



Datenwissenschaft bringt die Welt zusammen und konzentriert zufällig verteilte Informationen in kleine Einheiten.
Bei all dem Hype um Big Data, strukturierte vs. unstrukturierte Daten und wie Unternehmen sie nutzen, könnten Sie sich fragen: „Von welchen Datentypen sprechen wir?“
Das Erste, was man verstehen muss, ist, dass nicht alle Daten gleich geschaffen sind. Das bedeutet, dass die Daten, die von Social-Media-Apps generiert werden, völlig anders sind als die Daten, die von Point-of-Sales- oder Lieferkettensystemen generiert werden.
Einige Daten sind strukturiert, aber die meisten sind unstrukturiert. Im Backend ist eine Datenbankmanagement-Software (DBMS) ein Abfragemanagementsystem, das den Benutzerzugriff auf diese Daten authentifiziert und die Fähigkeit, sie durch Benutzerabfragen zu speichern, zu verwalten und abzurufen.
Um dies zu verdeutlichen, lassen Sie uns die einzigartigen Unterschiede zwischen strukturierten und unstrukturierten Daten aufschlüsseln.
Was ist der Unterschied zwischen strukturierten und unstrukturierten Daten?
Strukturierte Daten sind hochorganisiert und formatiert, sodass sie in relationalen Datenbanken leicht durchsuchbar sind. Unstrukturierte Daten haben kein vordefiniertes Format oder Organisation, was es viel schwieriger macht, sie zu sammeln, zu verarbeiten und zu analysieren. Strukturierte Daten sind begrenzter und in Datenarrays sortiert, während unstrukturierte Daten verstreut und variabel sind.
Zusätzlich dazu, dass sie auf unterschiedliche Weise bezogen, gesammelt und skaliert werden, werden strukturierte und unstrukturierte Daten in völlig getrennten Datenbanken gespeichert.
Was sind strukturierte Daten?
Strukturierte Daten werden meist als quantitative Daten kategorisiert und sind die Art von Daten, mit denen die meisten von uns gewohnt sind zu arbeiten. Denken Sie an Daten, die ordentlich in festen Feldern und Spalten in relationalen Datenbanken und Tabellenkalkulationen passen.
Beispiele für strukturierte Daten sind Namen, Daten, Adressen, Kreditkartennummern, Aktieninformationen, Geolokationen und mehr.
Strukturierte Daten sind hochorganisiert und leicht von Maschinen zu verstehen. Diejenigen, die in relationalen Datenbanken arbeiten, können strukturierte Daten schnell eingeben, durchsuchen und manipulieren, indem sie ein relationales Datenbankmanagementsystem (RDBMS) verwenden. Dies ist das attraktivste Merkmal von strukturierten Daten.
Die Programmiersprache zur Verwaltung strukturierter Daten wird als strukturierte Abfragesprache bezeichnet, auch bekannt als SQL. IBM entwickelte diese Sprache in den frühen 1970er Jahren, und sie ist besonders nützlich für die Handhabung von Beziehungen in Datenbanken.
Beispiele für strukturierte Daten
Wenn dies verwirrend klingt, hier ist ein Beispiel für einen DDL (Data Definition Language)-Befehl, der ausgeführt wird, um strukturierte Daten zu tabellieren. Die Daten werden in einer SQL-Tabelle gespeichert, wobei jede Zeile und Spalte zu einem bestimmten Datentyp beiträgt.
