



Angenommen, Sie senden Ihren Kollegen ein wichtiges Dokument per E-Mail.
Ganz einfach, oder? Sie fügen das Dokument Ihrer E-Mail bei und drücken auf die Senden-Taste. Ihre Kollegen erhalten fast sofort die benötigten Daten.
Denken Sie nun an diesen Informationsaustausch in größerem Maßstab.
Ihr Unternehmen arbeitet mit Lieferanten, Herstellern, Kunden und Anbietern zusammen. Sie teilen alle möglichen Informationen wie Bestandsdaten, Produktwartungsinformationen, Bauzeichnungen, Simulationsmodelle, Qualitätsplanungsdaten, Verträge, kommerzielle Dokumente, Programmquellcodes – die Liste geht weiter. Und all diese Daten kommen in verschiedenen Formaten.
Wie normalisieren Sie dieses riesige Datenvolumen, ohne seine Bedeutung zu verändern? Hier kommt der Datenaustausch ins Spiel. Datenaustausch-Software bietet Data-as-a-Service (DaaS)-Funktionen, um Anbietern und Verbrauchern zu helfen, Informationen mühelos zu teilen und zu beschaffen. Dadurch können Unternehmen Marktinformationen sammeln und datengetriebene Entscheidungen mit minimalem Aufwand treffen.
Was ist Datenaustausch?
Datenaustausch ist der Prozess des Teilens von Daten zwischen Unternehmen, Stakeholdern und Datenökosystemen, ohne die inhärente Bedeutung während der Übertragung zu verändern. Der Datenaustausch transformiert Datensätze, um die Datenakquise zu vereinfachen und eine sichere Datenzusammenarbeit zu kontrollieren.
Datenaustausch sorgt für einen reibungslosen Datentransfer zwischen Datenlieferanten und -verbrauchern. Lieferanten, Datensyndikatoren und Makler teilen oder verkaufen Daten. Verbraucher sammeln oder kaufen Daten von Datenlieferanten.
Eine Datenaustauschplattform ermöglicht es Lieferanten und Verbrauchern, Daten auszutauschen, zu kommerzialisieren, zu beschaffen und zu verteilen. Diese Plattformen helfen Lieferanten und Verbrauchern, rechtliche, sicherheitstechnische, technische und Compliance-Anforderungen zu erfüllen.
Bedeutung des Datenaustauschs
Unternehmen produzieren, sammeln und erwerben riesige Datenmengen aus täglichen Operationen. Diese Erstanbieterdaten reichen jedoch kaum aus, um Geschäftsentscheidungen auf der Grundlage neuer Perspektiven zu treffen. Dann werden Unternehmen zu Datenverbrauchern. Sie nutzen überprüfbare Datenpunkte von Zweit- und Drittanbietern, um Informationslücken zu schließen, Daten zu analysieren und Intelligenzbedürfnisse zu erfüllen.
Auf der anderen Seite haben Datenverteiler, die Daten verkaufen, nicht immer so viele Informationen, wie sie benötigen. Sie nutzen den Online-Datenaustausch, um Informationsressourcen zu monetarisieren und Daten aus anderen Quellen zu erwerben. Wenn Daten nicht nützlich sind, monetarisieren Unternehmen sie. Die meisten Unternehmen nutzen Daten und verkaufen sie an andere Firmen.
Warum nutzen Unternehmen den Datenaustausch?
Unternehmen nutzen Datenaustauschsysteme, um:
- Geschäftsanalysen, Prognosen und Pläne zu verbessern
- Einblicke zu gewinnen, um potenzielle Kunden für Kampagnen zu finden
- Daten zu sammeln, um maschinelles Lernen oder statistische Modelle zu bereichern
- Klickstromdaten zu nutzen, um die Benutzererfahrung zu personalisieren und Empfehlungsmaschinen zu erstellen
- Demografische, soziale und psychografische Daten zu finden, um 360°-Kundenansichten zu erstellen
Unternehmen schätzen den Datenaustausch, weil er die Datenqualität sicherstellt – etwas, das der traditionelle Datenkauf- und -verkaufsprozess oft übersieht.
Als Datenverbraucher in der Vergangenheit Datensätze kauften, fanden sie oft viele doppelte Einträge. Manchmal fehlte es den Daten an Regelmäßigkeit und Normalisierung. Andere Male enthielten die Daten fehlende Einträge, Nullwerte, ungültige Zahlen und unleserliche Bezeichnungen. Datenaustausch-Softwarelösungen beseitigen diese Probleme, indem sie Käufern ermöglichen, Daten vor dem Kauf zu überprüfen und Qualitätsprobleme zu beheben.
Der Datenaustausch löst auch Probleme bei der Datenentdeckung. Früher mussten Organisationen unzählige Websites durchsuchen, bevor sie Daten erwerben konnten. Hinzu kam das große Problem der Preisverhandlungen, Vertragsunterzeichnung, Datenbereinigung und Integration. Keine gute Gleichung für gutes Geschäft.
Datenaustauschsysteme machen den gesamten Prozess für Verbraucher und Lieferanten mühelos. Datenverbraucher können mehrkriterielle, gefilterte Suchen, Abtastwerkzeuge und Datenvisualisierung nutzen, um das zu finden, wonach sie suchen.
Wer nutzt den Datenaustausch?
Datenanbieter und -verbraucher, die Datenaustausch-Softwarelösungen nutzen:
- Organisationen, die ihre datengetriebenen Entscheidungen verbessern
- Lieferkette, Betrieb und Logistik, die nach umsetzbaren Erkenntnissen suchen
- Vermarkter, die umsetzbare Daten über ihre Zielgruppen benötigen
- Projektmanager, die eine bessere Datenzusammenarbeit zwischen Teams fördern
- Agenturen, die nach Zielgruppen und wertvollen Kampagneneinblicken suchen
- Verlage, die versuchen, Leserdemografien zu verstehen und Konversionen zu steigern
- IT-Support-Manager, die die Bedürfnisse der Softwarebenutzer identifizieren und entsprechende Schulungen erleichtern müssen
Möchten Sie mehr über Datenaustauschplattformen erfahren? Erkunden Sie Datenaustauschplattformen Produkte.
Geschichte des Datenaustauschs
Der bescheidene Anfang des Datenaustauschs, wie wir ihn heute kennen, begann in den 1960er Jahren, als IBM und General Electronics (GE) Datenbanken erfanden. Der Datentransfer zwischen Datenbanken war erst in den 1970er Jahren notwendig, als Datenbanken endlich genug Daten gesammelt hatten.
