



Tiefes Lernen ist die Art und Weise, wie eine intelligente Maschine Dinge lernt.
Es ist eine Lernmethode für Maschinen, inspiriert von der Struktur des menschlichen Gehirns und wie wir lernen.
Es ist eine kritische Technologie, die autonome Fahrzeuge zur Realität macht und auch der Grund, warum der Sprachassistent Ihres Smartphones mit der Zeit besser darin wird, Ihnen zu helfen. Mit anderen Worten, tiefes Lernen ist unsere beste Chance, Maschinen mit menschenähnlicher Intelligenz zu schaffen.
Was ist tiefes Lernen?
Tiefes Lernen (DL) ist ein Teilbereich des maschinellen Lernens, der die Funktionsweise des menschlichen Gehirns bei der Datenverarbeitung imitiert. DL ermöglicht es Maschinen, ohne menschliche Aufsicht zu lernen und verleiht ihnen die Fähigkeit, Sprache zu erkennen, Sprachen zu übersetzen, Objekte zu erkennen und sogar datengetriebene Entscheidungen zu treffen.
Mit anderen Worten, tiefes Lernen ist eine Art des maschinellen Lernens (ML), inspiriert von der Struktur des menschlichen Gehirns. Tatsächlich ist DL eine Nachahmung der Neuronen des menschlichen Gehirns und versucht, deren Funktionen zu imitieren.
Obwohl tiefes Lernen ein Zweig des maschinellen Lernens ist, sind DL-Systeme nicht durch eine begrenzte Lernkapazität wie traditionelle ML-Algorithmen eingeschränkt. Stattdessen können DL-Systeme mit dem Zugang zu größeren Datenmengen lernen und ihre Leistung verbessern.
Tiefes Lernen ermöglicht es künstlichen Intelligenz-Systemen, die Art und Weise zu imitieren, wie Menschen bestimmte Arten von Wissen erwerben. DL-Algorithmen versuchen, Schlussfolgerungen zu ziehen – ähnlich wie Menschen es tun – indem sie kontinuierlich Daten analysieren. Um dies zu erreichen, verwendet DL künstliche neuronale Netze (ANNs).
DL imitiert die Arbeitsweise des menschlichen Gehirns, hauptsächlich Funktionen wie die Datenverarbeitung und die Erstellung von Mustern für Entscheidungsfindungen. Es ist interessant zu bemerken, dass Wissenschaftler und KI-Forscher begannen, ANNs zu bauen, damit Maschinen schließlich die Eigenschaften menschlicher Intelligenz zeigen könnten, wie Problemlösungsfähigkeiten, Selbstbewusstsein, Wahrnehmung, Kreativität und Empathie, um nur einige zu nennen.
Tiefes Lernen wäre ohne die günstiger, schneller und kleiner werdenden Computer nicht möglich gewesen. Dasselbe gilt für Speichermedien, da große Datenmengen gespeichert und verarbeitet werden müssen, damit tiefes Lernen Realität wird. Deshalb wurde tiefes Lernen, obwohl es bereits in den 1980er Jahren theoretisiert wurde, erst kürzlich machbar.
Die Verarbeitung solcher enormen Mengen unstrukturierter Daten ist für Menschen praktisch unmöglich. Selbst wenn wir es schaffen, die benötigte Manpower zu beschaffen, könnte es Jahre dauern, um relevante Informationen aus diesen großen Datensätzen zu analysieren und zu extrahieren. Mit tiefem Lernen wird dieser Prozess jedoch erstaunlich vereinfacht.
Mit Hilfe des tiefen Lernens kann ein KI-System ohne jegliche menschliche Aufsicht lernen und sich verbessern. DL ermöglicht es Maschinen auch, aus Daten zu lernen, die nicht beschriftet oder unstrukturiert sind, oder beides. Beachten Sie jedoch, dass der Lernprozess unüberwacht, halbüberwacht oder überwacht sein kann.
Tiefes Lernen ist auch ein kritischer Bestandteil der Datenwissenschaft. Es ist vorteilhaft für Datenwissenschaftler, große Datenmengen zu sammeln, zu analysieren und zu interpretieren, und macht Prozesse wie die prädiktive Modellierung schneller und effizienter.
Zweige der künstlichen Intelligenz wie Computer Vision und natürliche Sprachverarbeitung sind dank des tiefen Lernens praktikabel. Bevor wir weiter darauf eingehen, schauen wir uns an, wie tiefes Lernen funktioniert, um uns zu helfen.
Wie funktioniert tiefes Lernen?
Einfacher ausgedrückt, findet der Lernprozess von DL statt, indem die Systemaktionen basierend auf einer kontinuierlichen Feedbackschleife modifiziert werden. Das Lernsystem wird für jede richtige Aktion belohnt und für die falschen bestraft. Das System versucht, seine Aktionen anzupassen, um die Belohnung zu maximieren.
Tiefes Lernen verwendet überwachte, halbüberwachte sowie unüberwachte Lernmodelle zum Trainieren.
Die Neuronen, die die neuronalen Netze bilden, können basierend auf ihrer Hierarchie in drei Kategorien eingeteilt werden: Eingabe-, versteckte und Ausgabeschichten.
- Die Eingabeschicht, die die erste Neuronenschicht ist, empfängt die Eingabedaten und leitet sie an die erste versteckte Schicht weiter.
