



Denken Sie daran, einen Film oder eine TV-Serie auf einer Streaming-Plattform anzusehen.
Bei der Nutzung von Streaming-Plattformen streamen globale Nutzer oder speichern lokal große Multi-Gigabyte (GB) Mediendateien gleichzeitig.
Objekt-Streaming ist das, was im Hintergrund passiert, wenn dies geschieht. Jede TV-Serie oder jeder Film wird entweder als gesplittetes Objekt oder als montierte Reihe von Objekten gespeichert. Und die Art und Weise, wie sie gespeichert werden, ist ein klassisches Beispiel für Objektspeicherung.
Was ist Objektspeicherung?
Objektspeicherung oder objektbasierte Speicherung ist eine Datenarchitektur, die Daten als Objekte oder eigenständige Einheiten speichert. Diese Objekte enthalten die Daten, relevante Metadaten und global eindeutige Bezeichner (GUID) – alle sofort zugänglich über RESTFUL-Schnittstellen, APIs oder HTTP/HTTPS. Die flache Struktur eines Objektspeichersystems ermöglicht es, Daten in einem einzigen Speicherhaus zu speichern, anstatt Dateien in Ordnern oder Blöcke in Servern.
Objektspeicher-Software eignet sich am besten für Organisationen, die eine große Menge an Daten sammeln, speichern und analysieren möchten. Objektspeicherlösungen sind entscheidend für die Ermöglichung bandbreitenintensiver Analysen. Sie können Unternehmen helfen, ein fragmentiertes Speicherportfolio zu beheben, Daten schneller abzurufen und Ressourcen zu optimieren.
Objektspeicherung war nicht immer die bevorzugte Option für den Umgang mit großen Datenmengen. In den frühen Tagen war sie eher geeignet für die Verwaltung von Data Lakes, Backups und Datenarchiven. Dann kam die Ära des explosiven Datenwachstums. Eine traditionelle relationale Datenbank war nicht in der Lage, die beispiellose Menge an generierten Daten zu bewältigen.
Dies zwang Unternehmen, Block- oder dateibasierte Speicher neu zu überdenken, datensicher zu sein und über die Speicherkapazität hinauszugehen. Entwickelt in den späten 1990er Jahren von Forschern der Carnegie Mellon University und der University of California–Berkeley, kann Objektspeicher-Software heute Terabytes (TBs) oder Petabytes (PBs) an Daten in einem einzigen Namensraum mit der Dreifaltigkeit von Skalierbarkeit, Geschwindigkeit und Kosteneffizienz speichern und verwalten. Was sie weiter dazu zwang, die IT-Infrastruktur vor Ort zu überdenken, ist der Aufstieg von cloud-nativen Anwendungen.
Objektspeicherung vs. Blockspeicherung vs. Dateispeicherung
Die Menge an Daten, mit denen Sie arbeiten, wächst jeden Tag weiter, was das Datenmanagement noch überwältigender macht. Mit drei Arten von Speicherarchitekturen: Objektspeicherung, Blockspeicherung und Dateispeicherung zur Auswahl, ist es entscheidend, ein solides Verständnis der Vor- und Nachteile jeder zu haben, da die gewählte Speichertechnologie die Geschäftsentscheidungen erheblich beeinflusst.
.png)
Objektspeicherung
Unternehmen, die unstrukturierte Daten archivieren und sichern möchten, die von Internet of Things (IoT)-Geräten erzeugt werden, finden objektbasierte Speicherung oft als die beste Lösung. Diese unstrukturierten Daten umfassen Webinhalte, Medien und Sensordaten.
Ein Objektspeichersystem verlässt sich auf eine strukturell flache Datenumgebung anstelle komplexer Hierarchien wie Ordner oder Verzeichnisse, um Daten als Objekte zu speichern. Denken Sie an diese Objekte als eigenständige Repositories oder Buckets. Jedes von ihnen speichert Daten mit eindeutigen Bezeichnern (UID) und anpassbaren Metadaten. Organisationen können diese Buckets über Rechenzentren und Speichergeräte spiegeln und Löschcodes ausführen.
Merkmale der Objektspeicherung:
- Flexible Datenzugriffsprotokolle
- Verteilte Scale-out-Architektur
- Metadaten-gesteuertes Informationsmanagement
- Multi-Tenancy innerhalb derselben Infrastruktur
- Globaler Namensraum für größere Datentransparenz
- Automatisiertes Systemmanagement zur Reduzierung der Komplexität
- Erweiterter Datenschutz durch Löschcodierung und Datenreplikation
Aufgrund ihrer Skalierbarkeit und Zuverlässigkeit wird die Objektspeicherung häufig für cloudbasierte Speicheranwendungen verwendet. Außerdem macht das flache Adressierungsschema das Auffinden und Zugreifen auf einzelne Objekte einfach.
S3, das ursprünglich Amazon S3 war, ist das am häufigsten verwendete Zugriffsprotokoll, das Objektspeicher verwenden. Es verwendet verbindungslose Befehle wie LIST, GET, PUT und DELETE, um auf Objekte zuzugreifen. Heute können Anwendungen das S3-Protokoll nativ verwenden, um auf Dateien zuzugreifen, was bedeutet, dass ein Dateisystem nicht mehr benötigt wird.