CSV
Der Bedarf an Datentransfer führte dazu, dass der IBM Fortran-Compiler 1972 das Format für kommagetrennte Werte (CSV) unterstützte. Unternehmen nutzten CSV, um Daten in Tabellen zu sammeln und in eine andere Datenbank zu importieren.
CSV ist auch heute noch die häufigste Methode zur Datenverteilung. Große Unternehmen, Regierungsstellen und akademische Institutionen verwenden CSV, um Daten im Internet zu verteilen.
XML und JSON
Bald erkannten Unternehmen, dass sie nicht die gesamte Informationstabelle austauschten. Stattdessen stellten sie den Endbenutzern nur begrenzte Datensätze zur Verfügung. Dieses Bedürfnis, den Zugriff auf eine Handvoll Datensätze zu ermöglichen, führte zur Nutzung von Anwendungsprogrammierschnittstellen (APIs), die leichte Anwendungen verbanden.
APIs erleichterten den Datenaustausch mit kleinen, hierarchischen Informationssammlungen. Der Prozess des Versendens von Daten mit APIs erforderte zwei API-Aufrufe: einen für das Basisobjekt und einen weiteren für die Tag-Liste aus einer relationalen Datenbank. Dieses Problem führte zur Erfindung der erweiterbaren Auszeichnungssprache (XML) im Jahr 1998 und der Javascript-serialisierten Objektnotation (JSON) im Jahr 2001.
Unternehmen wandten sich schnell von XML ab, da es Tags erzeugte, die größer als die Datenlast waren. JSON konnte nur Schlüssel-Wert-Paare und Arrays darstellen. Infolgedessen begannen APIs, JSON zu verwenden, um Apps zu verbinden.
Heute verwenden Unternehmen API-Management-Tools, um APIs zu überwachen und den Datenaustausch zu erleichtern.
Source Code Control System
Der Informatiker Marc Rochkind erfand ein Versionskontrollsystem namens Source Code Control System (SCCS), während er bei Bell Labs im Jahr 1972 arbeitete. Mehrere Codeautoren nutzten SCCS und stellten fest, dass sie effizient zusammenarbeiten konnten, indem sie Versionskontrollfunktionen wie Diffs, Merges und Branches nutzten.
Vor SCSS verließen sich Unternehmen auf die manuelle Kompilierung und Integration der Arbeit aller in den Code. Die Zusammenarbeit am gleichen Code wurde mit SCSS mühelos.
CVS
Organisationen nutzten proprietäre Versionskontrollsysteme, bis der Informatiker und Dozent Dick Grune Concurrent Versions Systems (CVS) im Jahr 1986 veröffentlichte. Die meisten Open-Source-Projekte nutzten CVS, um Code mit freien, offenen Formaten zu teilen.
Im Jahr 2005 verlagerte der finnische Software-Ingenieur Linus Torvalds sein Open-Source-Projekt zu Git, und Produktunternehmen folgten.
Git und Github
Mit verteilten Formaten machte Git die Zusammenarbeit am Quellcode einfach. Die Plattform speicherte alle Codeversionen lokal, und Unternehmen mussten nur die Änderungen des Remote-Servers synchronisieren. Die einfache Versionskontrolle ermöglichte es Unternehmen, riesige Mengen an Diff-, Branch- und Merge-Operationen schneller zu bearbeiten.
Im Gegensatz zu anderen Versionskontrollsystemen verwendete Git die Merkle-gerichtete azyklische Graphenstruktur (DAG), um Branches zu ermöglichen, Zeiger auf Commits zu sein. Mit praktisch unbegrenzten Branches machte Git es einfacher für Menschen, zusammenzuarbeiten und am gleichen Code zu arbeiten.
Die Einführung von Github im Jahr 2008 verbesserte die Zusammenarbeit am Quellcode weiter und führte zu vielen Open-Source-Projekten.
Funktionen des Datenaustauschs
Datenaustauschsysteme bieten die folgenden Funktionen, um Unternehmen bei der Datenbeschaffung und der Gewinnung von Erkenntnissen zu unterstützen.
Daten-Normalisierung
Daten-Normalisierung organisiert ähnliche Daten über Datensätze hinweg, um saubere Daten zu erzeugen. Der Normalisierungsprozess sorgt für eine logische Datenspeicherung, minimiert Datenänderungsfehler, vereinfacht Abfragen und eliminiert Redundanz und unstrukturierte Daten. Diese Funktion ermöglicht es Unternehmen, verschiedene Informationseinträge zu standardisieren, einschließlich Telefonnummern, Straßenadressen und Kontaktnamen.
Die Normalisierung verwendet Normalformen, um die Integrität der Datenbank zu gewährleisten und Abhängigkeiten zwischen Attributen und Relationen zu überprüfen.
Gängige Normalformen:
Unternehmen verwenden in der Regel diese drei Normalformen, um Daten zu normalisieren.
- Erste Normalform (1NF) betrachtet einen einzelnen Zell- und Datensatzwert, um wiederholte Einträge aus einer Gruppe zu eliminieren.
- Zweite Normalform (2NF) erfüllt 1NF und verlagert Datensubgruppen aus mehreren Zeilen in eine neue Tabelle.
- Dritte Normalform (3NF) stellt sicher, dass es keine Abhängigkeit zwischen nicht-primären Schlüsselattributen gibt, neben der Erfüllung von 1NF und 2NF.
Die meisten relationalen Datenbanken erfordern normalerweise nicht mehr als 3NF, um Daten zu normalisieren. Unternehmen verwenden jedoch die vierte Normalform (4NF), die fünfte Normalform (5NF) und die sechste Normalform (6NF), um komplexe Datensätze zu handhaben.
DaaS
Datenaustauschlösungen verwenden das Data-as-a-Service (DaaS)-Modell, um Daten zu speichern, zu verarbeiten und Analysedienste bereitzustellen. Unternehmen wenden sich an die Bereitstellung von Cloud-Diensten, um die Agilität zu verbessern, die Funktionalität zu verbessern, schnell einzurichten, die Wartung zu automatisieren und Kosten zu sparen.