- Die versteckten Schichten führen spezifische Berechnungen, wie die Bilderkennung, an den empfangenen Daten durch.
- Sobald die Berechnungen abgeschlossen sind, erzeugt die Ausgabeschicht die erforderliche Ausgabe.
Wie bereits erwähnt, wird tiefes Lernen durch künstliche neuronale Netze ermöglicht. Sie werden gebaut, indem sie sich von den neuronalen Netzen des menschlichen Gehirns inspirieren lassen. Eine große Anzahl von Perzeptronen – das künstliche Gegenstück zu Neuronen – wird zusammengefügt, um ANNs zu bilden.
Der Begriff "tief" wird verwendet, um die Anzahl der versteckten Schichten zu spezifizieren, die die neuronalen Netze haben. Während traditionelle neuronale Netze zwei bis drei versteckte Schichten enthalten, können tiefe Netze sogar 150 Schichten haben.
Eine einfache Möglichkeit, zu verstehen, wie tiefes Lernen funktioniert, besteht darin, sich konvolutionale neuronale Netze (CNNs) anzusehen. Es ist eine der beliebtesten Arten von tiefen neuronalen Netzen neben rekurrenten neuronalen Netzen (RNNs), generativen gegnerischen Netzen (GANs) und Feedforward-neuronalen Netzen.
CNN extrahiert Merkmale direkt aus den Bildern und eliminiert die Notwendigkeit der manuellen Merkmalsextraktion. Keine der Merkmale sind vortrainiert; stattdessen werden sie vom Netzwerk gelernt, wenn es auf dem gegebenen Satz von Bildern trainiert wird. Diese automatisierte Merkmalsextraktionseigenschaft macht tiefe Lernmodelle hochwirksam für die Objektklassifizierung und andere Anwendungen der Computer Vision.
Der Grund, warum tiefe neuronale Netze hochgenau bei der Identifizierung von Merkmalen und der Klassifizierung von Bildern sind, liegt in den Hunderten von Schichten, die sie enthalten. Jede Schicht würde lernen, spezifische Merkmale zu identifizieren, und mit zunehmender Anzahl der Schichten steigt die Komplexität der gelernten Bildmerkmale.
Möchten Sie mehr über Künstliche Neuronale Netzwerk-Software erfahren? Erkunden Sie Künstliches Neuronales Netzwerk Produkte.
Tiefes Lernen vs. maschinelles Lernen
Maschinelles Lernen ist eine Anwendung der KI, die es Maschinen ermöglicht, automatisch aus Erfahrung zu lernen und sich weiterzuentwickeln, ohne explizit programmiert zu werden.
Der Spam-Filter-Algorithmus in Ihrem E-Mail-Konto ist ein hervorragendes Beispiel für einen maschinellen Lernalgorithmus. ML-Algorithmen werden auch in OTT-Plattformen wie Netflix verwendet, um Filme und Serien zu empfehlen, die Sie wahrscheinlich ansehen und genießen werden.
ML-Algorithmen sind in der Lage, Daten zu analysieren, Muster zu identifizieren und Vorhersagen zu treffen. Sie lernen und passen sich an, wenn ihnen neuere Datensätze vorgestellt werden. In gewisser Weise macht maschinelles Lernen Computer menschlicher, da es die Fähigkeit verleiht, zu lernen und sich weiterzuentwickeln.