Blockspeicherung
Blockspeicherung, oder Block-Level-Speicherung, ist die älteste und einfachste Form der Datenspeicherung. Sie speichert Daten in festen Größenblöcken. Jeder dieser Blöcke hat eine Adresse und speichert separate Dateneinheiten auf Storage Area Networks (SANs).
Anstelle anpassbarer Metadaten verwendet ein Blockspeichersystem Adressen, um Dateien zu identifizieren, und eine Internet Small Computer System Interface (iSCSI), um sie von den erforderlichen Blöcken zu transportieren. Diese granulare Kontrolle führt zu einer schnelleren Leistung, wenn sowohl Anwendung als auch Speicher lokal sind. Es wird auch mehr Latenz geben, wenn sie weiter auseinander liegen.
Blockspeicherplattformen ermöglichen die Erstellung mehrerer Datenpfade und eine einfache Wiederherstellung, indem sie Daten von Benutzerumgebungen entkoppeln und über mehrere Umgebungen verteilen. Dies macht Blockspeicherung zur bevorzugten Wahl für Anwendungsentwickler, die nach schnellen, zuverlässigen und effizienten Datenübertragungslösungen für Hochleistungsrechnersituationen suchen.
Zum Beispiel kann eine unternehmensweite Bereitstellung virtueller Maschinen Blockspeicherung nutzen, um das virtuelle Maschinen-Dateisystem (VMFS) zu speichern. Die Verwendung eines blockbasierten Speichervolumens zur Speicherung des VMFS erleichtert es den Benutzern, Dateien mit dem nativen Betriebssystem (OS) zu teilen.
Dateispeicherung
Dateispeicherung, auch bekannt als Dateiebene-Speicherung oder dateibasierte Speicherung, ist eine hierarchische Methode zur Speicherung oder Organisation von Daten auf einem Network Attached Storage (NAS)-Gerät. Sie funktioniert ähnlich wie ein traditionelles Netzwerkdateisystem, was bedeutet, dass sie einfach zu konfigurieren ist, aber nur einen einzigen Pfad zu den Daten bietet.
Zum Beispiel nutzen Network Attached Storage (NAS)-Geräte Dateispeichersysteme, um Daten über lokale Netzwerke (LAN) oder Weitverkehrsnetze (WAN) zu teilen. Da Dateispeicherung gängige Dateiebene-Protokolle verwendet, schränken unterschiedliche Systeme normalerweise die Nutzbarkeit ein.
Angetrieben von einem globalen Dateisystem verwendet die Dateispeicherung Verzeichnisse und Unterverzeichnisse, um Daten zu speichern. Das Dateisystem ist verantwortlich für die Verwaltung verschiedener Dateiattribute wie Verzeichnisstandort, Zugriffsdatum, Dateityp, Dateigröße, Erstellungs- und Änderungsdetails.
Der perfekte Anwendungsfall für Dateispeicherung ist die Verwaltung strukturierter Daten.
Ein wachsendes Datenvolumen wird für sie herausfordernd zu handhaben sein, aufgrund steigender Ressourcenanforderungen und struktureller Probleme. Einige dieser Probleme können mit hochkapazitiven Geräten mit reichlich Speicherplatz oder cloudbasierter Dateispeicherung gelöst werden.
| Objektspeicherung | Blockspeicherung | Dateispeicherung | |
| Architektur | Daten als Objekte | Daten in Blöcken | Daten in Dateien |
| Struktur | Flach | Hoch strukturiert | Hierarchisch strukturiert |
| Transport | TCP/IP | FC/iSCSI | TCP/IP |
| Schnittstelle | HTTP, REST | Direkt angeschlossen/SAN | NFS, SMB |
| Geographie | Kann über Regionen hinweg gespeichert werden | Kann über Regionen hinweg gespeichert werden | Lokal verfügbar |
| Skalierbarkeit | Unendlich | Begrenzt | Nur für cloudbasierte Dateispeicherung möglich |
| Analytik | Anpassbare Metadaten für einfache Dateiwiederherstellung | Keine Metadaten | Verschiedene Dateiattribute für einfache Erkennung |
| Wann zu verwenden | Hoher Stream-Durchsatz | Datenbank- und Transaktionsdaten | Netzwerk-angehängte Datenspeicherung |
| Bester Anwendungsfall | Hohe Datenvolumen (statisch oder unstrukturiert) | Datenintensive Workflows mit niedriger Latenz | Datensicherung, Datenarchivierung, lokales Dateisharing und zentrale Bibliothek |
Die verteilte und Scale-out-Architektur der Objektspeicherung ist möglich durch parallelen Datenzugriff und verteilte Metadaten. Bevor Sie tief in die Architektur eintauchen, ist es wichtig, die verschiedenen Komponenten der Objektspeicherung zu kennen.
Möchten Sie mehr über Objektspeicherlösungen erfahren? Erkunden Sie Objektspeicherlösungen Produkte.
Was sind die Komponenten der Objektspeicherung?
Der Grund, warum Objektspeicherung so ansprechend ist, liegt in ihrer flachen Systemhierarchie, die Zugänglichkeit, Durchsuchbarkeit, Sicherheit und Skalierbarkeit fördert. Diese flache Umgebung besteht aus mehreren Komponenten, die es Ihnen erleichtern, große Datenmengen über verteilte Netzwerke zu speichern. Diese Komponenten sind:
Objekt
Ein Objekt ist die grundlegende Einheit eines objektbasierten Speichersystems. Es enthält Daten mit Attributen wie relevanten Metadaten und eindeutigen Bezeichnern.