DaaS funktioniert ähnlich wie SaaS, wurde jedoch erst kürzlich weit verbreitet angenommen. Ursprünglich behandelten Cloud-Computing-Dienste die Anwendungs-Hosting und Datenspeicherung anstelle von Datenintegration, Analytik und Verarbeitung. Heute macht kostengünstiger Cloud-Speicher es einfacher für Cloud-Plattformen, Daten in großem Maßstab zu verwalten und zu verarbeiten.
Datenmanagement
Datenmanagement, der Prozess des Sammelns, Organisierens, Transformierens, Speicherns und Schützens von Daten, beginnt mit der Datenakquise im Kontrollzentrum. Sobald Sie Daten erworben haben, setzen Sie die nachfolgenden Prozesse wie Datenvorbereitung, Konvertierung, Katalogisierung und Modellierung fort. Diese Schritte helfen den Daten, die Ziele der Datenanalyse zu erfüllen.
Effizientes Datenmanagement optimiert die Datennutzung über Teams und Organisationen hinweg. Außerdem ist es entscheidend, um Richtlinien- und Regulierungsanforderungen zu erfüllen.
Dynamischer Datenaustausch
Dynamischer Datenaustausch (DDE) überträgt Daten mit einem Nachrichtenprotokoll. DDE teilt Daten zwischen Anwendungen unter Verwendung verschiedener Datenformate. Remote-Datenaustauschplattformen, die dynamischen Datenaustausch verwenden, helfen Ihnen, Anwendungen basierend auf der Verfügbarkeit neuer Daten zu aktualisieren.
DDE verwendet Client- und Servermodelle zusammen mit gemeinsamem Speicher, um Informationen auszutauschen. In diesem Modell fordert der Client Informationen an und die Anwendung bietet Informationen an. Sie können DDE mehr als einmal verwenden, um Daten auszutauschen.
Automatisierung des Datenaustauschs
Die Automatisierung des Datenaustauschs hilft Unternehmen, Zeit zu sparen, die Datenverarbeitung zu vereinfachen und Aufgaben im Datenlebenszyklus schneller auszuführen. Datenaustausch-Softwaresysteme mit Automatisierungsfunktionen emulieren manuelle Aktionen, um Prozesse effizienter zu gestalten.
Arten des Datenaustauschs
Nachfolgend sind die vier Arten des Datenaustauschs aufgeführt, abhängig von den Datenübertragungsbeziehungen zwischen Datenverbrauchern und -lieferanten.
1. Peer-to-Peer-Datenaustausch ist der direkte Datenaustausch zwischen zwei verschiedenen Unternehmen oder zwei Abteilungen innerhalb desselben Unternehmens. Zum Beispiel kann ein großes Unternehmen mit mehreren Datenlagern den Peer-to-Peer-Datenaustausch nutzen, um Datensubsets zwischen Abteilungen zu teilen.
2. Privater Datenaustausch erfolgt, wenn zwei Unternehmen Daten über einen sicheren Kanal austauschen. Häufige Beispiele sind branchenspezifische Datenaustausch unter Benutzern. Ebenso, wenn ein Unternehmen Daten mit Lieferanten teilt, die sie mit Kunden teilen, wird dies als privater Datenaustausch bezeichnet.
Diese Art des Datenaustauschs verwendet Representational State Transfer (REST) API, Simple Object Access Protocol (SOAP) Webdienst, Nachrichtenwarteschlange, File Transfer Protocol (FTP), Electronic Data Interchange (EDI) oder Business-to-Business (B2B) Gateway-Technologie.
3. Elektronischer Datenaustausch erfolgt über die Cloud. Diese Art des Datenaustauschs schützt Daten mit Passwörtern und kann Daten zum Download bereitstellen.
4. Datenmarktplatz ist ein öffentlicher Datenaustausch, der für Unternehmen offen ist, die Daten konsumieren oder bereitstellen möchten. Zum Beispiel ist Amazon Web Services (AWS) ein globaler Datenmarktplatz, der verschiedene Branchen und Funktionen bedient. Sie werden auch auf Nischen-Datenmarktplätze stoßen, die Finanzdatenaustausch oder Gesundheitsdatenaustauschdienste für Verbraucher und Lieferanten anbieten.
Datenaustauschformate
Einige der gängigen Formate, die Unternehmen zum Austausch von Daten verwenden, sind:
- CSV
- XML
- JSON
- INTERLIS
- Apache Parquet
- GMT-Gitterdateiformat
- Generalized Markup Language (GML)
- Yet Another Markup Language (YAML)
- Resource Description Framework (RDF)
- Relative Expression Based Object Language (REBOL)
- Any Transport Over Multi-Protocol Label Switching (MPL) (ATOM)
Datenkatalog vs. Datenaustausch vs. Datenmarktplatz
Ein Datenkatalog erstellt und pflegt ein Inventar von Datenressourcen in einem Unternehmensumfeld. Geschäftsanalysten, Dateningenieure und Wissenschaftler verwenden Datenkataloge, um Geschäftswert aus relevanten Datensätzen zu extrahieren.
Um die Datenkatalogisierung zu automatisieren, verwenden maschinelle Lern-Datenkatalog-Tools natürliche Sprachabfragen und Datenmaskierungslösungen, die eine sichere und effiziente Metadatenentdeckung, -aufnahme, -anreicherung und -übersetzung ermöglichen.
