



Cada segundo del día, el mundo accede, cambia y depende de los datos.
Funciones diarias como comprar un billete de tren o salir a almorzar con compañeros de trabajo implican el procesamiento de datos. Las organizaciones y los individuos necesitan datos para gestionar negocios, sin importar si consisten en 30 o 3,000 personas. Los datos están realmente en todo lo que hacemos y nos siguen a donde quiera que vayamos.
Es precisamente por eso que proteger tus datos es tan importante. Una simple copia de seguridad de los datos de tu negocio puede salvarte de la amenaza de posibles hackers, de descargar accidentalmente un virus e incluso de desastres naturales.
Existen docenas de maneras de proteger tus datos de ser comprometidos. Uno de esos métodos es la replicación de datos.
¿Qué es la replicación de datos?
La replicación de datos es el proceso de almacenar tus datos en más de una ubicación. El proceso crea múltiples copias de una base de datos para protegerla mejor de un evento de pérdida de datos. La replicación de datos como proceso es más útil para mejorar la accesibilidad de los datos. Todos los usuarios con acceso podrán compartir exactamente los mismos datos, sin importar dónde se encuentren en el mundo.
Los datos empresariales cambian cientos, a veces miles de veces en un solo día. Muchas organizaciones prefieren la replicación de datos debido a lo conveniente que hace compartir datos a través de oficinas y continentes. En este artículo, profundizaremos en cómo funciona, los diferentes tipos y métodos, y los beneficios y desafíos que vienen con cada uno.
¿Por qué usar la replicación de datos?
La replicación de datos es un método de respaldo atractivo por dos razones principales: su seguridad y su rápida conveniencia. El método ayuda a las organizaciones a mantener múltiples copias actualizadas de sus datos, distribuyéndolos a centros de datos cercanos a oficinas remotas.
Mantener más de una copia mejora la seguridad de los datos en caso de un desastre. Si una copia se daña, existe otra versión exacta en otro lugar.
No te equivoques, la replicación de datos no es una copia estática de tus datos. De manera similar a la protección continua de datos, la replicación de datos siempre está procesando tus datos de manera continua para que cada copia, sin importar dónde se encuentre, sea siempre precisa y esté actualizada para reflejar su fuente original.
El resultado final es una multitud de copias de datos en diferentes ubicaciones a las que los usuarios pueden acceder sin tener que preocuparse por estropear los datos de sus colegas.
Debido a que la replicación de datos gestiona múltiples ubicaciones de datos, también puede ayudar a los usuarios a acceder a los datos mucho más rápido. Puede ser especialmente útil si una organización tiene un número sustancial de oficinas internacionales.
Supongamos que trabajas en Asia pero la sede de tu empresa y la fuente original de datos están ubicadas en América del Norte. Puedes experimentar latencia de datos al acceder a datos desde un centro de datos a miles de millas de distancia. Al usar la replicación de datos para colocar otra réplica más cerca de los usuarios internacionales, les ahorras tiempo y frustración.
Replicar datos también ayudará a mejorar el rendimiento del servidor. Si tu organización ejecuta múltiples copias de datos en múltiples servidores de datos, todos los usuarios pueden acceder a los datos mucho más rápido. Además, al guardar todas las operaciones de lectura en una réplica del original, podrás ahorrar ciclos de procesamiento en el servidor principal para operaciones de escritura de mayor importancia.
Uno de los usos más comunes de la replicación de datos es para la recuperación ante desastres. Similar a la protección continua de datos, la replicación de datos asegura que siempre exista una copia de seguridad actualizada en caso de falla de hardware, daño físico o una violación del sistema que ponga en riesgo tus datos.
El software de recuperación ante desastres ayuda a las empresas a recuperar rápidamente y de manera eficiente software, configuraciones y datos a un estado anterior en caso de falla de una computadora, servidor o infraestructura. Descubre una lista imparcial de las mejores herramientas de hoy en G2 en el enlace anterior.
¿Quieres aprender más sobre Replicación de datos Software? Explora los productos de Replicación de datos.
¿Cómo funciona la replicación de datos?
La replicación de datos implica copiar datos de una ubicación y crear otra versión exacta en otra ubicación. Por ejemplo, los datos pueden replicarse entre dos servidores locales, entre servidores en diferentes ubicaciones, a través de múltiples medios de almacenamiento en el mismo servidor y hacia y desde un host basado en la nube.