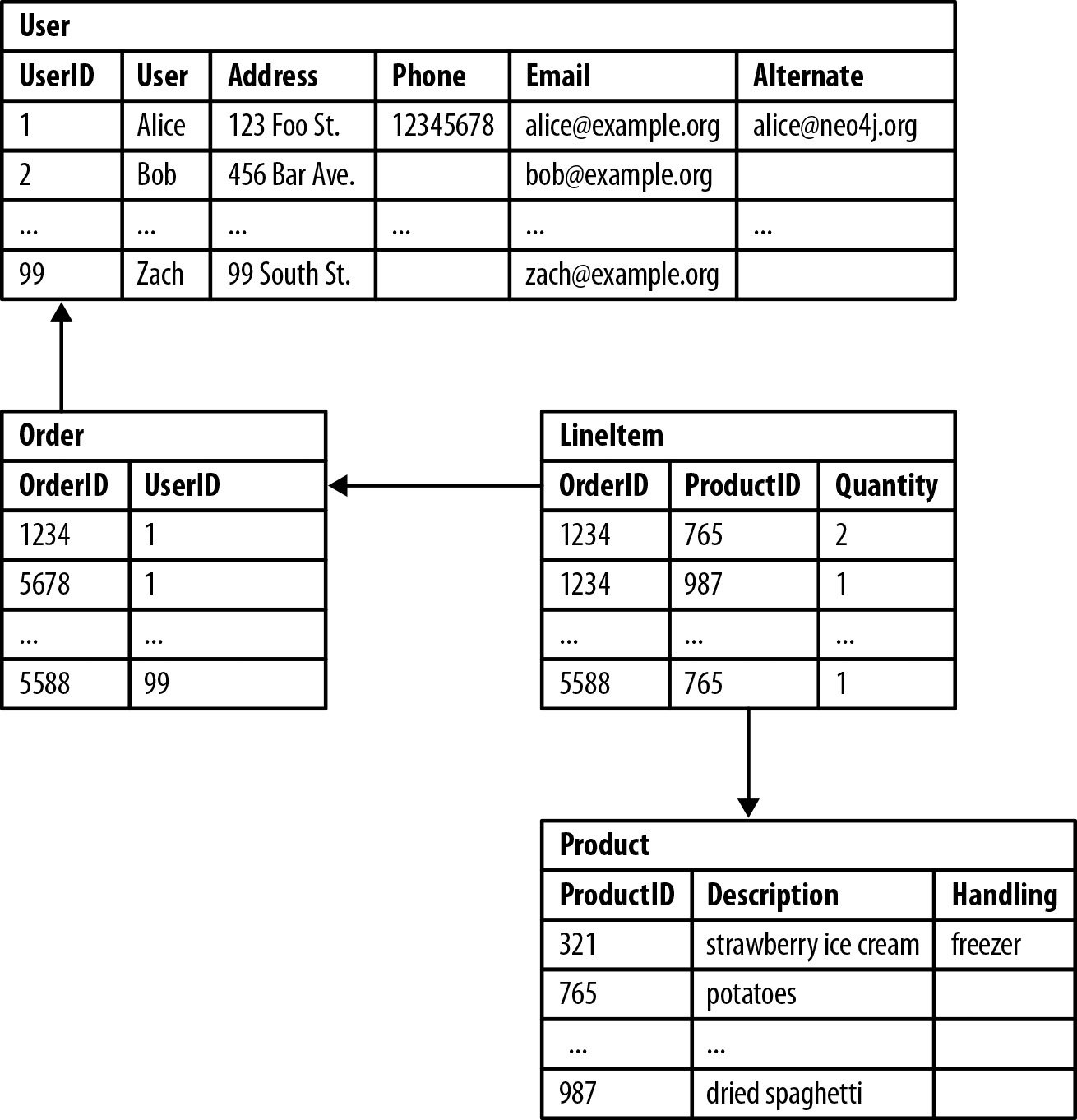
Von oben nach unten können wir sehen, dass UserID 1 sich auf die Kundin Alice bezieht, die zwei Bestell-IDs von '1234' und '5678' hatte. Als nächstes hatte Alice zwei Produkt-IDs von '765' und '987'. Schließlich können wir sehen, dass Alice zwei Packungen Kartoffeln und eine Packung getrocknete Spaghetti gekauft hat.
Strukturierte Daten werden auch in Flugreservierungssystemen, elektronischen Mitfahrgelegenheiten, Lebensmittel- und Liefer-Apps sowie Suchmaschinenoptimierung (SEO-Daten) verwendet. In jedem dieser Fälle werden Daten in relationalen Datenbanken gespeichert und können in großen Formen gespeichert, abgerufen oder verwaltet werden.
Strukturierte Daten revolutionierten papierbasierte Systeme, auf die Unternehmen vor Jahrzehnten für Business Intelligence angewiesen waren. Während strukturierte Daten immer noch nützlich sind, suchen mehr Unternehmen nach Möglichkeiten, unstrukturierte Daten für zukünftige Chancen zu dekonstruieren.

Quelle: Fivetran
Beispiele für strukturierte Daten
Strukturierte Daten werden in mehreren verbraucherorientierten Geschäftsdatenbanken oder ERPs verwendet, wie zum Beispiel:
- E-Commerce: Bewertungsdaten, Preisdaten und SKU-Nummer von Waren
- Gesundheitswesen: Krankenhausverwaltung, Apotheken- und Patientendaten sowie medizinische Geschichte der Patienten.
