



Dieser Beitrag ist Teil der 2021 Digital Trends Serie von G2. Lesen Sie mehr über G2s Perspektive zu digitalen Transformationstrends in einer Einführung von Michael Fauscette, G2s Chief Research Officer, und Tom Pringle, VP, Marktforschung, sowie zusätzliche Berichterstattung über Trends, die von G2s Analysten identifiziert wurden.
Datenmanagement-Trends im Jahr 2021
Im Jahr 2021 werden datengetriebene Führungskräfte ihre Datenmanagement-Strategien aufgrund der sich entwickelnden Technologieumgebung neu bewerten. Organisationen werden Investitionen in skalierbare Datenplattformen priorisieren, um Daten über Geschäftsbereiche hinweg effektiv zu sichern, zu verwalten und zu analysieren, und zwar über eine einzige einheitliche Plattform. Diese Plattformen werden eine größere Kontrolle über ihre Daten bieten und einen nahtlosen Zugriff ermöglichen, unabhängig davon, wo sie sich befinden, was ihnen letztendlich hilft, wertvolle Einblicke zu gewinnen und bessere Geschäftsentscheidungen zu treffen.
Organisationen können sich einen Wettbewerbsvorteil verschaffen, indem sie Fachwissen im Datenmanagement aufbauen, um ihre Geschäftsstrategie zu unterstützen. Neue Werkzeuge und Technologien, die auf künstlicher Intelligenz (KI) und maschinellem Lernen (ML) basieren, werden kontinuierlich eingeführt, um die sich ständig weiterentwickelnden Komplexitäten wie Datenvielfalt und -disparität in verschiedenen Umgebungen zu bewältigen.
Eine weitere allmähliche Entwicklung im Datenmanagement ist die Verwischung der Grenzen zwischen IT- und Geschäftsverantwortlichkeiten; Organisationen sind nicht mehr durch funktionale Grenzen eingeschränkt, was eine unternehmensweite Datenzusammenarbeit ermöglicht und Stakeholder in der gesamten Organisation mit den richtigen Daten zur richtigen Zeit befähigt.
Lassen Sie uns tiefer in die Trends eintauchen, die im Datenmanagement-Bereich im Jahr 2021 voraussichtlich auftauchen werden.
Neues Denken im Datenmanagement für hybride und Multi-Cloud-Strategien
VORHERSAGE
Bis 2025 werden 95 % der Unternehmensorganisationen eine hybride Cloud-Bereitstellung annehmen. Daten werden bis 2025 eine jährliche Wachstumsrate von 25 % aufweisen, mit zunehmender Vielfalt und Disparität.
Der Aufstieg von hybriden und Multi-Cloud-Architekturen sowie kontinuierliche Fortschritte in KI und ML veranlassen den Datenmanagement-Markt, sich ständig mit intensiveren Herausforderungen, Chancen und Strategien weiterzuentwickeln. Die jüngste Partnerschaft zwischen zwei Technologieriesen, IBM und SAP, erklärt die Bewegung von Organisationen hin zu einer hybriden Cloud-Reise.
Die Cloud-Adoption hat in den letzten Jahren drastisch zugenommen, wobei 2020 den Trend noch weiter beschleunigte, angesichts der COVID-19-Pandemie. Das Wachstum des Cloud-Infrastruktur-Dienstleistungsmarktes stieg im dritten Quartal sprunghaft an, wobei die Pandemie als Katalysator fungierte und die Online-Nachfrage anheizte. Unternehmen haben begonnen, immer mehr ihrer Arbeitslasten und Daten in die Cloud zu verlagern, während sie gleichzeitig mehrere Cloud-Umgebungen einem einzigen Cloud-Anbieter vorziehen.
Da Unternehmen ihre Migration in die Cloud beschleunigen, implementieren sie zunehmend eine Multi-Cloud-Strategie. 93 % der Unternehmen haben eine Multi-Cloud-Strategie und 87 % eine hybride Cloud-Strategie, laut dem State of Cloud Report 2020 von Flexera.
Eine Multi-Cloud-Strategie ermöglicht es Organisationen, eine hybride Cloud-Umgebung aufrechtzuerhalten, die eine Kombination aus Sicherheit und spezialisierten Fähigkeiten wie integrierten ML-Fähigkeiten bietet. Die sicherheitsfokussiertesten Arbeitslasten und Daten können in der privaten Cloud gehalten werden, während reguläre Daten und Anwendungen auf kostengünstigen öffentlichen Cloud-Netzwerken laufen können. Diese Art von Infrastruktur erweist sich als erfolgreiches Modell für Organisationen, da sie eine reichhaltige Auswahl an Cloud-Optionen bieten, die sowohl die Rendite von Cloud-Investitionen optimieren als auch die Abhängigkeit von Anbietern verringern.