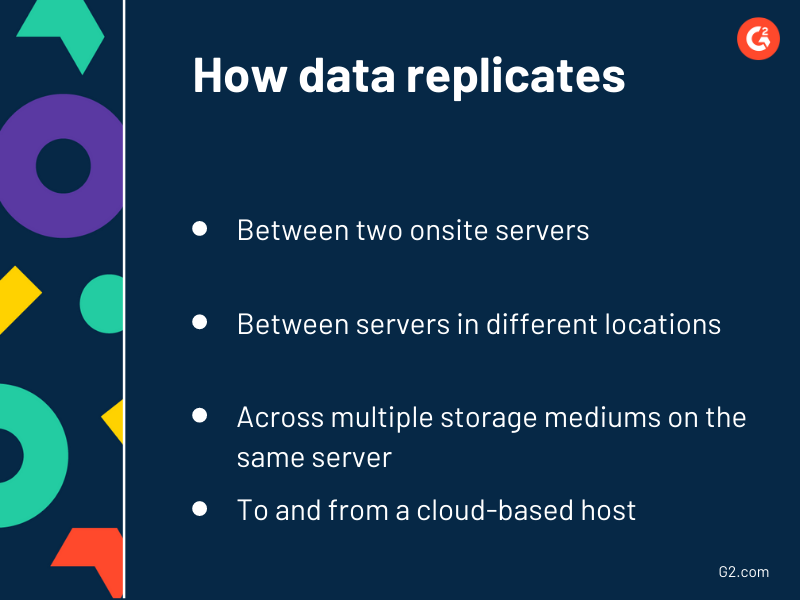
Tendrás la opción de copiar datos instantáneamente, transferirlos en grandes bloques o pequeños lotes, establecer un horario para cuando quieras que se muevan los datos y replicar datos en tiempo real a medida que los datos del servidor maestro se escriben, cambian o eliminan por completo.
Además, puedes usar la replicación completa donde se copia una base de datos completa en cada ubicación del servidor, o la replicación parcial donde solo algunos de los datos más utilizados se replican a través de los servidores. Hablaremos más sobre estos tipos de replicación más adelante.
Nota: La replicación de datos puede ocurrir a través de una red de área local, una red de área de almacenamiento, una red de área local amplia o a través de la nube.
El proceso de replicación de datos
Utilizar la replicación de datos solo será útil si hay copias exactas de tus datos almacenadas en todos los servidores. Ese es el objetivo completo del método de respaldo. Al igual que harías con cualquier otro método, seguir un proceso de replicación te ayudará a mantener los datos seguros y consistentes en cada ubicación.
El proceso seguiría más o menos estos pasos:
- Identifica tu fuente de datos y dónde quieres que se replique.
- Elige los archivos, carpetas y aplicaciones que deseas copiar desde la fuente.
- Planifica tu horario de respaldo y con qué frecuencia deseas que se realicen las copias de seguridad.
- Decide si usarás replicación de tabla completa, basada en claves o basada en registros.
- Si usas replicación basada en claves, identifica las claves de replicación (columnas que si cambian en la fuente copiarán los registros de los que forman parte en el proceso).
- Usa una herramienta de replicación o escribe un código personalizado para comenzar el proceso de replicación.
- Vigila el proceso de respaldo para asegurarte de que todo se respalde correctamente.
Ventajas de la replicación de datos
Algunos de los beneficios más obvios de la replicación de datos incluyen su papel en la recuperación ante desastres y el fácil acceso a datos y aplicaciones empresariales cruciales. En caso de un desastre o daño a la fuente principal, una copia replicada de los datos estará allí para mantener los flujos de trabajo en movimiento como de costumbre.
Debido a que los datos existen en múltiples ubicaciones y en múltiples servidores, la replicación de datos ayuda a facilitar el intercambio de datos a gran escala. También distribuye el estrés de la carga de la red entre cada sitio del servidor de datos.
Algunas ventajas adicionales que las organizaciones pueden esperar al usar la replicación de datos incluyen:
- La replicación de datos mantiene tus datos consistentes y siempre actualizados sin importar desde dónde los usuarios intenten acceder.
- Puedes esperar un aumento en la disponibilidad de datos. Si un sistema falla, es atacado o se corrompe, podrás acceder a tus datos desde otro sitio.
- Implementar la replicación de datos puede potencialmente minimizar el trabajo del departamento de TI al crear y mantener las transacciones de replicación de datos de la organización.