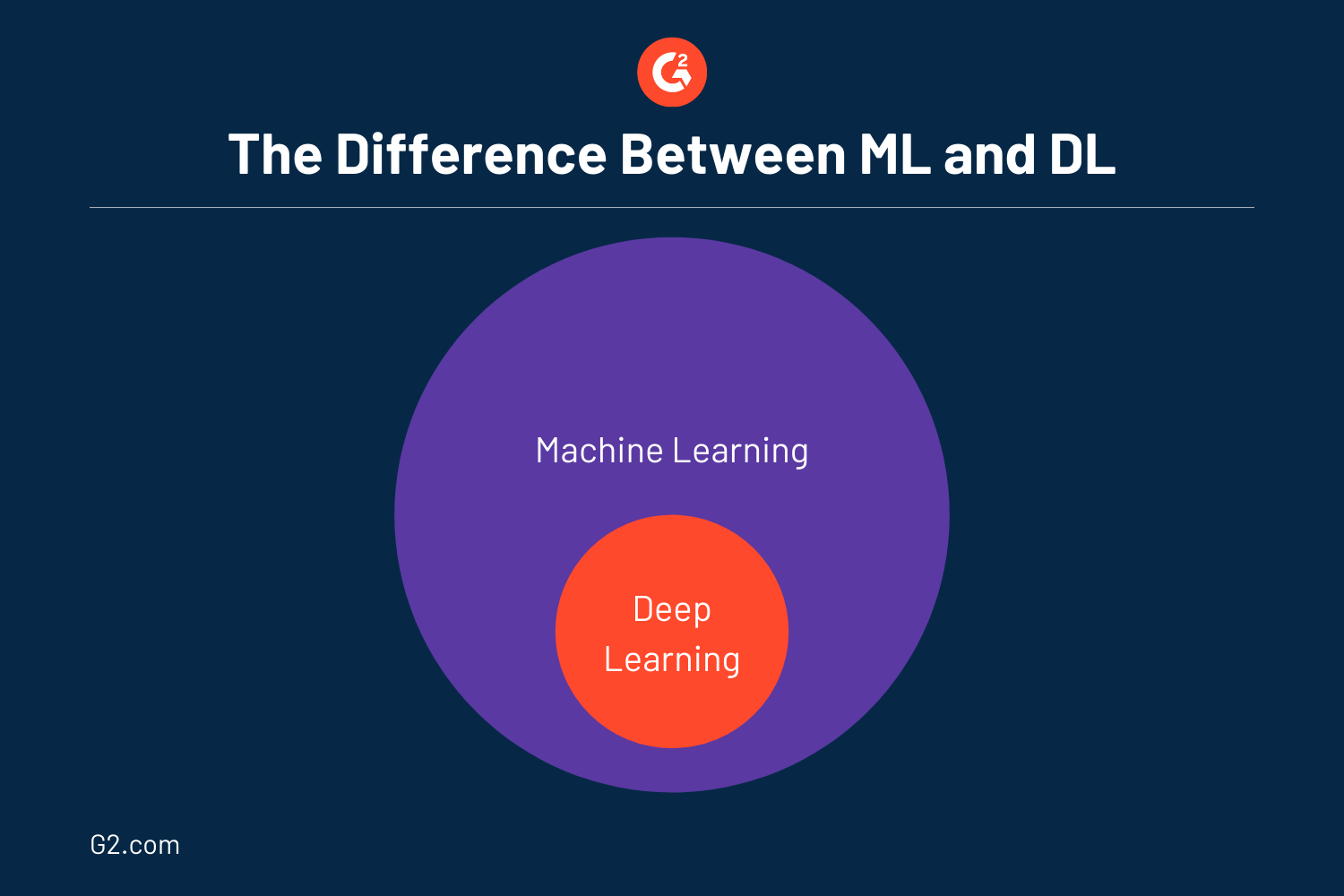
Wie bereits erwähnt, ist tiefes Lernen ein Teilbereich des maschinellen Lernens, das wiederum ein Teilbereich der künstlichen Intelligenz ist. Genauer gesagt ist tiefes Lernen tatsächlich maschinelles Lernen und kann als eine weiterentwickelte Version des letzteren betrachtet werden. Oft verwenden viele DL und ML austauschbar, da sie fast ähnlich funktionieren.
Ihre Fähigkeiten sind jedoch unterschiedlich. Obwohl ML-Algorithmen allmählich lernen und sich verbessern können, benötigen sie dennoch eine Form der Anleitung. Wenn der Algorithmus beispielsweise eine falsche Vorhersage macht, ist menschliches Eingreifen erforderlich, um Anpassungen vorzunehmen. Im Gegensatz dazu können tiefes Lernen-Algorithmen mit Hilfe künstlicher neuronaler Netze bestimmen, ob ihre Vorhersagen korrekt sind oder nicht.
Das AlphaGo-Programm, das von DeepMind entwickelt wurde, nutzt tiefes Lernen umfassend. Es ist das allererste Computerprogramm, das einen menschlichen professionellen Go-Spieler besiegt hat. AlphaGo wurde von zahlreichen fortgeschrittenen Versionen abgelöst, darunter MuZero, das ein Spiel meistern kann, ohne die Regeln zu kennen.
Es ist interessant zu bemerken, dass Forscher versucht haben, traditionelle maschinelle Lerntechniken zu verwenden, um Roboter zu trainieren, das Spiel zu meistern, aber sie hatten nur Erfolg, als sie tiefes Lernen mit Verstärkungslernen und anderen Paradigmen kombinierten.
Eine weitere Möglichkeit, zwischen maschinellem Lernen und tiefem Lernen zu unterscheiden, besteht darin, zu betrachten, wie sie lernen. Angenommen, Sie müssen einer Maschine beibringen, die Bilder von Hunden und Katzen zu kategorisieren. Wenn Sie das maschinelle Lernmodell verwenden, müssen Sie strukturierte Daten bereitstellen – in diesem Fall die beschrifteten Bilder von Hunden und Katzen – damit der Algorithmus die spezifischen Merkmale lernen kann, die die Bilder beider Tiere unterscheiden. Der Algorithmus wird mit jedem ihm gezeigten beschrifteten Bild besser.
| Maschinelles Lernen | Tiefes Lernen | |
| Menschliche Aufsicht | Erforderlich | Nicht erforderlich |
| Beschriftete Daten | Erforderlich | Nicht erforderlich |
| Trainingszeit | Sekunden oder ein paar Stunden | Stunden oder ein paar Wochen |
| Anzahl der benötigten Datenpunkte | Tausende | Millionen |
| Rechenressourcen | Weniger Ressourcen benötigt | Massive Ressourcen benötigt |
| GPU | Nicht erforderlich | Erforderlich |
Sobald die Bilder durch verschiedene Schichten der tiefen neuronalen Netze verarbeitet werden, hat das System Zugang zu spezifischen Identifikatoren, die bei der Klassifizierung der Tiere und ihrer Bilder helfen. Die unterschiedlichen Ausgaben, die von jeder Schicht des neuronalen Netzes verarbeitet werden, werden kombiniert, um die Bilder effektiv zu kategorisieren.
