



Jede Sekunde des Tages greift die Welt auf Daten zu, verändert sie und verlässt sich auf sie.
Tägliche Funktionen wie der Kauf eines Zugtickets oder das Mittagessen mit Kollegen beinhalten die Verarbeitung von Daten. Organisationen und Einzelpersonen benötigen Daten, um Geschäfte zu führen, egal ob sie aus 30 oder 3.000 Personen bestehen. Daten sind wirklich in allem, was wir tun, und sie folgen uns überall hin.
Genau deshalb ist der Schutz Ihrer Daten so wichtig. Ein einfaches Backup Ihrer Geschäftsdaten kann Sie vor der Bedrohung durch potenzielle Hacker, dem versehentlichen Herunterladen eines Virus und sogar vor Naturkatastrophen bewahren.
Es gibt Dutzende von Möglichkeiten, Ihre Daten vor Kompromittierung zu schützen. Eine dieser Methoden ist die Datenreplikation.
Was ist Datenreplikation?
Datenreplikation ist der Prozess, Ihre Daten an mehr als einem Ort zu speichern. Der Prozess erstellt mehrere Kopien einer Datenbank, um sie besser vor einem Datenverlustereignis zu schützen. Datenreplikation als Prozess ist am nützlichsten, um die Zugänglichkeit von Daten zu verbessern. Alle Benutzer, denen Zugriff gewährt wird, können genau dieselben Daten teilen, egal wo sie sich auf der Welt befinden.
Geschäftsdaten ändern sich hunderte, manchmal tausende Male an einem einzigen Tag. Viele Organisationen bevorzugen die Datenreplikation, weil sie das Teilen von Daten über Büros und Kontinente hinweg so bequem macht. In diesem Artikel werden wir darauf eingehen, wie es funktioniert, verschiedene Typen und Methoden sowie die Vorteile und Herausforderungen, die mit jedem einhergehen.
Warum Datenreplikation verwenden?
Datenreplikation ist eine verlockende Backup-Methode aus zwei Hauptgründen: ihrer Sicherheit und ihrer schnellen Bequemlichkeit. Die Methode hilft Organisationen, mehrere aktuelle Kopien ihrer Daten zu pflegen und sie an Datenzentren in der Nähe von entfernten Büros zu verteilen.
Mehr als eine Kopie zu behalten, erhöht die Sicherheit der Daten im Falle einer Katastrophe. Wenn eine Kopie beschädigt wird, existiert eine andere exakte Version anderswo.
Machen Sie keinen Fehler, Datenreplikation ist keine statische Kopie Ihrer Daten. Ähnlich wie bei kontinuierlichem Datenschutz verarbeitet die Datenreplikation Ihre Daten kontinuierlich, sodass jede Kopie, egal wo sie sich befindet, immer genau und aktualisiert ist, um ihre ursprüngliche Quelle zu spiegeln.
Das Endergebnis ist eine Fülle von Datenkopien an verschiedenen Orten, auf die Benutzer zugreifen können, ohne sich Sorgen machen zu müssen, die Daten ihrer Kollegen zu beschädigen.
Da die Datenreplikation mehrere Datenstandorte verwaltet, kann sie auch Benutzern helfen, viel schneller auf Daten zuzugreifen. Es kann besonders nützlich sein, wenn eine Organisation eine beträchtliche Anzahl internationaler Büros hat.
Angenommen, Sie arbeiten in Asien, aber der Hauptsitz Ihres Unternehmens und die ursprüngliche Datenquelle befinden sich in Nordamerika. Sie könnten Datenlatenz erleben, wenn Sie auf Daten von einem Datenzentrum zugreifen, das Tausende von Meilen entfernt ist. Durch die Verwendung von Datenreplikation, um eine weitere Replik näher an internationale Benutzer zu bringen, sparen Sie ihnen Zeit und Frustration.