- Verás un mejor rendimiento general de la red al usar la replicación de datos. Al almacenar tus datos en múltiples ubicaciones (especialmente si tu organización tiene oficinas internacionales), tus empleados no experimentarán tanta latencia de acceso a los datos. Debido a que los datos se almacenan cerca de ellos, se cargarán más rápido.
- Verás un aumento en el rendimiento del sistema de prueba. Las herramientas de replicación de datos pueden hacer que la sincronización y distribución de datos para sistemas de prueba sea mucho más rápida y fácil.
- La replicación de datos puede aumentar el soporte de análisis de datos. Copiar datos a un almacén de datos dará a los equipos de análisis el soporte para trabajar en proyectos de inteligencia empresarial.
Las plataformas de inteligencia empresarial permiten a las empresas analizar datos y revelar ideas accionables que pueden ayudar a mejorar la toma de decisiones e informar la estrategia. Las plataformas de BI se conectan a bases de datos, almacenes de datos o distribuciones de big data y ofrecen a los analistas la capacidad de experimentar con datos para descubrir ideas.
Desventajas de la replicación de datos
Hemos visto que la replicación de datos tiene un buen número de ventajas, pero las organizaciones siempre deben evaluar las desventajas que pueden enfrentar al implementar una nueva herramienta. Uno de los desafíos más comunes con la replicación de datos puede surgir de la demora de datos o interrupciones del servicio mientras los datos se transfieren o respaldan.
Además, a medida que aumenta la distancia entre los sistemas de datos replicados y la copia original, el proceso de replicación de datos puede volverse más exigente.
Algunas desventajas adicionales que las organizaciones pueden esperar al usar la replicación de datos incluyen:
- Mantener todos los datos actualizados puede ser un desafío. Cuantas más ubicaciones almacenes tus datos, más tendrás que implementar sistemas complejos para hacer un seguimiento de qué es qué.
- Necesitarás más espacio de almacenamiento a medida que tus datos continúen creciendo. Este espacio puede costarte una buena parte del presupuesto de tu equipo.
Cuando se trata de ello, los desafíos principales que enfrentarás al usar la replicación de datos se reducen a recursos limitados.
- Cuando usas herramientas de replicación de datos, mantener un número de réplicas en unas pocas, tal vez incluso una docena de ubicaciones puede llevar a tu organización a gastar más dinero en costos de procesador y almacenamiento más altos.
- Alguien tiene que estar a cargo del proceso de respaldo. Implementar la replicación de datos en el proceso de respaldo de una organización lleva tiempo para que el equipo dedicado lo perfeccione.
- Mantener todas las copias de datos consistentes requiere una revisión de los procedimientos y aumenta el tráfico de la red, lo que potencialmente ralentiza el trabajo.
Tipos de replicación
Cuando se trata de replicación, hay tres tipos principales entre los que puedes elegir, cada uno con diferentes ventajas. Asegurarte de saber cuál funcionaría mejor para tu organización es un gran comienzo para usar herramientas de replicación de datos.
1. Replicación transaccional
Al usar la replicación transaccional, recibirás una copia completa de tu base de datos y se te enviarán continuamente actualizaciones a medida que tus datos cambien. Esto facilita el seguimiento de lo que se altera y si se pierden datos.
La consistencia transaccional está garantizada con este tipo de replicación. Los datos se replicarán en tiempo real y se enviarán desde el editor (el servidor principal) a los suscriptores (servidores secundarios) en el orden exacto en que ocurren.
La replicación transaccional no solo copia tus cambios de datos, sino que replica continuamente cada cambio con gran precisión. Normalmente, este tipo se usa en entornos de servidor a servidor.
2. Replicación de instantáneas
La replicación de instantáneas es cuando se toma una instantánea de la base de datos y se distribuye a través de los servidores. Los datos se envían exactamente como aparecen en un momento específico (el momento de la instantánea). Este tipo no toma nota de las actualizaciones de los datos; más bien, envía a los suscriptores (servidores secundarios) una vista general de los datos en un instante.
Normalmente, la replicación de instantáneas se usará cuando los cambios en los datos sean escasos. Este tipo de replicación es excelente cuando se realiza la sincronización inicial entre el editor y el suscriptor, pero tiende a ser un poco más lenta. Esto se debe a que cada instantánea enviada intenta mover múltiples registros de datos de un extremo al otro.
3. Replicación de fusión
Este tipo de replicación ocurre cuando dos o más bases de datos se combinan en una sola base de datos. La replicación de fusión permite que cualquier cambio en los datos se envíe desde el editor (servidor principal) a uno o más suscriptores (servidores secundarios).