Die Anwesenheit von neuronalen Netzen bedeutet auch, dass tiefes Lernen-Algorithmen große Datensätze erfordern. Das liegt daran, dass die DL-Algorithmen nur lernen können, wenn sie einer Million oder mehr Datenpunkten ausgesetzt sind. Andererseits können ML-Algorithmen mit vordefinierten Richtlinien lernen und sich verbessern.
Ein weiterer bemerkenswerter Unterschied zwischen maschinellem Lernen und tiefem Lernen ist die Art der Hardware, die für beide erforderlich ist. Da die Komplexität der Berechnungen und die Menge der verarbeiteten Daten für das maschinelle Lernen erheblich geringer ist, können ML-Programme auf Low-End-Computern laufen, ohne viel Rechenleistung zu benötigen.
Andererseits erfordern tiefe Lernsysteme massive Rechenressourcen und leistungsstarke Hardwarekomponenten wie grafische Verarbeitungseinheiten (GPUs). Der Informatiker Andrew Ng stellte fest, dass GPUs die Geschwindigkeit von tiefen Lernsystemen um mehr als das 100-fache erhöhen können.
Mit Hilfe von GPUs kann die Zeit, die benötigt wird, um tiefe Lernmodelle zu trainieren, von Tagen auf nur Stunden verkürzt werden. Die Mehrheit der tiefen Lern-Frameworks wie PyTorch und TensorFlow sind bereits GPU-beschleunigt.
Unternehmen wie Nvidia nehmen GPU-beschleunigtes tiefes Lernen ernster und passen ihre Produkte entsprechend an. Außerdem sind GPUs nützlich für Matrix- oder Vektorrechnungen.
Die Zeit, die benötigt wird, um tiefe Lern- und maschinelle Lernalgorithmen zu trainieren, ist ebenfalls erheblich unterschiedlich. Wie Sie vielleicht vermutet haben, benötigen tiefe Lernalgorithmen viel Zeit zum Trainieren aufgrund der enormen Datenmenge und der komplexen Berechnungen. Es kann einige Stunden oder sogar Wochen dauern, um ein DL-System zu trainieren, während ein ML-System in wenigen Sekunden oder Stunden trainiert werden kann.
Wiederum sollte die Wahl zwischen tiefem Lernen und maschinellem Lernen eine sehr informierte Entscheidung sein. Die Entscheidung muss unter Berücksichtigung des Volumens und der Art der Daten, der Komplexität des zu lösenden Problems und der verfügbaren Rechenressourcen getroffen werden.
Anwendungen des tiefen Lernens
Obwohl tiefes Lernen als aufstrebendes Feld gilt, profitieren Forscher und Organisationen bereits von seinen Anwendungen. Hier sind einige Beispiele für tiefes Lernen, die die Welt um uns herum gestalten, und höchstwahrscheinlich sind Sie einigen von ihnen in Ihrem täglichen Leben begegnet.
Selbstfahrende Autos
Autonome Fahrzeuge sind die bekanntesten Nutznießer des tiefen Lernens. Millionen von Datensätzen, die zahlreiche reale Szenarien replizieren, werden in das System eingespeist, das verwendet wird, um dem Fahrzeug beizubringen, wie es sicher auf der Straße navigiert.
Mit Hilfe von tiefen Lernmodellen können Hersteller sicherstellen, dass fahrerlose Autos unvorhergesehene Szenarien bewältigen können, ohne den Fahrern oder Fußgängern Schaden zuzufügen.
Neben der Hilfe für Maschinen bei der Lösung hypothetischer Szenarien hilft tiefes Lernen ihnen auch, die von Kameras, GPS und zahlreichen Sensoren gesammelten Rohdaten zu analysieren und zu verarbeiten. Dadurch können die autonomen Fahrzeuge zwischen Fahrspuren und Straßenbegrenzungen, Barrikaden, Schildern, Fußgängern, langsamen oder angehaltenen Autos und mehr unterscheiden.
Natürliche Sprachverarbeitung
Die natürliche Sprachverarbeitung (NLP) ist ein Bereich der künstlichen Intelligenz, der Maschinen die Fähigkeit verleiht, menschliche Sprachen zu verstehen, zu interpretieren und Bedeutung daraus abzuleiten. Einfach ausgedrückt, macht NLP es Maschinen möglich, mit Menschen zu kommunizieren und sogar die kontextuellen Nuancen einer Sprache zu verstehen.
Intelligente Assistenten wie Siri und Google Assistant und Sprachübersetzungs-Apps wie Google Translate sind reale Beispiele für NLP. NLP kann weiter in natürliche Sprachgenerierung (NLG) und natürliches Sprachverständnis (NLU) unterteilt werden.
Tipp: Schauen Sie sich einige der besten Softwarelösungen zur natürlichen Sprachverarbeitung in der Branche an.
Auf den ersten Blick mag Spracherkennung nur eine Frage der Umwandlung von Klang in entsprechende Wörter sein. Für Menschen ist es ziemlich einfach, da der auditive Kortex unseres Gehirns jahrelang darauf trainiert wurde, eine oder mehrere gesprochene Sprachen zu erkennen und zu verstehen.
Ein einfaches Beispiel, um die Komplexität des Verstehens von Klängen darzustellen, ist "recognize speech" und "wreck a nice beach". Beide klingen sehr ähnlich, obwohl ihre Bedeutungen völlig unterschiedlich sind. Obwohl Maschinen Wörter in einem Satz erkennen können, ist das Verständnis ihrer kontextuellen Bedeutung immer noch eine herkulische Aufgabe. Hier kommt DL für NLP ins Spiel.