Die Replikation von Daten wird auch dazu beitragen, die Serverleistung zu verbessern. Wenn Ihre Organisation mehrere Kopien von Daten auf mehreren Datenservern betreibt, können alle Benutzer viel schneller auf Daten zugreifen. Außerdem können Sie, indem Sie alle Leseoperationen auf eine Replik des Originals speichern, Verarbeitungszyklen auf dem primären Server für wichtigere Schreiboperationen sparen.
Einer der häufigsten Verwendungszwecke der Datenreplikation ist die Notfallwiederherstellung. Ähnlich wie bei kontinuierlichem Datenschutz stellt die Datenreplikation sicher, dass immer ein aktuelles Backup existiert, falls es zu einem Hardwarefehler, physischen Schaden oder einem Systembruch kommt, der Ihre Daten gefährdet.
Notfallwiederherstellungssoftware hilft Unternehmen, Software, Einstellungen und Daten schnell und effizient in einen Zustand wie zuvor wiederherzustellen, falls ein Computer-, Server- oder Infrastrukturfehler auftritt. Entdecken Sie eine unvoreingenommene Liste der heutigen Top-Tools auf G2 im obigen Link.
Möchten Sie mehr über Datenreplikation Software erfahren? Erkunden Sie Datenreplikation Produkte.
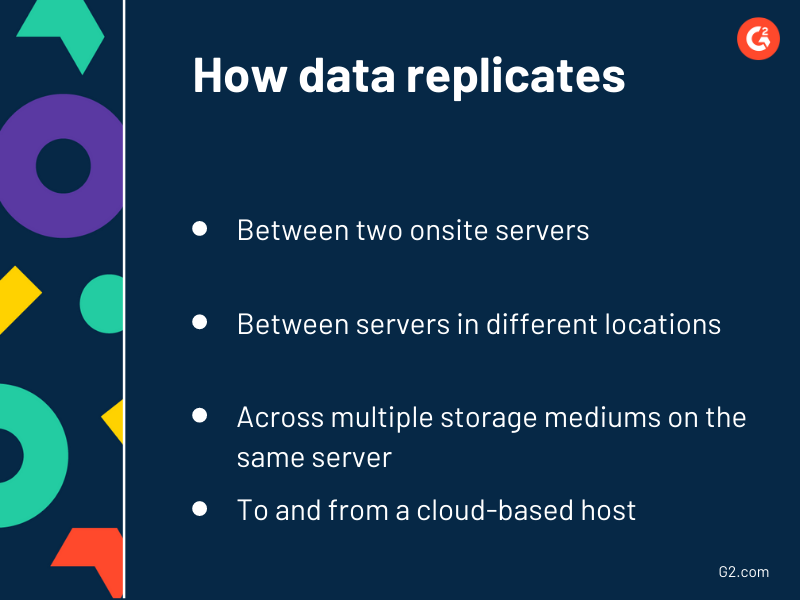
Wie funktioniert Datenreplikation?
Datenreplikation beinhaltet das Kopieren von Daten von einem Ort und das Erstellen einer weiteren exakten Kopie an einem anderen Ort. Zum Beispiel können Daten zwischen zwei lokalen Servern, zwischen Servern an verschiedenen Standorten, über mehrere Speichermedien auf demselben Server und zu und von einem cloudbasierten Host repliziert werden.
Sie haben die Möglichkeit, Daten sofort zu kopieren, sie in großen oder kleinen Chargen zu übertragen, einen Zeitplan festzulegen, wann Sie Daten verschieben möchten, und Daten in Echtzeit zu replizieren, wenn die Daten des Master-Servers geschrieben, geändert oder vollständig gelöscht werden.
Zusätzlich können Sie eine vollständige Replikation verwenden, bei der eine vollständige Datenbank an jeden Serverstandort kopiert wird, oder eine partielle Replikation, bei der nur einige der am häufigsten verwendeten Daten über Server repliziert werden. Wir werden später mehr über diese Arten der Replikation sprechen.
Hinweis: Die Replikation von Daten kann über ein lokales Netzwerk, ein Speichernetzwerk, ein lokales Weitverkehrsnetzwerk oder über die Cloud erfolgen.