- Bankwesen: Finanztransaktionsdetails wie Name des Begünstigten, Kontodetails, Absender- oder Empfängerinformationen und Bankdetails.
- Customer Relationship Management (CRM) Software: Lead-Akquisitionsdaten, Quelle, Aktivität und so weiter von Leads in der CRM-Datenbank.
- Reisebranche: Passagierdaten, Fluginformationen und Reisebuchungen.
Strukturierte vs. unstrukturierte Daten
Unstrukturierte Daten sind das genaue Gegenteil von strukturierten Daten. Hier ist eine Übersicht über bemerkenswerte Unterschiede zwischen den beiden.

Strukturierte Daten sind vorformatiert, saubere Daten, die ordentlich in Speicherblöcke angeordnet sind. Ihr Format ist in Zeilen und Spalten vordefiniert und wird in relationalen Datenbanksystemen (RDBMS) oder Microsoft Excel gespeichert. Die Daten sind als "Schema on Write" bekannt, was Daten für ein großes Datenbankschema oder einen Entwurf darstellt. Sie sind hoch skalierbar und sicher und erfordern weniger Verwaltung.
Unstrukturierte Daten sind hochkomplex, qualitativ und unorganisiert. Sie werden auch als Big Data bezeichnet, die keinem bestimmten Standard entsprechen. Diese Daten können numerisch, alphabetisch, boolesch oder eine Mischung aus allem sein. Sie werden mit einer NoSQL-Datenbank gespeichert. Sie können nicht in einer relationalen Datenbank oder einem RDBMS gespeichert werden, da Datenstrings gemischte Datentypen haben, die nicht in eine Zeile oder Spalte passen. Häufige Arten von unstrukturierten Daten sind Clickstream-Daten, Social-Media-Daten, Text und Multimedia.
Verwandt: Entdecken Sie SQL vs. NoSQL, um zu sehen, welche Datenbank für Sie geeignet ist.
Vorteile von strukturierten Daten
Es ist einfach, strukturierte Daten zu speichern, abzurufen und zu verwalten, da sie einen organisierten Backend-Mechanismus haben. Die Verwendung von strukturierten Daten im Geschäft kann zu folgenden Vorteilen führen.
- Strukturierte Daten können problemlos in Machine-Learning-Modelle als Eingabedatensätze eingespeist werden, ohne dass ein Trimmen erforderlich ist.
- Die Arbeit mit strukturierten Daten erfordert keine KI- oder ML-Expertise. Jeder mit guten Produktinformationen und grundlegenden Datenwissenschaftskenntnissen kann dies tun.
- Strukturierte Daten werden gleichmäßig in Data Warehouses oder Tabellenkalkulationen gespeichert. Ihre spezifische und organisierte Natur macht es einfach, sie zu manipulieren und abzufragen.
- Strukturierte Daten sind älter als unstrukturierte Daten, daher stehen mehr Analysetools zur Verfügung, um sie zu messen und zu analysieren.
- Die Daten sind von höherer Qualität, Konsistenz und Benutzerfreundlichkeit als unstrukturierte Daten.
- Es gibt Rückfallmechanismen, um sich anzupassen, wenn der Benutzer auf einen Fehler beim Verwalten strukturierter Daten stößt.
- Es wird auch als quantitative Daten bezeichnet, da Unternehmen ihre Metriken verwenden, um Geschäftstrends und strategische Auswirkungen vorherzusagen.
- Es wird in einem stabilen, zentralisierten Repository gepflegt, das den Fluss von Geschäftsprozessen und Entscheidungsfindung verbessert, um den ROI zu optimieren.
Herausforderungen von strukturierten Daten
Die meisten Probleme mit strukturierten Daten heben ihre Unflexibilität und Starrheit bei der Skalierung größerer Datenbankschemata hervor. Strukturierte Daten sind "Schema on Write" oder "stark schemaabhängig" für Operationen. Häufige Herausforderungen von strukturierten Daten sind wie folgt aufgeführt:
- Da strukturierte Daten schemaabhängig sind, ist es etwas schwierig, sie für große Datenbanken zu skalieren.
- Die Zeit, die zum Laden strukturierter Daten benötigt wird, wird manchmal unterschätzt. Das Erkennen versteckter Probleme im Quellsystem und das Aktualisieren, Abrufen und Wiederherstellen kann Ihren Cloud-Speicher belasten.