Fast alle intelligenten Assistenten verlassen sich auf tiefes Lernen, und ihre Verständnis- und Genauigkeitsniveaus steigen mit jeder Aufgabe. Google Assistant, der sich fast vollständig auf DL verlässt, hat die höchste Genauigkeit.
Tiefes Lernen ermöglicht es Maschinen auch, die Komplexitäten einer Sprache zu verstehen, wie tonale Nuancen, Ausdrücke und sogar Sarkasmus. Das Verständnis der Komplexitäten einer Sprache ist auch entscheidend für die Stimmungsanalyse von Textdaten. Nur dann können Unternehmen Marken- und Produktreputation überwachen, die öffentliche Meinung verstehen und Kundenerfahrungen analysieren.
Eine weitere Anwendung des tiefen Lernens ist die Dokumentenzusammenfassung. Dokumentenzusammenfassung oder einfach Textzusammenfassung ist die Aufgabe, wichtige Informationen aus einem großen Textabschnitt zu extrahieren und eine prägnante Zusammenfassung davon zu erstellen. Neben der Zeitersparnis für Menschen kann die Dokumentenzusammenfassung auch Computerprogrammen helfen, die große Datenmengen in kurzer Zeit verarbeiten müssen.
Sprechererkennung ist eine weitere nützliche Anwendung des tiefen Lernens und wird immer genauer. Regierungen können diese Technologie nutzen, um Terroristen zu identifizieren, die anonyme Telefonanrufe tätigen, indem sie ihre Sprachproben mit einer Datenbank anerkannter Stimmen abgleichen.
Bilderkennung
Vor dem tiefen Lernen war der Bereich der Bilderkennung stark auf manuelle Abstimmung angewiesen. Das bedeutet, dass viele Prozesse von Menschen durchgeführt werden mussten und viel Zeit in Anspruch nahmen. Tiefes Lernen eliminiert die Notwendigkeit der manuellen oder traditionellen Bildverarbeitung und beschleunigt den gesamten Prozess erheblich.
In diesem Jahrzehnt verlassen sich die meisten genauen Objekterkennungssysteme, denen Sie begegnen, ausschließlich auf tiefes Lernen. Google Fotos ist ein hervorragendes Beispiel. Es verwendet tiefes Lernen, um Bilder zu klassifizieren und zu gruppieren.
Selbst wenn Sie keine manuelle Beschriftung vorgenommen haben, können Sie in Ihrem Google Fotos-Album nach etwas wie "Insekten auf Blumen" suchen und Ergebnisse erhalten, vorausgesetzt, Sie haben verwandte Bilder gespeichert. Sie können sogar nach Tieren basierend auf ihrer Art oder Rasse suchen und erhalten dennoch alle Fotos, die das betreffende Tier enthalten.
Während traditionelle nicht-tiefe Lernsysteme Schwierigkeiten haben, die Objekte eines Bildes zu identifizieren, geht tiefes Lernen mehrere Schritte weiter. Es leistet beeindruckende Arbeit bei der Erkennung von menschlichen Gesichtern, Tieren, Orten und Dingen mit hoher Genauigkeit und nahezu null Fehlern.
Fertigung
Mit der Einführung des Internets der Dinge (IoT) werden Fabriken intelligenter als je zuvor. Automatisierung ist in der Fertigungsindustrie nicht neu, und tiefes Lernen macht die Dinge reibungsloser.
Mit Hilfe von tiefen Lernarchitekturen wie CNN können Unternehmen die Mehrheit der menschlichen Bediener ersetzen, die ansonsten integraler Bestandteil der Erkennung defekter Produkte in der Montagelinie waren.
Auf diese Weise wird die Erkennung von Qualitätsproblemen genauer und kostengünstiger, und die Wahrscheinlichkeit menschlicher Fehler wird eliminiert. Solche Systeme sind auch hoch skalierbar und können darauf trainiert werden, Qualitätsprobleme an jedem Punkt der Produktionslinie zu erkennen.
Eine weitere Anwendung des tiefen Lernens in der Fertigung ist die vorausschauende Wartung. Durch das Sammeln und Analysieren der Gesundheitsdaten von Maschinen über einen bestimmten Zeitraum können tiefes Lernen-Algorithmen die Wahrscheinlichkeit eines Ausfalls eines Fertigungsgeräts vorhersagen.
Die Bestimmung, wann ein Gerät repariert werden muss, ist aus finanzieller Sicht eines Unternehmens entscheidend, da eine fehlerhafte Maschine die gesamte Produktion zum Stillstand bringen könnte. Da unregelmäßige Wartung auch kostspielige, irreparable Schäden an Maschinen und im schlimmsten Fall katastrophale Fabrikunfälle verursachen kann, können Unternehmen mit vorausschauender Wartung viel sparen. Zu wissen, wann repariert werden muss, hilft Unternehmen auch, im Voraus zu planen und nach Alternativen zu suchen, um die Ausfallzeiten der Fabrik zu reduzieren.
Optimierung der Fabrikeingaben ist eine weitere vorteilhafte Anwendung des tiefen Lernens. Da Verbraucher zunehmend besorgt über den CO2-Fußabdruck von Produkten und die umweltfreundlichen Reformen ihrer Hersteller sind, haben Unternehmen keine andere Wahl, als die Nutzung physischer Ressourcen zu optimieren.