Der Datenreplikationsprozess
Die Nutzung der Datenreplikation wird nur dann nützlich sein, wenn exakte Kopien Ihrer Daten auf allen Servern gespeichert sind. Das ist der ganze Punkt der Backup-Methode. Genau wie bei jeder anderen Methode wird das Festhalten an einem Replikationsprozess Ihnen helfen, Daten an jedem Standort sicher und konsistent zu halten.
Der Prozess würde mehr oder weniger diese Schritte umfassen:
- Identifizieren Sie Ihre Datenquelle und wo Sie sie replizieren möchten.
- Wählen Sie die Dateien, Ordner und Anwendungen aus, die Sie von der Quelle kopieren möchten.
- Planen Sie Ihren Backup-Zeitplan und wie häufig Sie Backups durchführen möchten.
- Entscheiden Sie, ob Sie eine vollständige Tabellen-, schlüsselbasierte oder logbasierte Replikation verwenden möchten.
- Wenn Sie eine schlüsselbasierte Replikation verwenden, identifizieren Sie Replikationsschlüssel (Spalten, die, wenn sie in der Quelle geändert werden, die Datensätze, zu denen sie gehören, im Prozess kopieren).
- Verwenden Sie ein Replikationstool oder schreiben Sie benutzerdefinierten Code, um den Replikationsprozess zu starten.
- Behalten Sie den Backup-Prozess im Auge, um sicherzustellen, dass alles korrekt gesichert wird.
Vorteile der Datenreplikation
Einige der offensichtlicheren Vorteile der Datenreplikation umfassen ihre Rolle bei der Notfallwiederherstellung und den einfachen Zugriff auf wichtige Geschäftsdaten und Anwendungen. Im Falle einer Katastrophe oder eines Schadens an der primären Quelle wird eine replizierte Kopie der Daten vorhanden sein, um Arbeitsabläufe normal weiterlaufen zu lassen.
Da Daten an mehreren Standorten und auf mehreren Servern existieren, hilft die Datenreplikation, das Teilen von Daten in großem Maßstab zu erleichtern. Sie verteilt auch die Belastung des Netzwerkverkehrs auf jede Datenserver-Site.
Einige zusätzliche Vorteile, die Organisationen bei der Verwendung von Datenreplikation erwarten können, sind:
- Datenreplikation hält Ihre Daten konsistent und immer auf dem neuesten Stand, egal von wo aus Benutzer versuchen, darauf zuzugreifen.
- Sie können mit einer erhöhten Datenverfügbarkeit rechnen. Wenn ein System ausfällt, angegriffen wird oder beschädigt wird, können Sie auf Ihre Daten von einem anderen Standort aus zugreifen.
- Die Implementierung der Datenreplikation kann potenziell die Arbeit der IT-Abteilung minimieren, indem sie die Datenreplikationstransaktionen der Organisation erstellt und pflegt.
- Sie werden eine verbesserte Gesamtleistung des Netzwerks feststellen, wenn Sie Datenreplikation verwenden. Indem Sie Ihre Daten an mehreren Standorten speichern (insbesondere wenn Ihre Organisation internationale Büros hat), werden Ihre Mitarbeiter nicht so viel Datenzugriffslatenz erleben. Da die Daten in ihrer Nähe gespeichert sind, werden sie schneller geladen.
- Sie werden eine Verbesserung der Testsystemleistung feststellen. Datenreplikationstools können die Synchronisation und Verteilung von Daten für Testsysteme viel schneller und einfacher machen.
- Datenreplikation kann die Unterstützung der Datenanalyse erhöhen. Das Kopieren von Daten in ein Data Warehouse gibt den Analyseteams die Unterstützung, um an Business-Intelligence-Projekten zu arbeiten.
