



Ich habe Grammarly verwendet, um mir beim Schreiben dieses Artikels zu helfen. Grammarly hat natürliche Sprachverarbeitung verwendet, um mir zu helfen, diesen Artikel großartig aussehen zu lassen.
So weit verbreitet sind die Anwendungsfälle der natürlichen Sprachverarbeitung geworden. NLP-Technologien haben einen langen Weg zurückgelegt, von der Erstellung eines Artikels und der Transkription von Verkaufsgesprächen bis hin zur Abfrage großer Mengen relevanter Informationen und dem wirklichen Verständnis dessen, was der Benutzer meint.
Die Entwicklung der Computerlinguistik hat es Maschinen erleichtert, menschliche Sprachen zu verstehen und die Lücken in der Mensch-Computer-Interaktion zu verringern. Software zur natürlichen Sprachverarbeitung verbessert die Kundenerfahrung, automatisiert Dateneingaben, verbessert Suchvorschläge und stärkt Sicherheitsmaßnahmen in verschiedenen Branchen.
Was ist natürliche Sprachverarbeitung?
Natürliche Sprachverarbeitung (NLP) ist eine künstliche Intelligenz (KI)-Technologie, die es Computerprogrammen ermöglicht, Text und gesprochene Wörter zu interpretieren, um menschliche Sprache besser zu verstehen.
NLP verwendet Machine-Learning (ML)-Algorithmen, regelbasierte Modellierung und Deep-Learning-Modelle, um Computern zu helfen, Sprachdaten zu verarbeiten, um die Absicht und das Sentiment von Nachrichten zu analysieren.
Wenn Sie GPS-Navigation verwendet haben, um sich in einer neuen Stadt zurechtzufinden, oder quer durch den Raum zu einem Sprachassistenten gerufen haben, um das Licht einzuschalten – Glückwunsch, Sie haben ein NLP-Programm kennengelernt!
Dank der natürlichen Sprachverarbeitung können Computeranwendungen auf gesprochene Befehle reagieren und große Textmengen in Echtzeit zusammenfassen, um auf sinnvolle und ausdrucksstarke Weise mit Menschen zu interagieren.
Wie funktioniert NLP?
NLP ist überall um uns herum, auch wenn wir es nicht unbedingt bemerken. Virtuelle Assistenten, Kundenservice-Chatbots, Transformer-Modelle, prädiktiver Text – all das wird durch NLP-Technologie ermöglicht, die unsere Anfragen versteht und filtert. Die Programme überbrücken die Kluft zwischen Computern und Menschen, um Geschäftsabläufe zu organisieren und die Produktivität durch fein abgestimmte Interaktionen zu revitalisieren.
Die Techniken des NLP-Trainings basieren auf Deep Learning und Algorithmen, um menschliche Sprache zu interpretieren und zu verstehen.
Deep-Learning-Modelle verarbeiten unstrukturierte Daten oder qualitative Daten, die nicht mit herkömmlichen Werkzeugen wie Sprache und Text analysiert werden können. Sie verwandeln sie in strukturierte Daten, die in Datenbanken passen, die wir kennen, um verwertbare Erkenntnisse zu liefern.
Die natürliche Sprachverarbeitung extrahiert kontextuelle Informationen, indem sie die Sprache in einzelne Wörter zerlegt und deren Beziehungen identifiziert. Dadurch wird ein genauerer Indexierungs- und Segmentierungsprozess ermöglicht – einer, der auf Sentiment und Absicht basiert.
Bevor ein Modell Textdaten verarbeiten kann, muss es diese in ein Format vorverarbeiten, das die Maschine verstehen kann. Es gibt mehrere Datenverarbeitungstechniken.
Tokenisierung
Die Tokenisierung, der erste Schritt zur Umwandlung von Rohdaten in ein Format, das die Maschine erfassen kann, besteht darin, den Text in kleinere Einheiten, sogenannte Tokens, zu unterteilen. Die Maschine versteht den Text leicht, sobald er in Wörter oder Phrasen zerlegt ist. Da Maschinen nur numerische Daten verstehen, wird der tokenisierte Text als numerische Tokens für die Programme dargestellt.
