



Verbraucher möchten bequem auf Daten mit Geräten zugreifen, die sie lieben.
Sie schätzen Self-Service-Systeme, die eine ordnungsgemäße Governance und Sicherheit über Daten anwenden, während sie ihnen erlauben, über einen einzigen Einstiegspunkt darauf zuzugreifen und sie zu ändern. Sie sind oft zögerlich, sich an die IT-Abteilung zu wenden, die bestimmte Datentypen verwaltet, da dies zeitaufwändig sein kann.
Moderne Unternehmen speichern verschiedene Datensätze wie Big Data, soziale Medien, Web- oder IoT-Gerätedaten. Datenvirtualisierung ermöglicht Endbenutzern den Zugriff und die Änderung von Daten, die in isolierten, unterschiedlichen Systemen gespeichert sind, durch eine einzige Kundenansicht. Es hilft Kunden, entscheidungsrelevante Daten zusammenzuführen, um Analysen zu fördern und Unternehmen bei der strategischen und fundierten Entscheidungsfindung zu unterstützen.
Was ist Datenvirtualisierung?
Datenvirtualisierung ist ein Ansatz zur Datenverwaltung, der eine logische Extraktionsschicht erstellt. Es ermöglicht Benutzern den Zugriff und die Änderung unterschiedlicher Daten, ohne sich um technische Details kümmern zu müssen, wie z.B. wie die Daten an der Quelle formatiert sind oder wo sie gespeichert sind.
Datenvirtualisierung ermöglicht Benutzern den Zugriff auf alle Daten durch eine einzige Ansicht. Anstatt große Informationsblöcke zu verschieben, verwendet die Datenvirtualisierung Zeiger auf diese Blöcke, die einen kleineren Speicherbedarf erfordern und einen leistungsstarken Zugriff auf gespeicherte Daten bieten.
Datenvirtualisierung repliziert keine Daten oder speichert sie irgendwo. Sie hilft einem Benutzer, sich mit den benötigten Daten zu verbinden und liefert sie in Echtzeit. Sie ermöglicht es Unternehmen auch, eine Reihe von Analysen wie prädiktive, visuelle und Streaming-Analysen auf den neuesten Datenaktualisierungen anzuwenden. Sie hilft Unternehmen nicht nur, Sicherheit und Governance über isolierte Daten zu zentralisieren, sondern ermöglicht es ihnen auch, Daten in einer Weise bereitzustellen, die Verbraucher nutzen können.
Mit der großen Menge an Daten, die Unternehmen in verschiedenen Aspekten und Formaten sammeln, wird es schwieriger, sie zu verwalten. Einige Unternehmen haben Datenlager, um die Vielzahl von Informationen zu speichern, die sie erworben haben. Aber das Speichern unstrukturierter Daten, die von sozialen Medien, dem Web oder IoT-Geräten stammen, wird zu einer komplizierten Aufgabe.
Datenvirtualisierungssoftware bietet eine Lösung, um auf all diese Daten in einer Weise zuzugreifen, die Ihre Endbenutzer lieben. Da sich Verbraucheranwendungen weiterentwickeln, ermöglicht die Datenvirtualisierung Unternehmen, einen agilen Ansatz zur Datenverwaltung zu verfolgen.
Warum müssen Sie Daten virtualisieren?
In diesem wettbewerbsintensiven Geschäftsumfeld, in dem die Datenanforderungen im gleichen Maße steigen wie die Menge der gespeicherten Daten, ist es entscheidend, sie ordnungsgemäß zu verwalten und bei Bedarf zu nutzen. Da Organisationen verschiedene Arten von Daten ansammeln, ist die Aufgabe der Verwaltung über die Fähigkeiten traditioneller Datenintegration wie Extract Transform Load (ETL) Systeme oder Datenlager-Software hinausgegangen.
Ihre Agilität bestimmt, wie gut Sie sich an sich entwickelnde Markttrends in einem schnelllebigen Geschäftsumfeld anpassen können. Datenvirtualisierung ermöglicht es Unternehmen, schnell auf Produktionsqualitätsdaten zuzugreifen und sie zu nutzen, was ihnen hilft, agil mit ihren Entwicklungs-, Test-, Produktions- und Freigabezyklen zu sein.