Business-Intelligence-Plattformen ermöglichen es Unternehmen, Daten zu analysieren und umsetzbare Erkenntnisse zu gewinnen, die helfen können, die Entscheidungsfindung zu verbessern und die Strategie zu informieren. BI-Plattformen verbinden sich mit Datenbanken, Data Warehouses oder Big-Data-Verteilungen und bieten Analysten die Möglichkeit, mit Daten zu experimentieren, um Erkenntnisse zu entdecken.
Nachteile der Datenreplikation
Wir haben gesehen, dass die Datenreplikation eine gute Anzahl von Vorteilen hat, aber Organisationen sollten immer die Nachteile bewerten, denen sie bei der Implementierung eines neuen Tools begegnen könnten. Eine der häufigsten Herausforderungen bei der Datenreplikation kann von Datenverzögerungen oder Dienstunterbrechungen während der Datenübertragung oder -sicherung herrühren.
Zusätzlich kann der Prozess der Datenreplikation umso belastender werden, je größer die Entfernung zwischen den replizierten Datensystemen und der Originalkopie ist.
Einige zusätzliche Nachteile, die Organisationen bei der Verwendung von Datenreplikation erwarten können, sind:
- Alle Daten aktuell zu halten, kann eine Herausforderung sein. Je mehr Standorte Sie Ihre Daten speichern, desto mehr müssen Sie komplexe Systeme implementieren, um den Überblick zu behalten, was was ist.
- Sie benötigen mehr Speicherplatz, da Ihre Daten weiter wachsen. Dieser Platz kann Ihnen einen guten Teil Ihres Team-Budgets kosten.
Wenn es darauf ankommt, drehen sich die Kernherausforderungen, denen Sie bei der Verwendung von Datenreplikation begegnen werden, alle um begrenzte Ressourcen.
- Wenn Sie Datenreplikationstools verwenden, kann das Halten einer Anzahl von Replikaten an einigen, vielleicht sogar einem Dutzend Standorten dazu führen, dass Ihre Organisation mehr Geld für höhere Prozessor- und Speicherkosten ausgibt.
- Jemand muss für den Backup-Prozess verantwortlich sein. Die Implementierung der Datenreplikation in den Backup-Prozess einer Organisation erfordert Zeit für das engagierte Team, um es zu perfektionieren.
- Alle Datenkopien konsistent zu halten, erfordert eine Überarbeitung der Verfahren und erhöht den Netzwerkverkehr, was potenziell die Arbeit verlangsamt.
Arten der Replikation
Wenn es um Replikation geht, gibt es drei Haupttypen, aus denen Sie wählen können, jeder mit unterschiedlichen Vorteilen. Sicherzustellen, dass Sie wissen, welcher am besten für Ihre Organisation geeignet ist, ist ein guter Start zur Nutzung von Datenreplikationstools.
1. Transaktionale Replikation
Bei der Verwendung von transaktionaler Replikation erhalten Sie eine vollständige Kopie Ihrer Datenbank und werden kontinuierlich über Änderungen Ihrer Daten informiert. Dies macht es einfach, den Überblick darüber zu behalten, was geändert wurde und ob Daten verloren gegangen sind.
Transaktionale Konsistenz ist mit dieser Art der Replikation garantiert. Daten werden in Echtzeit repliziert und vom Herausgeber (dem primären Server) an die Abonnenten (sekundäre Server) in genau der Reihenfolge gesendet, in der sie auftreten.
Transaktionale Replikation kopiert nicht nur Ihre Datenänderungen, sie repliziert kontinuierlich jede einzelne Änderung mit großer Genauigkeit. Normalerweise wird dieser Typ in Server-zu-Server-Umgebungen verwendet.
2. Snapshot-Replikation
Snapshot-Replikation ist, wenn ein Schnappschuss der Datenbank gemacht und über Server verteilt wird. Daten werden genau so gesendet, wie sie in einem bestimmten Moment erscheinen (zum Zeitpunkt des Schnappschusses). Dieser Typ macht keine Notiz von Aktualisierungen der Daten; vielmehr sendet er den Abonnenten (sekundären Servern) eine Gesamtansicht der Daten in einem Augenblick.