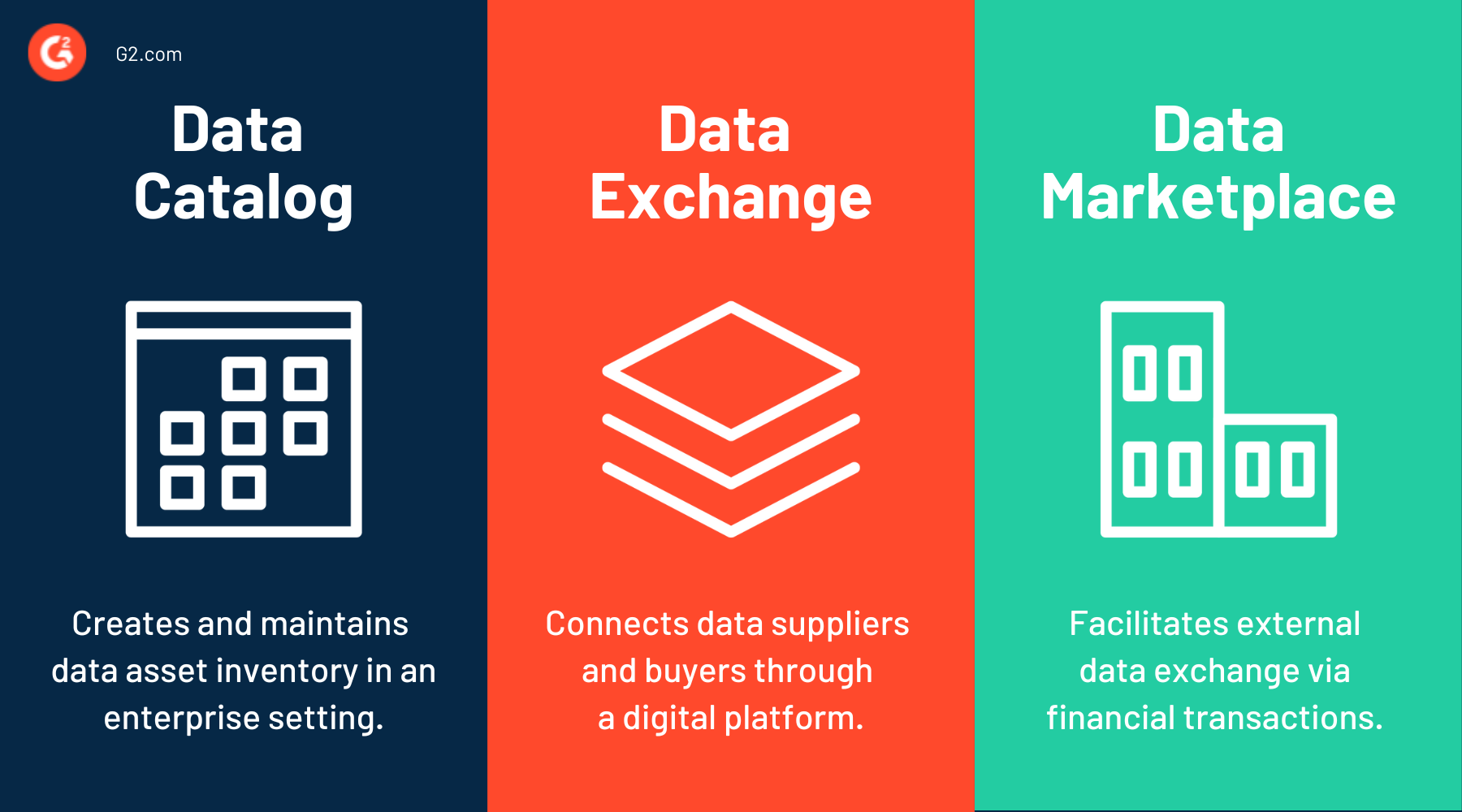
Datenaustausch-Plattformen verbinden Datenlieferanten und -käufer über eine digitale Datenschnittstelle, die es Unternehmen erleichtert, relevante Daten zu finden, zu nutzen und zu verwalten. Datenaustausch-Interaktionen können transaktional oder kollaborativ sein.
Ein Datenmarktplatz erleichtert den externen Datenaustausch über finanzielle Transaktionen. Datenmarktplätze ermöglichen es Unternehmen, Daten zu entdecken, zu veröffentlichen, zu lizenzieren und zu verteilen. Alle Datenmarktplätze sind Datenaustausche, aber Marktplätze unterstützen keine nicht-finanziellen Anwendungsfälle.
Wie funktioniert der Datenaustausch?
Datenaustausch-Softwarelösungen bringen Verkäufer und Käufer zusammen. Diese Zusammenarbeit erfolgt in den folgenden Schritten.
- Partnervereinbarungen: Sobald Käufer wissen, welche Daten sie möchten, unterzeichnen sie Vereinbarungen oder Verträge mit Verkäufern. Diese Vereinbarungen definieren Datenaustauschprotokolle, Nutzungsrichtlinien und andere Kollaborationsprinzipien.
- Node-Client-Setup: Abhängig von den Bedürfnissen der Verbraucher richten Lieferanten Nodes ein, um Daten über das Netzwerk zu teilen. Diese Node-Clients ermöglichen es Verbrauchern, Daten über einen sicheren Kanal anzufordern und zu empfangen. Einige Unternehmen verwenden Nodes nur, um die Überwachung von Datenanforderungen zu automatisieren.
- Datenstandardisierung: Lieferanten standardisieren und bereichern Daten mit vereinbarten Datenformaten.
- Informationsaustausch: Datenlieferanten teilen Daten mit Node-Clients und Käufer empfangen die Daten.
Datenaustauschmuster
Datenaustauschmuster kombinieren Datenformat, Kommunikationsprotokolle und Architekturmodelle, um den Datenaustausch zu erleichtern. Lassen Sie uns einige der häufigsten Datenaustauschmuster aufschlüsseln.
API
APIs verwenden das Hypertext Transfer Protocol (HTTP) und Webdienste, um zwischen Anwendungen zu kommunizieren. Webdienste wie die unten genannten standardisieren die Interoperabilitätsbereitstellung zwischen Anwendungen.
- Das SOAP-standardisierte Protokoll verwendet HTTP und ein einfaches Mail-Transfer-Protokoll (SMTP), um Nachrichten zu senden. Das World Wide Web Consortium (W3C) entwickelt und pflegt die SOAP-Standard-Spezifikationen.
- REST bietet einen RESTful-Webdienst mit einer Reihe von Richtlinien.
- GraphQL oder ähnliche API-Design-Architektur-Tools bieten Abfrage- und Manipulationssprache zusammen mit zugehöriger Laufzeit.
ETL
Um Daten zu lesen und zu schreiben, müssen Anwendungen, die Daten übertragen, sich mit anderen Datenbanken verbinden. Extract, Transform, and Load (ETL)-Tools verbessern Datenbankverbindungen mit Datenbündelung, Transformation und Planung.
ETL-Lösungen helfen Unternehmen, Daten aus mehreren Datenbanken in ein einziges Repository zu sammeln, um sie zu formatieren und für die Datenanalyse vorzubereiten. Dieses einheitliche Datenrepository ist der Schlüssel zur Vereinfachung der Analyse und Datenverarbeitung.