Beispiel:
Betrachten Sie den folgenden Text, der von einem Benutzer eingegeben wurde:
"Es gibt eine Bank über die Brücke."
Text, den die Maschine nach der Tokenisierung versteht:
["Es", "gibt", "eine", "Bank", "über", "die", "Brücke", "."]
Stoppwortentfernung
Der nächste Vorverarbeitungsschritt in NLP entfernt häufige Wörter mit wenig bis keiner spezifischen Bedeutung im Text. Diese Wörter, bekannt als Stoppwörter, umfassen Artikel (der/die/das), „ist“, „und“, „sind“ und so weiter. Dieser Schritt eliminiert nicht nützliche Wörter und bietet ein bedeutungsvolles, effizientes und genaues Verständnis des Textes.
Beispiel:
Betrachten Sie den gleichen Beispieltext, der von einem Benutzer eingegeben wurde:
"Es gibt eine Bank über die Brücke."
Text, den die Maschine nach der Entfernung von Stoppwörtern versteht:
["Es", "Bank", "über", "Brücke", "."]
Stemming und Lemmatisierung
Stemming und Lemmatisierung beziehen sich auf die Techniken, die NLP-Anwendungen verwenden, um Wörter und Textanalysen zu vereinfachen, indem sie auf ihre Grundform reduziert werden.
Stemming ist ein regelbasierter Ansatz, der Präfixe und Suffixe entfernt, um die Wörter auf ihre grundlegenden Formen oder Stämme zurückzuführen. Der Prozess erfordert nicht viel Rechenleistung, und die resultierenden Grundwörter ergeben möglicherweise nicht immer Sinn, aber sie helfen dem Programm, die Textanalyse zu erleichtern.
Zum Beispiel wird das Wort „sharing“ zu einem „shar“-Stamm.
Eine Einschränkung des Stemming ist, dass mehrere semantisch nicht verwandte Wörter denselben Stamm teilen können.
Lemmatisierung ist ein wörterbuchbasierter Ansatz zur Umwandlung von Wörtern in ihre morphologische Form, auch bekannt als Lemma. Der Prozess erfordert hohen Rechenaufwand aufgrund der Notwendigkeit von Wörterbuchabfragen. Das resultierende Lemma wird immer ein gültiges Wort im Kontext und als Teil der Sprache sein.
Zum Beispiel wird das Wort „sharing“ zu einem „share“-Lemma.
Merkmalextraktion
Da unsere Maschinenfreunde nur Zahlen und Algorithmen verstehen, müssen die Rohtexte, die wir eingeben, in numerische Darstellungen umgewandelt werden. Die Merkmalextraktion hilft, die relevanten Informationen zu behalten und gleichzeitig die Komplexität der Daten zu reduzieren, um nur die notwendigsten Muster und Beziehungen zu erfassen.
Verschiedene Techniken können verwendet werden, um dieses Ergebnis basierend auf der NLP-Aufgabe zu erreichen.
- Bag-of-Words berücksichtigt nur das Vorhandensein oder Fehlen von Wörtern und erstellt einen Vektorraum des Textes. Die Darstellung des Textes erfolgt durch Wortfrequenz anstelle der Wortreihenfolge.
- Term Frequency-Inverse Document Frequency (TF-IDF) berücksichtigt die Bedeutung jedes Wortes im Datensatz. Häufig vorkommende Wörter werden höher bewertet.
- Wort-Einbettungen erfassen semantische Beziehungen zwischen Wörtern und erstellen eine dichte Vektordarstellung. Beispiele sind Word2Vec und GloVe.
- Themenmodellierung extrahiert ähnliche Themen aus Texten, um themenverteilte Dokumente darzustellen. Ein Beispiel für diese Technik ist Latent Dirichlet Allocation (LDA).