Darüber hinaus wird die Optimierung von Ressourcen Unternehmen helfen, mehr von jedem Produkt zu profitieren, daher die Optimierung der Fabrikeingaben. Durch die Verfolgung des Ressourcenverbrauchs (hauptsächlich Strom- und Wasserverbrauch) verschiedener Maschinen und Produktionsprozesse können tiefes Lernen-Systeme dynamisch die besten Optimierungspraktiken vorschlagen.
Arzneimittelentdeckung
Die Arzneimittelentdeckung ist unglaublich zeitaufwändig und teuer. Tiefes Lernen kann diesen Prozess billiger und schneller machen. Tiefes Lernen kann helfen, die Bindungsaffinität von Medikamenten mit bestimmten Proteinen und sogar die toxischen Wirkungen bestimmter Verbindungen vorherzusagen.
AtomNet ist ein tiefes konvolutionales neuronales Netz, das für das rationale Arzneimitteldesign verwendet wird. Es ist eine hochmoderne Technologie, die in der Lage ist, neuartige und nicht offensichtliche Arzneimittelverbindungen zu finden und ein bemerkenswertes Werkzeug für beschleunigte Arzneimittel-Neupositionierungsprojekte sein kann. AtomNet wurde auch verwendet, um neue Kandidaten-Biomoleküle für Ebola und Multiple Sklerose (MS) vorherzusagen.
Gastgewerbe
Das Gastgewerbe ist eine milliardenschwere Branche, die immer bereit ist, neue Technologien zu übernehmen, und die Technologie des tiefen Lernens ist keine Ausnahme. Mit DL können Organisationen neue Mittel finden, um das Kundenerlebnis und die Zufriedenheit zu verbessern und sogar kostspielige, ersetzbare Prozesse zu identifizieren.
Tiefes Lernen kann Organisationen helfen, im Voraus zu planen, indem es saisonale Nachfragen vorhersagt. Ein tiefes Lernen-System kann mühelos die Korrelation zwischen Faktoren finden, die saisonale Nachfragen verursachen, und zukünftige Trends vorhersagen, indem es vergangene Daten analysiert.
Durch die Analyse von Kundendaten können DL-Modelle Unternehmen auch helfen, Kundenstrategien für bessere Bindungs- und Zufriedenheitsraten zu entwickeln. Unternehmen können auch verschiedene maschinelle Lerntechniken für wettbewerbsfähige Preisgestaltung verwenden, indem sie mehrere Faktoren wie Saisonalität, Echtzeitereignisse, Drittanbieteraktionen, lokale Ereignisse und vergangene Buchungsdaten berücksichtigen.
Finanzen
Da die Verarbeitung komplexer Big Data eine Spezialität des tiefen Lernens ist, hat es ein immenses Potenzial in der Finanzindustrie. Durch die Analyse historischer Daten, verschiedener Marktparameter und externer Faktoren, die die Leistung eines Unternehmens beeinflussen können, können tiefes Lernen-Algorithmen Aktienwerte mit beeindruckender Genauigkeit vorhersagen.
Da DL-Algorithmen in der Lage sind, große Datenmengen aus mehreren Quellen gleichzeitig zu analysieren, sind sie unglaublich schneller als Menschen und werden daher verwendet, um profitable Handelsstrategien zu erstellen.
Tiefe neuronale Netze werden auch im Kreditgenehmigungsprozess verwendet. Durch die Analyse historischer Daten zu Genehmigungen und Ablehnungen können Banken die Risiken einer Kreditvergabe an eine Entität richtig einschätzen.
Bildwiederherstellung
Die Bildwiederherstellung ist eine weitere beeindruckende Leistung, die tiefes Lernen vollbringen kann. Bildwiederherstellung bezieht sich im Allgemeinen auf die Wiederherstellung eines klaren, nicht degradierten Bildes aus einem degradierten Bild. Degradation kann aus einer Reihe von Faktoren resultieren, wobei Bildrauschen einer davon ist.
Wenn Bildrauschen der Übeltäter ist, wird der Wiederherstellungsprozess als Bildentrauschung bezeichnet. Ebenso können Bilder von niedrigerer Auflösung sein, und durch den Prozess der Superauflösung können Bilder mit höherer Auflösung erstellt werden.
Mit tiefem Lernen werden solche Wiederherstellungsprozesse genauer und weniger zeitaufwändig. Lernmethoden wie Deep Image Prior werden für den Wiederherstellungsprozess genutzt. Einfach ausgedrückt, ist Deep Image Prior ein konvolutionales neuronales Netz, das verwendet wird, um ein Bild ohne vorherige Trainingsdaten außer dem Bild selbst zu verbessern.
Im Jahr 2017 trainierten die Forscher des Google Brain-Teams ein tiefes neuronales Netz, um sehr niedrig aufgelöste Bilder von Gesichtern zu analysieren und die Gesichter vorherzusagen. Diese Methode wird als Pixel Recursive Super Resolution bezeichnet und kann die Auflösung von Bildern erheblich verbessern. Das neuronale Netz kann die unterscheidenden Merkmale einer Person mit Leichtigkeit identifizieren.