Dateiübertragung
Der Dateiübertragungsprozess verwendet eine Netzwerk- oder Internetverbindung, um Daten von einem Gerät auf ein anderes zu speichern und zu verschieben. Datenaustauschlösungen verwenden Dateiübertragungen, um logische Datenobjekte zwischen lokalen und entfernten Benutzern zu teilen, zu übertragen oder zu verschieben. JSON, XML und CSV sind gängige Dateiformate, die im Datenaustauschprozess verwendet werden.
Remote Procedure Call
Verteiltes Computing verwendet einen Remote Procedure Call (RPC), um Nachrichten zwischen Client-Server-basierten Anwendungen zu übersetzen und zu senden. RPC erleichtert Punkt-zu-Punkt-Kommunikationen während des Datenaustauschs.
Ein RPC-Protokoll fordert einen Remote-Server auf, bestimmte Prozeduren basierend auf den Parametern des Clients auszuführen. Sobald der Remote-Server antwortet, überträgt RPC die Ergebnisse an die aufrufende Umgebung.
Ereignisbasierte vermittelte Nachrichtenübermittlung
Ereignisbasierte vermittelte Nachrichtenübermittlung verwendet Middleware-Software, um Datenmeldungen zu liefern. In diesem Prozess verwalten verschiedene technische Komponenten Warteschlangen und Caching. Es verlässt sich auf eine Geschäftsregel-Engine, um Veröffentlichungs- und Abonnementdienste zu verwalten.
Datenstreaming
Datenstreaming ist der Prozess des Empfangs eines kontinuierlichen Datenflusses oder -feeds aus verschiedenen Quellen. Datenaustausch-Tools verwenden Datenstreaming, um Datenfolgen zu empfangen und Metriken für jeden ankommenden Datenpunkt zu aktualisieren. Dieses Datenaustauschmuster eignet sich für Echtzeitüberwachung und Reaktionsaktivitäten.
Berücksichtigen Sie Ihre lokalen und Unternehmensbedürfnisse, bevor Sie ein Datenaustauschmuster auswählen.
Die Verwendung universeller Datenaustauschstandards ermöglicht nahtlosen Datenzugriff und Integration auf allen Ebenen des Gesundheitswesens.
Gesundheitseinrichtungen verwenden Gesundheitsintegrations-Engines, um den Zugriff auf elektronische Gesundheitsakten (EHR) zu gewährleisten, disparate Datensilos zu reduzieren und bessere Kompatibilität und Compliance zu erreichen.
Gesundheitsdatenaustauschstandards
Das Clinical Data Interchange Standards Consortium (CDISC) setzt die folgenden Standards durch, um strukturierte Daten über Informationssysteme hinweg zu teilen.
- Clinical Trial Registry (CTR)-XML nutzt die Lösung "einmal schreiben, mehrmals verwenden", indem eine einzelne XML-Datei für mehrere klinische Studieneinreichungen verwendet wird.
- Operational Data Model (ODM)-XML ist ein herstellerneutrales Format, das den regulatorisch konformen Datenaustausch und die Archivierung mit Metadaten, Referenzdaten und Auditinformationen erleichtert. Elektronische Datenerfassungstools verwenden häufig ODM-XML für Fallberichte.
- Studien-/Versuchsdesignmodell in XML (SDM-XML) verwendet drei Submodule (Struktur, Workflow und Timing), um maschinenlesbare klinische Studiendesignbeschreibungen anzubieten.
- Define-XML beschreibt die tabellarische Metadatenstruktur mit Datensatzmetadaten.
- Dataset-XML verwendet Define-XML, um den Datensatz-Austausch zu unterstützen.
- Resource Description Framework (RDF) CDISC-Standards bieten eine verknüpfte Datenansicht der CDISC-Standards.
- Laboratory Data Model (LAB) bietet ein Standardmodell für die Erfassung und den Austausch von Labordaten.
Datenaustausch-Framework
Ein Datenaustausch-Framework erleichtert den Datentransfer zwischen Systemen. Es definiert die Logik, die benötigt wird, um Daten aus Quelldateien zu lesen, Daten in kompatible Formate zu transformieren und transformierte Daten mit dem Zielsystem zu teilen. Um diesen Prozess zu erleichtern, verbinden Entwickler in der Regel Drittanbieter- und Zielsysteme mit dem Framework.
Datenaustausch-Frameworks bieten die folgenden Funktionen, um die Interaktion zwischen Datenverbrauchern und -lieferanten zu unterstützen.
- Durchsuchbarer Katalog vereinfacht die Suche nach Datenressourcen, indem er die Beschreibung des Datensatzes verwendet, einschließlich der Anzahl der Datensätze, Dateityp, Preisgestaltung, Profilstatistiken und Bewertungen. Datenverbraucher durchsuchen diese Kataloge, um geeignete Datensätze zu finden und die Qualität der Beispieldaten zu bewerten.
- Asset-Management ermöglicht das Hochladen, Verwalten und Veröffentlichen von Datenressourcen. Datenlieferanten verwenden diese Funktion, um Datenlizenzen, Zugriffsrechte zu spezifizieren und Inventar zu verwalten.
- Zugriffskontrolle hilft Datenlieferanten, Zugriffsregeln für Datenressourcen festzulegen. Zum Beispiel kann ein Lieferant den Zugriff auf Datensätze einschränken, bis die Zahlung abgeschlossen oder eine Vereinbarung getroffen wurde. Einige Datenaustauschschichten bieten auch den Austausch von Verschlüsselungsschlüsseln für die Dateizustellung an.
- Datentransfer ist der Prozess, den Lieferanten verwenden, um Daten mit Verbrauchern zu teilen. Gängige Datentransfermethoden umfassen Dateiübertragung, Multi-Tenant-Datenaustausch und APIs. Cloud-basierter Transfer speichert Dateien und vereinfacht den Datenzugriff mit Objektspeicher. Andererseits erfordert der Multi-Tenant-Datenaustausch, dass Lieferanten und Verbraucher dieselben Datenmanagement-Plattformen (DMPs) für Transparenz verwenden.
- Abonnement-Management rationalisiert die Abonnementangebote für Datenressourcen für Datenlieferanten. Einige Datenaustausche bieten auch eine "Bring Your Own Subscription" (BYOS)-Funktion, die verschiedene Abonnements über Token verbindet.
- Transaktionsmanagement bietet Zahlungstransaktionen und Zahlungsabwicklung über Kreditkarten, Banküberweisungen und Kontenabrechnungen. Datenverbraucher verfolgen Käufe und Abonnements, bleiben über Erneuerungsbedingungen informiert und ändern Abonnements mithilfe von Transaktionsmanagementmodulen.