Es gibt drei Arten von Objekten:
- Root-Objekt: Identifiziert Speichergerät und seine Attribute
- Gruppenobjekt: Bietet Verzeichnis zum logischen Teilmengen von Objekten auf einem Objektspeichergerät
- Benutzerobjekt: Verschiebt Anwendungsdaten zu Speicherzwecken und speichert Attribute im Zusammenhang mit Benutzer und Speicher
Objektbasiertes Speichergerät (OSD)
Ein objektbasiertes Speichergerät ist verantwortlich für die Verwaltung des lokalen Objektspeichers, das Bedienen und Speichern von Daten aus dem Netzwerk. Es ist die Grundlage der Objektspeicherarchitektur und besteht aus einer Festplatte, einem Arbeitsspeicher (RAM), einem Prozessor und einer Netzwerkschnittstelle.
Vier Hauptfunktionen eines objektbasierten Speichergeräts sind:
- Datenspeicherung: Speichert und ruft Daten zuverlässig über Objekt-IDs ab
- Intelligentes Layout: Optimiert Datenlayout und Vorabruf mit Prozessor
- Metadatenverwaltung: Verwalten von Metadaten für gespeicherte Objekte
- Sicherheit: Überprüft eingehende Übertragungen auf Sicherheit
Objektbasierte Speichergeräte funktionieren ähnlich wie Storage Area Networks (SAN) in traditionellen Speichersystemen, können jedoch direkt parallel adressiert werden, ohne dass ein Redundant Array of Independent Disks (RAID) eingreifen muss.
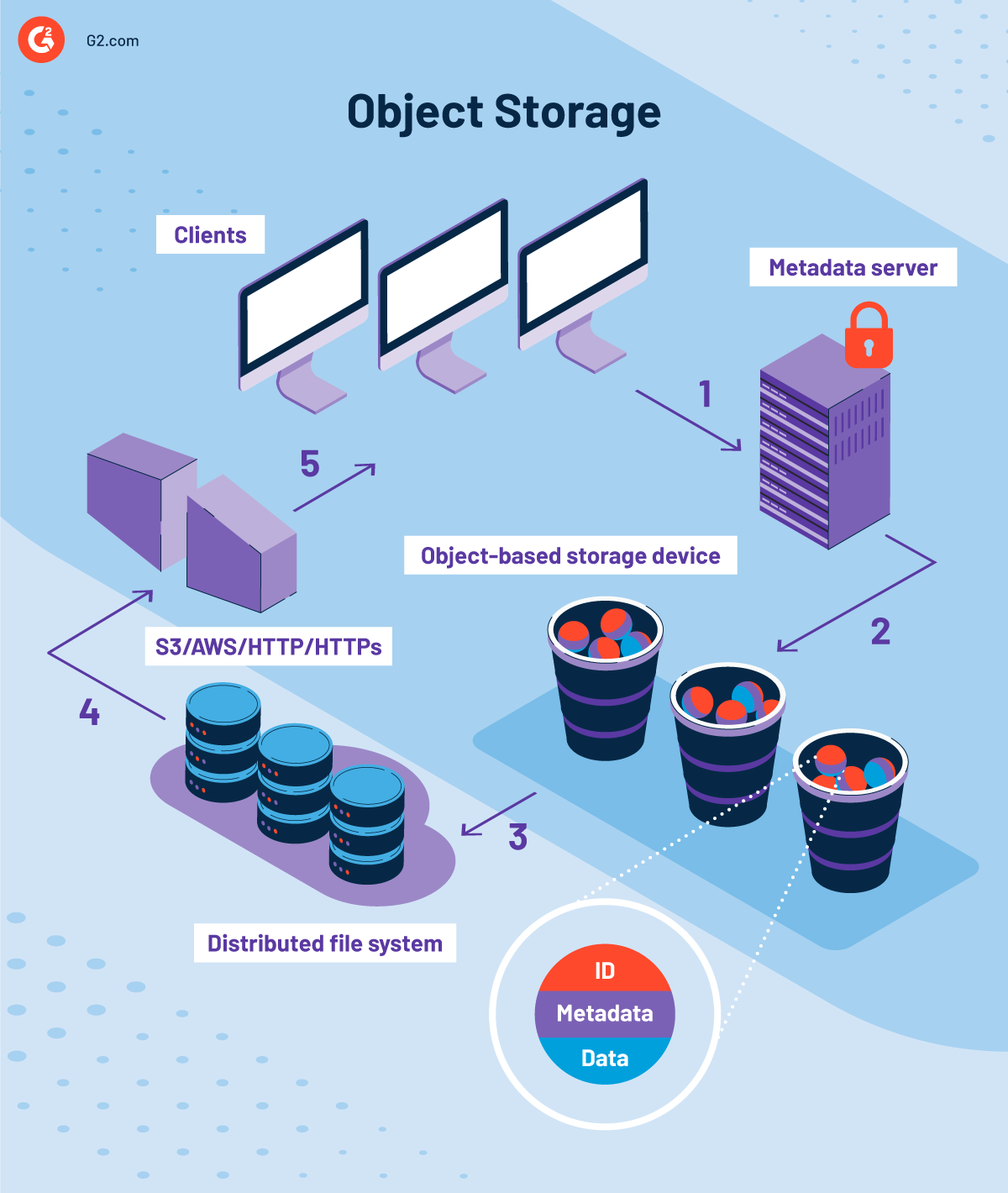
Verteiltes Dateisystem
Ein verteiltes Dateisystem nutzt ein installierbares Dateisystem, um es Computerknoten zu ermöglichen, Objekte auf das Objektspeichergerät zu lesen und zu schreiben. Seine Hauptfunktionen sind:
- Portable Operating System Interface (POSIX): Ermöglicht standardisierte Systemoperationen wie Öffnen, Lesen, Schreiben und Schließen für das zugrunde liegende Speichersystem
- Caching: Bietet Caching für die eingehenden Daten im Rechenknoten
- Striping: Verwalten des Stripings von Objekten über mehrere Objektspeichergeräte
- Mounting: Verwendet Zugriffskontrolle, um Dateisysteme am Root zu mounten
- Internet Small Computer System Interface (iSCSI) Treiber: Implementiert iSCSI-Treiber, um Objekterweiterungen und Datenlast zu erleichtern
Metadaten-Server
Ein Metadaten-Server (MDS) fungiert als zentrales Repository und erleichtert die Speicherung, Verwaltung und Bereitstellung von Metadaten mithilfe des Common Warehouse Metamodel (CWM) und der offenen Metadatenarchitektur.