Datenvisualisierung hilft Ihnen, über das traditionelle Ticketing-System hinauszuwachsen und erfordert nicht, dass Sie sich an einen Datenbankadministrator wenden, um Ihre Bedürfnisse zu erfüllen. Traditionell verließen sich IT-Unternehmen auf das Anforderungs-Erfüllungs-Modell, bei dem Entwickler und Tester in einer Warteschlange warten, da die Vorbereitung einer Testdatensicherung zeitaufwändig war.
Dies fügte Redundanzen im Anwendungsentwicklungszyklus hinzu und verlangsamte den Prozess. Da es viel Zeit in Anspruch nahm, Testdaten zu aktualisieren oder zu aktualisieren, waren Entwicklungs- oder QA-Teams gezwungen, mit veralteten Daten zu arbeiten, was zu datenbezogenen Fehlern in der Produktionsumgebung führte.
Datenvirtualisierung hilft Unternehmen, Redundanzen zu beseitigen und gleichzeitig bessere Geschäftsergebnisse zu liefern. Sie hilft Ihrem Unternehmen, kosteneffizienter und zeiteffizienter zu sein, indem sie eine einzige Ansicht gut konstruierter Daten bereitstellt, auf die Sie zugreifen, sie ändern und verwalten können.
Abgesehen von den oben genannten Faktoren gibt es viele Fähigkeiten der Datenvirtualisierung, die sie zu einem Muss für Unternehmen machen.
Fähigkeiten der Datenvirtualisierung umfassen:
- Rentabilität: Datenvirtualisierung bietet nahtlosen Zugriff auf die Längen und Breiten der Daten einer Organisation, was es Unternehmen ermöglicht, fundierte und profitable Entscheidungen zu treffen.
- Risikoreduzierung: Die aktuellen Informationen der Datenvirtualisierung helfen Unternehmen, die mit Compliance-Strafen verbundenen Risiken zu mindern. Sie spart auch Entwicklungszeit durch schnelle Iteration und minimiert das Projektrisiko.
- Effizienz: Datenvirtualisierung verbessert die Nutzung von Server- und Speicherressourcen. Sie repliziert keine Daten, was mehr bei der Governance und Hardware spart.
- Beschleunigung der Lösungszeit: Datenvirtualisierungsprojekte werden schneller abgeschlossen und kommen dem Unternehmen schneller zugute. Dies ist auch ein Vorteil niedrigerer Projektkosten.
- Produktivität: Datenvirtualisierung ist einfach zu bedienen und ermöglicht es Datenengineering-Teams, mehr in weniger Zeit zu tun.
- Skalierbarkeit: Datenvirtualisierung stellt leichte Datenbankkopien in Minuten über eine Benutzeroberfläche oder API bereit, was Ihnen ermöglicht, die agile Entwicklung zu skalieren.
- Daten-Governance: Datenvirtualisierung implementiert Zugriffskontrollen darüber, welche Daten für wen zugänglich sein sollten, was sie zu einem vorteilhaften Sicherheitsasset macht.
Möchten Sie mehr über Datenvirtualisierungssoftware erfahren? Erkunden Sie Datenvirtualisierung Produkte.
Wie funktioniert Datenvirtualisierung?
Datenvirtualisierung ermöglicht es Unternehmen, schnell auf die benötigten Daten zuzugreifen. Zuerst müssen Sie ein Datenvirtualisierungs-Middleware für Ihr Unternehmen wählen, das einfach zu bedienen und skalierbar über Ihre On-Premise-, Cloud- oder Hybrid-Infrastruktur ist. Datenvirtualisierungssoftware ermöglicht es Ihrem Datenengineering-Team, saubere und prägnante Datenansichten mit reichhaltigen Analyse-, Design- und Entwicklungsfunktionen zu entwerfen.
Als nächstes können Ihre Datenanalysebenutzer die Geschäftsansichten, die sie benötigen, durch Datenkataloge oder Anwendungsprogrammierschnittstellen (API) Managementsysteme finden. Jedes Mal, wenn die Benutzer einen Bericht ausführen oder ein Dashboard aktualisieren, greift die Datenvirtualisierung in Echtzeit auf Informationen zu, führt Transformationen durch und liefert sie an den Benutzer.
Darüber hinaus helfen ihre Sicherheits- und Governance-Funktionen sicherzustellen, dass Unternehmen ihre Service-, Sicherheits- und Datenschutz-Service-Level-Agreements (SLAs) einhalten und den Branchenvorschriften entsprechen.