- Kontoverwaltung sammelt Details zu Benutzern, Käufern, Verkäufern sowie Zahlungsmechanismen, Abrechnungsinformationen und Kontenaktivitäten.
- Verwaltung und Datenaustauschbetreiber überwachen Benutzeraktivitäten und beheben Probleme.
- Zusammenarbeit bietet einen sicheren Bereich für Lieferanten und Verbraucher, um gemeinsam an Datensätzen zu arbeiten.
- Datenanreicherung verbessert die Qualität durch Datenstandardisierung, Adressverifizierung, Duplikatsbeseitigung, Dateizusammenführung, Validierung und Datenbereinigung.
- Selektives Teilen ermöglicht die Konfiguration von Datensätzen für ausgewählte Verbraucher.
- Daten-Mapping empfiehlt ergänzende Daten für eine weitere Anreicherung.
- Multi-Tenant-Datenaustausch beseitigt traditionelle Datenaustauschprobleme beim Ersetzen von FTP sowie beim Kopieren und Verschieben von Daten.
- Connector Software Development Kit (SDK) erstellt benutzerdefinierte Connectoren für Datenaustauschlieferanten, um auf andere Datenplattformen zuzugreifen.
- Abgeleitete aggregierte Daten ermöglichen es Verbrauchern, benutzerdefinierte Funktionen (UDFs) auszuführen und aggregierte Ausgaben zu erhalten. Lieferanten bieten diese Funktionalität in der Regel an, wenn sie nicht möchten, dass Verbraucher Zugriff auf sensible Rohdaten haben.
- Erweitertes Onboarding vereinfacht das Onboarding von Lieferanten mit der Bewertung der Datenkonformität von Lieferanten.
- Benachrichtigungen informieren Verbraucher, wenn eine neue Datenveröffentlichung ihren Anforderungen entspricht.
- Pipeline-Management kombiniert und integriert, bevor Drittanbieterdaten an Endbenutzer geliefert werden.
- Erweiterte Berichterstattung zeigt die Verkaufsleistung des Datenaustauschs und hilft Lieferanten, Erkenntnisse zu gewinnen, um die richtigen Käufer zu finden.
- Benutzerdefinierte Datenprodukte mischen, segmentieren und entwickeln Daten, um geeignete Datenprodukte für Verbraucher zu erstellen.
- Verbot des Wechsels des Besitzes verhindert Lizenzverletzungen mit sensibler Datenvorschau und Tests.
Die meisten Datenaustauschlösungen kombinieren die oben genannten Funktionen, um einfache und konforme Transaktionen zwischen Datenkäufern und -verkäufern zu schaffen.
Vorteile des Datenaustauschs
Ob Ihr Unternehmen Datensilos abbauen, den Datenzugriff verwalten oder Daten sicher mit Kunden teilen möchte, Datenaustausch-Software bietet Ihnen viele Vorteile.
- Vereinfacht den Datenkauf und -verkauf. Das Finden glaubwürdiger Drittanbieterdaten war für Datenverbraucher mühsam. Und bedenken Sie die Herausforderungen bei Preisverhandlungen, Datenevaluierung und Integration. Datenaustauschsysteme machen es für Datenlieferanten mühelos, Daten zu verkaufen, und für Käufer, sie zu erwerben.
- Erleichtert die Datenbeschaffung für Erkenntnisse. Datenaustausche bieten Unternehmen, die wichtige datengetriebene Entscheidungen treffen möchten, schnelleren Datenzugriff. Diese einfache Zugänglichkeit hilft Unternehmen, den Umsatz zu steigern und Prognosen mit maschinellen Lernmodellen zu verbessern.
- Rationalisiert Datenmonetarisierungsmöglichkeiten. Unternehmen, die Daten verkaufen, verließen sich traditionell auf einen Vermittler, um geeignete Käufer zu finden. Datenaustausche bedeuten, dass Verkäufer Daten zu ihren eigenen Bedingungen mit einer leicht zugänglichen Plattform verkaufen.
- Erleichtert die Datenkommerzialisierung. Der Datenaustausch hilft Datenursprüngen und -erwerbern, ein Ökosystem aufzubauen, das beiden Parteien zugutekommt. Datenaustausche helfen Datenkäufern, neu gewonnene Erkenntnisse zu nutzen, um strategische Schritte zu unternehmen, während sie Verkäufern Möglichkeiten bieten, neue Einnahmequellen zu schaffen.
- Verbessert die Datenqualität und minimiert verschwendete Ausgaben. Datenaustausche helfen Ihnen, auf zuverlässige Daten zuzugreifen und Datenbots zu eliminieren, damit Sie keine Zeit mit falschen Leads verschwenden. Außerdem bietet Datenaustausch-Software genaue Daten für die korrekte Segmentierung, was zu erfolgreicheren Geschäftsergebnissen führt.
Herausforderungen des Datenaustauschs
Der Datenaustausch löst einige Probleme und schafft einige. Nachfolgend sind einige der häufigsten Probleme aufgeführt, mit denen Unternehmen beim Datenaustausch konfrontiert sind.
- Erfordert eine robuste Datenkonformitätspolitik. Ohne sie können Sie kaum Datensynchronisationssysteme synchronisieren. Konformitätsregeln helfen Unternehmen, Datenmanagement-Frameworks zu definieren, um zu verfolgen, welche Daten sie teilen und mit wem. Diese Frameworks erleichtern die Anwendung von Datenzugriffskontrollen für Datenengineering-Teams.
- Benötigt ausreichende Anbieter und Verbraucher. Datenaustauschplattformen ohne genügend Verbraucher finden es schwierig, ihr volles Potenzial zu erreichen. Lieferanten bleiben skeptisch, ihre Unternehmen auf diesen Plattformen aufzulisten. Vielleicht ist dies der Grund, warum viele Cloud-Lösungen mit Datenaustauschfähigkeiten Systemen helfen, Käufer und Verkäufer zu gewinnen.
- Verlässt sich auf Datenintegration und -validierung. Datenverbraucher können keine Erkenntnisse gewinnen, es sei denn, sie integrieren die Daten mit internen Datenmanagement-Tools. Diese Integration erfordert, dass Datenaustausch-Software in der Lage ist, Rohdaten zu validieren, zu bereinigen und in ein lesbares Format zu formatieren.