- Kommt nicht gut mit dem sich ändernden Geschäftsszenario zurecht. Es ist schwer zu bestimmen, welche Abfrage zu einem bestimmten Geschäftsergebnis führen würde. Die Art der Abfragen und Transaktionen ändert sich, wenn ein Unternehmen seinen Verbraucherfokus verschiebt.
- Strukturierte Daten werden manuell in das Datenbankmanagement-System eingegeben. Der Benutzer muss einen DDL (Data Definition Language)-Befehl wie Create, Insert und Select eingeben, um Daten aus dem System zu sortieren, zu verwalten und abzurufen.
Werkzeuge für strukturierte Daten
Abgesehen von der Verwendung einer strukturierten Abfragesprache (SQL) oder Microsoft Excel zur Verwaltung strukturierter Datenmanipulationen gibt es noch einige weitere Werkzeugerweiterungen, die Sie verwenden können.
- PL SQL: Procedural Query Language oder PL SQL ist eine bestehende Version von SQL, die sich mit Arbeitstransaktionen befasst. Die häufigsten Transaktionsabfragen sind "commit" oder "rollback".
- Postgre SQL: Postgre SQL ist ein Open-Source-Relationales Datenbankmanagementsystem, das große Datenmengen verarbeitet. Es unterstützt auch SQL- und JSON-Abfragen sowie Hochsprachen.
-
SQLite: Es ist eine hochrangige, eigenständige und serverlose Datenbank, die Softwareentwickler verwenden, um strukturierte Daten für Geschäftsanwendungsintegrationen zu extrahieren,
- My SQL ist eine standardisierte integrierte Datenumgebung, die Benutzerautorisierung verwendet, um Datensätze durch Abfragen in einer massenverteilten Datenbank einzugeben.
- OLAP: Es umfasst eine breitere Kategorie des Datenbankmanagements, einschließlich Data Mining, Berichtserstellung und Business Intelligence.

Was sind unstrukturierte Daten?
Unstrukturierte Daten werden oft als qualitativ kategorisiert und können nicht mit herkömmlichen Datenwerkzeugen und -methoden verarbeitet und analysiert werden. Sie sind auch als "schemaunabhängige" oder "Schema on Read"-Daten bekannt.
Beispiele für unstrukturierte Daten sind Text, Videodateien, Audiodateien, mobile Aktivitäten, Social-Media-Posts, Satellitenbilder, Überwachungsbilder – die Liste geht weiter und weiter.
Unstrukturierte Daten sind schwer zu dekonstruieren, da sie kein vordefiniertes Datenmodell haben, was bedeutet, dass sie nicht in relationalen Datenbanken organisiert werden können. Stattdessen sind nicht-relationale oder NoSQL-Datenbanken am besten geeignet, um unstrukturierte Daten zu verwalten.
Eine andere Möglichkeit, unstrukturierte Daten zu verwalten, besteht darin, sie in einen Data Lake oder Pool fließen zu lassen, sodass sie in ihrem rohen, unstrukturierten Format bleiben.
Die Einsicht, die in unstrukturierten Daten verborgen ist, zu finden, ist keine leichte Aufgabe. Es erfordert fortgeschrittene Analysen und hohe technische Expertise, um einen Unterschied zu machen. Datenanalyse kann für viele Unternehmen eine teure Umstellung sein.
95%
der Unternehmen geben an, dass die Verwaltung unstrukturierter Daten ein Problem für ihr Geschäft darstellt.
Quelle: Techjury
Beispiele für unstrukturierte Daten
Diejenigen, die in der Lage sind, unstrukturierte Daten zu nutzen, haben jedoch einen Wettbewerbsvorteil. Während strukturierte Daten uns einen Überblick über Kunden geben, können unstrukturierte oder Big Data uns detaillierte Informationen über die täglichen Handlungen der Verbraucher geben.
Zum Beispiel können Data-Mining-Techniken, die auf unstrukturierte Daten von einer Einzelhandelswebsite angewendet werden, Unternehmen helfen, das Kaufverhalten und die Kaufzeitpunkte der Kunden, Kaufmuster, die Einstellung zu einem bestimmten Produkt und vieles mehr zu erfahren.
Unstrukturierte Daten sind auch entscheidend für Predictive Analytics Software. Zum Beispiel können Sensordaten, die an Industriemaschinen angebracht sind, Hersteller im Voraus auf ungewöhnliche Aktivitäten aufmerksam machen. Mit diesen Informationen kann eine Reparatur durchgeführt werden, bevor die Maschine einen kostspieligen Ausfall erleidet.