Typischerweise wird die Snapshot-Replikation verwendet, wenn Änderungen an Daten spärlich sind. Diese Replikationsart ist großartig, wenn die anfängliche Synchronisation zwischen Herausgeber und Abonnent durchgeführt wird, neigt jedoch dazu, etwas langsamer zu sein. Dies liegt daran, dass jeder gesendete Schnappschuss versucht, mehrere Datensätze von einem Ende zum anderen zu verschieben.
3. Merge-Replikation
Diese Art der Replikation tritt auf, wenn zwei oder mehr Datenbanken zu einer einzigen Datenbank zusammengeführt werden. Merge-Replikation ermöglicht es, dass alle Änderungen an Daten vom Herausgeber (primärer Server) an einen oder mehrere Abonnenten (sekundäre Server) gesendet werden.
Diese Replikationsart ist die komplexeste, da sie sowohl dem Herausgeber als auch den Abonnenten erlaubt, Änderungen an der Datenbank vorzunehmen. Sie wird typischerweise in einer Server-zu-Client-Umgebung verwendet.
Datenreplikationstechniken
Früher haben wir die drei Datenreplikationstechniken erwähnt: schlüsselbasierte inkrementelle, vollständige Tabellen- und logbasierte inkrementelle. Wenn es um Datenbankreplikation geht, müssen Sie den Unterschied zwischen den drei Methoden kennen, um vollständig zu verstehen, wie Datenreplikation funktioniert.
1. Vollständige Tabellenreplikation
Die vollständige Tabellenreplikation kopiert jedes Datenstück von der ursprünglichen Quelle zum Ziel. Dies schließt alle neuen, bestehenden und aktualisierten Daten ein.
Der größte Nachteil dieser Technik ist, dass sie mehr Rechenleistung erfordert und zu einer stärkeren Belastung des Netzwerkverkehrs führt. Da sie jedes Mal alle Daten kopiert, kann dies sie langsamer machen als andere Techniken. Die Kosten für das Backup werden steigen, wenn Ihre Daten weiter wachsen.
Diese Technik ist am nützlichsten, wenn Daten regelmäßig von der Quelle gelöscht werden oder wenn die Quelle keine geeignete Spalte für andere Techniken hat.
2. Schlüsselbasierte inkrementelle Replikation
Die schlüsselbasierte inkrementelle Replikation aktualisiert nur die Daten, die seit dem letzten Update geändert wurden. Da bei diesen Updates zunehmend weniger Daten kopiert werden, ist diese Datenreplikationstechnik effizienter als die vollständige Tabellenreplikation.
Der Hauptnachteil der schlüsselbasierten inkrementellen Replikation ist ihr Versagen, bereits gelöschte Daten zu replizieren (da die Daten gelöscht werden, sobald das Original gelöscht wird).
Hinweis: Schlüsselbasierte inkrementelle Replikation wird auch als schlüsselbasierte inkrementelle Datenerfassung und schlüsselbasierte inkrementelle Ladung bezeichnet.
3. Logbasierte inkrementelle Replikation
Die logbasierte inkrementelle Replikation ist eine einzigartige Technik. Sie funktioniert nur für Datenbankquellen und repliziert Daten basierend auf Informationen aus der Datenbank-Logdatei (eine Datei, die Änderungen an der Datenbank aufzeichnet). Logbasiert ist die effizienteste der drei Techniken, muss jedoch von der Quelldatenbank unterstützt werden.
Diese Replikationstechnik wird am besten für Sie geeignet sein, wenn Ihre Quelldatenbankstruktur relativ statisch ist. Wenn sich Datentypen ändern oder Spalten entfernt werden, muss die gesamte Konfiguration des logbasierten Systems aktualisiert werden, um diese Änderungen zu spiegeln. Dies ist typischerweise ein Zeitfresser für alle Beteiligten.
Aus diesem Grund könnten vollständige Tabellen- oder schlüsselbasierte Replikation besser für Ihre Bedürfnisse geeignet sein, wenn Sie wissen, dass sich Ihre Quelldatenbankstruktur häufig ändern wird.