Eines der größten Herausforderungen, die mit der zunehmenden Rate der Multi-Cloud- oder hybriden Cloud-Adoption einhergehen, ist das Management von Daten über mehrere Systeme und Standorte innerhalb von Organisationen. Unternehmen werden sich irgendwo zwischen 100 % On-Premises und Cloud auf dem Bereitstellungsspektrum befinden.

In einem Echtzeit-Hybrid-Cloud-Szenario werden die meisten Organisationen eine Mischung aus Multi-Cloud- und On-Premises-Bereitstellung verwenden. Um die Herausforderungen in Bezug auf diese sich entwickelnde Landschaft zu überwinden, werden Organisationen End-to-End-Hybrid-Datenmanagement-Plattformen einführen, um eine größere Sichtbarkeit und Kontrolle über ihre Daten in Cloud-, Hybrid- und On-Premises-Umgebungen zu gewährleisten und gleichzeitig Datensicherheit und Governance sicherzustellen.
Riesen im Datenmanagement-Bereich, wie IBM definieren eine moderne hybride Datenmanagement-Plattform als eine, die vollständige Zugänglichkeit unabhängig von Quelle oder Format gewährleisten sollte, verschiedene Bereitstellungsoptionen unterstützen, Einschränkungen beseitigen und den Zugang zu Daten demokratisieren sowie die Kraft intelligenter Analysen mit eingebettetem ML nutzen sollte.
Möchten Sie mehr über iPaaS-Software erfahren? Erkunden Sie iPaaS Produkte.
Entschlüsselung der aufkommenden Technologie im Datenmanagement: Datengewebe
VORHERSAGE
2021 wird einen Anstieg der aufkommenden Datengewebe-Technologie erleben.
Daten befinden sich nicht mehr in einer einzigen Umgebung; sie sind über On-Premises- und Cloud-Umgebungen verstreut, was darauf hinweist, dass Unternehmen in eine hybride Welt übergehen. Mit dem exponentiellen Wachstum von Datenformaten, -quellen und -bereitstellungen in Organisationen suchen Unternehmen ständig nach Möglichkeiten, Datenressourcen, die in bestehenden On-Premises-Altsystemen leben, optimal zu nutzen.
Datengewebe kann als ein Gewebe betrachtet werden, das über einen großen Raum gespannt ist und mehrere Standorte, Typen und Datenquellen verbindet, mit Methoden zum Zugriff auf diese Daten. Die Datengewebe-Technologie ist darauf ausgelegt, Komplexitäten im Zusammenhang mit der Verwaltung von Datenunterschieden in sowohl On-Premises- als auch Cloud-Umgebungen über eine einzige einheitliche Plattform zu lösen.
Datengewebe ist ein aufkommender Begriff in der Daten-Technologie-Branche. Organisationen wie Cinchy, ein in Toronto ansässiges Daten-Kollaborationsunternehmen, versuchen, Anbieter über das Potenzial dieser Technologie aufzuklären. Das Unternehmen hat kürzlich auch eine Series A Finanzierungsrunde abgeschlossen, um die wachsende Nachfrage nach Datengewebe-Technologie zu unterstützen. Der Fokus dieser Unternehmen liegt darauf, eine Datenumgebung zu schaffen, die zentralisierten Zugriff über eine einzige, einheitliche Ansicht der Daten einer Organisation bietet, die Zugriffs- und Governance-Beschränkungen erbt, unabhängig vom Format oder Standort der Daten.

Die in einem Datengewebe angewandte Daten-Kollaborationstechnologie ermöglicht es Benutzern, intensive ETL-Prozesse zu beschleunigen und zu rationalisieren, indem sie einfach auf verschiedene Datenquellen zugreifen und die Zeit, die für das Verschieben und Kopieren von Daten zwischen Anwendungen aufgewendet wird, durch eine miteinander verbundene Architektur eliminieren. Datenprofis glauben, dass Unternehmen mit zunehmend verteilten, dynamischen und vielfältigen Daten einen reibungslosen Zugang und Austausch von Daten benötigen, und dies wird den Aufstieg der Datengewebe-Technologie vorantreiben.
Organisationen setzen weiterhin auf KI und ML, um Datenmanagement-Strategien zu unterstützen
Erweitertes Datenmanagement (ADM)
Datenwissenschaftler und Dateningenieure verbringen den Großteil ihrer Zeit damit, Daten manuell zuzugreifen, vorzubereiten und zu verwalten. ADM ist die Anwendung von KI/ML-Technologien zur Automatisierung manueller Aufgaben in Datenmanagement-Prozessen.