- Benötigt technisches Fachwissen. Unternehmen können Datenaustauschlösungen nicht navigieren, ohne zu wissen, wie man Daten verpackt, filtert oder validiert.
- Begrenzt die Datenfilterfähigkeit. Datenaustausche lassen Käufer nicht genau das auswählen, was sie benötigen. Datenkäufer können keine präzisen Datensätze nach ihren Vorlieben erstellen oder erwerben.
Überlegungen zum Datenaustauschansatz
Es gibt keinen einheitlichen Datenaustauschansatz, den jedes Unternehmen verwenden kann. Jede Methode hat ihre Vor- und Nachteile, aber beachten Sie diese Punkte, während Sie den Datenaustauschansatz für Ihr Unternehmen auswählen.
- Datenkomplexität sagt Ihnen, ob Sie direkten Datenbankzugriff benötigen oder nicht. Zum Beispiel, wenn Sie keinen Zugriff auf bestimmte Datenentitätskomponenten haben, sind Sie mit direktem Zugriff besser dran. Andererseits erfordern REST-APIs mehrere Aufrufe und Codierung, um Beziehungen zwischen Datenelementen aufzubauen. Sie können auch JSON und XML für komplexere Datenmodelle verwenden.
- Häufigkeit der Datenaktualisierung zeigt, ob Sie Datensätze regelmäßig ersetzen müssen. APIs und Nachrichtensystemmethoden sorgen für eine bessere Resynchronisation im Falle großer Datenaktualisierungen.
- Datensatzgröße bestimmt, ob Sie eine direkte Datenbankverbindung oder Dateiübertragung für die Leistungsoptimierung benötigen. Sie können auch nach Möglichkeiten suchen, die Leistung beim Senden von Daten über REST oder andere APIs zu verbessern.
- Datenversionen oder -schemata helfen Ihnen auch bei der Auswahl zwischen API oder anderen Datenaustauschprotokollen. Zum Beispiel sind APIs nicht ideal, um verschiedene Datenformate darzustellen. Wenn Ihre Anwendungen Daten in verschiedenen Versionen benötigen, sind Sie mit einem anderen Datenaustauschprotokoll besser dran.
- Daten-Sicherheitskontrollen leiten Sie zum besten Datenaustauschansatz. Zum Beispiel müssen Sie möglicherweise APIs so gestalten, dass sie Schlüssel erfordern, Webserver konfigurieren oder Datenbankmanagementsystem (DBMS)-Sicherheitskontrollen einrichten, um Daten zu schützen.
- Schwierigkeit der Datentransformation sagt Ihnen, was Sie benötigen, um Daten zu verschieben. Sie benötigen eine direkte Datenbankverbindung und ETL-Tools für eine umfangreiche Transformation mit komplexen Regeln. Bewerten Sie auch die Komplexität der Transformation, um zu sehen, ob API-Management-Plattformen von Nutzen sein können.
- Verbindungstyp ist eine weitere Entscheidung, die Sie treffen müssen, bevor Sie einen Ansatz wählen. Kurzlebige Protokolle eignen sich für eine bestimmte Aktion oder eine Reihe von Aktionen, während langlebige Protokolle Verbindungen auf unbestimmte Zeit offen halten. Berücksichtigen Sie die Anforderungen der Endbenutzer, während Sie die Verbindungspersistenz wählen.
Erfolgreiche Organisationen betrachten auch breitere organisatorische Ziele, bevor sie Entscheidungen über Anforderungen für spezifische Projekte und Anwendungen treffen. Sie arbeiten zusammen und koordinieren Ansätze, um Datenkonflikte und Inkonsistenzen zwischen Teams zu vermeiden.
Was müssen Sie vor einem Datenaustausch beachten?
- Daten-Governance-Strategie
- Benutzereinwilligung für die Datenfreigabe
- Benutzerrollen- und Zugriffsmanagement
- Datenlizenzen und rechtliche Vereinbarungen
- Technische Anforderungen an den Datenaustausch
- Vereinbarte Softwareplattformbedingungen für den Datenaustausch
Best Practices für das Design von Datenaustausch
Ein gut implementierter Datenaustausch erfordert eine korrekte Datenkonfiguration und -synchronisation. Verlassen Sie sich auf die folgenden Best Practices, um Datenaustauschprozesse genau zu gestalten und Daten über den Implementierungszyklus hinweg zu validieren.
- Überprüfen Sie das XML-Schema-Register, bevor Sie ein neues Schema erstellen.
- Befolgen Sie die Designregeln für das Austauschnetzwerk und die Schema-Design-Standards.
- Teilen Sie logische Datengruppen in separate Schema-Dateien auf.
- Verwenden Sie Schemakonstraints effektiv, um die Kompatibilität mit Ihrer Zieldatenbank sicherzustellen.
- Minimieren Sie erforderliche Felder und verwenden Sie sie nur, wenn nötig.
- Verwenden Sie Zähl-, Listen- oder detaillierte Ergebnismengen für eine einfache Datensynchronisation.
- Vermeiden Sie große Datentransaktionen außerhalb der Geschäftszeiten.
- Nutzen Sie asynchrone Methoden für große Datensätze.
- Vorverarbeiten Sie Anfragen, um die Auswirkung von Nodes zu bewerten.
- Vereinfachen Sie die Konvertierung relationaler Daten in XML mit Datenvorbereitung.
- Wählen Sie ein flexibles Schema-Design, um die Rückgabeoptionen für Daten zu optimieren.
- Begrenzen Sie die Auswahlmöglichkeiten für Abfrageparameter, um große Datensätze zu vermeiden.
- Komprimieren Sie Dateien, um die Datenübertragungsgröße zu begrenzen.
- Verwenden Sie Datenunterschiede, um Änderungen seit der letzten Datenübertragung zu identifizieren.
- Wählen Sie eine einfache und flexible Namenskonvention für den Datenservice.
- Dokumentieren Sie die Parameter des Datenservices vor dem Datenaustausch.
Datenaustausch-Software
Datenaustausch-Software wird verwendet, um Daten zu teilen und zu übertragen, ohne ihre Bedeutung zu verändern.