Tiefes Lernen wird auch extensiv verwendet, um Schwarz-Weiß-Fotos zu kolorieren. Sie können Online-Tools wie Algorithmia ausprobieren, um zu sehen, wie bestimmte Schwarz-Weiß-Bilder ausgesehen hätten, wenn sie mit einer Farbkamera aufgenommen worden wären.
Mobile Werbung
Tiefes Lernen ermöglicht es mobilen Werbetreibenden, Anzeigen zu veröffentlichen, die die Aufmerksamkeit ihrer Zielgruppe erregen und eine höhere Kapitalrendite (ROI) erzielen können. Tiefes Lernen-Techniken wie datengesteuerte prädiktive Werbung werden ebenfalls verwendet, um die Relevanz von Anzeigen zu erhöhen.
Zahlreiche mobile Echtzeit-Bidding-Werbenetzwerke verwenden tiefes Lernen-APIs, die Werbetreibenden helfen, die Klickrate (CTR) zu maximieren. Die schnelleren Reaktionszeiten von tiefen Lernen-Systemen ermöglichen es Werbetreibenden auch, die richtigen Anzeigen zur richtigen Zeit und am richtigen Ort zu schalten.
Entwicklung von Entwicklungsverzögerungen erkennen
Eine frühzeitige Diagnose und Behandlung von Entwicklungsstörungen, Autismus oder Sprachstörungen kann sich positiv auf die Zukunft eines Kindes auswirken. Ein Mensch würde zahlreiche frühe Anzeichen nicht bemerken, aber ein tiefes Lernen-System kann es sicherlich.
Mit tiefem Lernen haben Forscher am MIT's Computer Science and Artificial Intelligence Laboratory und am Massachusetts General Hospital's Institute of Health Professions ein Computersystem entwickelt, das Sprachstörungen erkennen kann, noch bevor ein Kind in den Kindergarten kommt.
Außerdem haben Kinder, die sich im Autismus-Spektrum befinden, Schwierigkeiten, die emotionalen Zustände der Menschen um sie herum zu erkennen. Zum Beispiel haben Kinder mit Autismus Schwierigkeiten, zwischen einem glücklichen und einem ängstlichen Gesicht zu unterscheiden.
Als Abhilfe für dieses Problem verwenden einige Ärzte tiefes Lernen-gestützte, kinderfreundliche Roboter, um Kinder dazu zu bringen, Emotionen zu imitieren und angemessen darauf zu reagieren. Während der Roboter interagiert, analysiert er das Interesse und das Engagement des Kindes, indem er auf ihre Reaktionen achtet.
Tiefes Lernen ermöglicht es dem Roboter, die wichtigsten Informationen aus den gesammelten Daten zu extrahieren, ohne dass menschliche Hilfe erforderlich ist. Mit Hilfe von DL haben Forscher zahlreiche faszinierende Fakten aufgedeckt, wie die kulturellen Unterschiede zwischen Kindern aus verschiedenen Ländern.
Sie beobachteten, dass Kinder aus Japan während Episoden hoher Beteiligung mehr Körperbewegungen zeigten. Andererseits wurden große Körperbewegungen bei Kindern aus Serbien mit Episoden der Disengagement in Verbindung gebracht.
Einer der größten Gründe, warum diese Art der Behandlung wirksam ist, ist, dass der Roboter darauf ausgelegt ist, die Aufmerksamkeit der Kinder zu erregen. Außerdem neigen Menschen dazu, ihre Ausdrücke häufig zu ändern und dieselbe Emotion auf unterschiedliche Weise auszudrücken. Aber der Roboter macht es immer auf die gleiche Weise, damit der Lernprozess für das Kind viel weniger frustrierend wird.
Tonvorhersage
Die Tonproduktion ist ein integraler Bestandteil der Filmproduktion. Obwohl bestimmte Geräusche wie Schritte, Klopfen an der Tür oder quietschende Reifen aus Stock-Audios entnommen werden können, müssen sie oft neu erstellt werden, um das filmische Erlebnis zu verbessern.
Forscher vom MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) haben einen tiefen Lernen-Algorithmus entwickelt, der Töne vorhersagt. Wenn ein stummer Videoclip eines Objekts, das getroffen wird, gegeben wird, kann der Algorithmus realistische Geräusche erzeugen. Der vorhergesagte Ton ist realistisch genug, um Menschen zu täuschen.
Um den Algorithmus zu trainieren, filmten die Forscher etwa 1.000 Videos von fast 46.000 Geräuschen, die verschiedene Objekte darstellen, die mit einem Drumstick getroffen, angestoßen und geschabt werden. Sie verwendeten speziell einen Drumstick, da er eine konsistente Methode zur Erzeugung eines Geräusches bot.
Tonvorhersagesysteme werden nicht nur die Dinge für die Filmindustrie verbessern, sondern könnten intelligenten Maschinen helfen, die Welt zu navigieren und die Eigenschaften von Objekten zu verstehen.
Visuelle Übersetzung
Haben Sie jemals versucht, Fremdsprachen mit der Google Translate-App zu übersetzen? Die App "übersetzt" nicht nur die Wörter, sondern überlagert das Bild mit der Übersetzung. Die App macht dies mit Hilfe von tiefen neuronalen Netzen und ist eine der vielen Möglichkeiten, wie Google tiefes Lernen in ein Smartphone integriert.