VORHERSAGE
Bis 2022 werden 80 % der alltäglichen Datenmanagement-Aufgaben durch ADM automatisiert, sodass sich Datenwissenschaftler auf die Entwicklung von Modellen konzentrieren können, um fortgeschrittene Einblicke in Daten zu gewinnen.
ADM wird Unternehmen helfen, Operationen im Zusammenhang mit Datenqualität, Metadatenmanagement, Stammdatenmanagement, Datenbankmanagementsystemen usw. zu vereinfachen, zu optimieren und zu automatisieren, indem sie sich selbst konfigurieren und selbst optimieren. Eine KI/ML-gestützte Engine bietet Datenprofis intelligente Empfehlungen, die es ihnen ermöglichen, aus mehreren vorab gelernten Modellen von Lösungen für eine bestimmte Datenaufgabe auszuwählen. Die Automatisierung manueller Datenaufgaben innerhalb von Organisationen wird zu höherer Produktivität und erhöhter Demokratie unter der Datenbenutzergemeinschaft führen.
Anwendung von ADM in Datenkatalogen
Der Bedarf an ML-gestützten Metadatenkatalogen wird 2021 weiter steigen. Angesichts der zunehmend breiten und verteilten Datensätze gibt es erhebliche Herausforderungen bei der Inventarisierung und Synthese der Daten für den unternehmensweiten Einsatz. Heute wird das Suchen und Verfolgen des Datenverlaufs immer wichtiger für effektive Analysen.
Maschinelles Lernen Datenkataloge wurden 2020 wie warme Semmeln verkauft und dieser Trend wird weiter wachsen. ML automatisiert die alltäglichen Aspekte des Verständnisses der Daten und der Anwendung von Richtlinien, Geschäftsregeln, Tags und Klassifikationen in Datenkatalogen.
Verbreitung von Wissensgraphen
Graphdatenbanken sind eine relativ alte Technologie. Technologieriesen wie Google, Facebook und Twitter verwenden seit langem Wissensgraphen, um ihre Kunden, Geschäftsentscheidungen und Produktlinien zu verstehen. Wissensgraphen bestehen aus einer zugrunde liegenden Graphdatenbank zur Speicherung der Daten und einer Schicht zur Ableitung von Erkenntnissen aus den Daten.
In diesem Jahr verzeichnete G2 einen Anstieg von 119 % in der Kategorie Graphdatenbanken und verzeichnete das höchste Wachstum während der Pandemie. Es kann angenommen werden, dass Graphdatenbanken ein wirklich wertvolles Werkzeug bei der Modellierung der Ausbreitung des Coronavirus waren. Pharmaunternehmen wie AstraZenenca verwendeten Graphalgorithmen, um Patienten zu finden, die bestimmte Reisetypen und -muster hatten, und dann andere zu finden, die nahe und ähnlich waren.