Replikationsschemata
Organisationen können Datenreplikation durchführen, indem sie einem Schema folgen, um die Daten zu verschieben. Sie unterscheiden sich von den oben aufgeführten Techniken, da sie nicht als kontinuierliche Strategie zur Datenverschiebung verwendet werden. Vielmehr entscheiden sie, wie Daten repliziert werden können, um den spezifischen Bedürfnissen eines Unternehmens gerecht zu werden. Daten können in einem Rutsch oder in Abschnitten verschoben werden.
Es gibt drei Hauptreplikationsschemata, die in der Datenreplikation verwendet werden.
1. Vollständige Replikation
Vollständige Datenbankreplikation ist, wenn die gesamte Datenbank für mehrere Benutzer repliziert wird. Daten werden an fast jedem Standort oder Benutzer im Netzwerk zugänglich sein.
Dieses Schema bietet die beste Datenverfügbarkeit und kann bei internationalen Problemen helfen. Wenn ein Benutzer Schwierigkeiten hat, auf Daten vom europäischen Server der Organisation zuzugreifen, kann er dieselben Daten von anderen Servern auf der ganzen Welt als Backup abrufen.
Vorteile der vollständigen Replikation
- Verbessert die allgemeine Verfügbarkeit von Daten im gesamten System, da alles normal funktionieren kann, solange mindestens eine Site läuft.
- Die Abfrageausführung ist schneller.
- Da Daten von jeder Site abgerufen werden können, gibt es eine höhere Abrufrate globaler Abfragen.
Nachteile der vollständigen Replikation
- Da ein Update an allen Datenbanken durchgeführt werden muss, um exakte Kopien der Daten zu erhalten, wird das Aktualisieren mehr Zeit in Anspruch nehmen.
- Die Steuerung der Gleichzeitigkeit ist schwer zu erreichen, da sich die Daten ständig ändern.
2. Keine Replikation
Bei keiner Replikation werden Ihre Fragmente nur an einem Standort gespeichert. Dies kann es Benutzern, die weit von diesem Standort entfernt sind, erschweren, regelmäßig auf Informationen zuzugreifen.
Vorteile der fehlenden Replikation
- Daten sind leichter wiederherstellbar.
- Gleichzeitigkeit kann mit diesem Schema erreicht werden.
Nachteile der fehlenden Replikation
- Die Abfrageausführung kann langsamer sein, da mehrere Benutzer auf einen Server zugreifen.
- Da es keine Replikation gibt, sind Daten nicht leicht verfügbar.
3. Partielle Replikation
Partielle Replikation repliziert nur einige Fragmente aus der Datenbank. In diesem Schema werden die Daten in der Datenbank in Abschnitte unterteilt. Jeder Abschnitt wird an verschiedenen Standorten basierend darauf gespeichert, wie oft er von diesem Standort aus aufgerufen wird. Denken Sie daran als ein System, das analysiert, welche Daten für jeden Standort am wichtigsten sind. Wenn das chinesische Büro eine bestimmte Reihe von Tabellenkalkulationen verwendet, während der nordamerikanische Standort dies selten tut, werden diese Daten nur am chinesischen Standort repliziert.
Partielle Replikation ist am nützlichsten für Menschen, die im Finanz- und Vertriebsbereich arbeiten. Sie können Teile ihrer Datenbank auf Laptops und anderen Geräten mitnehmen und sie synchronisieren, wenn sie Daten vom Hauptdatenserver benötigen. Partielle Replikation hält wichtige Daten in der Nähe der Benutzer, die sie benötigen. Falls ein Benutzer auf Daten zugreifen muss, die er normalerweise nicht verwendet, wird immer eine Master-Datendatei auf dem Hauptserver des Hauptsitzes aufbewahrt.
Vorteile der partiellen Replikation
- Die Anzahl der Datenreplikate hängt von der Wichtigkeit der Daten in diesem Fragment ab.
