grandes conjuntos de datos de lenguaje humano. Las tecnologías de PLN están haciendo nuestras vidas personales y profesionales más atractivas, personalizadas e interactivas mientras navegamos por nuestro nuevo mundo centrado en los datos.
Una de las funcionalidades de PLN más populares es su uso en asistentes de voz. Aprende más sobre cómo funciona el reconocimiento de voz y las características que ofrece que te permiten gritarle comandos.
Este artículo fue publicado originalmente en 2019. Ha sido actualizado de acuerdo con nuevas pautas editoriales, con nuevos recursos y ejemplos recientes.

Aayushi Sanghavi
Aayushi Sanghavi is a Campaign Coordinator at G2 for the Content and SEO teams at G2 and is exploring her interests in project management and process optimization. Previously, she has written for the Customer Service and Tech Verticals space. In her free time, she volunteers at animal shelters, dances, or attempts to learn a new language.