Eine Datenaustauschlösung muss Folgendes tun, um die Anforderungen für die Aufnahme in die Kategorie Datenaustausch zu erfüllen:
- Daten teilen, ohne ihre Bedeutung zu verändern
- Daten normalisieren, um den Verbrauch zu erleichtern
- Marktdaten-as-a-Service-Akquisitionsdienst anbieten
- Mit anderen Datenlösungen integrieren, um den Austausch und die Analyse zu erleichtern
*Nachfolgend sind die fünf führenden Datenaustauschplattformen basierend auf G2-Daten vom 18. Juli 2022 aufgeführt. Einige Bewertungen können zur Klarheit bearbeitet worden sein.
1. PartnerLinQ
PartnerLinQ ist eine Plattform zur Sichtbarkeit der Lieferkette, die die Datensichtbarkeit und -konnektivität optimiert. Diese Plattform bietet elektronische Datenübertragung (EDI), nicht-EDI und API-Integrationsfähigkeiten, um mehrere Liefernetzwerke, Marktplätze, Echtzeitanalysen und Kernsysteme zu verbinden.
Was Benutzer mögen:
„Diese Plattform bleibt eine der besten Daten-Mapping-Plattformen. Die Einrichtung ist so ideal, dass sie ein großartiges Management von Lieferkettenproblemen ermöglicht. Das Schnittstellendesign ist so marginal, dass es die Leistung verbessert. Der den Benutzern angebotene Support ist einfach auf den Punkt.“
– PartnerLinQ Review, Chris J.
Was Benutzer nicht mögen:
„Der Preis ist teuer, denke ich. Und eine leichte Entwicklung der Analytik wäre nützlicher.“
– PartnerLinQ Review, Rashad G.
2. Crunchbase
Crunchbase ist ein führender Anbieter von Prospecting- und Forschungslösungen. Unternehmen, Vertriebsteams und Investoren nutzen diese Plattform, um neue Geschäftsmöglichkeiten zu finden.
Was Benutzer mögen:
„Das hilfreichste an Crunchbase sind die leistungsstarken Filter, mit denen Sie superzielgerichtete Listen von Unternehmen erstellen können, die Sie für zukünftige Zusammenarbeit kontaktieren möchten.“
– Crunchbase Review, Aaron H.
Was Benutzer nicht mögen:
„Das einzige Problem, das ich hatte, war, dass Sie, wenn Sie die Abfragefunktion der Website anstelle der API verwenden, relativ unbereinigte Daten erhalten, die Sie vor der ordnungsgemäßen Verarbeitung bereinigen müssen! Dieses Problem kann umgangen werden, wenn Sie die API verwenden, aber Sie benötigen grundlegende Kenntnisse in JSON.“
– Crunchbase Review, Kasra B.
3. Flatfile
Flatfile ist eine Daten-Onboarding-Plattform, die es Unternehmen ermöglicht, saubere, gebrauchsfertige Daten schneller zu importieren. Diese Plattform automatisiert Spaltenabgleichsempfehlungen und ermöglicht es Ihnen, Ziel-Datenmodelle für die Datenvalidierung festzulegen.
Was Benutzer mögen:
„Flatfile ist ein leistungsstarkes Import-Tool, das einfach funktioniert. Es hat alle Funktionen, die Sie von einem Importeur erwarten würden, plus solche, die Sie zunächst nicht in Betracht ziehen würden. Für Entwickler ist ihre API gut dokumentiert und ihr Support war immer verfügbar, um Ansätze zu besprechen. Wir haben Flatfile zu einem kritischen Bestandteil unseres Onboarding-Prozesses gemacht und es hat sich großartig bewährt!“
– Flatfile Review, Ryan F.
Was Benutzer nicht mögen:
„Das einzige kleine Problem ist, dass die clientseitige Version nicht ganz so funktionsreich ist wie die Version, die Daten an das Flatfile-Backend sendet, was bedeutet, dass der Spaltenabgleich nicht ganz so intelligent ist. Aber das ist wirklich geringfügig - ich würde Flatfile dringend empfehlen.“
– Flatfile Review, Rob C.
4. AWS Data Exchange
AWS Data Exchange vereinfacht, wie Unternehmen die Cloud nutzen, um Drittanbieterdaten zu finden.
Was Benutzer mögen:
„Es ist beeindruckend, Hunderte von kommerziellen Datenprodukten von führenden Datenanbietern in Kategorien wie Einzelhandel, Finanzdienstleistungen, Gesundheitswesen und mehr zu finden.“
– AWS Data Exchange Review, Ahmed I.
Was Benutzer nicht mögen:
„Die Abonnementpreise sind teuer und es wird sehr schwierig, das Budget zu verwalten.“
– AWS Data Exchange Review, Mohammad S.
5. Explorium
Explorium ist eine Datenwissenschaftsplattform, die Tausende von externen Datenquellen mit automatischer Datenentdeckung und Feature-Engineering verbindet. Unternehmen nutzen diese Plattform, um Daten zu erwerben und prädiktive Erkenntnisse zu gewinnen, die Geschäftsentscheidungen vorantreiben.
Was Benutzer mögen:
„Der Reichtum und die Breite der Daten sind unglaublich. Ich mag den sofortigen Zugriff auf die nützlichsten und zuverlässigsten externen Daten wirklich. Es hilft uns, einen besseren Kundenservice zu bieten, weil es die Daten sind, die wir benötigen, um schnellere und bessere Entscheidungen zu treffen. Die Plattform ist sehr einfach zu bedienen und äußerst vielseitig.“
– Explorium Review, Ishi N.
Was Benutzer nicht mögen:
„Ich wünschte, sie hätten mehr punktuelle Datenquellen.“
– Explorium Review, Noa L.
Harmonisieren Sie die Master-Daten-Governance über Geschäftsfelder hinweg
Wenn Sie bereit sind, unternehmensweite Tools, Prozesse und Anwendungen mit einer einzigen Quelle der Wahrheit (SSOT) zu synchronisieren, lassen Sie sich von Datenaustauschplattformen von Datensilos befreien. Entkompartimentieren Sie Ihre Erkenntnisse und treffen Sie bessere datengetriebene Entscheidungen.
Nutzen Sie Master Data Management (MDM), um eine vertrauenswürdige Sicht auf Daten zu schaffen und die betriebliche Effizienz zu erreichen.

Sudipto Paul
Sudipto Paul is an SEO content manager at G2. He’s been in SaaS content marketing for over five years, focusing on growing organic traffic through smart, data-driven SEO strategies. He holds an MBA from Liverpool John Moores University. You can find him on LinkedIn and say hi!