NLP-Algorithmen sind in der Regel regelbasiert oder auf Machine-Learning-Modellen trainiert. Kontinuierliches Training und Feedback-Schleifen können große Wissensreservoirs schaffen, die menschliche Absicht besser vorhersagen und falsche Antworten minimieren.
Was sind häufige NLP-Aufgaben?
Die natürliche Sprachverarbeitung verwendet KI-Techniken oder -Aufgaben, um natürliche (menschliche) Sprache zu verarbeiten, zu verstehen und zu erzeugen. Sie verbessern die Mensch-Computer-Interaktion und erleichtern die effektive Kommunikation durch sprachbasierte Anwendungen.
Wortarten-Tagging
Wissen Sie, wer seine Grammatiklektionen aus der 6. Klasse nicht vergessen hat? NLP.
Das Wortarten-Tagging, auch grammatikalisches Tagging genannt, ermöglicht es NLP-Anwendungen, einzelne Wörter in einem Satz zu identifizieren, um ihre Bedeutung im Kontext dieses Satzes zu bestimmen. Dadurch können Computer den Unterschied zwischen Substantiven, Verben, Adjektiven und Adverbien erkennen und ihre Beziehungen verstehen.
Wie im folgenden Beispiel gezeigt, bedeutet das Wortarten-Tagging, dass NLP-Programme die Macht haben, das Verb „like“ im Satz „I like the beach“ zu kontextualisieren und „like“ als Adverb im Satz „I am like Mark“ zu identifizieren.
.png)
Wortbedeutungsauflösung
Das Konzept ist nicht so kompliziert, wie es klingt; es bedeutet einfach, dass NLP-Programme die beabsichtigte Bedeutung desselben Wortes in verschiedenen Kontexten identifizieren können.
Durch semantische Analyse (d. h. das Extrahieren von Bedeutung aus Text und Parsing) können Computer Sätze und Beziehungen zwischen einzelnen Wörtern interpretieren, um im jeweiligen Kontext am meisten Sinn zu ergeben.

Das Wort "bark" im obigen Beispiel hat zwei verschiedene Bedeutungen.
NLP-Anwendungen unterscheiden zwischen dem Bellen eines Hundes und der Baumrinde durch Wortbedeutungsauflösung.
Benannte Entitätserkennung
Anwendungen der natürlichen Sprachverarbeitung können Wörter für bestimmte Kategorien identifizieren, wie z. B. Namen von Personen, Orte und Namen von Organisationen. Durch die benannte Entitätserkennung (NER) extrahiert NLP-Software Entitäten und versteht deren Beziehung zum Rest des Textes.
.png)
Im obigen Beispiel identifiziert die NLP-Aufgabe der benannten Entitätserkennung „Microsoft“ und „Bill Gates“ als Organisation bzw. Person.
Anwendungen der benannten Entitätserkennung
- Fakten aus Fake News extrahieren: NER kann wichtige Entitäten identifizieren, die helfen können, Nachrichtenquellen zu überprüfen.
- Informationsabruf: Um bei der Erstellung von Abrufsystemen zu helfen, bei denen Benutzer nach spezifischen Informationen suchen können, um relevante Dokumente zu finden.
Ko-Referenzauflösung
Hochrangige NLP-Aufgaben wie Fragebeantwortung und Informationsabruf (mehr dazu später) erfordern, dass Computer alle Wörter identifizieren, die sich auf dieselbe Entität beziehen. Dieser Prozess, bekannt als Ko-Referenzauflösung, hilft Programmen, Personen/Objekte zu bestimmen, die mit bestimmten Pronomen verbunden sind.
Die Ko-Referenzauflösung ist auch der Grund, warum Computer wissen, wann ein idiomatischer Ausdruck Teil eines Textes ist.
Spracherkennung
NLP-Programme profitieren davon, den Prozess der Umwandlung gesprochener Sprache in – mehr oder weniger – Computersprache zu verstehen. Spracherkennung ist entscheidend für die Ermöglichung natürlicher und intuitiver Mensch-Computer-Interaktionen.
Schauen wir uns ein paar Beispiele für Spracherkennung als Teil der natürlichen Sprachverarbeitung an.