Datenvirtualisierung vs. Datenföderation vs. Data Lake
Datenvirtualisierung und Datenföderation werden manchmal austauschbar verwendet. Datenföderation ist eine Art der Datenvirtualisierung. Beide integrieren Daten und vereinfachen den Zugriff für Front-End-Anwendungen.
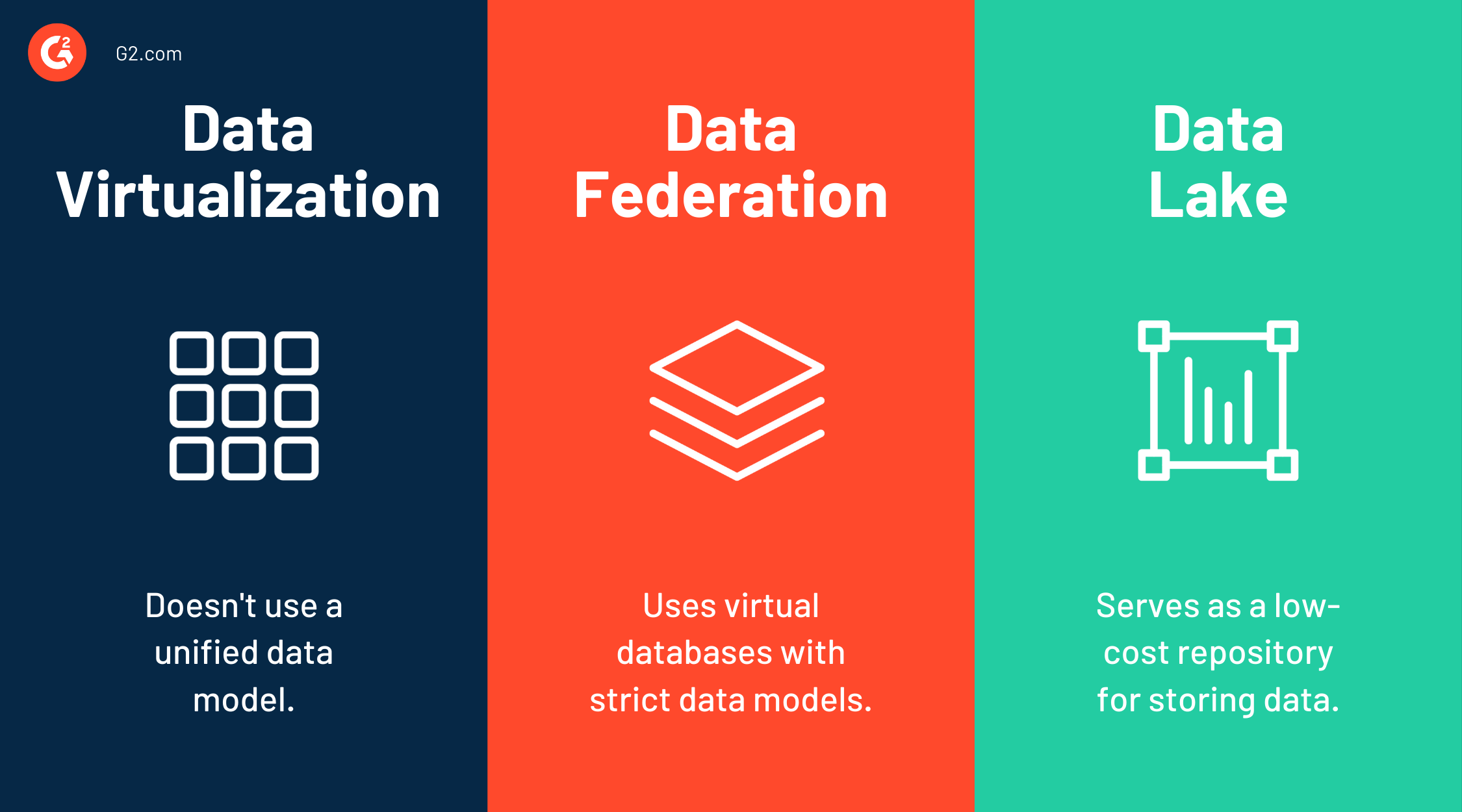
Datenföderation ist ein Ansatz, der virtuelle Datenbanken mit strengen Datenmodellen verwendet. Es ermöglicht Benutzern den Zugriff auf verteilte Datentypen und -modelle über eine einzige Schnittstelle und erlaubt es mehreren Datenbanken, als eine zu funktionieren. Die virtuelle Datenbank nimmt Daten aus verschiedenen Quellen und konvertiert sie in ein gemeinsames Modell.