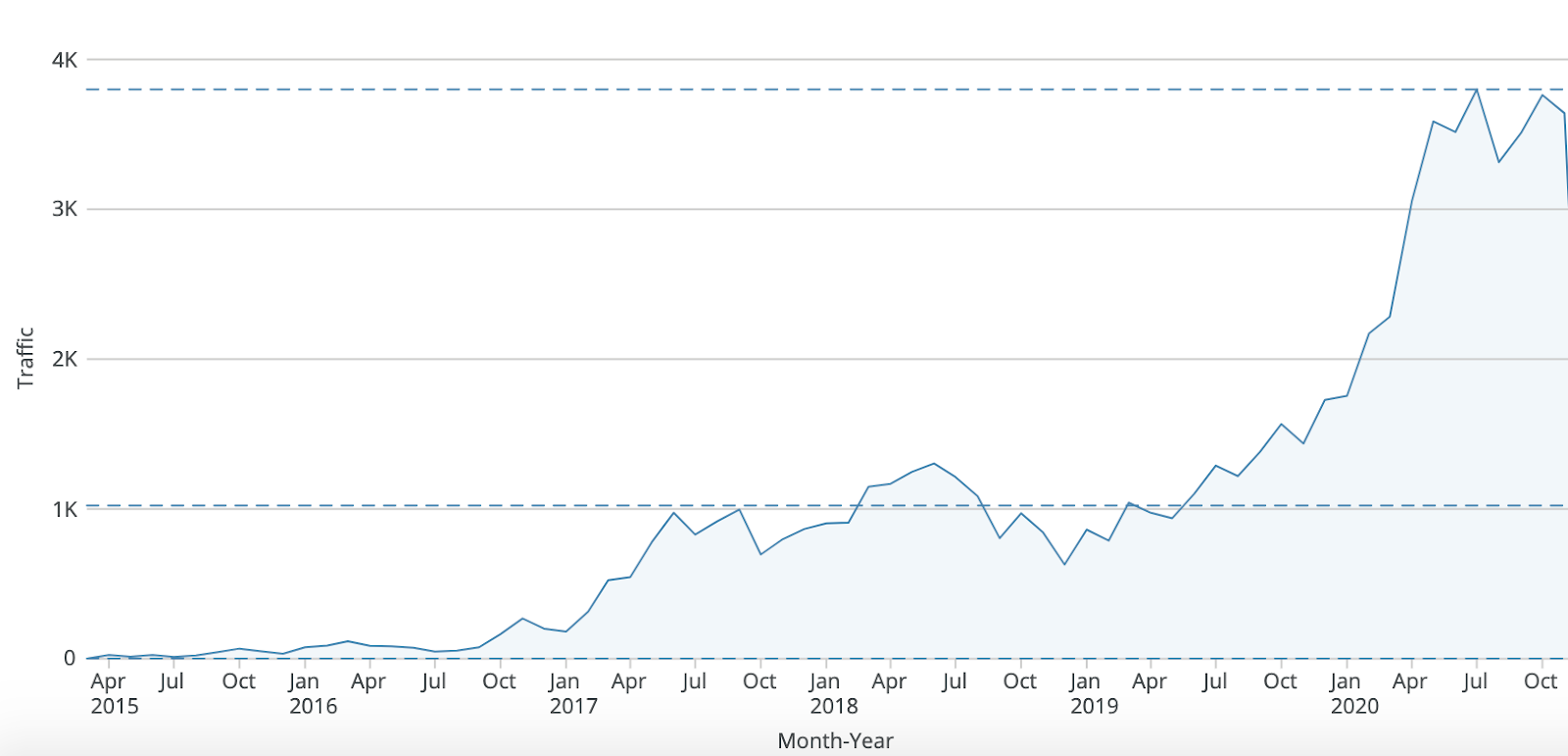
Die Fähigkeit von Wissensgraphen, komplexe heterogene Datenbeziehungen zu entwirren und zu analysieren, um bedeutungsvolle Beziehungen zu entdecken, hat die Produktivität von Datenwissenschaftlern erhöht. Es erleichtert auch die Fähigkeit der Benutzer, kontinuierlich zu lernen und organisch mit Hilfe von Ontologien zu wachsen.
Graph erweist sich als einer der schnellsten Wege, um Daten zu verbinden, insbesondere wenn es um komplexe oder große Mengen an unterschiedlichen Daten geht. Die Implementierung eines Wissensgraphen in Kombination mit KI- und ML-Algorithmen wird helfen, Kontext und Rationalität in Daten zu verankern. Wichtige Anwendungsfälle der Graphverarbeitung werden in Betrugserkennung, der Analyse sozialer Netzwerke und im Gesundheitswesen zu sehen sein.
Wichtige Erkenntnisse
Organisationen übernehmen zunehmend Multi-Cloud-Strategien und verlagern ihre Arbeitslasten und Daten in die Cloud. Daten werden irgendwo zwischen On-Premises und in der Cloud gespeichert. Das Management dieser verstreuten Daten über mehrere Quellen, Formate und Bereitstellungen hinweg ist eine Herausforderung, die Organisationen im Jahr 2021 erkennen werden. Dies wird Unternehmen dazu führen, ihre Datenmanagement-Strategie neu zu überdenken, um einen hybriden Datenmanagement-Ansatz zu übernehmen, mit dem Ziel, Daten zu verbinden und zu verwalten, unabhängig davon, wo sie sich befinden.
Organisationen werden skalierbare Datenplattformen aufbauen, die von KI/ML-Technologie angetrieben werden, um der sich ständig weiterentwickelnden technologischen Landschaft gerecht zu werden.
Entdecken Sie die am besten bewertete Software in verwandten Kategorien:

Isha Kaur
Prior to joining G2, Isha worked as a market research analyst at an IT Consulting firm with demonstrated experience in B2B software and services. As an analyst at G2, her research is concentrated on the data management space and related technologies. She leverages G2’s dynamic and unbiased review data to provide software buyer’s data-driven content and insights. Alongside, she also focuses on growing and evolving G2’s software taxonomy and representing sellers accurately on G2.com.