Sobald die App herausfindet, wo sich die Buchstaben im Bild befinden, indem sie seine Pixel analysiert, versucht ein konvolutionales neuronales Netz, das auf Buchstaben und Nicht-Buchstaben trainiert ist, zu erkennen, was jeder Buchstabe ist. Sobald die Buchstaben identifiziert sind, sucht die App in einem Wörterbuch nach Übersetzungen.
Die Übersetzung wird dann im gleichen Stil wie das Originalbild über die ursprünglichen Buchstaben gerendert. Solche visuellen Übersetzungen sind super schnell, wenn sie in den Rechenzentren von Google durchgeführt werden. Da jedoch die Mehrheit der Benutzer ein Low-End-Smartphone besitzt und instabile Internetverbindungen hat, entwickelte Google ein kleines neuronales Netz mit zahlreichen Einschränkungen.
Empfehlungssysteme
Tiefes Lernen-Algorithmen werden in Empfehlungssystemen verwendet, um Inhalte vorzuschlagen, die Benutzer wahrscheinlich ansehen werden. Die Effektivität dieser Algorithmen ist für Plattformen wie Netflix entscheidend, da nur wenn Benutzer häufig interessante Inhalte finden, sie das Abonnement fortsetzen. Amazon und zahlreiche andere E-Commerce-Plattformen verlassen sich ebenfalls stark auf tiefes Lernen-Algorithmen, um die richtigen Produkte zu empfehlen und den Umsatz zu steigern.
Betrugserkennung
Betrugsbedingte Verluste und Schäden sind eine traurige Realität der Finanzindustrie. Finanzbetrüger nehmen zu.
1,9 Milliarden Dollar
wurden 2019 durch Identitätsdiebstahl und Betrug verloren.
Quelle: Insurance Information Institute
Es kann jedoch zahlreiche Benutzerverhalten geben, die regelbasierte Systeme nicht als verdächtig identifizieren, aber DL-basierte Betrugserkennungssysteme sicherlich würden. Die Verarbeitungsgeschwindigkeit für DL-basierte Systeme ist ebenfalls bemerkenswert, und sie reduzieren auch den Bedarf an manueller Arbeit – im Gegensatz zu regelbasierten Systemen, die häufige menschliche Aufsicht und manuelle Korrekturen erfordern.
Wie man tiefe Lernmodelle erstellt und trainiert
Es gibt drei gängige Möglichkeiten, ein tiefes Lernmodell zu trainieren, um die Objektklassifizierung durchzuführen. Sie könnten es entweder von Grund auf neu trainieren, Transferlernen verwenden oder ein Netzwerk als Merkmalsextraktor verwenden. Schauen wir uns jede kurz an.
1. Training von Grund auf neu
Um tiefe neuronale Netze von Grund auf neu zu trainieren, müssen Sie große Mengen an beschrifteten Datensätzen erwerben – zum Beispiel die beschrifteten Bilder von Katzen und Hunden. Danach müssen Sie eine Netzwerkarchitektur entwerfen, die die unterschiedlichen Merkmale der Tiere lernen kann. Abhängig vom Datenvolumen, der Lernrate und der Rechenleistung kann das Training der Netzwerke Tage oder Wochen dauern.
2. Transferlernen-Ansatz
Der häufigste Weg, tiefe neuronale Netze zu trainieren, ist der Transferlernen-Ansatz. In diesem Prozess wird ein vortrainiertes Modell feinabgestimmt, um eine neue Aufgabe auszuführen. Sie können mit einem bestehenden Netzwerk beginnen und ihm neue Datensätze zuführen, die zuvor unbekannte Klassen enthalten.
Sie können das Netzwerk nach Ihren Anforderungen anpassen, in diesem Fall die Identifizierung und Unterscheidung zwischen den Bildern von Katzen und Hunden. Da dieser Prozess weniger Daten erfordert, sinkt die Rechenzeit erheblich.
3. Verwendung eines Merkmalsextraktors
Ein weiterer Ansatz, um ein tiefes Lernmodell zu trainieren, besteht darin, ein Netzwerk als Merkmalsextraktor zu verwenden. Da jede Schicht des Netzwerks darauf ausgelegt ist, spezifische Merkmale aus Bildern zu lernen, können Sie diese Merkmale während des Trainingsprozesses tatsächlich aus dem Netzwerk extrahieren. Diese Merkmale können dann in ein maschinelles Lernmodell eingegeben werden. Dadurch kann der Bedarf an enormen Rechenressourcen reduziert werden.
Tiefes Lernen: je mehr, desto besser
Eine interessante Eigenschaft des tiefen Lernens ist, dass es besser wird, wenn Sie mehr Daten und mehr Rechenressourcen bereitstellen. Obwohl tiefes Lernen-Algorithmen zu anspruchsvoll erscheinen mögen, sind sie in den meisten Fällen hochgenau und erfordern wenig bis keine menschliche Unterstützung.
Tiefes Lernen wird auch unser Schlüssel zur Entschlüsselung der allgemeinen künstlichen Intelligenz sein, eines KI-Systems, das in der Lage ist, wie Menschen zu denken, zu lernen und zu handeln.
Erfahren Sie mehr über allgemeine künstliche Intelligenz und sehen Sie selbst, ob eine solche intelligente Maschine ein Freund oder ein Feind wäre.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