Data Lakes dienen als kostengünstige Repositories zur Speicherung großer Mengen strukturierter oder unstrukturierter Daten. Es ist die bevorzugte Wahl großer Entwicklungsteams, die mit Open-Source-Tools arbeiten und eine kostengünstige Datenanalysesandbox benötigen.
Im Gegensatz dazu bietet die Datenvirtualisierung eine Schnittstelle, um auf verschiedene Datenmodelle zuzugreifen, ohne einem strengen Datenmodell zu folgen. Sie integriert alle Unternehmensdaten, die über unterschiedliche Systeme isoliert sind, implementiert zentrale Sicherheit und Governance mit einheitlichen Daten und liefert sie in Echtzeit an die Benutzer.
Anwendungsfälle der Datenvirtualisierung
Datenvirtualisierung beinhaltet die Einführung einer Schicht zwischen unterschiedlichen Datenquellen und Verbrauchern. Sie hat mehrere Anwendungsfälle in der Industrie.
Datenintegration
Datenintegration ist vielleicht der häufigste Anwendungsfall der Datenvirtualisierung. Viele Unternehmen arbeiten mit unterschiedlichen, isolierten Datenquellen wie Big Data, Cloud-Daten und sozialen Medien.
Da diese Datentypen in verschiedenen Formaten vorliegen, erleichtert die Datenvirtualisierung es den Verbrauchern, sich mit einem bestimmten Typ zu verbinden, den sie benötigen, ohne sich um dessen Format oder Speicherort kümmern zu müssen.
DevOps
In Anwendungsentwicklungsprozessen automatisieren Teams hauptsächlich alles außer Daten, um app-gesteuerte Kundenerfahrungen zu transformieren. Datenvirtualisierung hilft solchen Teams, Produktionsqualitätsdaten nahtlos zu verbinden, darauf zuzugreifen und zu nutzen.
Sie hilft DevOps-Teams, die Engpässe in der Datenbereitstellung zu beseitigen und die Ressourcen zu reduzieren, die erforderlich sind, um Daten für Entwickler und Tester zu berechnen und zu erstellen.
ERP-Upgrades
Die meisten Enterprise-Resource-Planning-Projekte werden aufgrund des langsamen und komplexen Prozesses der Aktualisierung von Projektumgebungen gestoppt. Datenvirtualisierungstools können ERP-Teams effizienter als herkömmliche Prozesse arbeiten lassen, indem sie Komplexitäten reduzieren, die Gesamtbetriebskosten (TCO) senken und Projekte beschleunigen, indem sie virtuelle Kopien von Daten bereitstellen.
Analysen, Berichterstattung und Sicherung
Für Business-Intelligence-Projekte, die Integration erfordern, kann die Datenvirtualisierung einen bedarfsgerechten Datenzugriff bieten. Virtuelle Datenkopien können eine Sandbox für destruktive Abfrage- und Berichtsentwürfe bereitstellen.
Wenn Ihre Teams auf ein Produktionsproblem stoßen, können sie die genaue Ursache mit der Möglichkeit identifizieren, virtuelle Datenumgebungen bereitzustellen. Es hilft auch bei der Validierung, dass Änderungen keine unvorhergesehenen Probleme verursachen.
Big Data und prädiktive Analysen
Big Data und prädiktive Analysen basieren auf Daten aus heterogenen Quellen. Es ist nicht so einfach, Daten aus einer Datenbank zu ziehen. Big Data stammt aus verschiedenen Quellen wie sozialen Medien, Mobiltelefonen, E-Mails und anderen Ursprüngen.
Datenvirtualisierung erleichtert es einem Benutzer, auf verschiedene Datensätze von einer einzigen Plattform aus zuzugreifen und sie für Analysen zu verwenden.
Top 5 Datenvirtualisierungssoftware
Datenvirtualisierungssoftware ermöglicht es Organisationen, sich an agile Datenlagerungs-, Abruf- und Integrationsprozesse anzupassen, indem sie virtuelle Datenschichten verwenden.