Este tipo de replicación es el más complejo porque permite que tanto el editor como los suscriptores realicen cambios en la base de datos. Normalmente se usa en un entorno de servidor a cliente.
Técnicas de replicación de datos
Anteriormente, mencionamos las tres técnicas de replicación de datos: incremental basada en claves, de tabla completa e incremental basada en registros. Al hablar de la replicación de bases de datos, necesitarás conocer la diferencia entre los tres métodos para comprender completamente cómo funciona la replicación de datos.
1. Replicación de tabla completa
La replicación de tabla completa copiará cada pieza de datos desde la fuente original al destino. Esto incluye cualquier dato nuevo, existente y actualizado.
El principal inconveniente de esta técnica es que requiere más poder de procesamiento y resulta en un mayor estrés en la carga de la red. Debido a que copia todos los datos cada vez, esto puede hacer que sea más lenta que otras técnicas. El costo de la copia de seguridad aumentará a medida que tus datos continúen creciendo.
Esta técnica es más útil si los datos se eliminan regularmente de la fuente o si la fuente no tiene una columna adecuada para otras técnicas.
2. Replicación incremental basada en claves
La replicación incremental basada en claves solo actualizará los datos que se cambiaron desde la última actualización. Debido a que se copia cada vez menos datos durante estas actualizaciones, esta técnica de replicación de datos es más eficiente que la replicación de tabla completa.
La principal desventaja de la replicación incremental basada en claves es su incapacidad para replicar datos ya eliminados (ya que los datos se eliminan una vez que el original se elimina).
Nota: La replicación incremental basada en claves también se llama captura incremental de datos basada en claves y carga incremental basada en claves.
3. Replicación incremental basada en registros
La replicación incremental basada en registros es una técnica única. Solo funciona para fuentes de bases de datos y replica datos basados en información del archivo de registro de la base de datos (un archivo que registra cambios en la base de datos). La basada en registros es la más eficiente de las tres técnicas, pero debe tener soporte de la base de datos de origen.
Esta técnica de replicación será la más adecuada para ti si la estructura de tu base de datos de origen es relativamente estática. Si los tipos de datos cambian o se eliminan columnas, toda la configuración del sistema basado en registros tendrá que actualizarse para reflejar esos cambios. Esto suele ser una pérdida de tiempo para todas las partes involucradas.
Debido a esto, la replicación de tabla completa o basada en claves puede ser más adecuada para tus necesidades si sabes que la estructura de tu base de datos de origen cambiará con frecuencia.
Esquemas de replicación
Las organizaciones pueden llevar a cabo la replicación de datos siguiendo un esquema para mover los datos. Se diferencian de las técnicas mencionadas anteriormente porque no se utilizan como una estrategia continua para mover datos. Más bien, deciden cómo se pueden replicar los datos para satisfacer las necesidades específicas de un negocio. Los datos se pueden mover de un solo golpe o en secciones.
Hay tres esquemas principales de replicación que se utilizan en la replicación de datos.
1. Replicación completa
La replicación completa de la base de datos es cuando toda la base de datos se replica para múltiples usuarios. Los datos estarán accesibles para casi todas las ubicaciones o usuarios en la red.
Este esquema ofrece la mejor disponibilidad de datos y puede ayudar con problemas internacionales. Si un usuario tiene dificultades para acceder a datos desde el servidor europeo de la organización, puede acceder a los mismos datos desde otros servidores en todo el mundo como respaldo.
Ventajas de la replicación completa
- Mejora la disponibilidad general de datos en todo el sistema porque todo puede operar normalmente mientras al menos un sitio esté funcionando.
- La ejecución de consultas es más rápida.
- Debido a que los datos se pueden tomar de cualquier sitio, hay una mayor tasa de recuperación de consultas globales.
Desventajas de la replicación completa
- Debido a que se debe realizar una actualización en todas las bases de datos para mantener copias exactas de los datos, la actualización tomará más tiempo.
- El control de concurrencia es difícil de lograr ya que los datos siempre están cambiando.
2. Sin replicación
En la no replicación, tus fragmentos se almacenarán en un solo sitio. Esto puede dificultar que los usuarios lejos de ese sitio accedan a la información regularmente.
Ventajas de la no replicación
- Los datos son más fáciles de recuperar.
- La concurrencia se puede lograr con este esquema.