Er koordiniert mit autorisierten Knoten, um eine ordnungsgemäße Interaktion zwischen Knoten und Objekten sicherzustellen. Er hält auch die Konsistenz des Caches für dieselben Dateien aufrecht. Die Entfernung von Metadaten-Servern führt zu hohem Durchsatz und linearer Skalierbarkeit in Storage Area Network (SAN)-Umgebungen.
Die Hauptfunktionen des Metadaten-Servers sind:
- Authentifizierung: Identifiziert und authentifiziert objektbasierte Speichergeräte, die dem Speichersystem beitreten möchten
- Zugriffsmanagement: Verwaltet Datei- und Verzeichniszugriff für Anforderungsoperationen von Knoten
- Cache-Kohärenz: Aktualisiert lokale Caches, bevor mehrere Knoten dieselbe Datei verwenden dürfen
- Kapazitätsmanagement: Stellt die optimale Nutzung der verfügbaren Festplattenressourcen sicher
- Skalierung: Verwaltet die Verwaltung von Metadaten auf Datei- und Verzeichnisebene für die Skalierbarkeit
Netzwerkgewebe
Netzwerkgewebe ist verantwortlich für die Verbindung des gesamten Netzwerks, d.h. objektbasierte Speichergeräte, Rechenknoten und Metadaten-Server in einem einzigen Gewebe. Weitere wichtige Komponenten des Netzwerks sind:
- Internet Small Computer System Interface (iSCSI) Protokoll: Ein grundlegendes Transportprotokoll für Daten und Befehle zu den Objektspeichergeräten (OSDs)
- Remote Procedure Call (RPC) Befehlssupport: Erleichtert die Kommunikation zwischen Metadaten-Servern und Rechenknoten
Wie funktioniert Objektspeicherung?
Objektspeichervolumen fungieren als eigenständige Repositories und speichern Daten in modularen Einheiten. Sowohl der Bezeichner als auch detaillierte Metadaten spielen eine Schlüsselrolle in der überlegenen Leistung der Lastverteilung. Sobald Sie ein Objekt erstellen, kann es je nach bestehenden Richtlinien leicht auf zusätzliche Knoten kopiert werden. Knoten mit hoher Verfügbarkeit und Redundanz können geografisch verteilt oder im selben Rechenzentrum gespeichert werden.
Öffentliche Cloud-Computing-Umgebungen ermöglichen den Zugriff auf Objektspeicherung über HTTP oder REST API. Die meisten öffentlichen Cloud-Speicher-Dienstanbieter bieten normalerweise APIs an, die sie selbst entwickeln. Einige der gängigen Befehle, die an HTTP gesendet werden, sind PUT (zum Erstellen von Objekten), GET (zum Lesen von Objekten), DELETE (zum Löschen von Objekten) und LIST (zum Auflisten von Objekten).
Wie bewegt ein Objektspeichersystem Daten?
READ-Operationen:
- Ein Client verbindet sich mit dem Metadaten-Server
- Die Identität des Knotens wird vom Metadaten-Server validiert
- Der Metadaten-Server gibt eine Liste von Objekten auf Objektspeichergeräten zurück
- Der Metadaten-Server validiert die Identität des Knotens
- Ein Sicherheitstoken wird an den Knoten gesendet, um auf bestimmte Objekte zuzugreifen
- Der Knoten verpackt die Daten
- Das Objektspeichergerät überträgt die Daten an den Client
WRITE-Operationen:
- Ein Client fordert den Metadaten-Server auf, ein Objekt zu schreiben
- Der Metadaten-Server autorisiert den Knoten mit einem Sicherheitstoken
- Der Knoten verpackt die WRITE-Anforderung und sendet sie gleichzeitig an zwei OSDs
- Der Knoten wird die Anforderung verarbeiten und den Client informieren
Was sind die Vorteile der Objektspeicherung?