Um in die Liste der Datenvirtualisierungssoftware aufgenommen zu werden, muss ein Produkt:
- Eine virtualisierte Schicht verwenden, um Daten zu abstrahieren
- Datenintegration zwischen Daten aus unterschiedlichen Quellen ermöglichen
- Datenabruf und -manipulation erlauben
*Unten sind die fünf führenden Datenvirtualisierungssoftware aus dem G2 Summer 2021 Grid® Report. Einige Bewertungen können zur Klarheit bearbeitet sein.
1. SAP HANA
SAP HANA bietet Datenvirtualisierungslösungen, die Benutzern helfen, Operationen auf Daten in Echtzeit durchzuführen. Es bietet eine einzige Plattform für alle Prozesse, was letztendlich die Hardwarekosten, den manuellen Aufwand und die Zeit reduziert.
Was Benutzer mögen:
„Ich benutze SAP HANA in meinem Büro seit zwei Jahren. Als Automatisierungsentwickler liebe ich die Funktion, Skripte im Textformat aufzuzeichnen, wo es die Feld-ID, Tabellen-ID und Fenster-IDs abruft und mir erlaubt, sie in meinem VB-Skript, UiPath-Automatisierung, Makros zu verwenden.
Verschiedene Umgebungen wie Q40, S40, D40, PRD helfen mir, sowohl Produktion als auch Tests zu handhaben. Wann immer wir ein Problem in der Produktion haben, erlaubt mir meine Q40-Verbindung, eine Replik davon zu erstellen und es zu handhaben. Auch liebe ich die T-Code-Funktionalitäten: FB70, FB60, BP, F-28, F-30, MIRO sind meine persönlichen Favoriten.“
- SAP HANA Review, Debasis N.
Was Benutzer nicht mögen:
„Es gibt viele Lizenzierungsoptionen für verschiedene Anwendungsfälle, aber die meisten kleinen Unternehmen können sich SAP HANA immer noch nicht leisten, da es sehr teuer ist.
Es funktioniert nicht mit einem anderen Betriebssystem als der Linux-Umgebung. Auch die Dokumentation, die die Funktionalität von SAP HANA beschreibt, sollte verbessert und bereitgestellt werden. Es verbraucht viel RAM und CPU-Leistung, was zu Verzögerungen und Abstürzen auf dem Gerät des Benutzers führt.“
- SAP HANA Review, Dr. Ravindra P.
2. PowerCenter
Informatica PowerCenter bietet eine End-to-End-Datenintegrationsplattform, die Fähigkeiten zur Integration von rohen, fragmentierten Daten aus unterschiedlichen Quellen umfasst. Es hilft Unternehmen, rohe Daten in vollständige, qualitativ hochwertige, geschäftsbereite Informationen zu verwandeln.
Was Benutzer mögen:
„Informatica PowerCenter ist eine innovative Software, die mit ETL-Datenintegration arbeitet. Dieses leistungsstarke Tool erleichtert die Datenmigration und die Integration verschiedener Datenbanken wie SQL Server und Oracle. All dies unter einer intuitiven und einfachen Benutzeroberfläche. Sein Support-System ist sehr effizient und löst Fehler, die in wenigen Minuten auftreten.“
- PowerCenter Review, Leah S.
Was Benutzer nicht mögen:
„Die Benutzeroberfläche kann verbessert werden. Sie können an dem Visualisierungsteil arbeiten, um es benutzerfreundlicher zu machen. Ein weiterer Aspekt, den ich erwähnen möchte, ist, dass, wenn ich daran arbeite, manchmal Daten für einige Zeit aufgrund von Synchronisierungsproblemen verloren gehen, die behoben werden können.“
- PowerCenter Review, Soumyadip R.
3. Denodo
Denodo bietet unternehmensgerechte Datenvirtualisierung mit einer benutzerfreundlichen Oberfläche, die Unternehmen hilft, komplexe Geschäftsoperationen durchzuführen, einschließlich Lieferantenmanagement, regulatorische Compliance, Daten-als-Service, Systemmodernisierung und mehr.
Was Benutzer mögen:
„Denodo ist einfach zu bedienen und ermöglicht es mir, einen REST-Webdienst in weniger als 30 Minuten ohne viel Code zu entwickeln, und ich erhalte oft gutes Feedback von Kunden. Sie können mit ihren Tests fortfahren und es am selben Tag oder innerhalb weniger Tage in die Produktion einführen!“
- Denodo Review, Chevon T.