Weitere Beispiele für unstrukturierte Daten:
Unstrukturierte Daten sind jedes Ereignis oder jede Benachrichtigung, die von einem Benutzer innerhalb einer Organisation gesendet und empfangen wird, ohne ordnungsgemäße Dateiformatierung oder direkte geschäftliche Abhängigkeit.
- Rich Media: Social Media, Unterhaltung, Überwachung, Satelliteninformationen, Geodaten, Wettervorhersagen, Podcasts
- Dokumente: Rechnungen, Aufzeichnungen, Webverlauf, E-Mails, Produktivitätsanwendungen
- Medien- und Unterhaltungsdaten, Überwachungsdaten, Geodaten, Audio, Wetterdaten
- Internet der Dinge: Sensordaten, Ticker-Daten
- Analytik: Maschinelles Lernen, Künstliche Intelligenz (KI)
Vorteile von unstrukturierten Daten
Unstrukturierte Daten, heutzutage auch als Big Data bekannt, sind frei fließend und spezifisch für jedes Unternehmen. Sie sind schemaunabhängig und werden als "Schema on Read" bezeichnet. Die Anpassung dieser Daten an Ihre Geschäftsstrategien kann Ihnen einen Wettbewerbsvorteil gegenüber Konkurrenten verschaffen, die noch in traditionellen Entscheidungsprozessen feststecken. Und hier ist der Grund.
- Unstrukturierte Daten sind leicht verfügbar und bieten genügend Einblicke, die Unternehmen sammeln können, um mehr über die Reaktion auf ihre Produkte zu erfahren.
- Unstrukturierte Daten sind schemaunabhängig. Daher wirken sich geringfügige Änderungen an der Datenbank nicht auf Kosten, Zeit oder Ressourcen aus.
- Unstrukturierte Daten können auf gemeinsamen oder hybriden Cloud-Servern mit minimalen Ausgaben für das Datenbankmanagement gespeichert werden.
- Unstrukturierte Daten liegen in ihrem nativen Format vor, sodass Datenwissenschaftler oder Ingenieure sie nicht definieren, bis sie benötigt werden. Dies eröffnet die Erweiterbarkeit von Dateiformaten, da sie in verschiedenen Formaten wie .mp3, .opus, .pdf, .png usw. verfügbar sind.
- Datenseen bieten "Pay-as-you-use"-Preise, die Unternehmen helfen, ihre Kosten und ihren Ressourcenverbrauch zu senken.
Herausforderungen von unstrukturierten Daten
Unstrukturierte Daten sind die derzeit am meisten angesagte Methode zur Datensammlung und -manipulation. Viele Unternehmen wechseln zu "kundenorientierteren" Geschäftsmodellen und setzen auf Verbraucherdaten. Die Arbeit mit unstrukturierten Daten führt jedoch zu folgenden Herausforderungen.
- Unstrukturierte Daten sind nicht leicht zu verstehen. Benutzer benötigen einen fundierten Hintergrund in Datenwissenschaft und maschinellem Lernen, um sie vorzubereiten, zu analysieren und mit maschinellen Lernalgorithmen zu integrieren.
- Unstrukturierte Daten ruhen auf weniger authentischen und verschlüsselten gemeinsamen Servern, die anfälliger für Ransomware und Cyberangriffe sind.
- Derzeit gibt es nicht viele Werkzeuge, die unstrukturierte Daten manipulieren können, abgesehen von Cloud-Commodity-Servern und Open-Source-NoSQL-DBMS.
Werkzeuge für unstrukturierte Daten
Abgesehen von der Verwendung eines NoSQL zur Verwaltung unstrukturierter Datenmanipulationen gibt es noch einige weitere Werkzeuge, die Sie verwenden können.
- Hadoop: Ein verteiltes Rechenframework zur Verarbeitung großer Mengen unstrukturierter Daten.
- Apache Spark: Ein schnelles und allgemeines Cluster-Computing-Framework zur Verarbeitung strukturierter und unstrukturierter Daten.
- Werkzeuge zur Verarbeitung natürlicher Sprache (NLP): Zum Extrahieren von Informationen aus unstrukturierten Textdaten.
- Maschinelle Lernbibliotheken: Zum Erstellen von Modellen zur Analyse und Vorhersage von Mustern in unstrukturierten Daten.
Weitere Datentypen
Abgesehen von den oben genannten Datentypen spielen semi-strukturierte Daten und Metadaten eine entscheidende Rolle bei der Bewältigung der zunehmenden Komplexität und Vielfalt moderner Datenquellen.