Die Erreichung der Spitzenleistung auf Commodity-Server-Hardware wird mit einem Objektspeichersystem viel einfacher. Wenn Ihr Unternehmen einen exponentiell wachsenden Data Lake, d.h. einen Pool unstrukturierter Daten, hat, ist Objektspeicherung ein Muss, um Daten zu organisieren, zu verwalten und darauf zuzugreifen. Hier ist der Grund:
- Einfachheit der Durchsuchbarkeit: Objekte in einem Objektspeichersystem werden normalerweise mit eindeutigen IDs, anpassbaren Metadaten und HTTP-URLs gespeichert. All dies macht es Benutzern super einfach, Objekte zu finden und READ/WRITE-Operationen durchzuführen. Diese einfache Zugänglichkeit und Durchsuchbarkeit macht Objektspeichersysteme zur bevorzugten Wahl für Organisationen, die mit unstrukturierten Daten umgehen.
- Unbegrenzte Skalierbarkeit: Vielleicht der größte Vorteil von Objektspeichersystemen ist, dass sie leicht skalieren können, wenn Daten wachsen. Die flache strukturelle Architektur ermöglicht die horizontale Hinzufügung von Knoten und erleichtert die Verwaltung großer Datenmengen.
- Agilität: Traditionelle Dateisysteme und Datenbanken sind normalerweise nicht agil und erfordern eine rigorose professionelle Wartung. Objektspeichersysteme können sich selbst basierend auf Metadatenanweisungen verwalten und Entwicklern ermöglichen, Apps zu ändern, ohne auf das Infrastrukturteam angewiesen zu sein. Diese Agilität ist es, die den Informationszyklus für Organisationen, die Objektspeicherlösungen übernehmen, effizient macht.
- Kosteneffektive Wiederherstellung: Ein Objektspeichersystem kann Objekte auf mehr als einen Knoten kopieren, während es ein Objekt erstellt. Im unwahrscheinlichen Fall von Katastrophen wird die Datenwiederherstellungszeit für Organisationen einfacher, da diese Knoten weltweit verteilt sind. Dies eliminiert die Notwendigkeit, große Datenmengen in physischer Hardware zu speichern, und macht Objektspeicherung kosteneffektiv.
- Erhöhte Sicherheit: Cloudbasierte Objektspeicherlösungen ermöglichen es Unternehmen, Daten sicher mit Verschlüsselung während der Übertragung und im Ruhezustand zu speichern. Viele Cloud-Speicheranbieter bieten auch andere Sicherheitsfunktionen wie Ransomware-Schutz, sichere Multi-Tenancy, Lightweight Directory Access Protocol (LDAP)-Authentifizierung, Datenschutz bei Datenverlusten usw. an.
Wann sollte man Objektspeicherung verwenden:
- Katastrophenwiederherstellung
- Mobile- und internetbasierte Apps
- Kritische Datensicherung und -wiederherstellung
- On-Premise-Speichererweiterung mit Hybrid-Cloud-Speicherung
- Write-once-read-many (WORM) Speicher für Compliance-Archive
- Um unstrukturierte Datenquellen wie Multimedia-Dateien zu speichern
Das gesagt, Objektspeichersysteme sind nicht geeignet für transaktionale und Datenbankdatenverwaltung. Außerdem erlauben sie nicht die Änderung eines einzelnen Datenstücks. Um einen Teil eines Blocks zu bearbeiten, muss man das gesamte Objekt vollständig lesen und schreiben.
Wie können Objektspeichersysteme Daten vor Ransomware schützen?
Mit komplexen Systemen kommen komplexe Schwachstellen. Deshalb ist es super wichtig, eine solide Wiederherstellungsstrategie zu haben. Eine der besten Möglichkeiten, mit Ransomware umzugehen, besteht darin, die Infektion zu umgehen, indem man Daten durch ein sicheres Backup wiederherstellt. Und Objektspeicherung bietet die perfekte Lösung dafür. Warum?:
- Keine unbefugten Datenänderungen: Objektspeicherung hat eine unveränderliche Datenarchitektur, was bedeutet, dass sie nicht geändert werden kann, sobald sie geschrieben wurde. Das liegt daran, dass die Daten mit der Write Once Read Many (WORM)-Technologie geschrieben werden. Außerdem haben Administratoren die Freiheit, Unveränderlichkeit auf Bucket-Ebene zu aktivieren. Da die Daten nicht modifiziert werden können, können sie nicht von Ransomware verschlüsselt werden. Einige Cloud-Speicheranbieter bieten auch eine Objekt-Sperrfunktion an, die Hand in Hand mit WORM arbeitet, um Daten auf Geräteebene zu schützen.
- Mehrere Kopien von Daten: Immer mehr Cyberkriminelle nutzen Ransomware-Varianten, um Daten-Backups anstelle der Daten selbst anzugreifen. Die Datenversionierungsfunktion eines Objektspeichersystems ermöglicht es Ihnen, eine neue Kopie von Daten zu erstellen, während Sie sie ändern. Das bedeutet, dass es immer eine Kopie der Originaldaten geben wird, selbst wenn eine Datei von Ransomware verschlüsselt wird.
Best Practices für Objektspeicherung
Das Beste aus der Objektspeicherung herauszuholen, ist nicht einfach. Unabhängig von der Art der unstrukturierten Daten, mit denen Ihre Organisation zu tun hat, ist es wichtig, die Best Practices für das Datenmanagement zu befolgen.