Desventajas de la no replicación
- La ejecución de consultas puede ser más lenta porque múltiples usuarios están accediendo a un servidor.
- Debido a que no hay replicación, los datos no están fácilmente disponibles.
3. Replicación parcial
La replicación parcial replica solo algunos fragmentos de la base de datos. En este esquema, los datos en la base de datos se dividen en secciones. Cada sección se almacena en diferentes ubicaciones según la frecuencia con la que se accede a ella en esa ubicación. Piénsalo como un sistema que analiza qué datos son más importantes para cada ubicación. Si la oficina china está usando un conjunto específico de hojas de cálculo mientras que la ubicación norteamericana rara vez lo hace, esos datos solo se replicarán en la ubicación china.
La replicación parcial es más útil para las personas que trabajan en finanzas y ventas. Pueden llevar partes de su base de datos con ellos en laptops y otros dispositivos y sincronizarlas cuando necesiten datos del servidor de datos principal. La replicación parcial mantiene los datos importantes cerca de los usuarios que los necesitan. En caso de que un usuario necesite acceder a datos que normalmente no toca, siempre se mantendrá un archivo maestro de datos en el servidor de la sede.
Ventajas de la replicación parcial
- La cantidad de réplicas de datos depende de la importancia de los datos en ese fragmento.
Desventajas de la replicación parcial
- Debido a que solo se replican fragmentos de ciertos datos en diferentes servidores, puede ralentizar el progreso cuando los usuarios necesitan acceder a datos que normalmente no usan desde el servidor principal.
Antes de implementar software de replicación de datos…
Antes de que decidas darle una buena oportunidad a la replicación de datos, hay algunas cosas que debes tener en cuenta.
Más uso de almacenamiento
Si las grandes organizaciones están considerando la replicación de datos, deben tomarse el tiempo para evaluar qué técnicas y esquemas quieren usar. Es probable que si la organización es grande, haya muchos datos que respaldar.
Almacenar datos de la empresa en múltiples lugares consumirá espacio de almacenamiento. Antes de avanzar, debes saber que más almacenamiento significa más dinero, lo que podría ser un factor decisivo.
La posibilidad de datos inconsistentes
Replicar datos en varias fuentes puede potencialmente causar inconsistencias. Si estás replicando datos en diferentes momentos y solo en ciertos servidores, la posibilidad de datos fuera de sincronización es alta, y puede ser difícil poner a todas las ubicaciones en la misma página. Los administradores deben crear un proceso de replicación personalizado y siempre verificar cada ubicación del servidor para garantizar la consistencia en todo el mundo.
La necesidad de mayor capacidad de red y poder de procesamiento
Aunque tener sitios de datos más cerca de los usuarios internacionales facilita el acceso a los datos para ellos, hay una desventaja. Gestionar múltiples ubicaciones puede afectar tu red y ralentizarla, así como consumir poder de procesamiento. Un proceso de replicación de datos más efectivo, adaptado específicamente a tu organización, puede ayudarte a gestionar esta carga aumentada.
Encuentra tu pareja perfecta
Puede ser desalentador comenzar la búsqueda de una solución de replicación de datos que funcione para tus necesidades particulares. Pero encontrar esa solución hará que el proceso sea mucho más fácil en el futuro.
Tu departamento de TI puede escribir código y gestionar el proceso de replicación por su cuenta, pero esto plantea su propio conjunto de dificultades. Necesitarás dedicar tiempo a mantener tus datos, gastar dinero en aplicaciones y tal vez incluso contratar a algunas personas adicionales para agilizar el proceso. Además, debes estar consciente de la siempre amenazante posibilidad de error humano.
Es por eso que la replicación de datos y la copia de seguridad de bases de datos son tan útiles. Las soluciones de copia de seguridad de bases de datos ayudan a las empresas a proteger sus datos con copias de seguridad en caso de datos corruptos, errores de usuario o fallas de hardware. Al utilizar soluciones de copia de seguridad de bases de datos, las empresas pueden asegurarse de que sus datos estén siempre disponibles, incluso si su base de datos principal falla.
Explora las soluciones de copia de seguridad de bases de datos mejor valoradas para encontrar la adecuada para tu organización.

Alexa Drake
Alexa is a former content associate at G2. Born and raised in Chicago, she went to Columbia College Chicago and entered the world of all things event marketing and social media. In her free time, she likes being outside with her dog, creating playlists, and dabbling in Illustrator. (she/her/hers)