Was Benutzer nicht mögen:
„Beim Umgang mit großen Datenmengen haben wir einige Leistungsprobleme festgestellt, aber das ist kein großes Hindernis, da wir nicht täglich 5-10 Jahre historische Lasten verarbeiten.“
- Denodo Review, Bibhu D.
4. AWS Glue
AWS Glue ist ein serverloser Datenintegrationsdienst, der es einfach macht, Daten für Analysen, maschinelles Lernen und Anwendungsentwicklung zu entdecken, vorzubereiten und zu kombinieren. AWS Glue bietet alle erforderlichen Funktionen für die Datenintegration, sodass Sie Ihre Daten in Minuten statt Monaten analysieren und nutzen können.
Was Benutzer mögen:
„Das Nützlichste an AWS Glue ist, dass es die Daten in das Parquet-Format aus dem Rohdatenformat konvertiert, was bei anderen ETL-Tools nicht vorhanden ist. Es kann eine große Menge an Daten in das Parquet-Format konvertieren und sie bei Bedarf abrufen.“
- AWS Glue Review, Anudeep M.
Was Benutzer nicht mögen:
„Es kann teuer sein, abhängig von der Nutzung und dem, was Sie damit vorhaben.“
- AWS Glue Review, Danny S.
5. Oracle Virtualization
Oracle VM ist für Effizienz konzipiert und für Leistung optimiert, um eine Vielzahl von Linux-, Windows- und Oracle Solaris-Workloads zu unterstützen. Die Virtualisierungssoftware wird von einer langen Liste von Partnern in jeder Branche unterstützt.
Was Benutzer mögen:
„Oracle Virtualization ist seit langem mein Lieblingstool zum Verwalten, Bearbeiten und Erstellen von virtuellen Maschinen. Die Benutzeroberfläche ist intuitiv, und es ist möglich, die verfügbaren Ressourcen für jede virtuelle Maschine im Detail zu konfigurieren. Ich hatte nie ernsthafte Probleme beim Ausführen der virtuellen Maschinen. Es ist ein ausgezeichnetes Tool, um Funktionen und Konfigurationen zu testen, bevor sie auf physische Geräte angewendet werden.
Die Software hat interessante Funktionen, wie die Möglichkeit, dass virtuelle Maschinen echte angeschlossene Peripheriegeräte erkennen, zusätzlich zu grafischen Konfigurationen. Es ist ein grundlegendes Tool für jeden IT-Experten.“
- Oracle Virtualization Review, Rafael C.
Was Benutzer nicht mögen:
„Die Exportfunktion ist nicht gut und war anfangs ziemlich verwirrend. Ich war verwirrt über den unterstützten Dateityp.
Die Dokumentation ist auf der Website ziemlich lang. Ich habe viele YouTube-Videos über die Nutzung seiner Funktionen angesehen.“
- Oracle Virtualization Review, Niyati M.
Treffen Sie eine kluge Wahl
Datenvirtualisierung ist eine fantastische Lösung, wenn es darum geht, mit Daten zu arbeiten, die in unterschiedlichen Systemen gespeichert sind. Sie macht einen guten Geschäftsvorfall, wenn Sie benutzerfreundliche und gut konstruierte Datenansichten für Ihre Benutzer benötigen. Da sich die Anforderungen der Kunden weiterentwickeln, kann die IT schnell ein neues Datenset durch Datenvirtualisierung bereitstellen und iterieren.
Wenn Sie aktuelle Informationen benötigen oder Daten aus mehreren Quellen föderieren müssen, kann Ihnen die Datenvirtualisierung helfen, schnell darauf zuzugreifen und sie jedes Mal frisch zu servieren.
Aber Datenvirtualisierung ist nicht die Antwort auf jede Datenanalyseanforderung. Abhängig vom Anwendungsfall ist manchmal ein konsolidiertes Datenlager mit einem ETL eine bessere Lösung - oder sogar eine Hybridlösung aus beidem.
Wenn Datenlager besser zu Ihrem Zweck passen, entdecken Sie die beste Datenlager-Software, um Daten zu verarbeiten, zu transformieren und zu ingestieren, um Ihre Entscheidungsfindung zu unterstützen.

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.