- Sprachassistenten: Unsere virtuellen besten Freunde Siri, Alexa und Google Assistant reagieren auf unsere Befehle, indem sie Spracherkennungstechniken verwenden, um relevante Antworten zu geben.
- Transkription und Diktat: Transkriptionen von Audioaufnahmen und Umwandlungen gesprochener Sprache in Text sind grundlegend für die Content-Erstellung, den Rechts- und Bildungssektor.
- Datenvorverarbeitung: Spracherkennung ist wichtig, um Rohdaten in eine verständlichere Form zu transformieren. Die Vorverarbeitung kann für Audiodaten und Textdaten erfolgen.
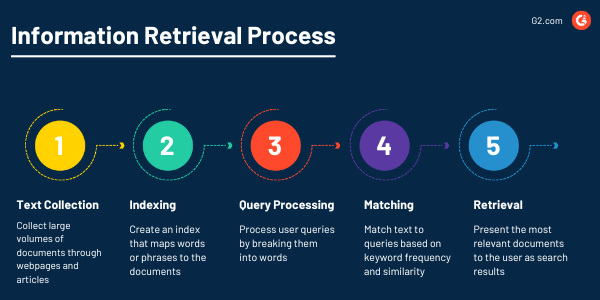
Informationsabruf
NLP-Programme werden immer das wichtige Dokument finden, genau dann, wenn Sie es brauchen, dank ihrer leistungsstarken Fähigkeit, Informationen aus großen Datensätzen abzurufen. Das Ziel des Informationsabrufs als NLP-Aufgabe ist es, Benutzern genaue und nützliche Informationen aus Textsammlungen durch Text-Mining zu bieten.
Sentiment-Analyse
Haben Sie sich jemals gefragt, wie Kundenservice-Bots fast immer wissen, wie Sie sich fühlen? Das verdanken wir der Sentiment-Analyse – einem automatisierten Prozess, der den emotionalen Ton und die ausgedrückten Stimmungen in verschiedenen Anwendungsfällen erkennt.
Machine-Learning-Modelle können für die Sentiment-Analyse trainiert werden, indem sie Sentiment-Labeling (positiv, negativ, neutral) Klassifizierung, Nachbearbeitung und Sentiment-Bewertung verwenden.
Die Sentiment-Analyse ist eine großartige Möglichkeit für Unternehmen, Kundenmeinungen durch Produktbewertungen zu gewinnen und ihre Marken basierend auf sozialen Medienstimmungen zu überwachen.
Maschinenübersetzung
Die NLP-Aufgabe der automatischen Übersetzung von Text oder gesprochenem Inhalt von einer Sprache in eine andere wird stark in Maschinenübersetzungssoftware verwendet. Ziel der Maschinenübersetzung ist es, genaue und kohärente Übersetzungen bereitzustellen und gleichzeitig die kontextuelle Präzision zu wahren.
Übersetzungsmodelle verwenden auch Spracherkennung. Sie sind darauf ausgelegt, die globale Kommunikation zu verbessern und Sprachbarrieren in Wirtschaft, Bildung, Gesundheitswesen und internationalen Beziehungen abzubauen.
Spam-Erkennung
Haben Sie jemals gedacht, eine E-Mail sei legitim und darauf geantwortet, aber es war nur Spam? Ich auch.
Die NLP-Aufgabe, automatisch irrelevante Nachrichten aus einer großen Nachrichtenmenge, wie E-Mails und Social-Media-Posts, zu erkennen und zu entfernen, wird als Spam-Erkennung bezeichnet.
Der Prozess hilft, betrügerische Nachrichten von echten zu unterscheiden und die Sicherheit der Benutzer auf Kommunikationsplattformen zu gewährleisten.
NLP-Bibliotheken und -Frameworks
Programmiersprachen sind für NLP das, was eine Motte für eine Flamme ist. Obwohl viele Sprachen und Bibliotheken Aufgaben der natürlichen Sprachverarbeitung unterstützen, gibt es einige beliebte.