- Entdecken Sie datenintensive Workloads: Der erste Schritt bei der Implementierung von Objektspeicherung besteht darin, datenintensive Workloads und Anwendungen zu identifizieren. Suchen Sie nach Anwendungen, die Streaming-Durchsatz erfordern, nicht hohe Transaktionsraten. Während Objektspeicherung ideal für größere Datensätze ist, überlegen Sie, ob es für Ihre Anwendung und Speicheranforderungen sinnvoll ist.
- Analysieren Sie den Proof-of-Concept: Die Durchführung eines Proof-of-Concept ist entscheidend, um die richtige Objektspeicherplattform zu identifizieren. Dies hilft Ihnen, die Fähigkeiten des Anbieters zu bewerten und zu sehen, ob sie Ihren Anforderungen entsprechen. Erwägen Sie die Verwendung von virtuellen Maschinen für nicht störende Tests, um den Projekterfolg sicherzustellen.
- Bereiten Sie sich auf Geräteausfälle vor: Mehrere Cloud-Speicheranbieter bieten 1 Petabyte (PB) in einem einzigen Gerät an. Diese Geräte schützen Sie vor Datenverlust und bieten kostengünstige Preise, aber sie benötigen normalerweise eine längere Wiederherstellungszeit nach einem Geräteausfall. Deshalb ist es am besten, große Server in unabhängige Knoten zu unterteilen. Sie können auch erasure-coding-fähige Cluster-Konfigurationen in Betracht ziehen, die Geräte widerstandsfähig gegen Ausfälle machen.
- Erfüllen Sie die Bedürfnisse der Benutzer: Mit Objektspeichersystemen können Sie Benutzer und Anwendungen in einer gemeinsamen Umgebung auf einem einzigen System konsolidieren. Benutzer benötigen unterschiedliche Service-Level zusammen mit Speicherkapazität und Sicherheit. Die Nutzung von Quality of Service (QoS) und Multi-Tenancy hilft Ihnen, diese Bedürfnisse zu erfüllen.
- Nutzen Sie die Kraft von reichhaltigen Metadaten: Metadaten erleichtern den Prozess der Datenanalyse und das Extrahieren von Erkenntnissen aus einer Objektspeicherdatenbank. Deshalb ist es entscheidend, eingebaute Metadaten-Tags zu nutzen, um Speicherpools und Datensätze durchsuchbar zu machen.
- Automatisieren Sie den Workflow mit Integrationen: Objektlösungen verlassen sich normalerweise auf die S3-API, um zu regulieren, wie Anwendungen Daten steuern. Jetzt kommt die S3-API mit über 400 Verben, die nahtlos verschiedene Funktionen im Zusammenhang mit Berichterstattung, Management und Integrationen handhaben können. Organisationen sollten diese Funktion der Objektspeicherung nutzen und mit DevOps zusammenarbeiten, um Workflows zu automatisieren.
Cloud-Objektspeicher-Software-Anwendungsfälle
Was Objektspeicheroptionen zur ersten Wahl für Unternehmensspeicher macht, ist ihre Fähigkeit, größere Mengen unstrukturierter Daten in einem flachen Pool zu speichern. Hier sind die Branchen, die weiterhin Objektspeicherung über Cloud-Dienste nutzen:
- Medien und Unterhaltung: Aufgrund ihrer Skalierbarkeit nutzen Medienindustrien Objektspeicherung, um große Mengen an Mediendateien und Multimedia-Assets zu speichern und zu verwalten. Die Präsenz von Metadaten erleichtert es Organisationen, diese Dateien im Moment der Dringlichkeit zu identifizieren und darauf zuzugreifen.
- Big Data: Da sie aus vielfältigen und großen Datensätzen bestehen, passen Big Data kaum in Datenbanken. Deshalb bevorzugen Organisationen, die Big Data-Analysen nutzen, die Verwendung von Objektspeicherung. Die skalierbare Natur der Objektspeicherung ermöglicht es ihnen, Petabytes an neuronalen Netzwerk- und Machine Learning-Daten zur Modellschulung zu speichern.
- Gesundheitswesen: Gesundheitsorganisationen müssen große Mengen an Daten speichern, sie sicher aufbewahren und die Datenschutzbestimmungen wie die Datenschutz-Grundverordnung (DSGVO) und den California Consumer Privacy Act (CCPA) einhalten. Sie müssen auch Daten speichern, die möglicherweise nicht häufig abgerufen werden, und Ärzten eine einheitliche Ansicht der Patientendaten bieten. Günstige cloudbasierte Objektspeicherung erfüllt all diese Anforderungen problemlos.
- Intensive Datenspeicherung: Organisationen, die mit Dateidiensten oder Kundendatenbanken zu tun haben, profitieren ebenfalls von Objektspeicherung. Die Natur ihres Geschäfts erfordert es, die Datenspeicherung auf eine leicht zugängliche Weise zu optimieren. Objektspeicherung ist die ideale Lösung, die all diese Anforderungen erfüllt.
- Speicherung als Dienstleistung: Objektspeicherung ist auch die bevorzugte Speicherlösung für Unternehmen, die AWS S3 oder S3-kompatible Speicher suchen. Die meisten dieser Unternehmen möchten entweder keine lokalen Speichersysteme bereitstellen oder suchen nach erweiterten Funktionen wie Multi-Tenancy, Quality-of-Service-Kontrollen usw. Und das macht den Fall für die S3-Protokoll- oder API-Annahme aus.