Was sind semi-strukturierte Daten?
Semi-strukturierte Daten sind eine Art von strukturierten Daten, die zwischen strukturierten und unstrukturierten Daten liegen. Sie haben kein spezifisches relationales oder tabellarisches Datenmodell, enthalten jedoch Tags und semantische Marker, die Daten in Datensätze und Felder in einem Datensatz skalieren.
Häufige Beispiele für semi-strukturierte Daten sind JSON und XML. Semi-strukturierte Daten sind komplexer als strukturierte Daten, aber weniger komplex als unstrukturierte Daten. Sie sind auch relativ einfacher zu speichern als unstrukturierte Daten und überbrücken die Lücke zwischen den beiden Datentypen.
Eine XML-Sitemap enthält Seiteninformationen für eine Website. Sie bettet URLs, Domain-Scores, Do-Follow-Seiten und Metatags ein.
Was sind Metadaten?
Metadaten werden häufig in Big Data Analytics verwendet und sind ein Master-Datensatz, der andere Datentypen beschreibt. Sie haben vordefinierte Felder, die zusätzliche Informationen über einen bestimmten Datensatz enthalten.
Metadaten haben eine definierte Struktur, die durch ein Metadaten-Markup-Schema identifiziert wird, das Metadatenmodelle und -standards umfasst. Sie enthalten wertvolle Details, die Benutzern helfen, Daten besser zu analysieren und fundierte Entscheidungen zu treffen.
Zum Beispiel kann ein Online-Artikel Metadaten wie eine Überschrift, einen Snippet, ein hervorgehobenes Bild, einen Bild-Alt-Text, einen Slug und andere verwandte Informationen anzeigen. Diese Informationen helfen, ein Stück Inhalt von mehreren anderen ähnlichen Inhalten im Web zu unterscheiden. Daher sind Metadaten ein nützliches Datenset, das als Gehirn für alle Datentypen fungiert.
Datenbankmanagement-Werkzeuge
Datenbankmanagement-Werkzeuge bieten die Infrastruktur, um Daten effektiv zu speichern, zu verwalten, und zu analysieren, um ein effizientes Datenmanagement und wertvolle Einblicke zu gewährleisten. Die Nutzung des richtigen Datenbankmanagement-Werkzeugs ermöglicht es Unternehmen:
- Betriebskosten zu senken
- Aktuelle Metriken zu verfolgen und neue zu erstellen
- Seine Kunden auf einer viel tieferen Ebene zu verstehen
- Intelligentere und gezieltere Marketingkampagnen zu enthüllen
- Neue Produktmöglichkeiten und Angebote zu finden
Top 5 Datenmanagement-Werkzeuge:
*Oben sind die fünf führenden Datenmanagement-Softwarelösungen aus dem G2 Summer 2024 Grid®-Bericht aufgeführt.
Wie Daten, so Entscheidungen
Das Volumen von Big Data steigt weiter an, aber die Bedeutung der Big-Data-Speicherung wird bald nicht mehr existieren.
Egal, ob Daten strukturiert oder unstrukturiert sind, die genauesten und relevantesten Datenquellen zu haben, wird für Unternehmen, die einen Vorteil gegenüber ihren Wettbewerbern erlangen möchten, entscheidend sein.
Je mehr Datenvarianten von Datenwissenschaftlern erstellt werden, desto mehr neue und fortschrittliche Algorithmen werden erstellt, die die Einhaltung der DSGVO erleichtern.
Daten dringen in jede große Branche der Welt ein. Marken bewegen sich weg von nicht wesentlichen Marketingtricks hin zu datengesteuertem Verbrauchermarketing. Die Informationen, die uns Daten liefern, werden in Verbindung mit künstlicher Intelligenz und Netzwerktechnologie gelernt und analysiert, um robuste, hypervernetzte Lösungen zu schaffen.
Am Ende des Tages liegt es am Verbraucher zu bestimmen, wie wohl er sich mit den Wegen fühlt, wie seine Daten verwendet werden.
Neu in der Big-Data-Analyse, aber möchten Sie mehr erfahren? Erfahren Sie, wie Sie mit der richtigen Big-Data-Analytics-Software Echtzeiteinblicke aus Ihren Daten gewinnen können.
Dieser Artikel wurde ursprünglich 2021 veröffentlicht. Er wurde mit neuen Informationen aktualisiert.

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)