Python
Die am häufigsten verwendete Programmiersprache für NLP-Aufgaben, Bibliotheken und Deep-Learning-Frameworks ist für Python geschrieben.
- Natural Language Toolkit (NLTK): Eine der ersten NLP-Bibliotheken, die in Python geschrieben wurde, das NLTK ist bekannt für seine benutzerfreundlichen Schnittstellen und Textverarbeitungsbibliotheken für Tagging, Stemming und semantische Analyse.
- spaCy: Eine Open-Source-NLP-Bibliothek, spaCy bietet vortrainierte Vektoren. Sie können es für NER, Wortarten-Tagging, Klassifizierung und morphologische Analyse verwenden.
- Deep-Learning-Bibliotheken: PyTorch und TensorFlow sind gängige Werkzeuge zur Entwicklung von NLP-Datenmodellen.
R
Statistiker verwenden die Programmiersprache für statistische Berechnungen und grafische NLP-Modelle, die in R geschrieben sind. Dazu gehören Word2Vec und TidyText.
Geschäftsanwendungen von NLP
Techniken der natürlichen Sprachverarbeitung werden in vielen Geschäftsfällen eingesetzt, um die betriebliche Effizienz, Produktivität und kritische Prozesse zu verbessern.
Chatbots und virtuelle Assistenten
Der Aufstieg der konversationellen KI hat die Art und Weise verändert, wie Chatbots und virtuelle Assistenten mit Menschen interagieren, insbesondere im Kundenservice.
NLP treibt die menschenähnlichen Fähigkeiten von Chatbots an, um automatisierten Kundensupport zu skalieren und gleichzeitig wirtschaftliche Abläufe aufrechtzuerhalten. Chat- und Sprachbots können personalisierte Empfehlungen und lokalisierte Chat-Funktionen bieten, um den Kaufprozess zu unterstützen, häufig gestellte Fragen zu beantworten und Benutzern in Echtzeit zu helfen.
Sprach-zu-Text-Funktionen sind auch nützlich, um Callcenter-Analysen zu verfolgen und Sprachdaten in Text zu transkribieren.
Social-Media-Überwachung
Die Sentiment-Analyse auf sozialen Plattformen hilft, Kundenfeedback und Bewertungen zu bewerten, um die Kundenzufriedenheit durch wertvolle Datenanalysen zu verstehen.
Social-Media-Überwachungstools werden von der natürlichen Sprachverarbeitung angetrieben, um Hör-, Tracking- und Inhalts-Sammelfunktionen zu gewähren. Diese Anwendungen werden häufig zur Durchführung von Marktforschung, zur Verfolgung von Trendanalysen und zur Identifizierung von Mustern in verschiedenen sozialen Netzwerken eingesetzt.
Erkenntnisgewinnung und Betrugserkennung
Die Gesundheits- und Rechtsbranche nutzt NLP-Technologie, um hochwertige, relevante Datenanalysen aus großen Mengen klinischer Studiendaten, wissenschaftlicher Literatur und rechtlicher Verträge zu extrahieren.
Wie bei der Spam-Erkennung kann die NLP-Technologie betrügerische Aktivitäten erkennen, indem sie Muster in Daten wahrnimmt. Dies ist besonders nützlich im Finanzsektor zur Überwachung von Transaktionen.
NLP vs. NLU vs. NLG
Obwohl es nur einen unterscheidenden Begriff in der natürlichen Sprachverarbeitung, dem natürlichen Sprachverständnis und der natürlichen Sprachgenerierung gibt, existieren einige Unterschiede zwischen den drei Konzepten.
Natürliche Sprachverarbeitung
NLP ist ein Zweig der KI, der Computern hilft, menschliche Sprache zu verstehen, zu interpretieren und zu erzeugen. Häufige NLP-Aufgaben umfassen Spracherkennung, Sentiment-Analyse und benannte Entitätserkennung.
NLP wird häufig in Sprachassistenten zur Zusammenfassung großer Textmengen und in Übersetzungsdiensten verwendet.