Nachteile der partiellen Replikation
- Da nur Teile bestimmter Daten auf verschiedene Server repliziert werden, kann es den Fortschritt verlangsamen, wenn Benutzer auf Daten zugreifen müssen, die sie normalerweise nicht vom primären Server verwenden.
Bevor Sie Datenreplikationssoftware implementieren...
Bevor Sie sich entscheiden, der Datenreplikation eine gute Chance zu geben, gibt es ein paar Dinge, die Sie beachten sollten.
Mehr Speicherverbrauch
Wenn große Organisationen in die Datenreplikation einsteigen, sollten sie sich die Zeit nehmen, um zu bewerten, welche Techniken und Schemata sie verwenden möchten. Die Chancen stehen gut, dass, wenn die Organisation groß ist, es viele Daten gibt, die sie unterstützen.
Das Speichern von Unternehmensdaten an mehreren Orten wird den Speicherplatz aufbrauchen. Bevor Sie fortfahren, sollten Sie wissen, dass mehr Speicher mehr Geld bedeutet, was ein Dealbreaker sein könnte.
Die Möglichkeit inkonsistenter Daten
Das Replizieren von Daten über eine Anzahl von Quellen kann potenziell Inkonsistenzen verursachen. Wenn Sie Daten zu unterschiedlichen Zeiten und nur auf bestimmten Servern replizieren, ist die Wahrscheinlichkeit von nicht synchronisierten Daten hoch, und es kann schwierig sein, jeden Standort wieder auf denselben Stand zu bringen. Administratoren sollten einen maßgeschneiderten Replikationsprozess erstellen und jeden Serverstandort regelmäßig überprüfen, um Konsistenz weltweit sicherzustellen.
Der Bedarf an höherer Netzwerkkapazität und Rechenleistung
Obwohl es internationalen Benutzern das Zugreifen auf Daten erleichtert, wenn Datenstandorte näher bei ihnen sind, gibt es einen Nachteil. Das Verwalten mehrerer Standorte kann Ihr Netzwerk belasten und verlangsamen sowie Rechenleistung verbrauchen. Ein effektiverer Datenreplikationsprozess, der speziell auf Ihre Organisation zugeschnitten ist, kann Ihnen helfen, diese erhöhte Belastung zu bewältigen.
Finden Sie Ihr perfektes Match
Es kann entmutigend sein, die Suche nach einer Datenreplikationslösung zu beginnen, die für Ihre speziellen Bedürfnisse funktioniert. Aber das Finden dieser Lösung wird den Prozess auf lange Sicht viel einfacher machen.
Ihre IT-Abteilung kann Code schreiben und den Replikationsprozess selbst verwalten, aber das bringt seine eigenen Schwierigkeiten mit sich. Sie müssen Zeit aufwenden, um Ihre Daten zu pflegen, Geld für Anwendungen ausgeben und vielleicht sogar ein paar zusätzliche Leute einstellen, um den Prozess zu optimieren. Außerdem müssen Sie sich der immer drohenden Gefahr menschlicher Fehler bewusst sein.
Deshalb sind Datenreplikation und Datenbank-Backup so hilfreich. Datenbank-Backup-Lösungen helfen Unternehmen, ihre Daten mit Backup-Kopien im Falle von beschädigten Daten, Benutzerfehlern oder Hardwarefehlern zu schützen. Durch die Nutzung von Datenbank-Backup-Lösungen können Unternehmen sicherstellen, dass ihre Daten immer verfügbar sind, selbst wenn ihre Hauptdatenbank ausfällt.
Durchsuchen Sie die am besten bewerteten Datenbank-Backup-Lösungen, um die richtige Lösung für Ihre Organisation zu finden.

Alexa Drake
Alexa is a former content associate at G2. Born and raised in Chicago, she went to Columbia College Chicago and entered the world of all things event marketing and social media. In her free time, she likes being outside with her dog, creating playlists, and dabbling in Illustrator. (she/her/hers)