- Backup und Wiederherstellung: Einige Organisationen nutzen Objektspeicherung auch für Daten-Backup- und Wiederherstellungszwecke. Sie tun dies, um Datenverlust zu vermeiden, indem sie es über Knoten in verschiedenen Rechenzentren sichern. Solche Organisationen sollten nach der WORM-Funktionalität suchen, wenn sie einen Cloud-Datenspeicheranbieter auswählen.
- Kaltlagerung: Je nach Art ihres Geschäfts müssen Organisationen möglicherweise auch inaktive Daten speichern, die nicht häufig abgerufen werden. Diese Sammlung von Daten ist als Kaltlagerung bekannt. Objektspeicherlösungen sind kosteneffektiv, wenn es darum geht, diese Art von Daten zu speichern.
- Artefaktspeicherung: Artefakte sind Sammlungen von Protokollen und Versionsdateien, die während des Lebenszyklus einer Anwendung generiert werden. Organisationen bevorzugen es oft, diese Artefakte für weitere Tests zu speichern. Die einzigartige URL-Verteilungsmethode der Objektspeicherung erleichtert es Entwicklern, diese Art von Datei zu speichern und darauf zuzugreifen.
Objektspeicher-Software
Die Wahl der richtigen Objektspeicher-Software ist entscheidend für die Speicherung skalierbarer unstrukturierter Daten. Wenn Sie nach robusten Funktionen suchen, die Flexibilität, Leistung und größere Fähigkeiten bieten, lassen Sie objektbasierte Speicher-Software die schwere Arbeit erledigen.
Um in diese Kategorie aufgenommen zu werden, muss das Softwareprodukt:
- Unstrukturierte Daten und relevante Metadaten speichern
- Die Datenwiederherstellung über APIs oder HTTP/HTTPS erleichtern
- Von Cloud-Dienstanbietern angeboten werden
*Unten sind die Top 5 führenden Objektspeicher-Softwarelösungen aus dem G2 Fall 2021 Grid® Report. Einige Bewertungen können zur Klarheit bearbeitet sein.
1. Amazon Simple Storage Service (S3)
Amazon Simple Storage Service (S3) kommt mit einer einfachen Webdienstschnittstelle, die es Ihnen ermöglicht, Daten von überall im Web zu speichern und abzurufen. Es ist bekannt für seine Skalierbarkeit, Zuverlässigkeit und kostengünstige Infrastruktur.
Was Benutzer mögen:
„Wir können unsere Daten speichern und jederzeit darauf zugreifen. Wir können viele IAM-Benutzer erstellen und ihnen Zugriff gewähren. Wir können die Seite per Handy aufrufen. Wir können eine Testumgebungsseite erstellen und die URL mit dem Kunden teilen. Das S3-Support-Team ist sehr technisch. Sie helfen und unterstützen Sie, wenn Sie sie brauchen. Ihre Sicherheit ist großartig. Unsere Kundendaten sind immer sicher und wir können sie jederzeit herunterladen.“
- Amazon S3 Review, Atul S.
Was Benutzer nicht mögen:
„Es ist ein wenig komplex, wenn wir das AWS S3 zum ersten Mal einrichten, da wir einen Bucket über die Konsole erstellen, Richtlinien einrichten und aus verschiedenen Einstellungen wählen müssen, was für Anfänger ein wenig Kopfschmerzen bereitet. Das Hauptproblem, das ich persönlich mit AWS habe, ist, dass das Herumspielen mit den AWS S3-Einstellungen ohne fortgeschrittene Kenntnisse entweder dazu führt, dass die Dateien im Internet durchsickern oder überhaupt nicht bereitgestellt werden.“
- Amazon S3 Review, Heena M.
2. Google Cloud Storage
Google Cloud Storage bietet zuverlässige und sichere Objektspeicherung mit Funktionen wie mehreren Redundanzoptionen, einfachem Datentransfer, Speicherklassen und mehr. Es ermöglicht auch die Datenkonfiguration mithilfe des Object Lifecycle Management (OLM).
Was Benutzer mögen:
„Google Cloud Storage ist eine großartige Speicherplattform, die eine erstklassige Leistung, Zuverlässigkeit und große Erschwinglichkeit für all meine Speicherbedürfnisse bietet. In meiner Arbeitsposition, in der ich mit vielen Daten zu tun habe, ist es sehr einfach, Daten in den Analyseprozess zu verschieben, mit Hilfe von Google Cloud Storage durch die Verwendung von BigQuery und API für die Datenextraktion.“
- Google Cloud Storage Review, Kelly T.
Was Benutzer nicht mögen:
„Die Daten können in die Hände Dritter gelangen. Die Sicherheit liegt in der Verantwortung des Unternehmens, was dem Benutzer Probleme bereiten kann, wenn es zu Ausfällen kommt. Der vollständige Datenzugriff ist nicht verfügbar. Internetzugang ist jederzeit erforderlich.“
- Google Cloud Storage Review, Corbet T.
3. Azure Blob Storage
Azure Blob Storage ist eine skalierbare Objektspeicherlösung, die ideal für Hochleistungsrechnen, cloud-native Anwendungen und maschinelles Lernen ist. Es ermöglicht den Zugriff auf Daten von überall über HTTP/HTTPS.