Natürliches Sprachverständnis (NLU)
Ein Teilbereich von NLP, NLU-Software konzentriert sich auf das Verständnis des Textes, um Bedeutung aus den Daten zu extrahieren. Es kombiniert Softwarelogik, Linguistik, ML und KI, um natürliche Sprache zu verstehen.
Häufige NLU-Aufgaben umfassen:
- Absichtserkennung. NLU-Modelle werden verwendet, um die Absicht verschiedener Entitäten für Textklassifizierungs- und Kategorisierungszwecke zu identifizieren. Zum Beispiel die Erstellung verschiedener Abschnitte für Unternehmensnachrichten, Unterhaltung und Wirtschaft.
- Inhaltsanalyse. Durch das Verständnis von Verbindungen zwischen Inhalten kann NLU eine eingehende Analyse von Entitäten durchführen, um komplexe Stimmungen und Beziehungen hervorzuheben.
- Kognitive Suche. NLU analysiert und extrahiert unstrukturierte Daten, sodass es relevante Informationen aus verschiedenen Datensätzen abrufen kann. Dies verbessert die Suchanfragen und liefert relevante Absichtsinformationen mithilfe von prädiktiver Analyse.
Top 5 NLU-Software
1. Amazon Comprehend2. IBM Watson Natural Language Classifier
3. Azure Translator Speech API
4. Azure Translator Text API
5. Apace cTAKES
*Diese Daten wurden aus dem G2 Summer Grid Report am 19. Juli 2023 basierend auf unserer Scoring-Methodik.
Natürliche Sprachgenerierung (NLG)
Am anderen Ende von NLU steht die NLG-Technologie, der Zweig der KI, der geschriebene oder gesprochene Texte aus einem Datensatz generiert. Sie ermöglicht es Computern, uns in einer Sprache Feedback zu geben, die für uns verständlich ist, nicht für Maschinen.
Häufige NLG-Aufgaben umfassen:
- Datenkonvertierung. NLG-Modelle konvertieren strukturierte Daten in für Menschen lesbare Texte.
- Kundeninteraktionen. Diese bieten natürlich klingende Antworten, Stimmungsanpassung und personalisierte Kundenkommunikation.
Top 5 NLG-Software
1. Anyword2. Quill
3. AX Semantics
4. Wordsmith
5. Phrazor by vPhrase
*Diese Daten wurden aus dem G2 Summer Grid Report am 19. Juli 2023 basierend auf unserer Scoring-Methodik.

Das Geheimnis der natürlichen Sprache entschlüsseln
Obwohl NLP wie ein Zauberer erscheinen mag, ist es das nicht. Es kombiniert verschiedene leistungsstarke rechnerische Fähigkeiten, die es in vielen Aufgaben nützlich machen, die menschliche Aufgaben effizienter machen.
Ob durch Chatbot-Begrüßungen oder Textzusammenfassungen, die Welt der NLP strebt weiterhin danach, wertvolle Erkenntnisse aus großen menschlichen Sprachdatensätzen zu liefern. NLP-Technologien machen unser persönliches und berufliches Leben engagierter, personalisierter und interaktiver, während wir uns in unserer neuen datenzentrierten Welt zurechtfinden.
Eine der beliebtesten NLP-Funktionalitäten ist die Verwendung in Sprachassistenten. Erfahren Sie mehr darüber, wie Spracherkennung funktioniert und welche Funktionen sie bietet, die es Ihnen ermöglichen, Befehle zu rufen.
Dieser Artikel wurde ursprünglich 2019 veröffentlicht. Er wurde gemäß neuen redaktionellen Richtlinien aktualisiert, mit neuen Ressourcen und aktuellen Beispielen.

Aayushi Sanghavi
Aayushi Sanghavi is a Campaign Coordinator at G2 for the Content and SEO teams at G2 and is exploring her interests in project management and process optimization. Previously, she has written for the Customer Service and Tech Verticals space. In her free time, she volunteers at animal shelters, dances, or attempts to learn a new language.