Was Benutzer mögen:
„Blob-Speicherung ist die Hauptspeicherlösung in Microsoft Azure. Es hat viele Integrationen und Anwendungsfälle. Die Hauptstärken sind unendliche Kapazität, verschiedene Redundanztypen je nach Bedarf und Budget sowie virtuelle Netzwerkendpunkte.
Flexible Zugriffspolitik basierend auf SAS-Token ermöglicht es Ihnen, permanenten und temporären Zugriff zu gewähren, ohne ihn manuell widerrufen zu müssen. Viele Tools können auf Speicherkonten zugreifen, Sie können es sogar in SQL Server Management Studio öffnen und Ihre Daten darüber verwalten. Unglaubliche Geschwindigkeit, BLOBs sind sogar schneller als lokale SSD-Laufwerke von Azure VMs.“
- Azure Blob Storage Review, Gleb M.
Was Benutzer nicht mögen:
„Die Verwaltung ist ein wenig knifflig. Jetzt gibt es ein RBAC, aber vorher waren es nur die SAS-Token. Es gibt keinen einfachen Weg, eine benutzerdefinierte Domain mit SSL-Zertifikaten zu verwenden - man muss CDN verwenden.“
- Azure Blob Storage Review, Aleksander K.
4. DigitalOcean Spaces
DigitalOcean Spaces ist eine S3-kompatible Objektspeicherlösung, die mit einem integrierten Content Delivery Network (CDN) und einer Drag-and-Drop-Benutzeroberfläche (UI) oder API für die Erstellung zuverlässiger Speicherplätze ausgestattet ist.
Was Benutzer mögen:
„DigitalOcean Spaces ist ein großartiges Tool zum Speichern von Bildern und Dateien für Ihre Anwendungen. Es ist einfach, es mit Java-basierten Anwendungen unter Verwendung des Amazon SDK zu integrieren. Es ist sehr benutzerfreundlich zu verwenden und über die DigitalOcean-Benutzeroberfläche zuzugreifen. Es ist auch erschwinglich für einen einzelnen Entwickler. Ich benutze es jeden Tag für meine Anwendung.“
- DigitalOcean Spaces Review, Sonam S.
Was Benutzer nicht mögen:
„Etwas, das mir an Spaces nicht gefällt, ist die Benutzeroberfläche. Außerdem können Sie manchmal Ausfälle mit dem Space erleben. Sie müssen möglicherweise gelegentlich die Statusseite von DigitalOcean überprüfen.“
- DigitalOcean Spaces Review, Sachin A.
5. IBM Cloud Object Storage
IBM Cloud Object Storage bietet skalierbaren und kosteneffektiven Cloud-Speicher für unstrukturierte Daten. Es ist mit Funktionen wie Hochgeschwindigkeits-Dateiübertragung, integrierten Diensten, Angeboten über mehrere Regionen und mehr ausgestattet.
Was Benutzer mögen:
„Ich mag die Speicherklassenoption von IBM Cloud Object Storage. IBM bietet vier Arten von Speicheroptionen an: Aktiv (Standard), Smart Tier, Cool (Vault), Cold Vault. In unserem Unternehmen besitzt jedes IT-Teammitglied ein IBM-Cloud-Konto und nutzt verschiedene Dienste basierend auf ihrer Arbeit. Als Mitglied des Cybersicherheitsteams überwache ich das System und speichere Protokolldaten auf dem aktiven Tier von IBM.
Wichtiger ist, dass das Unternehmen Backups auf dem Cold Vault-Dienst von IBM hat. Ich habe es getestet und kann sagen, dass es sicher und robust für unser Unternehmen ist. Der Migrationsprozess war einfach und schnell dank des IBM-Support-Desks. Sie haben wirklich gute Arbeit geleistet. Während meiner Sicherheitstests war der Service von IBM der beste unter den Cloud-Diensten. Die Compliance-Check-Leistung war die beste.“
- IBM Cloud Object Storage Review, Nikola M.
Was Benutzer nicht mögen:
„Ich habe ein paar Mal festgestellt, dass das System verzögert und mich dazu veranlasst hat, die Daten erneut hochzuladen, um sie zu speichern.“
- IBM Cloud Object Storage Review, Matthew B.
Daten nachhaltig mit Multi-Petabyte-Kapazitäten speichern
Moderne Datenspeicher müssen Dauerhaftigkeit, Verfügbarkeit, Skalierbarkeit und Sicherheit (PASS) erreichen, um große Mengen unstrukturierter Daten zu speichern und zu verwalten. Cloud-Objektspeicherlösungen erfüllen nicht nur all diese Anforderungen, sondern kommen auch ohne die Kostenbelastung. Deshalb nutzen Organisationen zunehmend Objektspeicher-Software, um öffentliche, private oder Unternehmens-Clouds zu erstellen.
Erfahren Sie mehr darüber, wie Sie den richtigen Cloud-Speicher-Anbieter auswählen, um unstrukturierte Datenspeicherung zu skalieren und gleichzeitig kosteneffizient zu bleiben.

Sudipto Paul
Sudipto Paul is an SEO content manager at G2. He’s been in SaaS content marketing for over five years, focusing on growing organic traffic through smart, data-driven SEO strategies. He holds an MBA from Liverpool John Moores University. You can find him on LinkedIn and say hi!

